📄 Incentivizing Consistent, Effective and Scalable Reasoning Capability in Audio LLMs via Reasoning Process Rewards
#音频问答 #强化学习 #音频大模型 #推理
🔥 8.5/10 | 前10% | #音频问答 | #强化学习 | #音频大模型 #推理
学术质量 8.5/7 | 选题价值 2.0/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Jiajun Fan (伊利诺伊大学厄巴纳-香槟分校 Siebel 计算与数据科学学院)
- 通讯作者:未说明
- 作者列表:Jiajun Fan (伊利诺伊大学厄巴纳-香槟分校),Roger Ren (Amazon),Jingyuan Li (Amazon),Rahul Pandey (Amazon),Prashanth Gurunath Shivakumar (Amazon),Ivan Bulyko (Amazon),Ankur Gandhe (Amazon),Ge Liu (伊利诺伊大学厄巴纳-香槟分校),Yile Gu (Amazon)
💡 毒舌点评
亮点在于系统性地诊断并解决了音频LLM推理的“测试时逆缩放”这一实际且重要的“反直觉”现象,并建立了一套从过程奖励到可扩展能力的完整方法论。短板是其基于GRPO的在线强化学习训练计算成本高昂(需要8块H200训练61小时),且多奖励组件的超参数调节(如α权重)虽经实验验证,但给实际复现增加了一定复杂度。
🔗 开源详情
- 代码:论文中明确承诺“所有源代码和训练模型将在出版后公开”,但当前未提供具体链接。
- 模型权重:论文承诺公开训练好的模型权重,未提供具体链接。
- 数据集:使用AVQA数据集进行训练,该数据集是公开的。论文通过模板进行了数据增强,增强模板在附录中说明。
- Demo:论文中未提及在线演示。
- 复现材料:提供了极其详尽的复现指南,包括:完整的算法伪代码(附录C)、详细的训练超参数(附录B.4)、奖励函数计算细节及关键词列表(附录B.6)、评估基准说明、硬件信息等。复现材料非常充分。
- 论文中引用的开源项目:基于Qwen2.5-Omni-7B模型进行训练,其基线代码参考了Ke-Omni-R的开源实现。
📌 核心摘要
本文针对音频大语言模型(Audio LLMs)在引入链式思维(CoT)推理时性能反而下降的“测试时逆缩放”问题进行了深入研究。作者指出,问题根源不在于推理本身,而在于现有训练方法(监督微调或仅基于结果正确性的强化学习)未能对推理过程进行有效监督,导致模型产生幻觉、不一致且逻辑混乱的推理链。为此,论文提出了CESAR(Consistent, Effective, and Scalable Audio Reasoners)框架,其核心创新在于将强化学习的优化目标从仅关注答案正确性(结果奖励)扩展为同时激励推理过程的一致性、结构化模式、因果逻辑、领域知识整合以及推理深度的合理性(过程奖励),并使用GRPO算法进行在线训练。与仅使用结果奖励的基线方法(如Ke-Omni-R)相比,CESAR不仅解决了测试时逆缩放问题,还使推理链长度与性能呈现积极的缩放关系,并发现了模型特定的“推理甜点”。实验表明,CESAR在MMAU Test-mini基准上达到77.1%的准确率,超越了GPT-4o Audio(62.5%)和Gemini 2.5 Pro(71.6%),在MMSU推理任务上达到近人类水平(81.07%),并通过人类评估和AI评判证实了其推理质量的显著提升。论文还揭示了推理能力提升对模型感知能力的协同增强作用。主要局限性在于训练计算开销大,且当前音频模型的性能瓶颈已部分转移至基础感知能力。
🏗️ 模型架构
本文的核心贡献并非提出一种新的端到端神经网络架构,而是设计了一套用于训练现有音频LLM(基础模型为Qwen2.5-Omni-7B)的强化学习框架。其整体训练和推理流程如下:
训练阶段(基于GRPO的在线强化学习):
- 输入:音频
ai、问题qi、选项集Ci和正确答案yi。 - 采样:使用当前策略模型
πθ对每个输入采样K=8组回答,每组包含思考过程ti和答案ŷi。 - 多维度奖励计算:对每组回答,计算总奖励
R_total(s_i)。该奖励由两部分组成:- 可验证奖励:包括答案准确率奖励
R_acc(二值)和格式奖励R_format(确保输出包含 `` 和<answer>标签)。 - 推理过程奖励:这是核心创新,包括:
- 一致性奖励
R_consistency:计算思考过程与答案、思考过程与问题上下文(包含选项)之间的语义重叠度,确保推理与结论、问题对齐。 - 关键词奖励
R_keywords:奖励思考过程中出现的结构化分析模式(如“首先”、“比较”)、逻辑因果词汇(如“因此”、“基于”)和领域特定术语(如“和弦”、“音调”)。 - 过度思考惩罚
R_overthinking:对过长的思考过程施加线性惩罚,防止冗余和错误累积。
- 一致性奖励
- 可验证奖励:包括答案准确率奖励
- 优势计算与策略优化:计算每组回答相对于组平均奖励的优势值
A(s_i),然后使用GRPO目标函数更新模型参数θ,同时加入KL散度正则化以保持训练稳定。
推理阶段:
模型在提示下生成结构化的输出:</think>ti</think><answer>ŷi</answer>。通过调节提示中``标签内的最大思考长度 L_max_think,可以实现“测试时缩放”,从而找到模型性能最优的“推理甜点”。
(图1:框架对比图,展示了从监督微调到仅结果奖励的RL(如Ke-Omni-R),再到本文提出的CESAR(过程奖励)的演进,以及不同方法在测试时缩放下的性能变化趋势。)
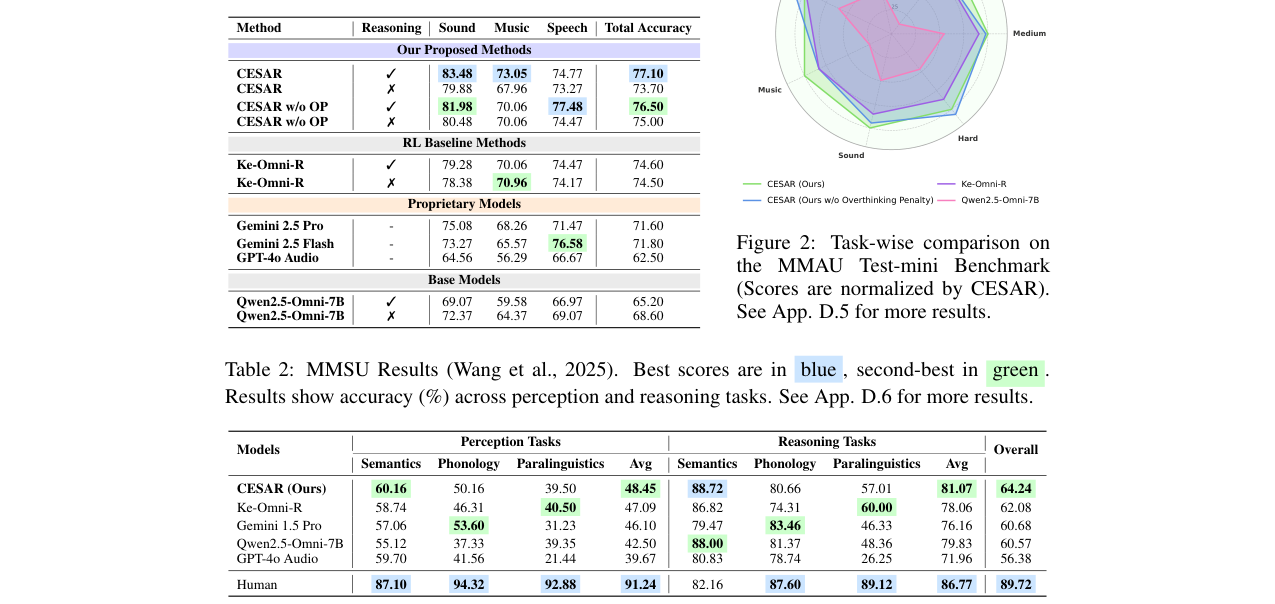
(图2:MMAU Test-mini基准上不同方法在不同难度(Easy, Medium, Hard)任务上的表现雷达图,显示了CESAR方法在各难度上相比基线的优势,以及去除过度思考惩罚(OP)后在困难任务上更深度分析的倾向。)
💡 核心创新点
- 系统诊断“测试时逆缩放”现象:首次明确指出并定义了Audio LLM中推理链越长性能越差的现象,将其根源归结为训练过程对推理过程监督不足,而非推理本身无用。
- 提出CESAR过程奖励框架:从“结果验证”转向“过程奖励”。设计了一套多维度奖励函数,不仅奖励答案正确和格式,更关键地奖励推理过程的内部一致性、结构化逻辑、领域知识运用,并惩罚无效的冗余思考。这是对现有仅基于结果正确性的RLVR方法的根本性改进。
- 实现可扩展推理并发现“推理甜点”:通过过程奖励训练,使模型性能随推理链增长先升后降,形成可预测的“甜点”,从而解锁了推理能力的可扩展性,将测试时缩放从“有害”变为“有利”。
- 揭示推理能力的协同提升效应:证明了通过过程奖励培养的强推理能力,能同时提升模型在无推理模式下的直接回答准确率(如在MMAU Test-mini上从68.60%提升至73.70%)以及基础感知任务(如MMSU感知任务)的性能。
- 建立全面的推理质量评估体系:引入了基于GPT-4o Audio的AI-as-Judge评估框架和大规模人工评估,超越单纯的准确率指标,定量和定性地验证了推理过程质量的提升。
🔬 细节详述
- 训练数据:主要使用AVQA数据集,并通过模板化的数据增强(生成问题的不同措辞)来增加多样性。没有使用Ke-Omni-R中使用的MusicBench数据。
- 损失函数:基于GRPO的目标函数(公式9),其核心是最大化加权总奖励,并加入KL散度正则化。
- 训练策略:使用AdamW优化器,学习率1e-5,全局批量大小32。采用在线学习,每个训练步骤对每个样本采样K=8个回答。
- 关键超参数:奖励权重设置为α1=5.0(准确率),α2-α5=1.0(其他奖励)。最大输出长度
L_max_output设为256,用于计算过度思考惩罚。 - 训练硬件:在配备8块NVIDIA H200 GPU(各141GB HBM3e内存)的集群上进行,一次完整训练耗时约61.44小时。
- 推理细节:采用特定的提示模板,要求模型先在
中生成思考过程,再在`<answer>`中给出答案。通过改变提示中内的最大思考长度max_think_len来进行测试时缩放分析。 - 正则化或稳定训练技巧:在GRPO损失中加入KL散度项(
L_KL),以防止策略偏离参考策略过远,保证训练稳定性。
📊 实验结果
本文在多个主流音频理解基准上进行了全面评估,主要结果如下:
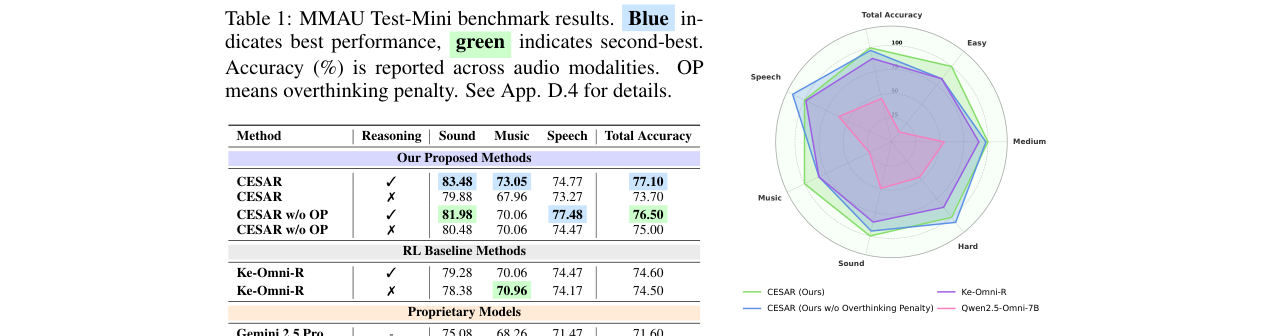
表1:MMAU Test-Mini基准结果(准确率%)
| 方法 | 推理 | 音效 | 音乐 | 语音 | 总体准确率 |
|---|---|---|---|---|---|
| CESAR (Ours) | ✓ | 83.48 | 73.05 | 74.77 | 77.10 |
| Ke-Omni-R | ✓ | 79.28 | 70.06 | 74.47 | 74.60 |
| Gemini 2.5 Pro | - | 75.08 | 68.26 | 71.47 | 71.60 |
| GPT-4o Audio | - | 64.56 | 56.29 | 66.67 | 62.50 |
| Qwen2.5-Omni-7B (Base) | ✓ | 69.07 | 59.58 | 66.97 | 65.20 |
表2:MMSU基准结果(准确率%)
| 模型 | 感知任务(平均) | 推理任务(平均) | 总体 |
|---|---|---|---|
| CESAR (Ours) | 48.45 | 81.07 | 64.24 |
| Ke-Omni-R | 47.09 | 78.06 | 62.08 |
| 人类 | 91.24 | 86.77 | 89.72 |
表3:MMAU-Pro基准结果(平均准确率%)
| 模型 | 平均准确率 |
|---|---|
| CESAR (Ours) | 56.4 |
| Ke-Omni-R | 54.5 |
| Gemini-2.5 Flash | 59.2 |
| GPT-4o Audio | 52.5 |
关键结论:
- SOTA性能:CESAR在MMAU Test-mini上取得77.10%的SOTA,显著超越GPT-4o Audio和Gemini 2.5 Pro。
- 推理能力接近人类:在MMSU推理任务上达到81.07%,接近人类水平(86.77%),并在语义推理上(88.72%)超越人类。
- 解决逆缩放:测试时缩放分析(图3左)显示,基线模型性能随思考长度增长而下降或波动,而CESAR性能先升后降,存在明确的“推理甜点”。
- 消融研究:逐步去除过程奖励组件会导致性能下降,证明了每个组件的贡献(表6)。例如,��除一致性奖励(即退化为Ke-Omni-R)后,总体准确率从77.10%降至74.60%。
- 推理质量评估:AI-as-Judge(图3右)和人类评估(表4)均显示,CESAR的推理过程远优于基线模型(如对基线Qwen2.5-Omni-7B有88.60%的胜率)。
(图3:左侧显示了MMAU Test-mini上不同方法随最大思考长度变化的性能曲线,CESAR展现出可扩展性和“推理甜点”;右侧为AI-as-Judge评估结果,显示CESAR的推理过程在头对头比较中占优。)
(图4:人类评估结果表格,显示CESAR在与基线模型的推理过程对比中,在所有音频模态上均获得高胜率。)
⚖️ 评分理由
- 学术质量:6.5/7:论文对音频LLM推理问题的诊断深刻且新颖,提出的CESAR框架方法论严谨、设计精巧(多维度过程奖励),实验极为充分且说服力强(多基准SOTA、全面的消融、人类/AI双重质量验证),结果显著优于现有方法。
- 选题价值:2/2:音频大模型的推理能力是当前多模态AI研究的前沿和关键瓶颈,本文工作对此提供了系统性的解决方案,对推动领域发展有重大价值,对音频/语音研究者具有高参考意义。
- 开源与复现加成:0/1:论文提供了非常详尽的复现信息(附录包含算法伪代码、超参数、奖励计算细节),并承诺开源代码和模型,但尚未实际发布。因此,暂不给予加成。