📄 Learnable Fractional Superlets with a Spectro-Temporal Emotion Encoder for Speech Emotion Recognition
#语音情感识别 #时频分析 #端到端
🔥 8.0/10 | 前25% | #语音情感识别 | #时频分析 | #端到端
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.8 | 置信度 高
👥 作者与机构
- 第一作者:Alaa Nfissi(数据科学实验室(DOT-Lab), Université TÉLUQ;康考迪亚大学信息系统工程学院(Concordia Institute for Information Systems Engineering))
- 通讯作者:未明确说明
- 作者列表:Alaa Nfissi(数据科学实验室(DOT-Lab), Université TÉLUQ;康考迪亚大学信息系统工程学院)、Wassim Bouachir(数据科学实验室(DOT-Lab), Université TÉLUQ)、Nizar Bouguila(康考迪亚大学信息系统工程学院)、Brian Mishara(魁北克大学蒙特利尔分校心理学系;蒙特利尔自杀、伦理问题及临终实践研究与干预中心)
💡 毒舌点评
这篇论文的亮点在于它不满足于简单地使用或微调现有前端,而是试图从数学原理上重新定义一个更灵活、可学习的时频分析框架(LFST),体现了扎实的信号处理功底和理论建模能力。然而,其主要短板在于计算效率:论文附录的复杂度分析显示,LFST+STEE在FLOPs、延迟和内存占用上远超STFT、LEAF等基线,这使得“紧凑”的STEE编码器所节省的参数优势在端到端系统中可能被前端的计算成本抵消,削弱了其实用吸引力。
🔗 开源详情
- 代码:论文中明确提供了GitHub代码仓库链接:https://github.com/alaaNfissi/LFST-for-SER。
- 模型权重:论文中未提及公开的模型权重。
- 数据集:NSPL-CRISE为私有数据集(经IRB批准使用),论文中未提及公开获取方式。IEMOCAP和EMO-DB为公开数据集,论文中提供了引用。
- Demo:论文中未提及在线演示。
- 复现材料:论文提供了详尽的超参数设置(Table 8)、训练细节(Section 4.2)、算法伪代码(Algorithm 1-3)和技术附录,为复现提供了充分信息。
- 论文中引用的开源项目:论文未明确提及依赖的外部开源工具或模型(除作为基线对比的方法外)。
📌 核心摘要
- 要解决什么问题:传统语音情感识别(SER)的前端(如STFT、小波变换)存在固定的时间-频率(TF)分辨率权衡,且参数需人工调优,无法自适应任务需求。已有超小波变换(Superlet)局限于整数阶,存在阶跃伪影。
- 方法核心:提出可学习分数阶超小波变换(LFST)作为全可微的前端。LFST通过学习每个频带上的分数阶阶数(通过对数域几何平均实现)、单调对数频率网格和频率依赖的基频周期,生成TF幅度图S和相位一致性图κ。结合一个可学习非对称硬阈值(LAHT)模块对S去噪。之后,设计了紧凑的频谱时序情感编码器(STEE),利用深度可分离卷积、混合TF块、自适应FiLM门控和轴向自注意力处理S和κ,输出情感分类。
- 新在哪里:相比固定前端或先前非可学习的超小波,LFST首次将超小波的阶数、频率网格和周期全部设为可学习参数,并进行了端到端训练。同时,引入了物理意义明确的相位一致性κ通道和LAHT去噪模块,形成了一个理论完备、可数据驱动的TF表示学习框架。
- 主要实验结果:在IEMOCAP(4类)上,准确率87.5%,F1值86.8%;在EMO-DB(7类)上,准确率91.4%,F1值90.4%;在NSPL-CRISE(5类,电话语音)上,准确率76.9%,F1值76.6%。在与相同STEE编码器下的STFT、小波、固定超小波、LEAF前端对比中,LFST在三个数据集上均取得最佳性能。关键消融显示,在NSPL-CRISE上,移除κ导致F1下降9.7个百分点,移除LAHT下降2.5个百分点。
- 实际意义:为语音及音频分析提供了一种可学习、可解释、数学基础扎实的TF表示学习前端,可替代传统固定设计,并可能应用于其他需要精细时频分析的场景。
- 主要局限性:系统计算成本较高,LFST前端的FLOPs和内存占用远高于STFT等轻量级前端,限制了部署。此外,研究未在更大规模、更多语言的数据集上验证,也未与强大的预训练SSL模型进行直接性能对比。
🏗️ 模型架构
整个系统(LFST+STEE)处理流程为:原始波形 → LFST前端 → 两通道TF图(幅度S, 相位一致性κ) → STEE编码器 → 情感类别。所有组件端到端可训练。
LFST前端架构: LFST接收原始波形x,输出S∈R^{B×F×T}, κ∈[0,1]^{B×F×T}。其核心是三个可学习组件:
- 可学习对数频率网格:通过学习一组正增量δ_j(经softplus和归一化)并累加,严格生成单调递增的F个频率点f_1…f_F,且f_1=f_min, f_F=f_max。
- 可学习频率依赖基频周期:对每个频率f_i学习基础周期c1(f_i) ≥1, 第o阶的周期为c_o(f_i) = o * c1(f_i), 用于构建Morlet小波。
- 可学习分数阶阶数权重:对每个频率f_i学习一组阶数权重w_{i,o}(通过softmax归一化),定义有效阶数oeff(f_i)。LFST幅度是各阶小波响应幅度的加权几何平均(在log域计算),相位一致性κ是各阶响应单位相量的加权平均的模。
最后,应用可学习非对称硬阈值(LAHT)对幅度S进行稀疏化去噪。
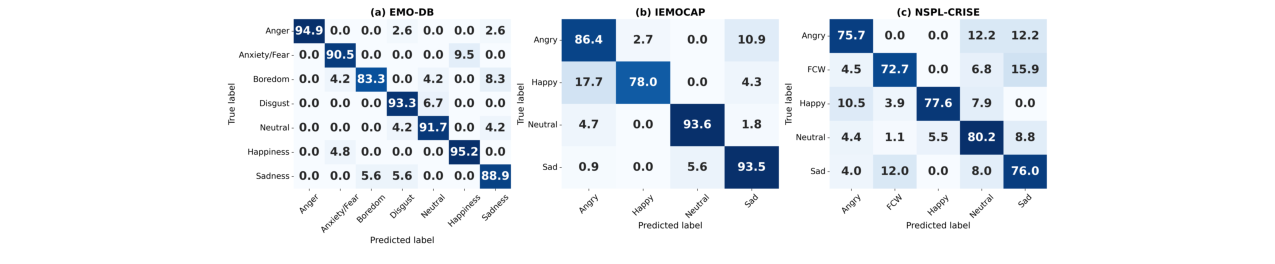
图1(原文图1)展示了LFST前端流程:原始波形输入,通过可学习的对数频率网格、softmax阶数权重和频率依赖周期,产生各阶Morlet小波响应。其幅度经加权几何平均得到S,加权单位相量得到相位一致性κ。长度掩码作用于输出,LAHT仅作用于S。最终S和κ被拼接为两通道输出。
STEE编码器架构: STEE接收LFST输出的两通道图[S; κ]∈R^{B×2×F×T}。其主要组件按顺序为:
- 时间维度深度卷积主干:沿时间轴进行深度卷积,提取局部时序模式。
- 频谱残差块:沿频率轴进行深度卷积,捕获短程跨频带相关性。
- 混合TF残差块+SE:并行进行频率轴和时间轴的深度卷积,结合通道注意力(Squeeze-and-Excitation)进行通道重加权。使用两个这样的块。
- 自适应FiLM频率门控:基于S和κ的时序统计量(均值、标准差)以及有效阶数oeff, 通过一个小MLP生成通道门控信号,对特征图进行调制,使编码器能感知LFST的分析状态。
- 时间下采样与轴向自注意力:沿时间轴进行固定步长下采样,然后对平均池化后的时序特征应用局部多头自注意力,捕获长程依赖。
- 注意力统计池化与分类头:将特征沿频率轴平均,再通过注意力加权统计(均值和标准差)得到一个固定长度的嵌入向量,最后通过线性层分类。
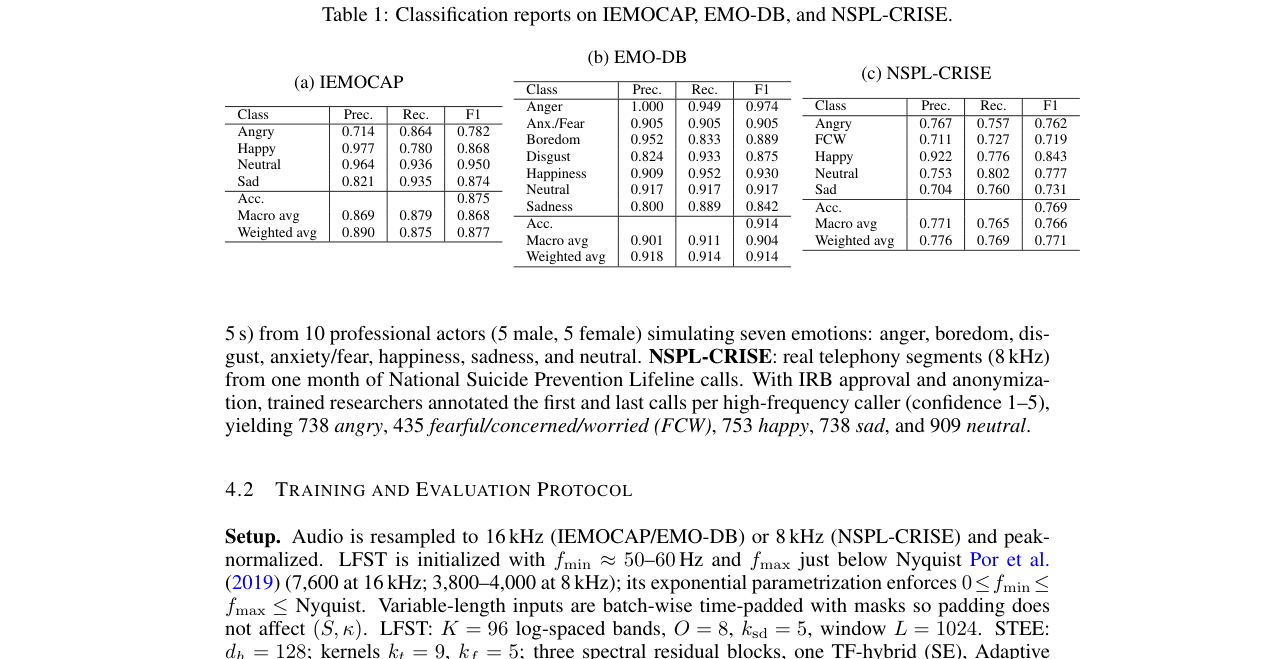
图2(原文图2)展示了STEE编码器的整体结构:从左到右依次为DW/PW卷积主干、频谱残差块、两个带SE的TF混合块、自适应FiLM门控、时间下采样与轴向注意力、注意力统计池化,最后是线性分类器。
图3(原文图3)详细展示了自适应FiLM门控的工作机制:对于每个频率f,利用S和κ的时序统计量(均值、对数标准差)与有效阶数oeff融合,通过一个小型MLP生成通道维度的门控值,用于调制编码器特征。
💡 核心创新点
- 可学习分数阶超小波变换(LFST):将传统超小波的固定整数阶扩展为可通过softmax权重混合的连续分数阶,并作为可微分前端与下游任务端到端联合优化。这解决了传统TF分析中分辨率权衡固定、无法适应数据的问题,实现了真正的“数据驱动”TF分析。
- 物理启发的正则化设计与理论保证:从第一性原理出发,对Morlet小波进行DC校正保证可容许性(零均值),分析了LFST的连续性、近似解析性(负频率泄漏有界),并提供了梯度推导和Lipschitz稳定性证明。这为可学习TF前端的设计提供了坚实的数学基础和稳定性保障。
- 相位一致性(κ)通道:在幅度S之外,额外引入一个量化各阶小波响应相位对齐程度的通道κ。相位一致性对噪声更鲁棒,能更好地表示有声段和瞬态结构,为分类器提供了互补信息。
- 可学习非对称硬阈值(LAHT):一个平滑的、参数化的稀疏化门控,作用在TF幅度图上,用于抑制低能量、噪声激活,保留显著结构。其非对称设计和可学习阈值使其比固定阈值方法更灵活。
- 紧凑的频谱时频情感编码器(STEE):设计了一个参数高效的编码器,通过深度可分离卷积、混合TF块和FiLM门控,高效地处理LFST生成的两通道TF图,并在多个基准上验证了其有效性。
🔬 细节详述
- 训练数据:
- IEMOCAP:约12小时,16kHz,10039条语音,4类情感(合并happy+excited)。
- EMO-DB:535条德语语音,16kHz,7类情感。
- NSPL-CRISE:2999条电话语音,8kHz,5类情感(来自美国自杀预防热线,经IRB批准匿名化标注)。
- 预处理:音频重采样至16kHz(IEMOCAP/EMO-DB)或8kHz(NSPL-CRISE),并进行峰值归一化。批次内填充至最长序列,并使用掩码避免填充影响。
- 损失函数:类别平衡的焦点损失(Focal Loss),聚焦参数γ=2,类别权重α_y ∝ 1/频率(y)。用于缓解类别不平衡问题。
- 训练策略:
- 优化器:AdamW,初始学习率10^{-3},采用余弦衰减调度,权重衰减10^{-4}。
- Batch Size:未明确说明(文中提及“variable per dataset”)。
- 训练步数/轮数:最多50个epoch,采用早停(基于验证集损失)。
- 其他:使用混合精度训练;梯度裁剪范围±1.0;随机种子固定(1234)。10次随机初始化取平均。
- 关键超参数:
- LFST:频率带数F=96,最大阶数O=8,窗长L=1024(奇数),小波带宽常数ksd=5,稳定性常数ε=10^{-12},初始基础周期c1=1.5。
- LAHT:sigmoid斜率γ=8,偏置边界b_{max}=5。
- STEE:基础通道数C=128,时间/频率核大小k_t=9,k_f=5,轴向注意力头数4,局部窗口128步,dropout率0.10。
- 训练硬件:未明确说明。
- 推理细节:未提及特殊解码策略或温度等,即标准的前向传播。
- 正则化/稳定训练技巧:LFST中使用log域累积、指数上限以防溢出;LAHT使用双softplus和tanh约束阈值为正且平滑;FiLM门控使用sigmoid;所有块内使用Dropout(0.10)和Batch Normalization。
📊 实验结果
论文在三个数据集上报告了主要结果(Table 1),并与多种方法进行了对比(Table 2)。核心消融实验在Table 3和Table 6中。
主要结果与SOTA对比
| 数据集 | 方法 | 准确率(%) | F1分数(%) |
|---|---|---|---|
| NSPL-CRISE (D1) | Mirsamadi et al. | 51.3 | 52.1 |
| Li et al. | 68.7 | 69.3 | |
| Chen et al. | 59.6 | 60.2 | |
| Zhao et al. | 67.2 | 67.9 | |
| LFST+STEE (本工作) | 76.9 | 76.6 | |
| IEMOCAP (D2) | Mirsamadi et al. | 63.5 | 63.8 |
| Li et al. | 81.6 | 82.1 | |
| Chen et al. | 64.8 | 65.2 | |
| Zhao et al. | 52.1 | 52.4 | |
| LFST+STEE (本工作) | 87.5 | 86.8 | |
| EMO-DB (D3) | Liu et al. | 89.13 | 89.4 |
| Tuncer et al. | 88.35 | 88.35 | |
| Parlak et al. | 87.2 | N/A | |
| Ancilin et al. | 81.5 | N/A | |
| LFST+STEE (本工作) | 91.4 | 90.4 |
表2(原文Table 2)总结了本方法与先前SOTA方法的对比,在三个数据集上均达到最优。
容量匹配消融实验(与相同STEE编码器下的不同前端对比)
| 前端方法 | NSPL-CRISE | IEMOCAP | EMO-DB |
|---|---|---|---|
| Acc / F1 | Acc / F1 | Acc / F1 | |
| STFT+STEE | 73.1 / 72.7 | 84.8 / 84.0 | 89.0 / 88.2 |
| Wavelet+STEE | 74.6 / 74.6 | 85.4 / 84.8 | 90.1 / 89.5 |
| Fixed superlet+STEE | 74.9 / 74.7 | 86.0 / 85.1 | 90.1 / 89.8 |
| LEAF+STEE | 72.5 / 72.1 | 84.9 / 84.1 | 89.0 / 88.2 |
| LFST+STEE (本工作) | 76.9 / 76.6 | 87.5 / 86.8 | 91.4 / 90.4 |
表3(原文Table 3)显示,在控制下游编码器容量的前提下,LFST前端在所有数据集上均带来稳定提升。
组件消融实验(在NSPL-CRISE数据集上)
| 变体 | 准确率(%) | F1分数(%) |
|---|---|---|
| LFST 去掉 κ(保留LAHT) | 67.2 | 66.9 |
| LFST 去掉 LAHT(保留κ) | 74.3 | 74.1 |
| LFST 完整模型(κ + LAHT) | 76.9 | 76.6 |
表6(原文Table 6)的消融实验表明,相位一致性κ带来了主要的性能提升(+9.7pp F1),LAHT提供了进一步的增益(+2.5pp F1)。
计算复杂度分析
| 模型 | FLOPs (GF) | 峰值显存 (MB) | 延迟 (ms) |
|---|---|---|---|
| STFT + STEE | 0.36 | 18.7 | 2.2 |
| SincNet + STEE | 19.8 | 504.6 | 8.6 |
| LEAF + STEE | 44.5 | 1156.0 | 15.7 |
| Wav2Vec2-feat + STEE | 15.4 | 514.9 | 3.3 |
| LFST + STEE | 201.5 | 4532.8 | 74.9 |
| Wavelet + STEE | 179.6 | 4533.2 | 109.4 |
| FixedSuperlet + STEE | 202.7 | 4533.2 | 75.4 |
附录D中的Table 5显示了不同前端+STEE组合的计算开销(1秒16kHz输入)。LFST+STEE的FLOPs、显存和延迟显著高于STFT、SincNet、LEAF,与Wavelet和FixedSuperlet处于同一数量级。
定性可视化
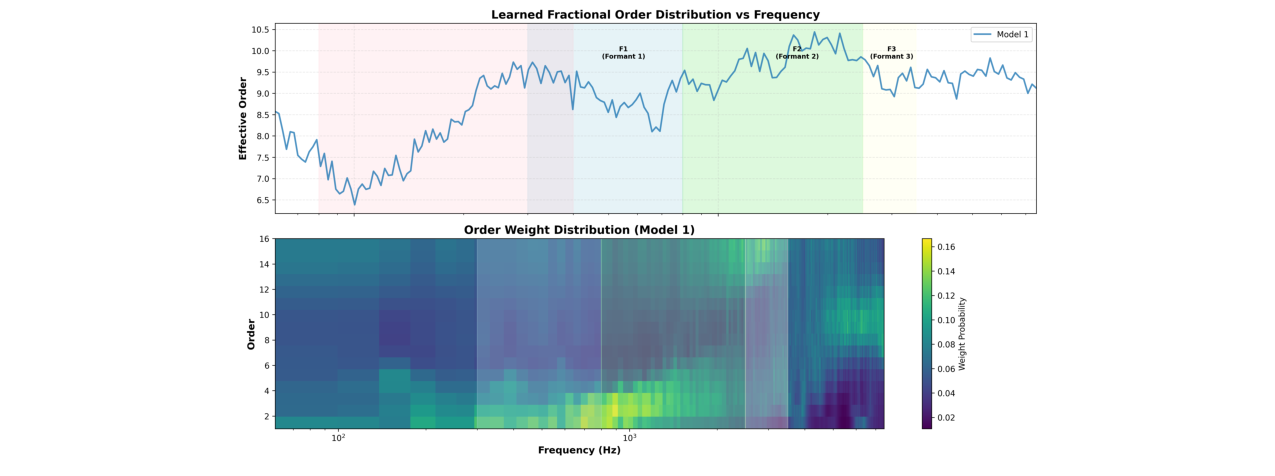
图5(原文图5)展示了LFST学习到的有效阶数oeff(f)随频率的变化(上图),以及完整的阶数权重分布热力图(下图)。结果显示,阶数在频谱上非均匀分配:在基频(F0)区域较低(强调时间精度),在共振峰(F1-F3)区域较高(强调频率分辨率),且权重平滑地分布在多个阶数上,验证了分数阶混合的学习能力。
⚖️ 评分理由
- 学术质量:5.5/7。创新性明确,从信号处理理论出发重新设计可学习TF前端,技术正确性高,数学推导和实现细节严谨。实验充分,在三个数据集上进行了对比和消融,控制了变量。主要不足在于未与最强的大规模预训练模型直接对比,且实验结果缺少方差报告。
- 选题价值:1.5/2。研究处于“可学习音频前端”与“物理启发模型”结合的前沿,对SER和通用音频分析有理论贡献。但SER任务应用相对垂直,且LFST的高计算开销可能限制其在实际场景中的广泛应用,影响了其潜在影响力。
- 开源与复现加成:+0.8/1。论文提供了完整的代码仓库链接,以及极其详细的训练设置、超参数和实现技巧说明,可复现性极强,这是一项显著的优点。