📄 LLM2Fx-Tools: Tool Calling for Music Post-Production
#音乐信息检索 #大语言模型 #多模态模型 #数据集
✅ 7.0/10 | 前25% | #音乐信息检索 | #大语言模型 | #多模态模型 #数据集
学术质量 7.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:SeungHeon Doh(KAIST, Sony AI)、Junghyun Koo(Sony AI)(共同第一作者)
- 通讯作者:未明确说明
- 作者列表:SeungHeon Doh (KAIST, Sony AI), Junghyun Koo (Sony AI), Marco A. Martínez-Ramírez (Sony AI), Woosung Choi (Sony AI), Wei-Hsiang Liao (Sony AI), Qiyu Wu (Sony Group Corporation), Juhan Nam (KAIST), Yuki Mitsufuji (Sony AI, Sony Group Corporation)
💡 毒舌点评
亮点是这篇论文首次将LLM的工具调用范式引入到音频效果链生成任务,框架设计完整(从感知、推理到执行),并配套发布了高质量的对话式数据集LP-Fx,为后续研究建立了不错的基础。短板是实验验证范围主要局限于单声道、单乐器音频,在真正复杂的多轨混音场景下有效性存疑,且“可解释性”在面对多效果器组合产生的复杂听感时可能大打折扣。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:未提及公开权重。
- 数据集:开源了LP-Fx数据集。论文提供了Demo页面链接:
https://seungheondoh.github.io/llm2fx-tools-demo/,通常数据集下载链接会在此类页面上提供。 - Demo:提供了在线演示页面:
https://seungheondoh.github.io/llm2fx-tools-demo/。 - 复现材料:论文详细说明了数据生成流程、参数范围(表6)、训练两阶段的学习率/步数等关键细节。提供了多个附录(C-F)用于补充生成提示词、评估指标定义等。
- 论文中引用的开源项目:
- 音频效果库:Pedalboard(用于部分效果器)。
- 音频效果移除:Fx-Removal (Rice et al., 2023)。
- 不同iable DSP基线:dasp-pytorch仓库(用于DeepAFx-ST基线)。
- LLM基础:Qwen3模型(Yang et al., 2025)。
📌 核心摘要
本文提出LLM2Fx-Tools,一个基于大语言模型(LLM)的多模态框架,用于自动生成可执行的音乐后期制作音频效果链(Fx-chain)。该方法旨在解决传统自动FX链估计方法在灵活性(动态选择效果和排序)和可解释性方面的不足。核心方法是利用一个预训练音频编码器将干声和参考音频映射到语言模型空间,再通过LLM(Qwen3-4B)以链式思维(CoT)规划为引导,生成结构化的工具调用序列,从而选择效果器、确定顺序并估算参数。为训练此模型,作者构建并开源了LP-Fx数据集,包含约10.1万条带有CoT标注的对话式样本。实验在逆向工程(给定干声和湿声推导FX链)和音频效果风格迁移(从参考音频推断FX链并应用于新音频)两个任务上进行。主要结果表明,LLM2Fx-Tools在效果分类准确率(80%)、排序相关性(0.56)以及多项感知和特征距离指标上优于回归、多任务学习等传统基线,也优于闭源的Gemini 2.5 Flash模型。MUSHRA主观听感测试也证实了其优势。论文的核心意义在于提出了一种可解释、可控且基于对话的音频后期制作新范式。主要局限性包括:处理范围限于单声道音频、FX链推导依赖于预处理得到的伪干声、以及效果器逆向工程本身存在的一到多映射歧义性。
🏗️ 模型架构
LLM2Fx-Tools是一个端到端的自回归多模态生成框架。其核心架构是:音频编码器 + 音频-语言适配器 + 大语言模型(LLM)。

图1展示了LLM2Fx-Tools的整体框架流程。输入包含用户指令、可用工具列表、参考音频以及经过Fx-Removal和Fx-Normalization预处理得到的伪干音频。模型输出包括链式思维(CoT)、工具调用序列(即FX-chain)和自然语言回复。生成的工具调用随后与音频效果模块环境结合,用于处理新音频。
图2详细说明了模型架构。具体流程如下:
- 输入处理:用户指令文本(
x_instruction)被分词为e_instruction。干声和参考音频x_dry,x_ref分别通过Fx-Encoder++(一个为音频效果处理预训练的编码器)提取音频表示,再通过一个基于交叉注意力的Transformer适配器投影到语言模型的嵌入空间,得到e_dry,e_ref。 - 统一输入序列:文本指令嵌入、用于分隔的文本标记(如“dry audio”、“reference audio”)以及音频嵌入被拼接成一个统一的多模态输入序列,送入LLM。
- 自回归生成:LLM(基于Qwen3-4B并通过LoRA微调)自回归地依次生成:
- 链式思维(CoT):将复杂任务分解为用户输入分析、效果器选择、顺序确定、参数规划四个子步骤。
- 工具调用序列:生成结构化的工具调用命令(JSON格式),每个命令指定一个音频效果模块及其参数。
- 自然语言响应:用自然语言总结FX链和参数。
- 关键设计选择:
- 音频编码器:选择Fx-Encoder++是因为其专门为音频效果表征学习,比通用音频编码器更有效。
- 适配器:采用基于交叉注意力的Transformer适配器而非简单线性投影,能更好地聚合音频信息到有限的可学习查询令牌中。
- CoT推理:作为中间规划阶段,显著提升了FX链生成的准确性和可解释性。
💡 核心创新点
- 首个面向音频效果模块的结构化工具调用框架:首次将LLM的工具调用能力系统地应用于控制非可微的音频效果模块(如EQ、压缩器、混响),实现了从自然语言或多模态输入到可执行FX链的端到端映射。这突破了传统方法在动态选择效果和排序上的限制。
- 专为FX链规划设计的链式思维(CoT):将FX链生成任务显式分解为四个推理步骤(分析、选择、排序、参数估算)。CoT不仅作为LLM生成更准确工具调用的上下文条件,还为用户提供了可读的决策过程,极大增强了系统的可解释性。
- 多模态指令跟随:将FX链估算从纯音频到效果参数的映射,扩展为包含自然语言指令的多模态框架。用户可以通过语言指定效果类型、音乐风格或乐器特性,从而引导生成更符合个性化需求的FX链。
- 大规模高质量对话式数据集LP-Fx:构建了首个用于此任务的指令跟随数据集,包含约10.1万个对话样本,每个样本都有用户指令、工具调用、CoT推理和助手回复,并采用LLM-as-a-judge进行了质量过滤。
🔬 细节详述
- 训练数据:
- 数据集:LP-Fx。音频源来自MedleyDB(约2000个原始干声音轨,覆盖9种流派、80种乐器)。效果链使用了Pedalboard库的6个效果器(压缩、失真、混响、延迟、限制器、增益)和3个自定义模块(三段均衡器、立体声加宽器、声像),共9个工具,26个参数。
- 数据合成:分为四阶段:1) 在音乐合理范围内随机采样FX链,合成干/湿声对;2) 使用Gemini-2.5-Flash-lite生成自然对话(指令和回复);3) 使用Gemini-2.5-Flash生成CoT推理;4) 使用Gemini-2.5-Pro作为评判,过滤低质量样本。
- 规模:训练集99,900条对话,测试集900条。按FX链长度(1-9个效果器)分层采样,每个长度约11,100训练样本,100测试样本。
- 损失函数:
- 主要采用自回归交叉熵损失
L_CE,仅计算在目标序列(CoT、工具调用、响应)上。 - 针对数值参数预测,额外引入数字令牌损失
L_NTL(基于Wasserstein-1距离),惩罚预测值与真实值在数值大小上的偏差,而不仅仅是令牌的正确与否。 总损失:L_total = L_CE + λ L_NTL,λ为平衡超参数。
- 主要采用自回归交叉熵损失
- 训练策略:
- 两阶段训练:
- 模态对齐预训练:冻结LLM,仅使用音频输入和FX链输出训练音频-语言适配器。采用随机FX采样以覆盖参数空间。
- LLM微调:解冻LLM,使用LoRA(rank=128, alpha=256)与适配器一起,在完整的多模态对话数据上进行端到端微调。
- 稳健性训练:在训练时引入干声掩码(以概率
p_masking随机省略干声输入),使模型能同时处理有干声(逆向工程)和无干声(盲估计)的场景。
- 两阶段训练:
- 关键超参数:
- LLM基础模型:Qwen3-4B。
- 音频编码器:Fx-Encoder++。
- 适配器:Transformer,使用32个可学习查询令牌。
- 微调方法:LoRA,秩128,Alpha 256。
- 训练阶段1:学习率1e-4,批次大小32,训练100K步。
- 训练阶段2:学习率5e-5,批次大小16,训练400K步。
- 训练硬件与推理细节:论文中未详细说明训练所用GPU型号和数量。推理时使用自回归解码。
- 正则化/稳定训练技巧:采用多阶段训练策略以稳定从预训练到微调的过程;使用LoRA进行参数高效微调;训练时使用干声掩码提升泛化能力。
📊 实验结果
论文在三个任务上进行了评估:逆向工程、音频效果风格迁移、自然语言生成。
- 逆向工程(表2)
方法 Fx-chain Planning Perceptual Dist. DSP Embedding Sim.(↑) Acc.(↑) Corr.(↑) MAE(↓) L/R(↓) M/S(↓) AF(↓) AFx-Rep FxEnc No Fx - - - 13.11 13.49 14.82 0.50 0.30 Random Fx 52% -0.01 0.39 8.07 8.90 13.70 0.41 0.34 Regression 55% -0.03 0.20 3.81 4.12 9.20 0.62 0.64 MultiTask 61% 0.00 0.23 3.17 3.39 8.39 0.63 0.66 DeepAFx-ST - - - 1.75 2.06 3.95 0.62 0.66 Gemini2.5Flash 78% 0.54 0.32 3.42 4.24 14.97 0.56 0.50 LLM2Fx-Tools 80% 0.56 0.23 3.13 3.27 8.29 0.68 0.67 w/o CoT 67% 0.49 0.24 3.34 3.38 8.39 0.64 0.66 w/o NTL 73% 0.51 0.32 3.69 3.52 8.47 0.61 0.63 w/o MST 76% 0.55 0.25 3.21 3.32 8.30 0.67 0.64
- 关键结论:LLM2Fx-Tools在效果分类准确率(80% vs. 次优的78%)和排序相关性(0.56 vs. 0.54)上取得最佳。在感知距离(MRS)和DSP特征距离上也显著优于大多数基线。DeepAFx-ST在感知距离上更优(因其训练目标),但无法使用非可微模块。消融实验证明了CoT、NTL和MST的贡献。
主观听感测试(图4):
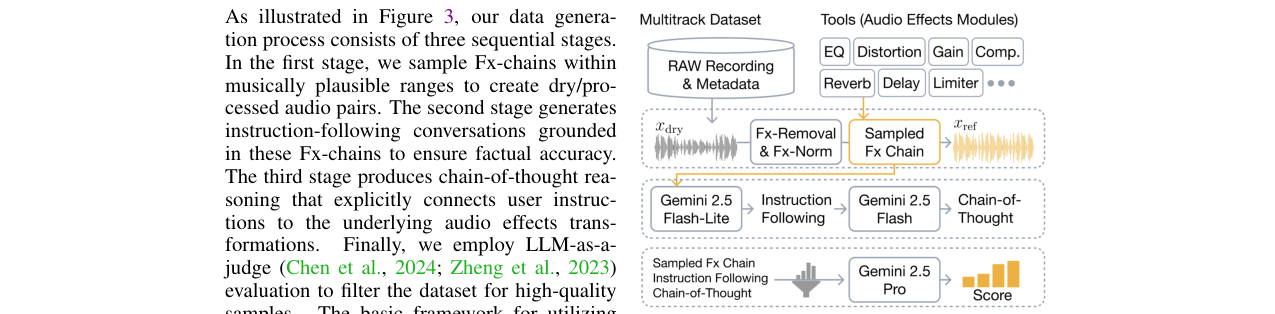
图4展示了MUSHRA听觉测试结果。LLM2Fx-Tools获得最高平均分(62.8),显著高于Gemini 2.5 Flash(56.5)、DeepAFX-ST(54.8)和No Fx基线(39.1)。有趣的是,MultiTask和Regression基线得分甚至低于No Fx,说明错误的效果器应用比不加效果更糟。
- 音频效果风格迁移(表3)
方法 DSP AF(↓) Embedding Sim.(↑) AFx-Rep FxEnc No Fx 8.69 0.24 0.43 Regression 7.83 0.24 0.31 MultiTask 7.62 0.29 0.46 DeepAFx-ST 10.50 0.26 0.49 Gemini2.5Flash 9.00 0.24 0.27 LLM2Fx-Tools 7.41 0.35 0.49
- 关键结论:在跨数据集的风格迁移任务上,LLM2Fx-Tools在DSP距离和嵌入相似度上均表现最佳,显示了良好的泛化能力。Gemini 2.5 Flash在此任务上表现较差。
- 自然语言生成(表4)
模型 参数量 多模态 推理能力 TC成功(%) IF质量 CoT质量 Qwen 2.5Omni 7B ✓ ✗ 0.2% 1.46 N/A Qwen 3 4B ✗ ✓ 73.7% 2.89 2.30 Gemini 2.5Flash N/A ✓ ✓ 100% 3.39 3.03 LLM2Fx-Tools 4B ✓ ✓ 99.8% 3.50 3.05
- 关键结论:LLM2Fx-Tools在工具调用成功率(99.8%)、指令跟随质量和CoT质量上均达到与Gemini 2.5 Flash相当甚至略优的水平,远超不具备多模态或推理能力的基线模型。
⚖️ 评分理由
- 学术质量:7.0/7:创新性强,首次将LLM工具调用系统化应用于音频效果链生成,提出了完整的框架和训练方法。技术实现严谨,实验对比充分,包括客观指标、消融研究和主观听感测试,证据链完整。主要扣分点在于验证场景(单轨、有限效果器)与真实复杂混音场景的差距。
- 选题价值:1.5/2:选题针对音乐后期制作自动化,有明确的应用前景,能降低专业门槛。但其研究方向属于音乐信息检索的垂直子领域,对广泛的音频/语音社区读者来说相关性中等。
- 开源与复现加成:0.5/1:最大的加分项是开源了LP-Fx数据集,并提供了详细的数据合成流程和参数范围,为复现和未来研究奠定了重要基础。主要扣分点是未开源核心模型代码和训练权重,使得完全复现该系统存在较大难度。