📄 Knowing When to Quit: Probabilistic Early Exits for Speech Separation Networks
#语音分离 #语音增强 #概率建模 #提前退出 #实时处理
✅ 7.0/10 | 前25% | #语音分离 | #概率建模 | #语音增强 #提前退出
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Kenny Falkær Olsen (Technical University of Denmark, WS Audiology)
- 通讯作者:未说明
- 作者列表:Kenny Falkær Olsen (Technical University of Denmark, WS Audiology), Mads Østergaard (WS Audiology), Karl Ulbæk (WS Audiology), Søren Føns Nielsen (WS Audiology), Rasmus Malik Høegh Lindrup (WS Audiology), Bjørn Sand Jensen (Technical University of Denmark), Morten Mørup (Technical University of Denmark)
💡 毒舌点评
亮点在于将概率建模与早退机制结合,推导出一套基于置信度的、可解释的SNR退出准则,比传统的启发式或固定损失权衡方法更 principled。短板是框架的实用性高度依赖于模型预测的不确定性(σ²)是否校准良好,论文显示这需要额外的、在全长度数据上的微调,增加了实际部署的复杂性,且核心模型架构(PRESS-Net)本身在绝对性能上并非无懈可击。
🔗 开源详情
- 代码:论文中未提及任何代码仓库链接或开源计划。
- 模型权重:未提及公开预训练模型权重。
- 数据集:评估使用的WSJ0-2mix, Libri2Mix, WHAM!, WHAMR!, DNS2020均为公开数据集,论文中提供了获取方式的引用链接。
- Demo:未提及。
- 复现材料:论文附录提供了详细的架构图(图2, 图8)、模块描述(编码器/解码器头、线性RNN、逆Gamma参数化块)、数据集描述(附录D)、训练细节(优化器、学习率调度、训练步数等,附录E)以及关键消融实验设置,为复现提供了充分信息。
- 引用的开源项目:论文中引用了用于数据生成的开源仓库(如pywsj0-mix, LibriMix, DNS-Challenge),以及基础架构和组件(如PyTorch, AdamW, minGRU, Hydra, Mamba等)。
📌 核心摘要
- 问题:当前深度学习的语音分离与增强网络(如TasNet, SepFormer)通常具有固定的计算复杂度,无法根据输入的简单程度(如低噪声、非重叠语音)动态调整计算量,限制了其在移动设备和助听器等资源受限场景的应用。
- 方法核心:提出了PRobabilistic Early-exit for Speech Separation (PRESS) 框架。该方法联合建模清晰语音信号及其预测误差的方差(采用共轭逆Gamma先验),从而导出预测的信噪比(SNR)分布。基于此,可以构建出可解释的早退条件,即当模型对SNR达到某一目标水平有足够信心时,即可提前终止计算。
- 创新点:
- 提出了一个统一的、具有不确定感知的概率框架,用于建模预测质量和推导退出条件,无需手动权衡多个损失项。
- 设计了PRESS-Net架构,基于线性RNN和早期分裂(early splitting),旨在同时实现高计算效率与高质量的中间表征重建。
- 引入了一个统一的退出SNR条件,综合考虑了目标SNR、SNR改进和参考信号SNR,以处理静默情况。
- 主要实验结果:在WSJ0-2mix、Libri2Mix、WHAM!、WHAMR!和DNS2020数据集上进行了评估。实验表明(见表2),PRESS模型(如PRESS-4(S)和PRESS-12(M))在仅使用部分计算量(例如,仅运行4/12个解码器块)时,就能达到接近使用全部计算的最终性能。更重要的是,通过概率退出条件动态调整计算,其效率-性能曲线(图3)优于静态模型。消融实验(表1)验证了概率似然、联合置换训练等关键设计的有效性。
- 实际意义:为部署在异构设备上的语音处理系统提供了一种高效、可伸缩的解决方案,可以根据实际需求和设备资源动态平衡性能与功耗/延迟,且退出条件具有物理意义(SNR)和可解释性(置信度)。
- 主要局限性:模型对误差方差的预测(σ²)在标准训练后并不校准(图5a,b),需要额外在全长度音频上进行微调才能达到良好校准(图5c,d),这增加了训练的复杂性。此外,退出决策目前是在所有说话人联合进行的,尚未支持对每个说话人独立退出。
🏗️ 模型架构
PRESS的整体流程遵循经典的编码器-分离器-解码器框架,并在分离器中嵌入了多个早退点。
输入输出流程:
- 输入:混合音频信号
e_x ∈ R^T。 - 编码器:一个浅层卷积编码器将音频下采样并映射到高维表示
∈ R^{D_enc × T/P},然后通过线性层投影到模型维度D(64或128)。 - 分离器:这是模型的核心,由多个层(
N_enc + N_dec)组成。它首先处理混合语音的表征,然后通过一个SpeakerSplit模块将特征沿通道维分裂为S个独立的说话人流。此后,每个说话人的处理流独立进行,但可以通过说话人注意力层交换信息。 - 早退点:在解码器堆栈(
N_dec层)中的特定位置(例如每2或3层)放置早退点E_i。每个早退点都连接一个独立的解码器头,可以将该点的中间表征直接重建为分离出的音频信号。同时,每个早退点还连接一个逆Gamma参数化模块,用于预测该点估计的误差方差参数α_i, β_i。 - 退出决策:在推理时,模型顺序执行每个块。在每个早退点,根据预测的
α_i, β_i和当前的估计信号,计算统一退出SNR的互补CDF值p(SNR_exit ≥ t)。当所有说话人的该值超过置信度阈值p时,模型立即退出,输出该点的重建结果;否则继续执行到下一个早退点或最终层。 - 输出:根据退出点的选择,输出分离出的
S个语音信号b_xi ∈ R^T。
主要组件:
- 编码器/解码器头:基于SepReformer设计,解码器头包含GLU层和一个转置卷积用于上采样。每个早退点共享同一套解码器头参数(在附录C中说明,但图2显示为独立块)。
- 分离器(Separator):一个深堆栈,采用预归一化、残差连接和LayerScale以实现稳定训练。
- 基础模块:线性RNN块(基于minGRU和Hydra双向性实现)和说话人注意力块(来自SepReformer)。线性RNN块通过并行关联扫描实现高效训练,避免了自注意力的二次复杂度。
- SpeakerSplit:在
N_enc层后,将混合表征沿特征维拆分为S份,分配给不同的说话人处理流。
- 逆Gamma参数化模块 (InvGam Block):一个简单的MLP(GLU -> GELU -> 线性层 -> softplus),从中间表征中预测标量
α_i和β_i。
关键设计选择:
- 早期分裂(Early Split):借鉴SepReformer,在网络早期就将信号流分离为不同说话人,使得每个早退点都能提供完整的多说话人重建,这是实现每个点都有高质量重建的关键。
- 线性RNN:为在保持长时依赖建模能力的同时,避免因网络深度增加(用于早退点)带来的过高计算成本,选择了线性复杂度的RNN作为主要构建块。
- 独立解码器头:每个早退点有自己的解码器头,允许网络从不同深度的表征中独立重建音频,避免了共享解码器可能带来的表示瓶颈。
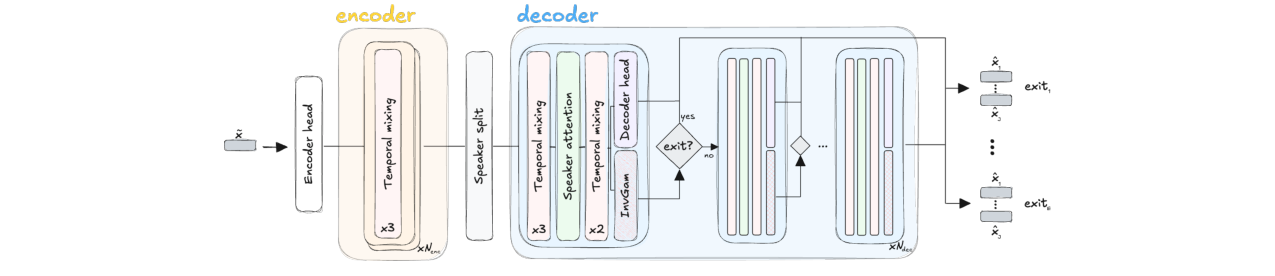
(图2:PRESS-Net的详细架构图。展示了从编码器、早期分裂模块到带有多个早退点(Exit Point)的解码器堆栈的整体结构。)
💡 核心创新点
- 概率性早退框架(PRESS):这是本文最核心的理论贡献。它没有使用隐式的损失权衡(如
Loss = Rec_loss + λ * Utilization_loss)或基于启发式(如相邻层差异)的退出条件,而是通过一个生成模型(假设误差服从高斯分布,其方差服从逆Gamma分布)直接建模预测不确定性,并从中推导出基于SNR的、可解释的早退条件。这使得退出决策可以基于一个置信度阈值p进行调节。 - 统一退出SNR条件:设计了一个结合了三种SNR度量(
SNR,SNRi,SNRref)的统一条件。SNR(目标/误差)在目标安静时失效,SNRi(改进量)在输入本身信噪比高时失效,SNRref(误差/参考)用于设定噪声的绝对上限。取其最大互补CDF(即至少一个条件满足的概率)作为乐观退出准则,再取所有说话人中的最小值作为悲观退出准则,确保了退出条件的鲁棒性。 - PRESS-Net架构与高效早退:为了支撑概率框架并实现高质量的早期重建,设计了PRESS-Net。其关键在于:(a) 使用早期分裂架构,使每个退出点都能访问完整的说话人分离信息;(b) 采用线性RNN作为主要计算单元,使得深层(多个退出点)堆叠不会导致计算成本爆炸;(c) 每个退出点配备独立的解码器头,确保中间表征能被充分解码为高质量信号。
🔬 细节详述
- 训练数据:
- 语音分离:WSJ0-2mix(30小时训练), Libri2Mix(40小时训练), WHAM!(添加环境噪声的WSJ0-2mix), WHAMR!(添加混响和噪声的WSJ0-2mix)。
- 语音增强:DNS2020(441小时清洁语音,195小时噪声,在线混合生成训练样本,SNR 0-20dB)。
- 数据预处理:所有模型在8kHz采样率(分离)或16kHz(增强)上训练。训练使用4秒短片段,评估使用全长度音频。
- 损失函数:多元学生t分布似然(公式2)。该损失函数源于对目标信号和预测误差方差的贝叶斯建模。最大化该似然等价于最小化
ln(1 + ||x_j - b_x_i||²/(2β_i))等项,它对误差进行了对数尺度的惩罚。训练时使用uPIT(句级排列不变训练)将预测源与真实源进行匹配,并且对于多个早退点,所有退出点的排列是联合进行的(即说话人在各层之间不交换),这对稳定训练至关重要。 - 训练策略:
- 优化器:AdamW (
β1=0.9,β2=0.99),权重衰减0.01(仅作用于线性和卷积层)。 - 学习率:基础
5e-4,根据模型宽度按比例调整(D_old/D_new)。使用线性预热(5000步)和线性衰减至零(straight-to-zero)的调度策略。 - 训练步数:最多600万步,批大小为1,等效于6666小时的数据曝光。
- 其他:梯度裁剪(L2范数上限为1)。
- 优化器:AdamW (
- 关键超参数:
- 模型尺寸:PRESS-4(S) (
D=64,N_enc=8,N_dec=12, 4个早退点); PRESS-12(M) (D=128,N_enc=4,N_dec=24, 12个早退点)。 - 编码器:卷积核大小16,步长4(8kHz)或8(16kHz)。
- 早退点位置:均匀分布在解码器堆栈中。
- 块大小
T(用于分块似然):在2000样本(250ms)的消融实验中表现良好。
- 模型尺寸:PRESS-4(S) (
- 训练硬件:未具体说明所有硬件,但提到使用NVIDIA Ampere架构或更高版本的GPU(H100, A100, A40, A10, RTX 4090等)。PRESS-4(S)训练约2-3天,PRESS-12(M)训练约6天。
- 推理细节:推理时,模型按顺序处理输入。在每个早退点,计算退出条件
min_i p(SNR_exit(x_j, b_x_i, e_x) ≥ t) ≥ p。如果满足,则立即输出该点的重建结果并停止计算;否则继续到下一个块。目标SNRt和置信度p是可调参数。 - 正则化/稳定训练技巧:使用LayerScale(初始化为
1e-5)和RMSNorm来稳定深层网络的训练;使用GELU激活函数;模型权重从截断正态分布初始化。
📊 实验结果
论文在多个基准数据集上评估了PRESS的分离和增强性能,并与强基线进行了对比。
- 主要语音分离结果 (表2) 在WSJ0-2mix等数据集上,PRESS模型展示了其动态计算能力。例如,在WSJ0-2mix上:
- PRESS-4 (S) @ 4(使用全部4个解码块):SI-SNRi = 22.91 dB, 参数量3.4M, 计算量11.3 GMAC/s。
- PRESS-12 (M) @ 12(使用全部24个解码块):SI-SNRi = 24.28 dB, 参数量22.4M, 计算量79.7 GMAC/s。
- 经过全长度数据微调(+FT)后,性能显著提升:PRESS-12 (M) @ 12 + FT 达到 SI-SNRi = 24.36 dB,接近SepReformer(M)的24.2 dB,但后者计算量为81.3 GMAC/s。
- 论文的核心论点在于动态性能:在图3中,PRESS-4(S)使用概率退出条件(不同目标SNR)构建的性能-效率曲线,位于所有静态模型性能点的左上方,意味着在达到相同SI-SNRi时,它使用的计算量更少。
| 模型 | WSJ0-2mix SI-SNRi (dB) | WSJ0-2mix SDRi (dB) | 参数量 (M) | GMAC/s (G/s) |
|---|---|---|---|---|
| SepFormer (S) | 23.0 | 23.1 | 4.5 | 21.3 |
| SepReformer (M) | 24.2 | 24.4 | 17.3 | 81.3 |
| PRESS-4 @ 4 (S) | 22.91 | 23.08 | 3.4 | 11.3 |
| PRESS-12 @ 12 (M) | 24.28 | 24.46 | 22.4 | 79.7 |
| PRESS-12 @ 12 (M) + FT | 24.36 | 24.55 | 22.4 | 79.7 |
- 语音增强结果 (表3) 在DNS2020上,PRESS模型同样具有竞争力。PRESS-12(M) @12的SI-SDR为22.15 dB,与计算量更大的ZipEnhancer(22.22 dB,133.5 GMAC/s)相当。
| 模型 | DNS2020 SI-SDR | # Params (M) | GMAC/s |
|---|---|---|---|
| ZipEnhancer | 22.22 | 11.34 | 133.5 |
| PRESS-12 @ 12 (M) | 22.15 | 18.14 | 78.3 |
- 关键消融实验 (表1)
- (a) vs (d/e):使用学生t似然损失代替SI-SNR损失,并未导致性能下降(22.89 vs 22.95),证明了概率框架的有效性。
- (b):使用普通正态似然(单一预测方差)会导致性能下降(22.42),说明了学生t分布建模(对数误差惩罚)的重要性。
- (c):联合置换训练(per-exit uPIT)至关重要。如果各退出点独立进行源置换,性能会大幅下降(21.1),因为说话人可能在各层间交换,破坏了早退的稳定性。
- (d, e):增加退出点数量(从4到6或12)不会损害最终性能,为训练更大、更灵活的模型奠定了基础。
- 校准实验 (图5):初始训练后模型的误差方差预测不校准(图5a, b的PIT曲线偏离对角线,CRPS值高)。仅通过额外3%训练时间的微调(在全长度数据上),模型变得高度校准(图5c, d),且分离性能也大幅提升。
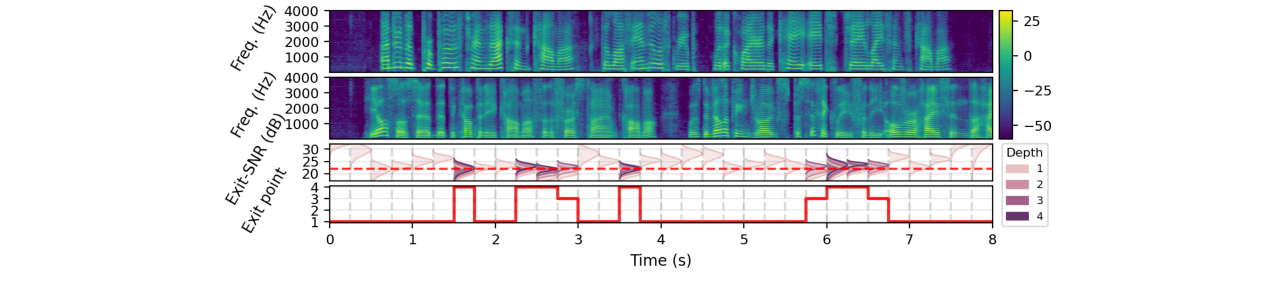
(图4:在WSJ0-2mix测试集上,不同早期退出策略的单侧“遗憾”(实际退出SNR与目标SNR的差距)对比。本文的概率退出策略(蓝色曲线)在适当的置信度p下,能紧密匹配“神谕”策略(红色虚线),而静态策略(绿色)和随机策略(灰色)表现较差。)
(图5:误差方差预测的校准曲线(PIT)。(a)(b)显示仅用4秒片段训练后,模型在训练集和测试集上均不校准。(c)(d)显示在全长度数据上微调后,校准性显著改善。CRPS分数从1.61/2.96降至1.43/2.80。)
⚖️ 评分理由
- 学术质量 (5.5/7):
- 创新性 (2.0/2):提出了将概率生成模型与神经网络早退机制相结合的新颖框架,推导出可解释的SNR退出条件,具有方法论上的创新。
- 技术正确性 (1.5/2):概率推导过程严谨(如利用卡方比率在大T下的近似),架构设计(早期分裂、线性RNN)合理。但模型预测的不确定性需要额外微调才能校准,暴露了框架的一个实际弱点。
- 实验充分性 (1.0/2):在多个主流语音分离/增强基准上进行了测试,消融实验充分(损失函数、置换策略、退出点数量、校准)。但绝对性能并非最顶尖,且主要亮点(动态效率曲线)需要结合特定评估角度来看。
- 证据可信度 (1.0/1):实验设置清晰,结果表格完整,校准性分析增强了论点的可信度。
- 选题价值 (1.5/2):
- 前沿性 (0.7/1):动态神经网络和模型效率是当前AI研究的重要方向,本文将早退机制引入语音处理是一个有价值的尝试。
- 潜在影响与应用空间 (0.8/1):直接针对助听器、手机等资源受限设备上的实时语音处理,应用场景明确,潜在影响直接。退出条件基于物理意义强的SNR,易于理解和部署。
- 开源与复现加成 (0.0/1):论文提供了详尽的架构描述、超参数、训练细节和数据集说明,理论上具有良好的可复现性。然而,论文中完全未提及代码、模型权重或复现脚本的公开计划,这是显著的扣分项。