📄 JointAVBench: A Benchmark for Joint Audio-Visual Reasoning Evaluation
#多模态模型 #基准测试 #音视频联合推理 #大语言模型 #模型评估
✅ 7.0/10 | 前25% | #音视频联合推理 | #基准测试 | #多模态模型 #大语言模型
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Jianghan Chao(中国人民大学高瓴人工智能学院)
- 通讯作者:Ruihua Song(中国人民大学高瓴人工智能学院)
- 作者列表:Jianghan Chao(中国人民大学高瓴人工智能学院),Jianzhang Gao(中国人民大学高瓴人工智能学院),Wenhui Tan(中国人民大学高瓴人工智能学院),Yuchong Sun(中国人民大学高瓴人工智能学院),Ruihua Song(中国人民大学高瓴人工智能学院),Liyun Ru(百川智能)
💡 毒舌点评
亮点在于提出了一个设计严谨、维度全面的音视频联合推理评估框架,并巧妙地利用先进的LLM构建了自动化数据生成流水线,在保证质量的同时大幅降低了标注成本;短板在于其基准数据集完全来源于SF20K这一特定影视数据集,可能存在领域偏差,且论文主要贡献是评估基准而非新的建模方法,对推动模型架构本身创新的直接贡献有限。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开权重。
- 数据集:公开。论文提供了项目页面链接 (https://jointavbench.github.io),并说明JointAVBench数据集将在该页面发布。
- Demo:未提及。
- 复现材料:论文在附录中提供了生成流水线各阶段使用的详细Prompt模板(如图10-16),这对于复现其数据生成过程至关重要。
- 论文中引用的开源项目:引用了多个开源模型(Qwen2.5-VL, Qwen2.5-Omni, Whisper-v3等)和工具(PySceneDetect)用于构建基准。
- 整体开源计划:论文明确表示会发布数据集,但代码和模型权重的开源计划未提及。
📌 核心摘要
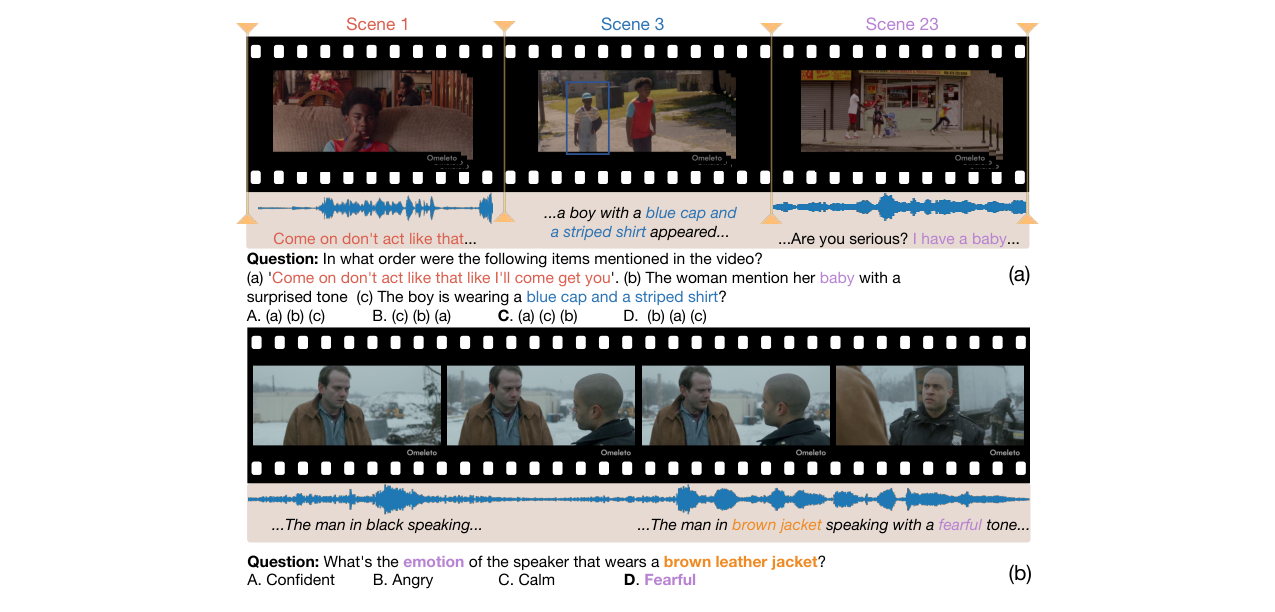
- 要解决什么问题:现有评估全模态大语言模型(Omni-LLMs)的基准测试在音视频关联严格性、音频类型多样性和场景复杂度覆盖方面存在不足,无法有效评估模型真正的联合音视频推理能力。
- 方法核心是什么:提出JointAVBench,一个从5个认知维度、4种音频类型、3个场景跨度构建的15项任务基准。其核心创新在于设计了一个三阶段半自动化数据生成流水线:首先生成全模态描述(视频、语音、声音事件、音乐、声纹特征),然后利用LLM合成严格依赖音视频联合信息的问答对,最后通过通用到特定的多层质量控制确保数据质量。
- 与已有方法相比新在哪里:这是首个同时满足“严格音视频关联(AV Correlation Ratio 100%)”、“覆盖四种音频类型(含声纹特征)”和“涵盖单场景、跨场景、全场景”的综合基准。与现有基准(如WorldSense,AV Corr. 62.9%)相比,其问题设计更严谨地强制依赖双模态信息。
- 主要实验结果如何:在JointAVBench上评估了主流Omni-LLMs、Video-LLMs和Audio-LLMs。结果显示,即使最强的Omni-LLM(Gemini2.5-Pro)平均准确率也仅为62.6%,显著优于单模态模型,但在跨场景推理等任务上表现仍不理想。模型在声纹特征和语音相关任务(如SPER, SPL)上表现最差,在涉及声音事件和音乐的任务上表现相对较好。
- 实际意义是什么:为评估和推动具有真正音视频联合推理能力的Omni-LLM发展提供了关键的、标准化的评测工具,明确指出了当前模型在处理抽象音频信息(如声纹特征、情感)和复杂跨场景推理时的主要短板。
- 主要局限性是什么:数据源单一(仅SF20K短片),可能引入领域偏差;设计的任务分类法虽全面但无法穷尽所有音视频推理能力;受计算资源限制,实验评估的模型数量有限。
🏗️ 模型架构
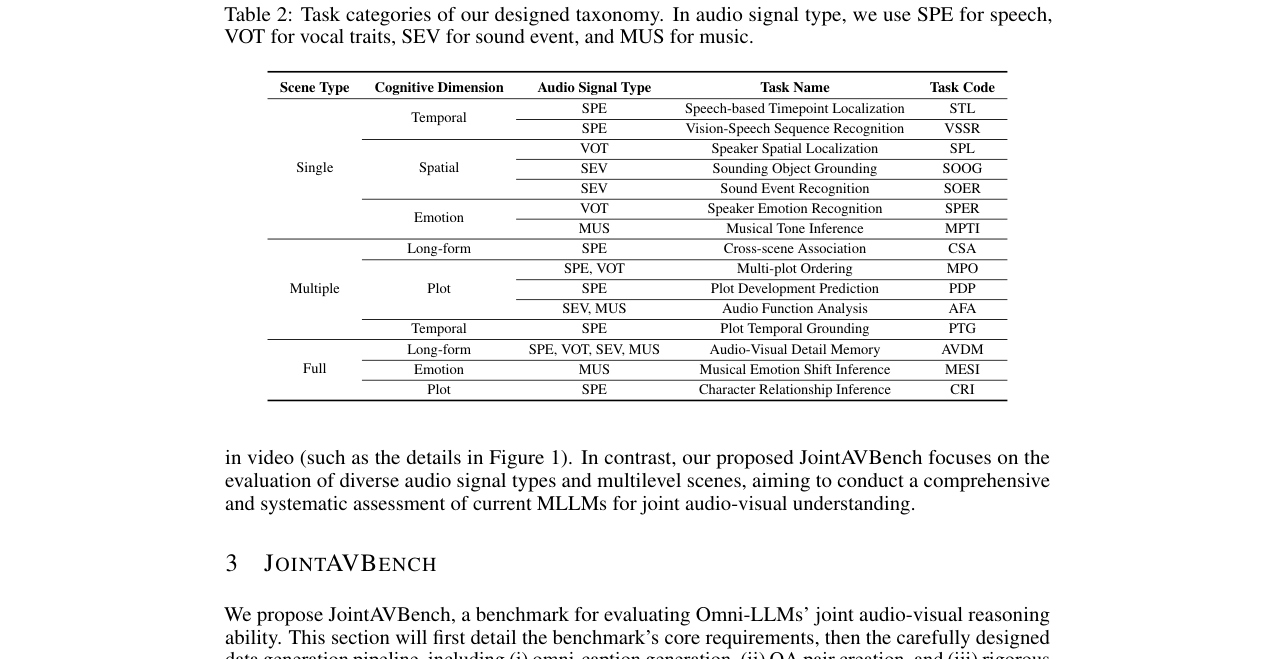
本文并非提出一个新的模型架构,而是设计一个评估基准。其核心贡献在于数据生成与质量控制流水线。论文详细描述的流水线架构如下:
全模态描述生成(Stage 1):该阶段旨在为原始视频生成丰富的多模态标注,作为后续QA生成的基础。流程图见下图。
- 场景识别:使用PySceneDetect将长视频分割为语义一致的片段。
- 视频描述生成:使用Qwen2.5-VL为每个片段生成详细的视觉描述,涵盖场景设置、人物动作、场景动态等。
- 音频描述生成:使用Qwen2.5-Omni为每个片段分别生成声纹特征(VOT)、声音事件(SEV)和音乐(MUS)描述。针对当前音频模型难以区分声音事件和音乐的问题,采用联合生成后分离的策略。
- 语音转录:使用Whisper-v3进行精确的对话转录和时间戳生成。
- 描述优化:使用Qwen-2.5对初始音频描述进行去幻觉、去冗余和跨描述一致性检查。
问答对创建(Stage 2):基于Stage 1生成的全模态描述,为设计的15种任务生成严格的音视频联合QA对。
- 任务模板化生成:对于需要复杂音视频关系推理的任务(如时序、情节类),使用预定义的问题模板引导LLM生成。
- 跨模态信息输入:严格根据任务要求,只输入指定场景和模态的描述(如SPL任务只输入单场景的视频描述和声纹特征描述),以避免模态干扰。
质量控制(Stage 3):采用从通用到特定的验证策略,确保生成的QA对质量。
- 通用检查:验证模态依赖性、格式、内容逻辑和推理性。
- 特定检查:针对不同任务类型设计专门的验证逻辑,如序列任务的顺序检查、复杂推理任务的歧义检查、声音/音乐任务的声源可推理性检查。
- 干扰项生成:为每个合格的QA对生成三个具有迷惑性的错误选项。
流水线架构图
该图展示了三阶段流水线:(a) 全模态描述生成,包括场景分割、视频描述、四类音频描述生成与优化;(b) 问答对创建,根据场景类型(单、多、全)和任务需求,从模态选择到干扰项生成的流程;(c) 质量控制,涵盖通用检查和任务特定检查。
💡 核心创新点
- 首个全面且严格的音视频联合推理基准:设计了包含5个认知维度、4种音频类型、3个场景跨度的15项任务分类法,并确保所有任务100%需要音视频信息才能回答,解决了现有基准音视频关联不严或类型覆盖不全的问题。
- 高效的半自动化高质量数据生成流水线:利用当前最强大的视觉-LLM、音频-LLM和通用LLM,构建了一个从描述生成、QA合成到多层级质量控制的完整流水线。这种方法在保证数据质量(通过人工验证,保留率71.8%)的同时,有效控制了高昂的人工标注成本。
- 对当前Omni-LLM能力的系统性实证分析:通过对多种模型的全面评估,定量揭示了当前模型在联合推理上的具体短板,例如在声纹特征理解和跨场景推理上的不足,为未来模型改进提供了明确方向。
🔬 细节详述
- 训练数据:未说明。本文是基准测试,不涉及模型训练。评估使用的视频数据来自公开的Short-Films 20K (SF20K)数据集,包含1046部电影。
- 损失函数:未说明。
- 训练策略:未说明。
- 关键超参数:未说明(评估时对模型使用了统一配置,如开源模型统一使用7B参数规模和32帧采样)。
- 训练硬件:未说明。
- 推理细节:对闭源模型(Gemini, GPT-4o)使用官方API默认配置;对开源模型使用其官方代码库和默认配置。评估时统一采样32帧,输入仅限于问题文本。
- 正则化或稳定训练技巧:未说明。
📊 实验结果
论文在JointAVBench上对17个模型(Omni-LLMs, Video-LLMs, Audio-LLMs)进行了全面评估,主要结果如下:
表1:JointAVBench与现有基准的对比(关键指标)
| 基准/数据集 | 平均时长 | QA数量 | 构建方法 | 模态 | 任务数 | 音频类型数 | 音视频关联比 |
|---|---|---|---|---|---|---|---|
| JointAVBench (Ours) | 97.2s | 2,853 | A+M | V&A | 15 | 4 | 100% |
| WorldSense | 141.1s | 3,172 | M | V&A | 26 | 3 | 62.9% |
| LongVALE | 235s | - | A+M | V&A | 3 | 3 | 76.2% |
| OmniBench | - | 1,142 | M | I&A | 8 | 3 | 100% |
| AV-Odyssey | - | 4,555 | M | V/I&A | 26 | 3 | 100% |
| A: 自动化流程; A+M: 流程+人工检查; M: 人工流程; V: 视频; I: 图像; A: 音频 |
表3:主流MLLMs在JointAVBench上的评估结果(部分关键模型)
| 模型 | 类型 | 参数量 | STL | SPL | SOOG | SOER | SPER | MPTI | VSSR | CSA | MPO | PTG | AFA | PDP | AVDM | MESI | CRI | 平均准确率 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Gemini2.5-Pro | Omni | - | 73.0 | 59.4 | 60.8 | 68.9 | 35.2 | 68.1 | 76.5 | 43.8 | 66.0 | 60.7 | 65.5 | 45.7 | 75.5 | 66.1 | 81.9 | 62.6 |
| Qwen3-Omni | Omni | 30B | 71.1 | 43.4 | 73.8 | 78.4 | 35.7 | 80.3 | 75.7 | 42.1 | 45.2 | 30.9 | 59.7 | 47.3 | 61.8 | 69.2 | 84.0 | 62.1 |
| Qwen2.5-Omni | Omni | 7B | 71.3 | 35.3 | 59.8 | 72.3 | 30.6 | 63.4 | 77.6 | 51.2 | 40.4 | 20.8 | 69.9 | 47.3 | 47.3 | 69.9 | 70.3 | 56.2 |
| InternVL2.5 | Video | 8B | 28.7 | 37.9 | 59.8 | 71.1 | 23.6 | 64.1 | 52.2 | 42.5 | 44.2 | 27.5 | 63.6 | 41.9 | 50.0 | 68.4 | 68.3 | 51.3 |
| Kimi-Audio | Audio | 7B | 56.5 | 21.9 | 48.6 | 61.7 | 32.9 | 53.3 | 34.3 | 38.0 | 33.0 | 26.2 | 65.3 | 38.7 | 40.2 | 56.1 | 69.5 | 45.9 |
关键结论:
- 总体性能:最强的Omni-LLM(Gemini2.5-Pro)平均准确率仅为62.6%,表明当前模型在联合音视频推理方面仍有巨大提升空间。
- 音频类型差异:模型在声音事件(SEV)和音乐(MUS)任务上表现相对较好,但在声纹特征(VOT)和语音(SPE)任务(如SPER, SPL)上表现最差,揭示了模型对抽象音频信息理解的薄弱环节。
- 场景复杂度影响:性能随场景复杂度增加而下降。跨场景任务(如MPO, PTG)通常比单场景任务表现更差,而全场景任务因侧重全局叙事而有所回升,凸显了模型在长时序、跨片段推理上的不足。
不同音频类型下的模型表现
该图展示了多个模型在四种音频类型(声纹特征、语音、音乐、声音事件)上的平均准确率对比。清晰地显示所有模型在声纹特征和语音任务上的性能显著低于音乐和声音事件任务。
不同场景类型下的模型表现
该图展示了多个模型在单场景、多场景和全场景任务上的平均准确率。多场景任务的准确率普遍低于单场景和全场景任务,印证了跨场景推理的挑战性。
消融实验:模态融合有效性(表4摘要)
表4:开源Omni-LLM不同模态使用的效果对比(部分模型)
| 模型 | 模态 | 性能提升任务数(No) | 性能下降任务数(Nu) | 平均准确率 |
|---|---|---|---|---|
| Qwen2.5-Omni | A+V (联合) | 8 | 1 | 56.2 |
| V (仅视频) | - | - | 49.3 | |
| A (仅音频) | - | - | 52.3 | |
| VideoLLaMA2 | A+V | 6 | 3 | 46.6 |
| OneLLM | A+V | 8 | 3 | 38.5 |
该表显示,对于所有评估的开源Omni-LLM,联合音视频(A+V)模态的性能在大多数任务上优于其单模态基线(No > Nu),且模型整体性能越强(如Qwen2.5-Omni),模态融合带来的提升越明显。
⚖️ 评分理由
- 学术质量:6.0/7:论文工作扎实,基准设计全面且严谨(100%音视频关联),自动化流水线创新性强且实用,实验评估系统全面。扣分点在于,其核心贡献是“评估基准”而非“模型或算法”,在方法论的原创性深度上有所局限。
- 选题价值:1.5/2:音视频联合推理是多模态AI的关键挑战,该基准填补了领域空白,对评估和推动Omni-LLM发展具有明确且重要的价值。1.5分是因为其应用场景主要局限于模型评估和学术研究,直接的工业应用价值相对间接。
- 开源与复现加成:0.5/1:论文承诺公开数据集(链接已提供),并详细描述了生成流程的Prompt(见附录),这为复现其基准提供了基础。但未提及提供代码仓库、训练好的模型权重或完整的评估脚本,因此复现存在一定门槛,加成有限。