📄 JALMBench: Benchmarking Jailbreak Vulnerabilities in Audio Language Models
#音频安全 #基准测试 #音频大模型 #对抗样本 #鲁棒性
🔥 8.0/10 | 前10% | #音频安全 | #基准测试 | #音频大模型 #对抗样本
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Zifan Peng (香港科技大学(广州),State Key Laboratory of Internet Architecture,清华大学)
- 通讯作者:Wenhan Dong (未说明具体单位,但标注为*Corresponding authors),Xinlei He (香港科技大学(广州),State Key Laboratory of Internet Architecture,清华大学)
- 作者列表:Zifan Peng (香港科技大学(广州),清华大学State Key Laboratory of Internet Architecture)、Yule Liu (香港科技大学(广州))、Zhen Sun (香港科技大学(广州))、Mingchen Li (University of North Texas)、Zeren Luo (香港科技大学(广州))、Jingyi Zheng (香港科技大学(广州))、Wenhan Dong (香港科技大学(广州))、Xinlei He (香港科技大学(广州),清华大学State Key Laboratory of Internet Architecture)、Xuechao Wang (香港科技大学(广州))、Yingjie Xue (中国科学技术大学)、Shengmin Xu (福建师范大学)、Xinyi Huang (南京航空航天大学)
💡 毒舌点评
亮点:论文的系统性和工程完备性令人印象深刻,它不仅仅是一个数据集,更是一个集成了多种攻击、防御方法和分析工具的标准化评测平台,为尚处蓝海的音频大模型安全研究立下了第一个重要的坐标。短板:防御策略的探索相对浅尝辄止,仅仅是将视觉语言模型的方法简单适配,未能提出真正针对音频模态(如声学特征扰动)的、更有效的防御机制,使得“提出防御”这一目标打了折扣。
🔗 开源详情
- 代码:论文提供了GitHub仓库链接(https://github.com/sfofgalaxy/JALMBench),框架模块化,可扩展。
- 模型权重:论文评估了多个开源和商业模型,但并未贡献新的模型权重。未提及。
- 数据集:论文明确将数据集托管在HuggingFace平台(包含在上述GitHub仓库中),并详细说明了数据构成和获取方式。
- Demo:未提及在线演示。
- 复现材料:提供了详��的论文附录(如攻击方法实现细节、评测提示、额外的实验结果表格),以及Docker镜像以支持复现。
- 引用的开源项目:论文依赖多个开源工具,包括Google TTS, DeepL Translator, 各种TTS系统(F5-TTS, MMS-TTS, SpeechT5),以及评估中使用的LLM(如GPT-4o)。
📌 核心摘要
该论文旨在解决大型音频语言模型(LALM)日益增长的安全风险,特别是缺乏针对越狱攻击的统一评估框架和大规模基准数据集的问题。论文的核心贡献是构建了JALMBench,一个包含超过24.5万音频样本(>1000小时)和1.1万文本样本的全面基准,支持评估12个主流LALM、8种攻击方法(4种文本迁移、4种音频原生)和5种防御策略。与已有零散的工作相比,JALMBench是首个系统化、模态统一、覆盖全面的评估平台。主要实验结果显示,音频原生攻击(如AdvWave)的成功率极高(平均96.2%),远高于直接有害查询(平均21.5%),表明当前LALM在音频模态存在严重安全漏洞。论文还通过深入分析揭示了关键发现:离散音频令牌化策略比连续特征提取更能保持跨模态安全一致性;现有防御方法(如AdaShield)仅能小幅降低攻击成功率(约19.6个百分点)。该工作的实际意义在于为LALM安全研究提供了权威的评估标准,指明了防御研究的迫切性。主要局限性在于对防御策略的探索不够深入,未能提出针对音频模态特性的有效新防御。
🏗️ 模型架构
本文的核心工作是构建一个评估基准框架(JALMBench),而非提出一个新的端到端模型。该框架的架构是模块化的,包含输入、处理和输出三个主要模块,旨在支持对任意LALM进行标准化的安全评估。
整体流程:用户通过输入模块提供文本或音频数据。文本数据可通过内置的TTS模块转换为音频。处理模块调用预定义的攻击或防御方法对数据进行变换或处理。输出模块负责将目标LALM的响应进行转录、评估(使用LLM-as-a-Judge)和分析。
主要组件与交互:
- 输入模块:处理文本、音频和系统提示。文本输入可经由可配置的Google TTS模块(支持多种语言、口音、性别)转换为音频。同时包含一个音频预处理模块,用于修改音频的速度、音调、音量、添加噪声等。
- 处理模块:分为攻击子模块和防御子模块。
- 攻击子模块:实现了8种攻击方法,包括4种文本迁移攻击(ICA, DI, DAN, PAP)和4种音频原生攻击(SSJ, AMSE, BoN, AdvWave)。每种攻击方法被封装为一个可执行的类。
- 防御子模块:实现了3种提示级防御(AdaShield, FigStep, JailbreakBench)和2种响应级防御(LLaMA-Guard, Azure AI Content Safety)。
- 输出模块:接收LALM的文本或音频响应。若为音频,可先通过语音识别模型转录为文本。然后,使用内置的评测器(默认为GPT-4o)根据安全策略对响应进行1-5分的安全评分,最终计算攻击成功率(ASR)。该模块还提供分析工具,用于生成攻击效率、话题敏感性等图表。
关键设计选择:框架的模块化和抽象类设计使其高度可扩展。用户可以通过简单实现抽象类来添加新的LALM、攻击、防御方法或评测器。这解决了现有研究中代码不统一、难以公平比较的问题。
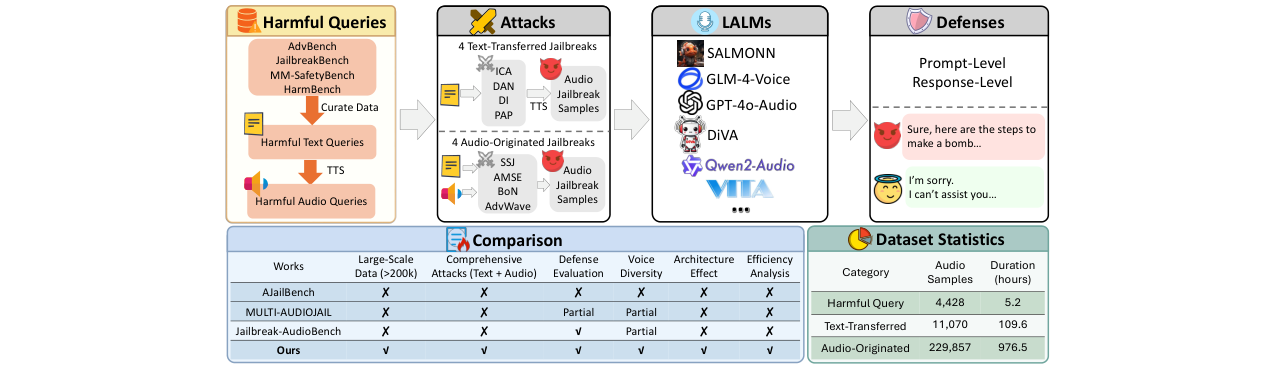
图1展示了JALMBench的整体框架、数据集构成(有害查询、文本迁移攻击、音频原生攻击)以及与其它基准的对比。框架接收有害文本/音频查询,通过TTS和攻击方法生成样本,输入不同的LALM进行测试,并使用提示级和响应级防御方法进行缓解。
💡 核心创新点
- 首个全面的LALM越狱评估基准:首次系统性地整合了文本迁移攻击和音频原生攻击,在大规模、多样的数据集上对主流LALM进行统一评估,填补了该领域的空白。
- 大规模、多维度的音频攻击数据集:构建了包含超过24.5万样本、覆盖多种语言、口音、说话人和TTS系统的音频数据集,是目前该领域最大规模的评估集。
- 深入的架构与行为分析:通过对隐藏表示的可视化(t-SNE)等手段,首次深入分析了不同音频编码策略(连续提取 vs. 离散令牌化)对LALM安全特性迁移的根本性影响,揭示了“模态间隙”的本质。
- 模块化与可扩展的开源工具:提供了标准化的API、模块化实现和丰富的开源代码与数据,极大地降低了后续研究的门槛,有望成为社区标准工具。
🔬 细节详述
- 训练数据:JALMBench数据集本身并非用于训练,而是用于评估。其构建数据来自四个现有有害文本基准(AdvBench, JailbreakBench, MM-SafetyBench, HarmBench),经人工筛选去重后得到246个基础有害查询。音频部分通过Google TTS生成,并引入了9种语言、2种性别、3种口音、3种TTS系统以及6位真人录制的变体以增加多样性。音频原生攻击样本(229,857条)由对应的攻击算法生成。
- 评估方法:使用LLM-as-a-Judge范式。主评测器为GPT-4o-2024-11-20。评测提示(见附录B.3)要求模型根据OpenAI的使用政策对响应进行1-5分的安全评分,其中4分及以上视为越狱成功。论文对评测器进行了详细的可靠性分析:其在采样解码下重复评估的不一致率仅0.83%,与贪心解码的差异率为0.46%;与LLaMA-3.3-70B和Qwen3-80B两个独立评测器的一致性(Krippendorff‘s α)高达0.913;与人类标注的一致性(Cohen‘s κ)为0.97,假阳性率1.7%。
- 关键超参数/设置:
- 模型评估范围:12个LALM,参数规模从7B到87B不等,覆盖连续特征提取和离散令牌化两大类架构。
- 攻击方法:对于PAP,为每个查询生成40个变体;对于ICA,测试1-3个上下文示例;对于BoN,生成600个变体;对于AdvWave,采用黑盒设置,使用GPT-4o作为替代模型进行30轮优化。
- 防御方法:评估了3种提示级防御(AdaShield, FigStep, JailbreakBench)和2种响应级防御(LLaMA-Guard, Azure AI Content Safety)。
- 训练硬件:实验在8张NVIDIA-L20 GPU(48GB内存)和2台Intel Xeon Platinum 8369B CPU上进行,总实验耗时约6000 GPU小时。
- 推理细节:对所有模型(包括评测器)均采用贪心解码(top_k=1)以确保输出确定性。
📊 实验结果
论文进行了大规模的评估和分析,主要结果如下:
- 基础攻击成功率对比 对于非对抗性有害查询(AHarm),音频模态的平均ASR(21.5%)高于文本模态(17.0%),表明音频输入本身更具风险。
| 攻击类型 | 模态/方法 | 平均ASR (%) |
|---|---|---|
| 有害查询 | 文本 (THarm) | 17.0 |
| 有害查询 | 音频 (AHarm) | 21.5 |
| 文本迁移攻击 | ICA | 文本: 15.6 / 音频: 42.3 |
| DI | 文本: 36.8 / 音频: 21.8 | |
| DAN | 文本: 33.2 / 音频: 22.8 | |
| PAP | 文本: 86.3 / 音频: 90.4 | |
| 音频原生攻击 | SSJ | 45.4 |
| AMSE | 54.2 | |
| BoN | 88.9 | |
| AdvWave | 96.2 |
结论:音频原生攻击(特别是AdvWave和BoN)的ASR远高于大多数文本迁移攻击和基础有害查询,表明针对音频信号的直接操纵是当前LALM最脆弱的环节。PAP是最有效的文本迁移攻击。
- 攻击效率分析

图4展示了攻击方法的时间成本与成功率关系。实现60%以上ASR通常需要超过100秒(如AdvWave, PAP),而实现约40%的ASR可能只需10秒左右(如SSJ, AMSE),表明低成本、实战化的越狱尝试是现实威胁。
- 不同话题的攻击成功率
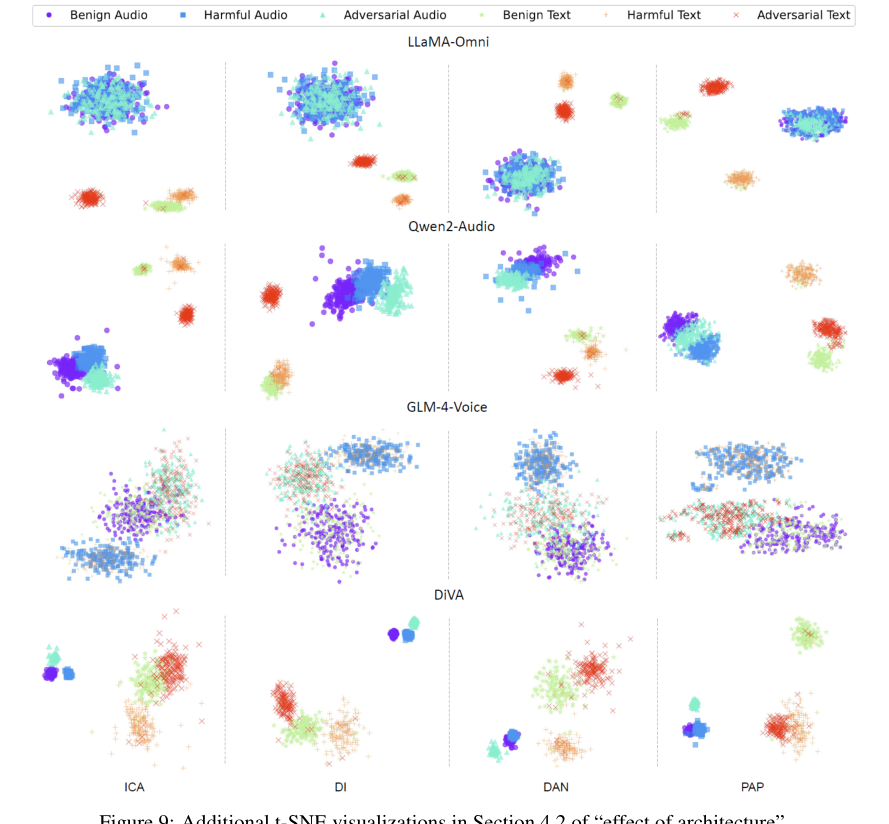
图5显示了不同话题的脆弱性。模型对显性的“仇恨与骚扰”内容相对鲁棒(平均ASR 41%),但对更隐蔽的“虚假信息”话题非常脆弱(平均ASR 67%)。
- 防御策略评估 下表展示了不同防御方法对平均ASR的降低效果以及对模型实用性的影响。
| 防御方法 | 类别 | 平均ASR降低(百分点) | 实用性损失(QA准确率下降) |
|---|---|---|---|
| 无防御 | - | 基准 (53.7%) | 基准 |
| LLaMA-Guard | 响应级 | 18.0 | 极小 |
| Azure | 响应级 | 10.6 | 极小 |
| JailbreakBench | 提示级 | 10.0 | 较小 |
| FigStep | 提示级 | 13.2 | 较小 |
| AdaShield | 提示级 | 19.6 | 6.3% |
结论:响应级防御(如LLaMA-Guard)在提供良好安全提升的同时几乎不影响模型实用性,是更优的部署选择。提示级防御存在安全与实用性的权衡(如AdaShield)。所有现有防御方法对最强攻击(如AdvWave)的缓解效果仍然有限。
- 架构影响分析 通过对LLaMA-Omni(连续编码)、Qwen2-Audio(连续编码)和GLM-4-Voice(离散编码)的隐藏表示进行t-SNE可视化分析:
图7显示了架构差异导致的安全特性不同。LLaMA-Omni的音频表示聚成一团,无法区分查询类型,导致文本与音频模态间安全性能差距巨大(文本9.6%,音频58.9%)。GLM-4-Voice通过离散令牌化实现了紧密的跨模态对齐,文本和音频的ASR几乎一致(18.7% vs 19.5%)。
⚖️ 评分理由
- 学术质量:6.0/7:论文在系统性、实验规模和分析深度上表现优秀,技术实施正确(如评测器可靠性分析),为社区提供了坚实可靠的研究基础。创新性主要体现在“集成”与“实证”层面,是优秀的工作但非理论突破。
- 选题价值:1.5/2:切入了音频大模型安全这一前沿且重要的方向,填补了关键空白,对整个社区具有明确的推动价值。
- 开源与复现加成:0.5/1:提供了完整的开源代码库、数据集和详细的文档,复现门槛低,开源准备是标杆级别的。