📄 LayerSync: Self-aligning Intermediate Layers
#音频生成 #多模态模型 #扩散模型 #自监督学习 #生成模型
✅ 7.5/10 | 前25% | #音频生成 | #扩散模型 | #多模态模型 #自监督学习
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.8 | 置信度 高
👥 作者与机构
- 第一作者:Yasaman Haghighi(Ecole Polytechnique Fédérale de Lausanne (EPFL))
- 通讯作者:Alexandre Alahi(Ecole Polytechnique Fédérale de Lausanne (EPFL))
- 作者列表:Yasaman Haghighi(EPFL)、Bastien van Delft(EPFL)、Mariam Hassan(EPFL)、Alexandre Alahi(EPFL)
💡 毒舌点评
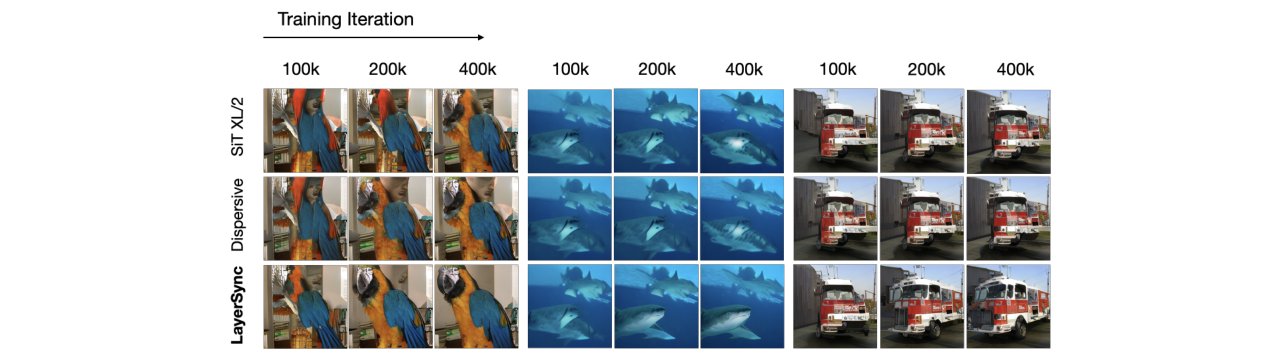
这篇论文的亮点在于其极致的“自给自足”哲学——用模型自己最强的层当老师,去教最弱的层,完全抛开了笨重的外部模型(如DINOv2),这个想法既优雅又实用,在多个模态上都跑通了,训练加速效果非常惊人。但短板是,这种“强层指导弱层”的启发式规则选择(比如跳过最后20%的层)感觉有点“经验主义”,理论上的解释(良性循环)目前更多是一种假设,缺乏更深层次的数学证明或机理分析,让人忍不住想问:这种对齐会不会在后期“扼杀”特征多样性,或者让模型过早陷入某种次优的表示空间?
🔗 开源详情
- 代码:论文中提供了代码仓库链接:
https://github.com/vita-epfl/LayerSync.git。 - 模型权重:论文中未提及公开预训练模型权重。
- 数据集:使用的是公开数据集(ImageNet, MTG-Jamendo, HumanML3D, CLEVRER, MixKit),论文中未说明获取方式,但这些是常见公开数据集。
- Demo:论文中未提及在线演示。
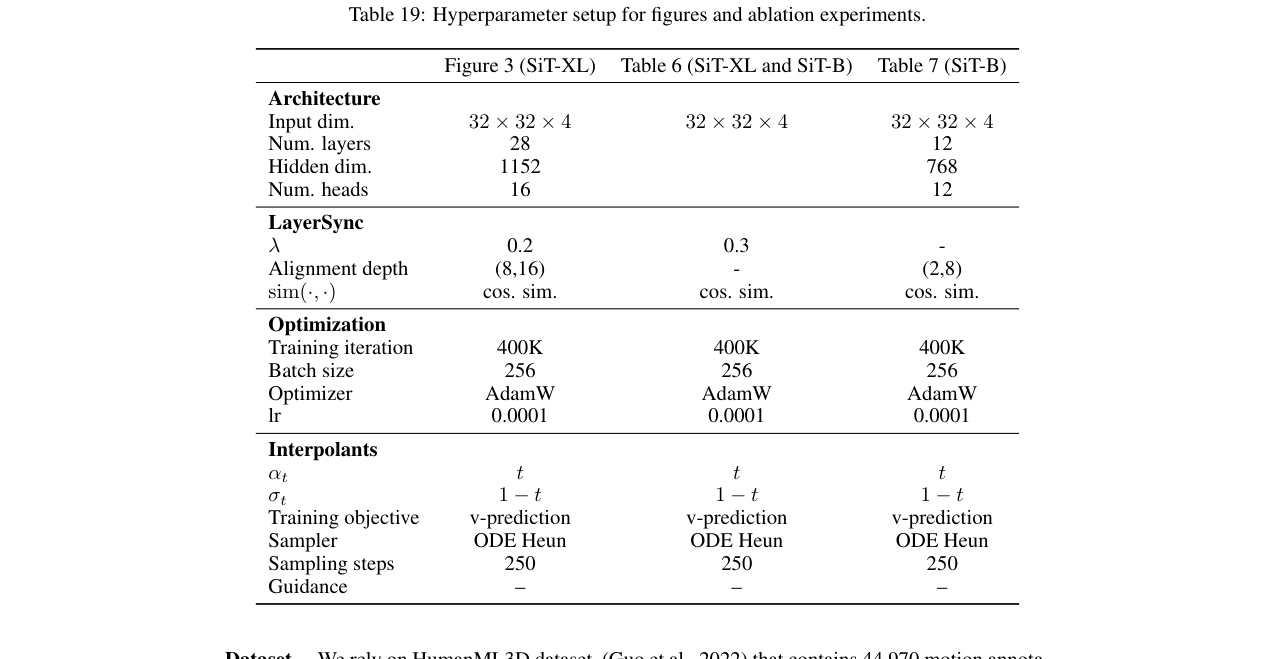
- 复现材料:非常充分。论文附录(Section L, M)详细列出了所有实验的超参数设置(表18, 19)、训练硬件、采样器配置、评估指标细节等。算法伪代码(Algorithm 1)也在附录中给出。
- 依赖的开源项目:主要依赖于SiT(Ma et al., 2024)作为基础模型架构,以及Stable Diffusion的VAE用于图像编码。
📌 核心摘要
这篇论文旨在解决使用外部大型预训练模型(如视觉语言模型)来引导扩散模型中间层表示时所带来的计算开销大、数据依赖强、跨模态迁移难的问题。作者提出了一种名为LayerSync的自包含、即插即用的正则化方法。其核心思想是:扩散模型内部不同层学习的特征质量存在异质性,深层的特征语义更丰富。因此,可以利用模型自身的这些深层强特征作为“内在引导信号”,通过最大化浅层弱特征与深层强特征之间的相似度,来正则化和提升浅层特征的学习。与已有的外部引导方法(如REPA)相比,LayerSync完全不依赖额外的模型或数据,计算开销几乎为零;与同属自包含范畴的Dispersive Loss方法相比,它提供了更具方向性的学习信号。实验表明,LayerSync在图像生成任务上可将训练加速超过8.75倍(FID改善23.6%),并在音频、人类动作和视频生成任务上均一致提升了生成质量和训练效率。此外,该方法还改善了模型各层的内部表征质量。其局限性包括:关键的层选择策略依赖启发式规则,且“良性循环”的理论支撑有待加强。
| 任务 | 数据集 | 指标 | 基线 (SiT-XL/2) | + LayerSync | 提升 |
|---|---|---|---|---|---|
| 图像生成 | ImageNet 256x256 | FID↓ (80 Epochs) | 17.97 | 11.24 | 37.5% |
| 图像生成 | ImageNet 256x256 | FID↓ (800 Epochs) | 8.99 | 6.87 | 23.6% |
| 音频生成 | MTG-Jamendo | FAD↓ (650 Epochs) | 0.251 | 0.199 | 20.7% |
| 人类动作生成 | HumanML3D | FID↓ (600K Iters) | 0.5206 | 0.4801 | 7.7% |
🏗️ 模型架构
LayerSync本身不是一个新模型,而是一个应用于现有扩散Transformer(如SiT)的正则化框架。它被集成到标准的扩散模型训练流程中,不改变模型的主体架构。
基础模型架构:论文主要基于SiT(Scalable Interpolant Transformer)架构。SiT将扩散/流匹配过程重新定义为随机插值,其核心是用一个Transformer网络
v_θ(x_t, t)预测从噪声到数据的速度场。模型输入是加噪后的潜在表示x_t和时间步t,输出是预测的速度。LayerSync的集成:LayerSync作为一个额外的损失项,附加在标准的流匹配损失(公式1)之上,总损失为
L = L_velocity + λ * L_LayerSync(公式3)。它在训练时提取模型内部两个不同层(一个浅层k,一个深层k')的特征表示f^k_θ(x)和f^{k'}_θ(x),并计算它们之间归一化后的相似度(如余弦相似度)的负均值作为损失。stopgrad操作确保只对浅层特征进行反向传播优化,而将深层特征视为固定目标。这个过程不增加任何额外的前向/反向传播开销,因为特征提取发生在标准的前向传播中。
Transformer内部结构观察:论文通过分析发现,扩散Transformer在收敛后,其内部块(Transformer Block)会自然形成高相关的功能分组(图2)。这为LayerSync的层选择提供了依据。
层选择策略:这是一个关键的设计点。策略基于三个原则:(1) 排除最后约20%的解码块;(2) 排除最前面的局部特征块;(3) 确保被对齐的层之间有足够的距离(如SiT-XL中隔8个块)。这种启发式策略在实验中被证明是稳健的,即使随机选择层也能获得提升,但遵循此策略能获得最优性能。
核心数据流:输入数据 -> 扩散Transformer -> 提取指定浅层和深层特征 -> 计算LayerSync损失(基于相似度)-> 与速度预测损失加权求和 -> 反向传播更新模型参数。深层特征通过stopgrad处理,不接收梯度。
💡 核心创新点
- 自包含的内在引导:摒弃了依赖DINOv2、VLM等外部强大模型的范式,转而挖掘模型自身深层表示的引导潜力,实现了零额外参数和数据依赖、极低计算开销的训练加速,大大增强了方法的通用性和实用性。
- 基于表示层次的层间对齐损失:明确利用了扩散模型中间表示质量随深度增加而提高的层次性特点,通过一个简单的相似度最大化损失,将弱特征“拉向”强特征,为优化提供了清晰、直接的信号,优于仅鼓励特征分散(如Dispersive Loss)的无导向正则化。
- 良性循环假说与结构正则化:提出了一个引人深思的假说:增强早期特征不仅能直接提升它们,还能为后续层提供更好的输入,从而促使整个特征层次结构进行更高效的优化,形成“良性循环”。实验证据(如表征质量评估和结构变化)支持了这一点。
- 跨模态的通用性与有效性:作为一个与数据模态无关的纯正则化方法,LayerSync在图像、音频、人类动作、视频生成等多个差异巨大的领域都展示了稳定的性能提升,这是先前外部引导方法难以做到的,证明了其作为基础训练技巧的广泛适用性。
🔬 细节详述
- 训练数据:图像:ImageNet (1.28M图像)。音频:MTG-Jamendo (55k歌曲,随机采样10秒片段)。动作:HumanML3D (44.9k动作标注)。视频:CLEVRER (概念验证) 和 MixKit (微调)。
- 损失函数:主损失:流匹配速度预测损失(公式1)。正则化损失:LayerSync损失(公式2),即两个层归一化特征间的负余弦相似度均值。超参数
λ控制权重。 - 训练策略:优化器:AdamW。学习率:1e-4(恒定)。Batch Size:图像实验为256(4xGH200)。训练长度:图像主实验为80-800个Epoch;音频465-650 Epoch;动作600K迭代。
- 关键超参数:
- 图像:SiT-XL/2 (28层,隐藏维度1152,16头),
λ=0.2, 对齐层(8, 16)。 - 音频:SiT-XL (28层,修改适配音频),对齐层
(8, 21)。 - 动作:8层Transformer,对齐层
(3, 6)。
- 图像:SiT-XL/2 (28层,隐藏维度1152,16头),
- 训练硬件:主要使用NVIDIA GH200 GPU,图像实验使用4或16卡,全局Batch Size 1024。
- 推理细节:图像使用ODE Heun采样器(250步)或SDE Euler采样器。音频、动作、视频使用对应的扩散/流模型采样器。
- 正则化技巧:LayerSync本身就是一种结构正则化技巧。此外,实验中可能使用了标准的Dropout等,但未详细说明。
📊 实验结果
主要基准结果(图像生成,ImageNet 256x256):
| 模型 | 训练轮数 | FID↓ | IS↑ | 备注 |
|---|---|---|---|---|
| SiT-XL/2 (基线) | 800 | 8.99 | - | 基线 |
| + Dispersive Loss | 800 | 8.08 (-10.1%) | - | 前最佳自包含方法 |
| + LayerSync | 160 | 8.29 | - | 训练加速8.75倍 |
| + LayerSync | 800 | 6.87 (-23.6%) | - | 大幅超越基线 |
| SiT-XL/2 (SDE) | 1400 | 8.3 | 270.3 | 使用SDE采样器 |
| + LayerSync | 800 | 6.32 (-23.9%) | - | SDE采样,新SOTA |
与其他方法的系统对比(带CFG):
| 方法 | 训练轮数 | FID↓ | 备注 |
|---|---|---|---|
| SiT-XL/2 | 1400 | 2.06 | 基线 |
| + REPA (外部引导) | 800 | 1.80 | |
| + REPA + CFG调度* | 800 | 1.42 | |
| + Dispersive Loss | ≥1200 | 1.97 | |
| + LayerSync | 800 | 1.89 | 自包含方法最佳 |
| + LayerSync + CFG调度* | 800 | 1.49 | 接近外部引导方法 |
关键消融与分析实验:
- 层选择鲁棒性:对SiT-XL进行随机层配对实验,FID的标准差仅为0.8,证明了方法对超参数不敏感。
- 表征质量分析:对比FID相似的基线模型(训练1400轮)和LayerSync模型(训练160轮),后者在分类(+32.4%)、分割(+63.3%)和DINOv2对齐(+88.2%)上表现更好,表明LayerSync从根本上优化了内部表征结构,而不仅仅是加速收敛。
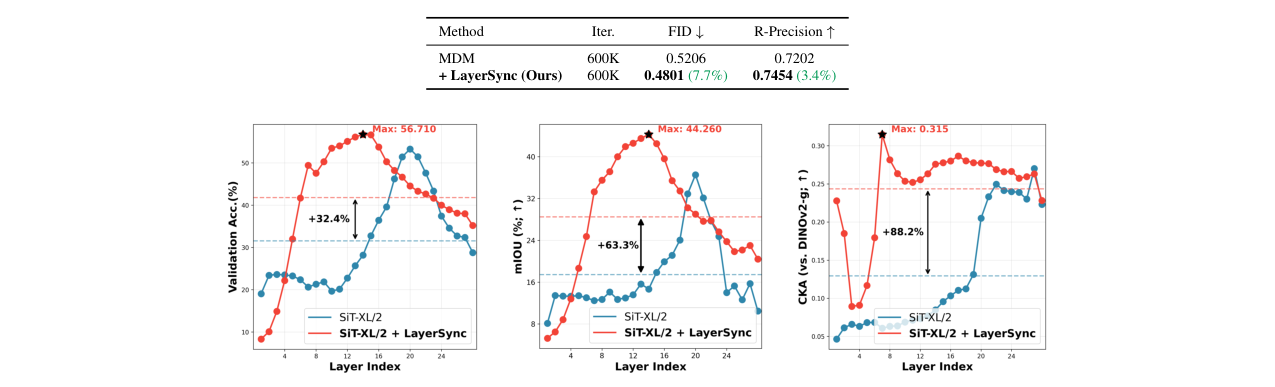
- 跨模态结果:
- 音频生成:在MTG-Jamendo数据集上,FAD从0.251降至0.199(改善20.7%)。
- 人类动作生成:在HumanML3D数据集上,FID改善7.7%,R-Precision改善3.4%。
- 视频生成(附录):在CLEVRER(从头训练)和MixKit(微调)上,FVD分别从265.50降至120.13,从321.84降至304.68。
⚖️ 评分理由
- 学术质量:6.0/7。创新点清晰且实用,将“内部自引导”想法工程化并验证有效。实验设计严谨,覆盖多领域,对比充分。技术实现正确,但理论机制(如“良性循环”)的解释深度不足,部分结论(如对层选择的“最佳”策略)缺乏严格的理论证明。
- 选题价值:1.5/2。解决扩散模型训练效率的关键痛点,提出的自包含方案具有高通用性和实用价值。对音频生成领域有直接应用,其内部表征学习的思想也对相关任务有启发。
- 开源与复现加成:+0.8/1。提供了代码仓库链接,论文附录包含大量训练细节、超参数、评估协议和消融实验设置,极大便利了复现。