📄 JavisDiT++: Unified Modeling and Optimization for Joint Audio-Video Generation
#音视频 #流匹配 #扩散模型 #多模态模型 #偏好优化
🔥 9.0/10 | 前25% | #音视频 | #流匹配 | #扩散模型 #多模态模型
学术质量 6.5/7 | 选题价值 1.8/2 | 复现加成 0.8 | 置信度 高
👥 作者与机构
- 第一作者:Kai Liu (浙江大学)
- 通讯作者:Hao Fei (新加坡国立大学)
- 作者列表:
- Kai Liu (浙江大学)
- Yanhao Zheng (未说明)
- Kai Wang (多伦多大学)
- Shengqiong Wu (新加坡国立大学)
- Rongjunchen Zhang (HiThink Research)
- Jiebo Luo (罗切斯特大学)
- Dimitrios Hatzinakos (多伦多大学)
- Ziwei Liu (南洋理工大学)
- Hao Fei (新加坡国立大学)
- Tat-Seng Chua (新加坡国立大学)
💡 毒舌点评
这篇论文的亮点在于提出了一个极其简洁有效的统一架构(MS-MoE)和精确的时间对齐策略(TA-RoPE),以相对较低的模型参数(2.1B)和数据量(~1M)达到了接近商业模型(Veo3)的SOTA性能。短板是其核心贡献高度依赖特定的视频生成骨干(Wan2.1),这虽然加速了研发,但也意味着其音视频联合生成的泛化能力与独立性有待进一步验证,且其对训练数据质量与分布的敏感性(见消融研究)暗示了在开放域场景下的潜在挑战。
📌 核心摘要
本文旨在解决现有开源联合音视频生成(JAVG)模型在生成质量、音视频时序同步性以及与人类偏好对齐方面落后于商业模型(如Veo3)的问题。其核心方法是构建一个基于Wan2.1视频生成模型的统一DiT框架,主要创新包括:1)采用模态特定专家混合(MS-MoE)设计,通过共享注意力层促进模态交互,同时使用独立的FFN增强单模态生成质量;2)提出时间对齐旋转位置编码(TA-RoPE),在位置ID的第0维度强制对齐音频和视频token,实现显式的帧级时间同步;3)首次将人类偏好对齐引入JAVG领域,设计了音视频直接偏好优化(AV-DPO),利用多奖励模型构建偏好数据,统一提升生成质量、一致性与同步性。与已有方法相比,该架构更简洁高效,避免了复杂的双流设计或拼接策略。实验表明,在仅使用约100万条公开数据训练后,JavisDiT++在JavisBench基准的多个维度(质量、一致性、同步性)上显著优于JavisDiT和UniVerse-1,达到了开源SOTA水平。其实际意义在于为原生联合音视频生成建立了一个高效且性能强大的基线,推动了该领域的研究。主要局限性包括:模型性能对特定视频骨干和训练数据质量/多样性有较强依赖;当前仅支持文本到音视频生成,可控性与任务扩展性有待探索。
🏗️ 模型架构
JavisDiT++的核心是一个统一的扩散Transformer(DiT)骨干,用于处理联合的文本、视频和音频token。其整体架构如下所示:
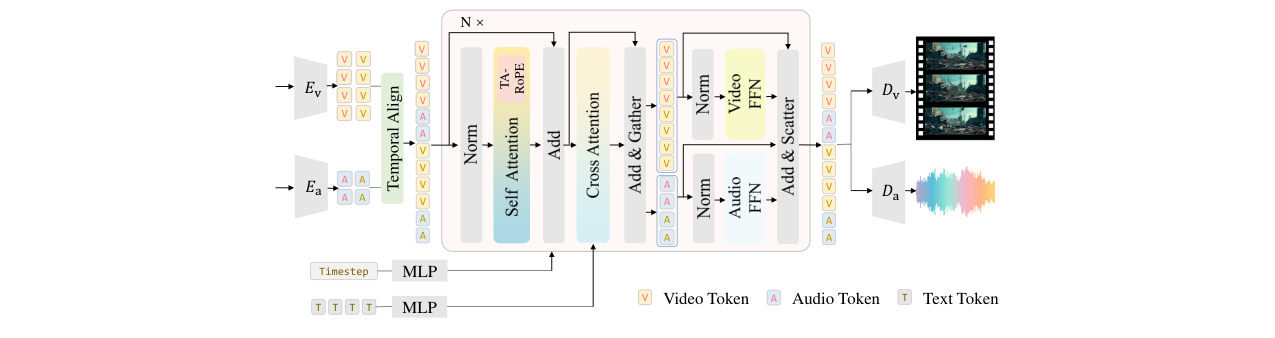
该架构的工作流程如下:
- 输入处理:输入文本提示经由冻结的文本编码器(umT5-xxl)得到文本token。视频片段通过冻结的视频VAE编码为视频token,音频片段(梅尔频谱图)通过冻结的音频VAE编码为音频token。
- Token拼接与注意力:将视频、音频和文本token在序列维度拼接,送入一系列Transformer块。每个块包含一个共享的多头自注意力层,让所有模态的token相互交互,实现密集的跨模态信息交换。这是MS-MoE设计的核心,保证了模态间的互信息建模。
- 模态特定前馈网络(MS-FFN/MS-MoE):经过共享注意力层后,token按模态被分离。视频token被路由到专用的视频FFN,音频token被路由到专用的音频FFN。文本token也与视频FFN交互。这种设计隔离了模态间的干扰,让每个分支专注于其模态内的特征聚合,类似于传统MoE的好处(扩大模型容量但不增加每个token的推理计算量)。
- 位置编码与时间对齐:模型使用旋转位置编码(RoPE)。视频token使用标准的3D RoPE (t, h, w)。音频token采用时间对齐RoPE(TA-RoPE),其位置ID定义为
([t·Tv/Ta], t+H, m+W)。这确保了在时间维度(第0维)上,对应同一时间窗口的音频和视频token拥有相同的时间ID,实现了显式的帧级对齐,同时通过偏移H和W避免了ID重叠。 - 预测与解码:DiT预测速度场(对于流匹配),输出经过去噪的音频和视频token,最后分别通过各自的VAE解码器重建为最终的视频和音频。
该架构的关键设计动机在于简洁性与效率的平衡。相比于JavisDiT的双流架构和复杂的时空先验,或UniVerse-1的预训练模型拼接,本架构用一个统一骨干加模态特定FFN实现了类似或更优的效果,且推理速度更快。
💡 核心创新点
模态特定专家混合(MS-MoE)架构:
- 之前局限:单FFN处理混合模态token(如UniForm)会导致模态信息损失;复杂的双流架构(如JavisDiT、UniVerse-1)参数冗余、训练和推理成本高。
- 如何起作用:采用共享注意力层促进跨模态交互,随后用确定性的模态特定FFN进行特征处理。这既保证了模态间信息的充分交换,又隔离了FFN层中的模态干扰,让模型专注于单模态特征建模。
- 收益:在模型总参数增至2.1B(相比骨干1.3B)的同时,保持了每个token的激活参数不变(1.3B),在不增加推理开销的情况下显著提升了性能(表2)。
时间对齐旋转位置编码(TA-RoPE):
- 之前局限:隐式同步机制(如JavisDiT的ST-Prior、UniVerse-1的缝合策略)控制不够直接,或会引入额外的计算开销(如帧级交叉注意力)。
- 如何起作用:通过精心设计位置ID,在RoPE中直接、显式地将音频token的时间ID与对应视频帧的时间ID对齐。同时通过偏移其他维度确保ID不重叠,避免了位置混淆(与Qwen2.5-Omni的策略对比见图4及附录C)。
- 收益:以零额外计算成本(表3)实现了更精确、更鲁棒的音视频时间同步,显著降低了DeSync指标。
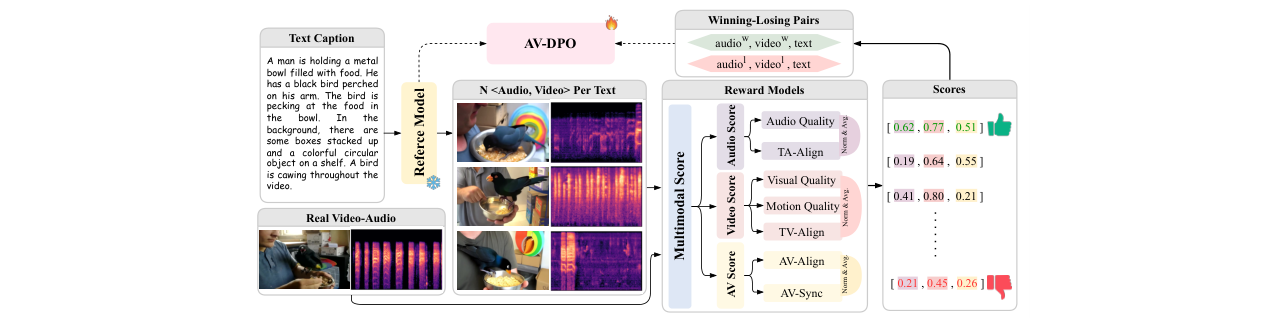
音视频直接偏好优化(AV-DPO):
- 之前局限:JAVG领域尚未有工作将人类偏好对齐技术应用于提升生成质量与一致性。
- 如何起作用:首次将DPO引入JAVG。利用多个奖励模型(AudioBox, VideoAlign, ImageBind, Synchformer)从音频质量、视频质量、音视频对齐三个模态感知维度评估生成样本,构建模态一致的偏好对。然后优化策略模型,使其相对于参考模型更倾向于生成赢得配对的样本。
- 收益:在监督微调(SFT)基础上进一步提升了模型的感知质量、语义一致性和时间同步性(图9),使生成结果更符合人类偏好。
🔬 细节详述
- 训练数据:
- 音频预训练:使用JavisDiT收集的780K音频-文本对,涵盖AudioSet, AudioCaps, VGGSound等多个公开数据集。
- 音视频SFT:从TAVGBench中筛选的330K高质量文本-音频-视频三元组。筛选过程包括:使用FunASR过滤语音视频、使用美学评分(>0.4)、运动评分(>0.1)和OCR评分(<5.0)进行过滤。
- 音视频DPO:使用独立的25K样本,避免与SFT数据重叠。偏好对构建时,为每个提示生成3个候选样本,并加入真实样本,由奖励模型打分。
- 损失函数:
- 流匹配损失(公式2):核心生成损失,最小化预测速度场与目标速度场的差异。
- AV-DPO损失(公式6):用于偏好优化,
L_av_DPO = -E[log σ(-β_v (Diff_v_policy - Diff_v_ref) - β_a (Diff_a_policy - Diff_a_ref))]。其中Diff是策略模型和参考模型预测速度场与真实速度场的L2误差之差。 - 训练时结合两者:DPO阶段同时使用DPO损失和流匹配损失进行正则化,防止过拟合。
- 训练策略:
- 三阶段渐进训练:
- 阶段1:音频预训练:在Wan2.1-1.3B-T2V骨干上,仅训练新增的音频FFN、嵌入层和预测头。学习率1e-4,50个epoch。
- 阶段2:音视频SFT:应用LoRA对骨干和音频FFN进行微调。学习率1e-4,2个epoch。
- 阶段3:音视频DPO:保留LoRA参数,在25K偏好数据上训练。学习率1e-5,1个epoch。
- 优化器与调度:使用AdamW优化器,带有1000步的warmup。
- 三阶段渐进训练:
- 关键超参数:
- 模型大小:骨干为1.3B参数(Wan2.1-1.3B-T2V)。训练后总参数2.1B(LoRA合并后)。
- 骨干结构:30层Transformer,隐藏维度1536。
- LoRA配置:rank=64,应用于注意力层和FFN层(AV-LoRA)。
- DPO超参:β_video=3000,β_audio=1000(见附录D.3分析)。
- 训练硬件:论文未明确说明GPU型号,但提及训练时长:音频预训练16 GPU天,音视频SFT 16 GPU天,DPO 3 GPU天。
- 推理细节:使用Rectified Flow求解ODE进行生成。模型支持动态时长(2-5秒)和分辨率(240p-480p)。运行时,生成4秒240p视频约需10秒(表1)。
📊 实验结果
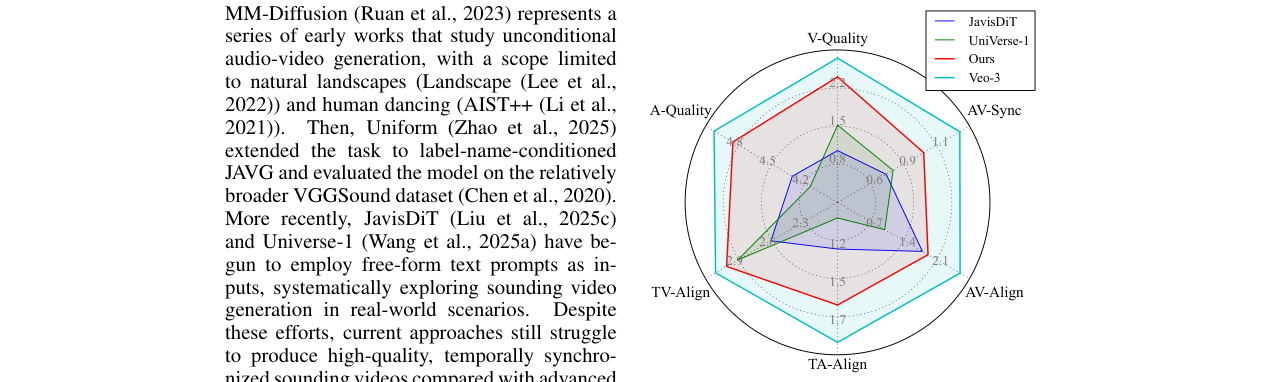
本文在JavisBench(10,140样本)和JavisBench-mini(1,000样本)上进行了全面评估,涵盖质量、一致性和同步性三大类共11个指标。
主要对比结果(表1):
| 模型 | 参数量 | FVD↓ | FAD↓ | TV-IB↑ | TA-IB↑ | CLIP↑ | CLAP↑ | AV-IB↑ | AVHScore↑ | JavisScore↑ | DeSync↓ | 运行时↓ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T2A+A2V流水线 | ||||||||||||
| TempoTkn | 1.3B | 539.8 | - | 0.084 | - | 0.205 | - | 0.139 | 0.122 | 0.103 | 1.532 | 20s |
| TPoS | 1.0B | 839.7 | - | 0.201 | - | 0.229 | - | 0.124 | 0.129 | 0.095 | 1.493 | 19s |
| T2V+V2A流水线 | ||||||||||||
| ReWaS | 0.6B | - | 9.4 | - | 0.123 | - | 0.280 | 0.110 | 0.104 | 0.079 | 1.071 | 17s |
| MMAudio | 0.1B | - | 6.1 | - | 0.160 | - | 0.407 | 0.198 | 0.182 | 0.150 | 0.849 | 15s |
| 联合生成模型 (T2AV) | ||||||||||||
| MM-Diff | 0.4B | 2311.9 | 27.5 | 0.080 | 0.014 | 0.181 | 0.079 | 0.119 | 0.109 | 0.070 | 0.875 | 9s |
| JavisDiT | 3.1B | 204.1 | 7.2 | 0.263 | 0.143 | 0.302 | 0.391 | 0.197 | 0.179 | 0.154 | 1.039 | 30s |
| UniVerse-1 | 6.4B | 194.2 | 8.7 | 0.272 | 0.111 | 0.309 | 0.245 | 0.104 | 0.098 | 0.077 | 0.929 | 13s |
| JavisDiT++ (Ours) | 2.1B | 141.5 | 5.5 | 0.282 | 0.164 | 0.316 | 0.424 | 0.198 | 0.184 | 0.159 | 0.832 | 10s |
关键发现:
- 全面SOTA:JavisDiT++在几乎所有指标上大幅超越了之前的开源模型(JavisDiT, UniVerse-1)。例如,在衡量视频质量的FVD(141.5 vs 194.2)、音频质量的FAD(5.5 vs 8.7)、以及关键的时间同步指标DeSync(0.832 vs 0.929)上均取得显著优势。
- 效率优势:模型参数量(2.1B)远小于JavisDiT(3.1B)和UniVerse-1(6.4B),且推理速度更快(10s vs 30s/13s),证明了MS-MoE架构的高效性。
- 人类偏好对齐:如图9所示的用户研究,经AV-DPO优化后的模型比优化前获得超过25%的人类偏好投票优势,验证了该方法的有效性。
消融实验关键结果(表2,表3,表4):
- 架构设计(表2):MS-MoE在质量(FVD 221.3)、一致性(AV-IB 0.194)和同步性(DeSync 0.807)上均优于“共享DiT+LoRA/全微调”的基线方案。
- 同步机制(表3):TA-RoPE(DeSync 0.807,1m4s)在性能和效率上均优于ST-Prior(0.863,1m10s)和帧级注意力(0.850,1m22s)。
- AV-DPO奖励策略(表4):采用“模态感知”策略(Modality-Micro)在质量(FVD 198.5)、一致性(AV-IB 0.201)和同步性(DeSync 0.776)上均取得最佳效果,显著优于模态无关策略。
⚖️ 评分理由
- 学术质量:6.5/7 - 论文提出了三个清晰、互补的技术创新(MS-MoE, TA-RoPE, AV-DPO),并进行了充分的实验验证,包括在多个基准上的定量比较、详细的消融研究以及人类评估。技术方案设计合理,实验数据详实,结论可信。扣分点在于其高度依赖特定视频模型骨干,且训练数据规模相对有限(~1M),限制了其作为通用JAVG解决方案的完备性。
- 选题价值:1.8/2 - 联合音视频生成是多模态AI生成领域的前沿核心任务,对于内容创作(短视频、电影、游戏、VR)具有巨大的潜在应用价值。本文聚焦于解决开源模型与商业模型之间的关键差距,选题具有高度的现实意义和影响力。
- 开源与复现加成:+0.8/1 - 论文明确承诺将发布所有代码、模型和处理后的数据集,并在附录中提供了极其详细的训练配置(三阶段细节、超参数)、数据处理流程和评估设置,极大地方便了学术复现和后续研究。代码、模型和数据的公开承诺是重要加成。