📄 LadderSym: A Multimodal Interleaved Transformer for Music Practice Error Detection
#音乐理解 #多模态模型 #端到端 #音乐信息检索
🔥 8.0/10 | 前25% | #音乐理解 | #多模态模型 | #端到端 #音乐信息检索
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 1.0 | 置信度 高
👥 作者与机构
- 第一作者:Benjamin Shiue-Hal Chou(Purdue University)
- 通讯作者:未说明(论文未明确指定,但联系邮箱主要为{作者名}@purdue.edu,可能为共同指导)
- 作者列表:
- Benjamin Shiue-Hal Chou(Purdue University)
- Purvish Jajal(Purdue University)
- Nick John Eliopoulos(Purdue University)
- James C. Davis(Purdue University)
- George K. Thiruvathukal(Loyola University Chicago)
- Kristen Yeon-Ji Yun(Purdue University)
- Yung-Hsiang Lu(Purdue University)
💡 毒舌点评
亮点:论文将“音乐练习错误检测”这一序列比较问题,巧妙地转化为一个多模态编码与解码任务,并且通过架构设计(Ladder编码器)和输入表示(符号提示)两个层面,针对性地解决了之前方法在对齐能力和输入歧义上的痛点,设计思路清晰且有效。短板:符号提示策略在更简单的CocoChorales-E数据集上(尤其对Extra Note)带来的增益有限,甚至略有下降,表明这种多模态融合的收益可能与任务复杂度强相关;此外,模型对大幅节奏变化和复杂和弦遮蔽的处理仍有明显局限。
🔗 开源详情
- 代码:论文提供了代码仓库链接:https://github.com/ben2002chou/LadderSYM。
- 模型权重:论文中未明确提及是否公开预训练模型权重。代码仓库可能包含。
- 数据集:使用了两个公开的合成数据集(MAESTRO-E, CocoChorales-E)。此外,论文作者新收集并发布了包含真实初学者错误的评估数据集,可通过论文或代码仓库获取详情。
- Demo:论文提到提供了演示示例页面(“our demo page”),但未给出具体URL。
- 复现材料:论文在附录中提供了完整的训练细节(Table 7)、超参数设置、评估指标定义、种子管理策略(A.12节)以及模型输入/输出的详细说明(A.2-A.3节),复现材料非常充分。
- 论文中引用的开源项目:主要基于MT3(音乐转录模型)、AST(音频频谱Transformer)、T5(文本到文本转换Transformer)以及前作Polytune的代码进行开发。具体依赖了EfficientTTMs(MIT许可)和Polytune(BSD 3-Clause,非商业)的部分代码。
- 论文中未提及更广泛的开源计划(如部署工具、API等)。
📌 核心摘要
本文针对音乐练习错误检测任务中现有方法存在的两大局限:后期(late fusion)设计限制了音频流间的细粒度对齐能力,以及仅用音频表示乐谱会引入频率歧义(尤其在同时演奏多个音符时),提出了名为LadderSym的新方法。该方法核心包含两部分:1)一个名为Ladder的交错Transformer编码器,它采用双流结构,并在每层之前交替进行跨流对齐(通过交叉注意力)和独立的模态内特征提取,以实现灵活的对齐和专门化表示学习;2)将乐谱的符号化表示(符号token序列)作为提示(prompt)输入给T5解码器,与编码器输出的音频上下文结合,以提供更明确的参考信息。在MAESTRO-E和CocoChorales-E两个合成数据集上的实验表明,LadderSym显著超越了前SOTA(Polytune)。在挑战性的MAESTRO-E数据集上,Missed Note的F1分数从26.8%提升至56.3%(翻倍以上),Extra Note的F1从72.0%提升至86.4%。在新收集的真实初学者演奏数据集上,LadderSym也表现出更好的泛化能力。该工作的实际意义在于为音乐学习者提供更精确的反馈工具,并为序列比较任务(如强化学习评估、技能评估)提供了可借鉴的架构设计原则。主要局限性包括:密集和弦声学遮蔽下的漏音检测仍具挑战;音符跨越上下文窗口边界时可能产生错误;以及模型不适用于处理与原谱节奏差异过大的演奏。
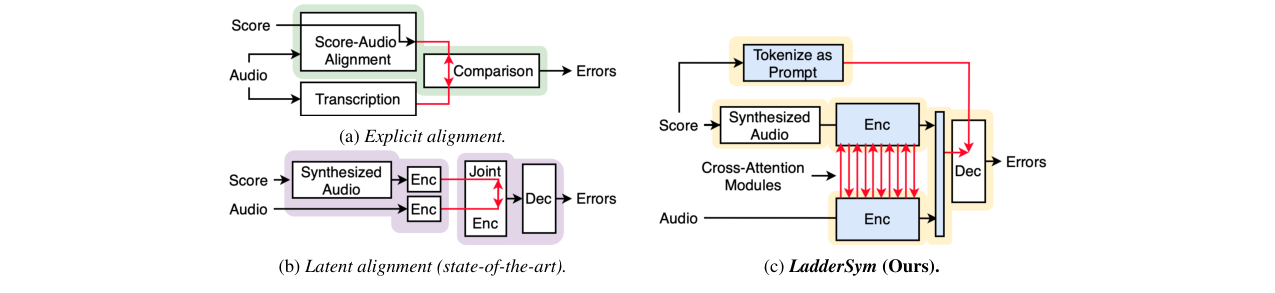
🏗️ 模型架构
LadderSym的整体架构是一个多模态的编码器-解码器模型,旨在将练习音频与参考乐谱(音频+符号)进行比较,并输出一个标记了“正确”、“漏音”、“错音”或“错音”的音符序列。其完整流程如下:
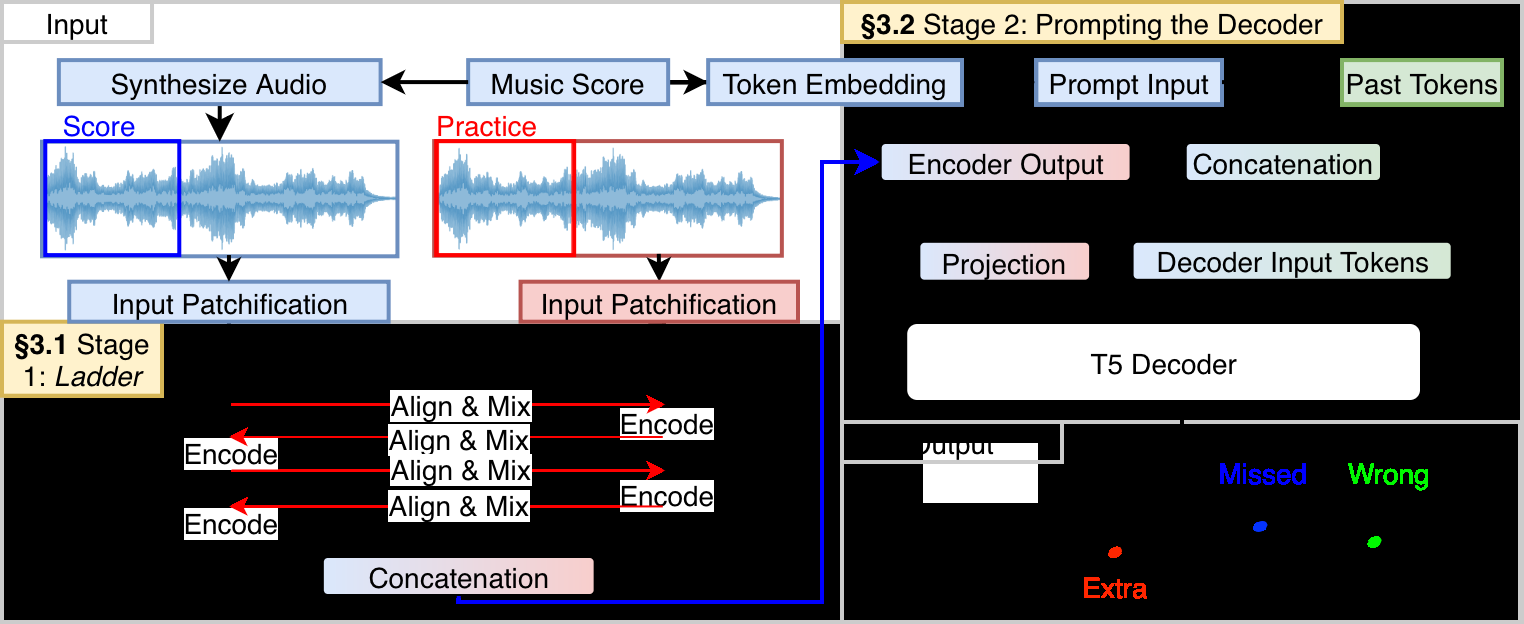
输入:
- 参考乐谱音频:乐谱(如MIDI)合成的音频,经过STFT转换为声谱图,再通过ViT patch embedding转换为token序列(
Pref)。 - 练习音频:学习者演奏的录音,同样转换为token序列(
Pprac)。 - 符号乐谱提示:同一乐谱的MIDI符号,被token化为一个包含时间、音高、标签(初始均为“正确”)的序列,作为解码器的提示。
核心组件与数据流:
- Ladder编码器:
- 这是一个双流、交错对齐的Transformer编码器,其核心思想是解耦特征提取与跨流对齐。
- 每一层处理都包含两个顺序步骤:
a. 对齐与融合:首先,一个流(如
Pref)通过交叉注意力(CA)关注另一个流(Pprac)的当前表示,并将结果加性融合到自身表示中(P(i+1)_ref = ViTref( P(i)_ref + CA(P(i)_prac, P(i)_ref) ))。这实现了从Pprac到Pref的信息流动和对齐。 b. 模态内处理:然后,另一个流(Pprac)执行类似操作,但使用刚刚更新过的P(i+1)_ref作为交叉注意力的键/值源(P(i+1)_prac = ViTprac( P(i)_prac + CA(P(i+1)_ref, P(i)_prac) ))。 - 通过交替进行上述步骤,两个流在每一层都相互对齐并交换信息,同时各自保留独立的ViT块进行特征提取。这种设计允许一个流专注于局部特征(如练习音频),另一个流专注于全局或跨流对应特征,实现“不对称分工”。
- 所有层处理完毕后,两个流的最终表示被拼接(
Hfused = Concat(P(final)_ref, P(final)_prac))作为编码器输出。

(图3:LadderSym的整体架构。展示了双流音频输入经过Ladder编码器进行对齐,以及符号乐谱作为提示与编码器输出一同送入T5解码器,生成错误标签序列。)
- Sym提示与解码器:
- 在解码器输入的最前面,插入一个“符号乐谱提示”序列(如
[SOS, Time=0, Label=Correct, On, Note=60, ...]),明确告知模型参考乐谱的“正确”版本。 - 随后是编码器输出的拼接序列(
Hfused)。 - T5解码器以自回归方式生成输出序列,该序列采用与输入提示类似的token格式,但包含实际检测到的错误标签(如
Label=Extra,Label=Missed)。
- 在解码器输入的最前面,插入一个“符号乐谱提示”序列(如
关键设计选择与动机:
- 交错对齐 vs. 后期融合:为克服前作(Polytune)在最后一层才融合两流的限制,LadderSym在每层都进行对齐,旨在实现更频繁、更细粒度的交互。实验(Table 4)和注意力可视化(图4,图8)证实了这种设计能学习到类似动态时间规整(DTW)的对齐模式,且性能优于仅使用少量联合层或完全共享参数的早期融合。
- 符号提示:为解决音频表示乐谱在同时演奏多个音符时的频谱歧义,直接将无歧义的符号序列作为上下文提示,为解码器提供“标准答案”的参考。消融实验(Table 5)显示,结合音频与符号输入(Prompt + Audio)能显著提升性能,尤其是在更复杂的MAESTRO-E数据集上。
(图5:编码器块内部结构。展示了交叉注意力对齐模块如何交替在参考流和练习流之间工作,以及加性融合和后续的ViT处理块。)
(图4:动态时间规整(a)与Ladder编码器中学习到的交叉注意力对齐模式(b)的对比。注意力图显示了模型在时间维度上学到的对应关系,类似于DTW路径。)
💡 核心创新点
- 交错对齐编码器(Ladder):提出了一种新的双流编码器架构,通过在每一层之前交替进行跨流交叉注意力对齐和独立的模态内处理,实现了对齐与特征提取的解耦。这既允许两流频繁交互以实现精细对齐(类似早期融合),又保持了参数独立以支持特征专门化(类似后期融合),克服了前人方法在这两者间的权衡局限。
- 符号乐谱提示(Sym):将乐谱的符号化表示作为解码器的提示,与音频表示形成多模态输入。这直接为模型提供了无歧义的参考信息,显著减少了因音频频谱重叠(尤其在复调音乐中)导致的混淆,提升了对“漏音”等微妙错误的检测能力。
- 系统化的分析与验证方法:论文不仅提出新模型,还通过表征探针(Table 1)、注意力图可视化(图6,7,8)、系统的消融实验(Table 4, 5)等方法,深入分析了不同编码器设计(早期/晚期融合)对模型表示学习的影响,为设计跨模态比较模型提供了可迁移的实证依据。
- 真实世界数据集的收集与验证:为了弥补合成数据的不足,作者亲自录制并标注了一个包含真实初学者错误的钢琴演奏数据集(20首曲子),并公开发布。在该数据集上的测试验证了LadderSym在未微调情况下对真实世界数据的泛化能力。
🔬 细节详述
- 训练数据:
- 合成数据:主要使用MAESTRO-E(钢琴,密集和弦)和CocoChorales-E(13种乐器,单声部为主)两个合成数据集。它们基于现有的MIDI语料库(MAESTRO, CocoChorales),通过算法注入漏音、错音、多余音符等错误生成,然后使用MIDI-DDSP合成音频。每个数据集包含超过1000个曲目片段。
- 真实数据:作者团队收集了一个新的、小规模的真实数据集,包含3名初学者演奏的20首简单钢琴曲的录音及人工标注的161个错误(75个错音对,51个多余音,35个漏音)。该数据集用作分布外评估。
- 损失函数:使用带权重的交叉熵损失,以缓解“正确”音符与“错误”音符之间的类别不平衡。权重设置为:错误音符的损失权重为10(详见Table 7)。
- 训练策略:
- 优化器:AdamW。
- 学习率调度:余弦退火,初始学习率为2e-4,衰减至1e-4。
- 训练轮数:300 epochs。
- 批大小:MAESTRO-E为48个音频段,CocoChorales-E为96个音频段(因其音符密度较低)。
- 数据增强:应用了“Token Shuffling”技术,对输出token序列进行随机排列而不改变语义。
- 精度:使用混合精度训练(bf16-mixed)。
- 关键超参数:
- 模型大小:LadderSym总共172M参数(编码器部分约12层,解码器8层)。编码器输出维度768,投影至512以匹配T5解码器。
- 音频分段:将音频切成2.145秒的非重叠片段。
- 声谱图参数:2048点FFT,128样本跳步,512个梅尔频带。
- Patch大小:16x16,每个片段生成512个token。
- 训练硬件:在单张NVIDIA A100-80GB GPU上进行训练。
- 推理细节:解码器采用自回归方式生成token序列。论文未提及使用beam search或温度调节,默认应为贪心解码或核采样。
- 正则化技巧:使用了token shuffling作为数据增强。未明确提及dropout、权重衰减等。
📊 实验结果
论文在MAESTRO-E和CocoChorales-E两个主要数据集,以及新收集的真实世界数据集上进行了评估,主要指标为各类别(Correct, Missed, Extra)的F1分数。
主要对比结果:
| 数据集 | 模型 | Correct F1 | Missed F1 | Extra F1 |
|---|---|---|---|---|
| MAESTRO-E | LadderSym (Ours) | 94.4% | 54.7% | 86.4% |
| Polytune (SOTA) | 90.1% | 26.8% | 72.0% | |
| Explicit Align. Baseline | 43.5% | 6.6% | 39.9% | |
| CocoChorales-E | LadderSym (Ours) | 97.7% | 61.7% | 61.4% |
| Polytune (SOTA) | 95.4% | 51.3% | 46.8% | |
| Explicit Align. Baseline | 36.7% | 7.7% | 23.5% |
关键发现:
- LadderSym在所有类别和数据集上均显著超越了之前的SOTA(Polytune)。在最困难的MAESTRO-E数据集上,Missed Note F1提升超过一倍(26.8% -> 54.7%)。
- 额外音符(Extra Note)的检测也得到了大幅提升(MAESTRO-E: 72.0% -> 86.4%)。
- 与基于显式对齐(DTW)的基线相比,性能提升是量级的。
消融实验结果:
融合位置的影响:固定总层数为12,改变联合编码器层数(Ljoint)。结果显示性能在Ljoint=2或3时达到峰值,过多联合层(如12,即早期融合)或过少(1)性能均下降,支持了Ladder的设计理念。
Ljoint Missed F1 Extra F1 1 51.26% 46.80% 2 59.58% 57.38% 3 56.81% 59.61% 4 59.51% 58.11% 12 (Early) 54.60% 56.20% (Table 4部分数据) 输入表示的影响:对比“仅音频”、“仅提示”、“音频+提示”三种输入。结果显示“音频+提示”组合在大多数情况下最优,尤其是在复杂的MAESTRO-E上。这验证了符号提示的价值。
输入配置 MAESTRO-E Missed MAESTRO-E Extra CocoChorales-E Missed CocoChorales-E Extra Prompt Only 24.3% 62.5% 44.6% 45.8% Audio Only 26.8% 72.0% 46.8% 51.3% Prompt + Audio 46.7% 81.7% 56.1% 58.1% (Table 5部分数据)
真实世界数据集评估: 在未微调的情况下,LadderSym在真实初学者数据上仍优于Polytune,尤其在Missed Note检测上(78.5% vs 63.9% F1)。具体每首曲子的结果见Table 9。
(图10:真实世界数据集上,LadderSym与Polytune在每首曲子上的Extra和Missed Note F1对比。显示了LadderSym在更困难的Missed Note检测上的普遍优势。)
⚖️ 评分理由
- 学术质量:5.5/7:论文提出了针对音乐错误检测任务的明确技术创新(Ladder编码器、Sym提示),并通过详尽的实验(主实验、消融实验、真实数据实验)和可视化分析(注意力图、表征探针)验证了其有效性。架构设计有清晰的动机和理论分析支撑,技术正确性高。虽然任务领域较专,但其提出的“分层融合”和“多模态提示”对于序列比较问题具有一定的普适性启发。
- 选题价值:1.5/2:音乐教育技术是一个有实际需求的应用方向。尽管音乐错误检测是细分市场,但该工作所解决的“精确序列比较”问题在强化学习(策略评估)、人类技能评估(如体育动作分析)、生成模型评估等领域有潜在的迁移价值,论文讨论中也明确指出了这一点。
- 开源与复现加成:1.0/1:论文提供了完整的代码仓库(GitHub)、用于评估的合成数据集以及新收集的真实数据集,并在附录中给出了极其详尽的训练超参数、硬件环境、随机种子等信息,使得复现门槛非常低,极大地增加了工作的可信度和影响力。