📄 Latent Speech-Text Transformer
#语音识别 #语音合成 #语音大模型 #预训练 #自回归模型
✅ 7.0/10 | 前25% | #语音识别 #语音合成 | #预训练 | #语音识别 #语音合成
学术质量 7.0/7 | 选题价值 1.8/2 | 复现加成 0.8 | 置信度 高
👥 作者与机构
- 第一作者:Yen-Ju Lu ( Johns Hopkins University, Center for Language and Speech Processing ),工作于 Meta 期间完成。
- 通讯作者:Srinivasan Iyer, Duc Le ( Meta Superintelligence Labs )
- 作者列表:
- Yen-Ju Lu ( Johns Hopkins University, CLSP )
- Yashesh Gaur ( Meta Superintelligence Labs )
- Wei Zhou ( Meta Superintelligence Labs ),工作于 Meta 期间完成。
- Benjamin Muller ( Meta Superintelligence Labs )
- Jesus Villalba ( Johns Hopkins University, CLSP )
- Najim Dehak ( Johns Hopkins University, CLSP )
- Luke Zettlemoyer ( Meta Superintelligence Labs )
- Gargi Ghosh ( Meta Superintelligence Labs )
- Mike Lewis ( Meta Superintelligence Labs )
- Srinivasan Iyer ( Meta Superintelligence Labs )
- Duc Le ( Meta Superintelligence Labs )
💡 毒舌点评
亮点在于精准识别了语音-文本模型因序列长度悬殊导致的“计算不公平”问题,并借鉴了文本领域的字节级Transformer思想,设计出一套从静态、对齐到课程学习的渐进式语音分块方案,有效提升了模型效率和跨模态性能。短板是部分最有效方案(如对齐分块)在推理时仍依赖外部对齐模型(Wav2Vec2+CTC),课程学习虽缓解了此问题,但完全无对齐依赖的端到端训练方案更具吸引力;此外,论文聚焦于预训练和补全任务,对更复杂的生成、理解或实时对话任务的探索尚待深入。
🔗 开源详情
- 代码:提供代码仓库链接:
https://github.com/facebookresearch/lst。 - 模型权重:论文中未提及是否公开预训练模型权重。
- 数据集:使用了多个公开数据集(LibriLight, People’s Speech, Multilingual LibriSpeech, Spotify),并在附录中说明了各自的数据许可。论文中未提供统一的数据获取链接。
- Demo:论文中未提及在线演示。
- 复现材料:提供了详尽的训练细节(数据集构成、比例、预处理、交错数据构造方法)、模型架构配置(表7)、优化器设置、训练硬件、超参数以及消融实验设置。附录包含大量补充细节。
- 引用的开源项目/模型:Llama 2 (tokenizer), HuBERT (speech tokenizer), Wav2Vec2+CTC (alignment), HiFi-GAN (vocoder), Kokoro TTS (评估用), Whisper (CER计算), SentencePiece (BPE), BLT (架构灵感)。
📌 核心摘要
- 解决的问题:现有的自回归语音-文本模型因语音token序列远长于文本,导致计算开销巨大,严重阻碍了模型的扩展效率和跨模态对齐效果。
- 方法核心:提出Latent Speech-Text Transformer (LST)。其核心是一个分块机制,将密集的语音token聚合成更高层次、信息更密集的“语音块”(latent speech patches)。全局Transformer则在交错的文本token和语音块序列上进行自回归建模。
- 创新之处:相比直接对语音token建模或尝试BPE压缩(效果不佳),LST通过一个轻量级的分块编码器和解码器,动态地将语音片段压缩成块。创新性地设计了多种分块策略(静态、对齐、混合、课程),其中课程分块是关键,它在训练早期利用对齐信息获得语义一致的块,后期过渡到静态分块,使模型摆脱推理时对对齐工具的依赖。
- 实验结果:在故事补全基准测试上,LST(特别是课程分块)在计算控制和数据控制设置下均显著优于基线。例如,在计算控制训练中,语音HellaSwag准确率绝对提升最高达6.5%,文本任务也同步提升。模型扩展性分析(从420M到1.8B参数)表明,LST的收益随模型规模增长而扩大。在下游任务中,LST稳定了ASR适应过程,并在ASR和TTS推理中将有效序列长度缩短约4倍,降低了计算成本。可视化分析显示,对齐分块能产生语义连贯的语音块嵌入。
- 实际意义:为构建更高效、可扩展的统一语音-文本基础模型提供了一条切实路径,能显著降低训练和推理成本,同时提升模型的跨模态理解与生成能力。
- 主要局限性:研究局限于半双工(交替对话)建模,未涉及全双工实时对话;核心预训练阶段未探索指令微调;部分最优分块策略(如对齐)在训练时仍依赖外部对齐模型。
🏗️ 模型架构
LST的整体架构旨在将离散的语音token和文本token统一建模,但通过分块机制显著提升语音建模的效率。其流程如下:
- 输入:交错的文本token序列和语音token序列。文本token使用Llama 2 tokenizer(32K词表),语音token使用HuBERT tokenizer(501个离散码本,25Hz)。
- 分块编码:对于输入的语音token序列,使用分块编码器(Patch Encoder) 根据特定策略(静态、对齐等)将其划分为多个块。每个块包含若干连续的语音token。分块编码器是一个轻量级模块,使用滑动窗口自注意力和交叉注意力层,将块内所有语音token的表示聚合为一个单一的“语音块表示”(latent patch embedding)。
- 全局建模:将文本token的嵌入表示与生成的语音块表示一起,输入到一个深度的全局Transformer(Global Transformer) 中。该Transformer使用带旋转位置编码(RoPE)的块因果注意力机制,自回归地建模这个交错的、信息密度更均衡的序列。这是模型计算开销的主要部分,由于输入序列长度缩短(特别是语音部分),效率得到提升。
- 分块解码:全局Transformer的输出被送入分块解码器(Patch Decoder)。解码器是一个轻量级Transformer,其每一层包含因果自注意力(关注过去512个token)和交叉注意力。交叉注意力以当前token的隐状态为查询(Query),以之前生成的语音块表示和文本token表示为键值(Key/Value),从而将高层块信息与底层的token预测结合起来。
- 输出:解码器最终预测下一个语音token的概率分布,用于自回归生成语音token序列。
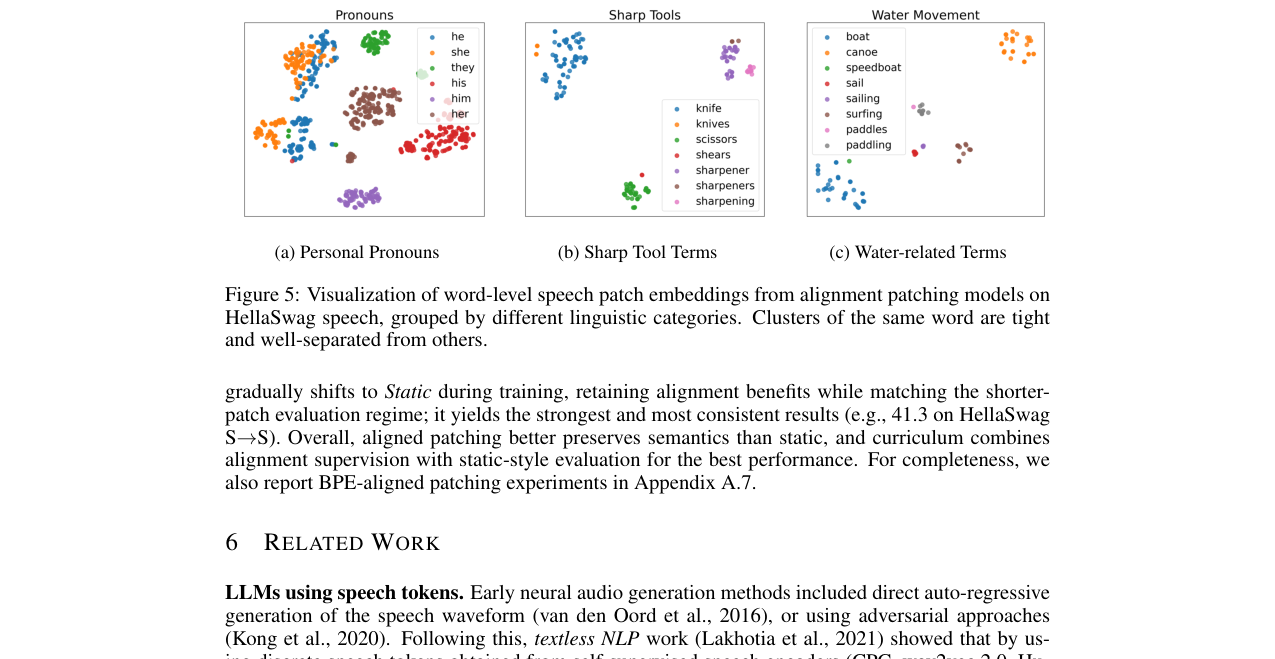
图2:LST模型架构图。显示了BPE文本token和HuBERT语音token如何被编码到共享的潜在空间。分块编码器将局部语音片段压缩为块表示,这些块与文本token一起被全局Transformer处理。分块解码器从潜在表示中预测未来的语音token,实现了跨模态的对齐与迁移。
分块策略(Patching Strategies)详解:这是LST的核心组件。
- 静态分块:将语音序列分割成固定长度(如4个token)的非重叠块,不依赖任何对齐信息。简单、鲁棒,但语义完整性可能不足。
- 对齐分块:利用Wav2Vec2+CTC模型获得文本词/BPE边界对应的时间戳。将每个词(或BPE)对应的语音帧划分为一个块,独立的静音段也各自成块。这能产生语义对齐更精确的块,但推理时需要辅助对齐模型。
- 课程分块:这是关键创新。在训练过程中,动态地、逐步地从对齐分块过渡到静态分块。训练早期(概率P=1)完全使用对齐分块;训练中期,以递减的概率使用对齐分块;训练后期(概率P=0)完全使用静态分块。这使得模型在训练初期能受益于对齐信息带来的良好初始化,而在推理时可以完全使用简单快速的静态分块,摆脱对齐工具的依赖。
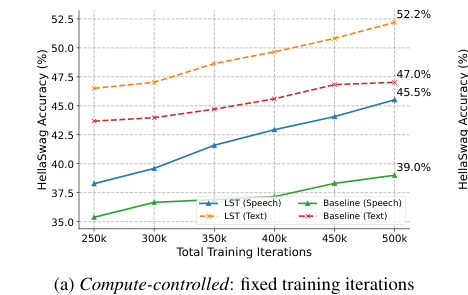
图3:对齐与分块方法示意图。(a)展示了静态分块(固定长度)与对齐分块(使用Wav2Vec2+CTC边界)的对比。(b)展示了如何通过对齐将音频信号与对应的文本对齐。
💡 核心创新点
- 引入“语音块”作为自回归建模单元:针对语音序列过长的核心瓶颈,LST创新性地将语音token聚合为更高层次的“块”,这与纯文本模型处理字节的BLT思想异曲同工,但专门适配了语音-文本联合建模的场景。此举对齐了两种模态的序列长度,从根本上提升了计算效率和跨模态对齐的可能性。
- 设计多样化的分块策略及课程学习范式:超越简单的固定长度分块,提出了语义驱动的对齐分块和混合分块。更重要的是,提出了课程分块(Curriculum Patching),解决了对齐分块依赖外部工具的痛点,实现了“训练时借助对齐,推理时无需对齐”的平滑过渡,是方法论上的重要贡献。
- 构建端到端的分块-全局-解码架构:设计了完整的、端到端可训练的分块编码器-全局Transformer-分块解码器的架构。编码器负责压缩,解码器负责精细重建,全局Transformer专注于高效的块级建模。这种分层设计在保持生成质量的同时,大幅减少了自回归步数。
- 在多个维度验证收益的全面性:不仅验证了在固定计算/数据预算下的性能提升,还深入分析了计算最优(Compute-Optimal)的扩展行为,证明收益随模型规模增长而扩大,这对于大规模预训练至关重要。同时验证了在下游ASR/TTS任务中的迁移收益。
🔬 细节详述
- 训练数据:
- 文本数据:来自Llama 2预训练集的一个子集,共计1.8T tokens。
- 语音数据:四个公开数据集:LibriLight (60k小时), People’s Speech (30k小时), Multilingual LibriSpeech (50k小时), Spotify Podcast (60k小时)。语音被量化为HuBERT token (501-entry codebook at 25Hz)。所有语音数据都通过Wav2Vec2+CTC获得了词级别的强制对齐。
- 交错数据构造:在预训练时,从平行的语音-文本数据中,随机选择文本片段替换对应的语音片段,并用特殊模态标记
<t>和<s>分隔,动态生成交错序列。 - 数据比例:训练时,语音token约占总训练数据的33%,文本token占67%。
- 损失函数:标准的自回归下一个token预测(NTP)负对数似然损失。全局Transformer和分块解码器都使用此损失进行训练,整体端到端优化。
- 训练策略:
- 优化器:AdamW (β1=0.9, β2=0.95, weight decay=0.1)。
- 学习率:初始4e-4,使用余弦衰减,包含2000步的warmup,最小比例为0.01。
- 批大小:对于1B模型,在32张H100 GPU上训练,每GPU batch size为4,序列长度4096,总batch size约0.5M units。
- 精度:使用bfloat16混合精度训练。
- 梯度处理:梯度裁剪为1.0,未使用dropout。
- 训练时长:1B模型训练200k步,约17小时。
- 关键超参数与架构:
- 全局Transformer:25层,隐藏维度2048,16个注意力头,使用RoPE (θ=5e5)。
- 分块编码器:1层,隐藏维度1024,16个注意力头,窗口大小512。
- 分块解码器:9层,隐藏维度1024,16个注意力头,自注意力窗口512。
- 语音块大小:静态分块通常为4个HuBERT token。
- 训练硬件:1B模型在32张NVIDIA H100 GPU上完成训练,约17小时。
- 推理细节:
- ASR任务:通过微调预训练模型实现。使用标准自回归解码。
- TTS任务:同样通过微调实现。使用分块解码器,自回归步数减少约4倍。
- 分块策略:课程分块模型在推理时统一使用静态分块,无需对齐模型。
📊 实验结果
实验在三个故事补全基准测试上进行:HellaSwag (HS)、StoryCloze (SC)、TopicStoryCloze (TSC),评估语音到语音(S→S)和文本到文本(T→T)两种模式。
主要对比结果(计算控制设置,表3): 在固定训练迭代次数的设置下,LST(特别是课程分块)全面优于基线。
| 模型 | 语音Tokens (B) | 文本Tokens (B) | HS S→S | HS T→T | SC S→S | SC T→T | TSC S→S | TSC T→T |
|---|---|---|---|---|---|---|---|---|
| Base SpeechLLM | 87 | 175 | 39.0 | 47.0 | 59.1 | 67.8 | 87.5 | 95.7 |
| BPE SpeechLLM | 95 | 190 | 38.0 | 47.5 | 58.0 | 66.4 | 87.0 | 93.5 |
| LST (Static) | 108 | 217 | 44.3 | 51.1 | 60.5 | 70.3 | 87.7 | 96.2 |
| LST (Aligned) | 108 | 217 | 42.7 | 51.7 | 60.4 | 70.4 | 86.6 | 95.7 |
| LST (Mixed) | 108 | 217 | 44.3 | 51.9 | 61.4 | 70.8 | 88.0 | 95.9 |
| LST (Curriculum) | 108 | 217 | 45.5 | 52.2 | 61.2 | 71.6 | 87.9 | 96.1 |
数据控制设置结果(表4): 固定语音和文本token总量,LST处理的“块”数更少,因此在相同数据下更高效。
| 模型 | 计算节省比例 | HS S→S | HS T→T | SC S→S | SC T→T | TSC S→S | TSC T→T |
|---|---|---|---|---|---|---|---|
| Base SpeechLLM | - | 40.2 | 49.6 | 60.2 | 69.1 | 87.5 | 95.2 |
| BPE SpeechLLM | 8.2% | 39.4 | 48.4 | 58.3 | 66.3 | 86.5 | 93.9 |
| LST (Static) | 19.3% | 44.3 | 51.1 | 60.5 | 70.3 | 87.7 | 96.2 |
| LST (Curriculum) | 19.7% | 45.5 | 52.2 | 61.2 | 71.6 | 87.9 | 96.1 |
规模扩展结果(图1与图4):
图1:LST与基线在HellaSwag故事补全任务上的性能对比,分为(a)计算控制设置(固定训练迭代次数)和(b)数据控制设置(固定数据量)。LST(语音和文本)均优于基线。
图4:扩展行为分析。(a)在420M到1.8B参数的计算最优训练中,LST的收益随模型规模增长而扩大。(b)在7B模型、低于最优token量的子最优设置下,LST也展现出更快的收敛和更高的准确率。
下游任务结果(表5):
| 任务 | 模型 | 迭代次数 | clean WER (%)↓ | other WER (%)↓ | 上下文单位 | 生成单位 |
|---|---|---|---|---|---|---|
| ASR | Baseline | 1k | 140 | 202 | 1.0× | – |
| Baseline | 2k | 44.7 | 73.2 | |||
| Baseline | 4k | 20.7 | 42.4 | |||
| LST | 1k | 6.8 | 10.4 | 0.25× | – | |
| LST | 2k | 6.0 | 13.3 | |||
| TTS | Baseline | 20k | 14.1 CER | 15.1 CER | – | 1.0× |
| LST | 20k | 14.1 CER | 16.2 CER | – | 0.25× |
关键消融与分析:
- 分块策略对比(表6):在相近平均块大小下,课程分块(sil sep.)在HellaSwag S→S上达到41.3%,优于静态分块(40.5%)和对齐分块(39.9%)。
- 块嵌入可视化(图5):对齐分块产生的块嵌入能形成清晰的词级别聚类,表明其成功捕捉了语义信息。
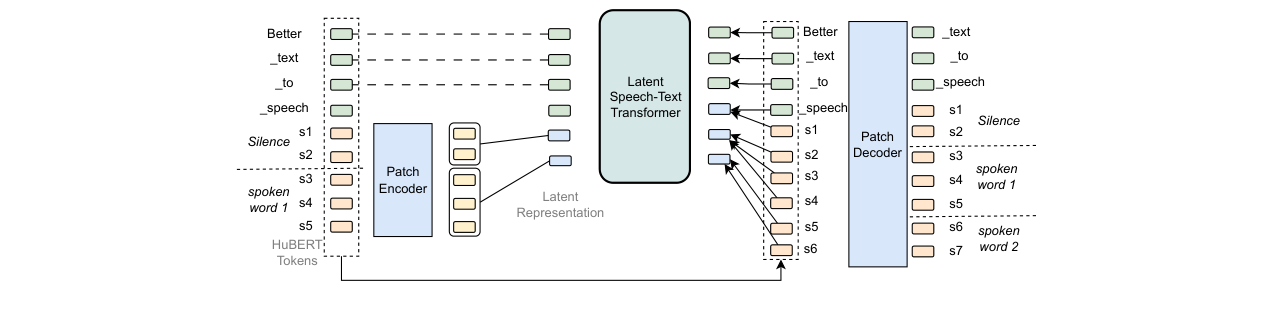
图5:从对齐分块LST模型中提取的词级语音块嵌入的t-SNE可视化图。同一词的嵌入形成紧密的簇,不同词的簇分离良好,证实了块表示的语义一致性。
⚖️ 评分理由
- 学术质量:7.0/7:论文针对一个公认的重要问题(语音序列过长)提出了一个新颖且有效的解决方案(语音块化)。方法设计(分块机制、课程学习)具有创新性,技术细节描述清晰。实验评估非常全面,涵盖了多种设置(计算控制、数据控制、规模扩展)、多个基准测试和下游任务,提供了强有力的证据支持其结论。结论的得出基于扎实的实验数据。扣分点在于核心思想(将长序列压缩成更高级单元)并非首次提出(如视觉patch、文本字节块),其在语音-文本领域的具体实现和课程学习是主要贡献。
- 选题价值:1.8/2:研究直接面向语音大模型规模化中的核心效率瓶颈,是当前该领域的重要前沿。提升模型效率和跨模态对齐能力对实际应用(如更快的语音对话系统、更低的训练成本)有显著价值。与音频/语音研究者高度相关。略扣分是因为研究场景仍限于预训练和补全,未涉及更复杂的多轮对话或实时交互。
- 开源与复现:0.8/1:论文提供了明确的代码仓库链接(https://github.com/facebookresearch/lst),并详细说明了数据集(包括许可证)、超参数、训练硬件配置、分块策略等关键细节,使得复现成为可能。主要不足在于未提及是否公开预训练模型权重,这降低了直接验证和下游研究的便捷性。