📄 Human or Machine? A Preliminary Turing Test for Speech-to-Speech Interaction
#语音对话系统 #模型评估 #基准测试 #多模态模型
✅ 7.5/10 | 前25% | #语音对话系统 | #模型评估 | #基准测试 #多模态模型
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 1.0 | 置信度 高
👥 作者与机构
- 第一作者:Xiang Li(北京邮电大学网络与交换技术国家重点实验室,深圳大数据研究院,香港中文大学(深圳),深圳环域研究院)
- 通讯作者:Jiale Han(香港科技大学)
- 作者列表:Xiang Li(北京邮电大学网络与交换技术国家重点实验室,深圳大数据研究院,香港中文大学(深圳),深圳环域研究院),Jiabao Gao(香港中文大学(深圳)),Sipei Lin(香港中文大学(深圳)),Xuan Zhou(香港中文大学(深圳)),Chi Zhang(香港中文大学(深圳)),Bo Cheng(北京邮电大学网络与交换技术国家重点实验室),Jiale Han(香港科技大学),Benyou Wang(深圳大数据研究院,香港中文大学(深圳),深圳环域研究院)
💡 毒舌点评
亮点是首次对语音到语音系统进行了图灵测试,并构建了一个包含18个细粒度维度的诊断框架,不仅指出了“通过/失败”,更深入剖析了“为何失败”,将瓶颈精准定位在非语义层面。短板在于,作为开创性工作,其评估的S2S系统数量和对话场景多样性仍有限,且伪人对话的脚本部分由GPT-4o生成,可能引入了额外的偏差。
🔗 开源详情
- 代码:论文中提供了GitHub仓库链接:https://github.com/Carbohydrate1001/Turing-Test。
- 模型权重:论文中明确提到公开了模型(“Our code, dataset, and model are publicly available”),但未直接提供权重下载链接,需从上述GitHub仓库获取。
- 数据集:论文中明确提到公开了数据集,同样需从上述GitHub仓库获取。
- Demo:论文中提到了部署了一个游戏化的在线评测平台,但未提供公开的在线演示链接。
- 复现材料:提供了极其详细的复现信息,包括:
- 数据收集的完整流程、参与者画像、初始化策略(附录B)。
- Turing测试平台的设计细节(附录C)。
- 18个细粒度维度的定义、标注指南、标注员信息及质量保证流程(附录D)。
- AI评委模型的训练框架、嵌入读取策略消融、模型消融、超参数调优(网格搜索与敏感性分析)的完整细节(附录E)。
- 论文中引用的开源项目:论文在构建伪人对话数据集时,引用了两个开源TTS模型:Nari Dia-1.6B (nari-labs, 2025) 和 Spark-TTS (Wang et al., 2025c)。在评估模型泛化性时,引用了CosyVoice2、Fisher和MultiDialog数据集。
📌 核心摘要
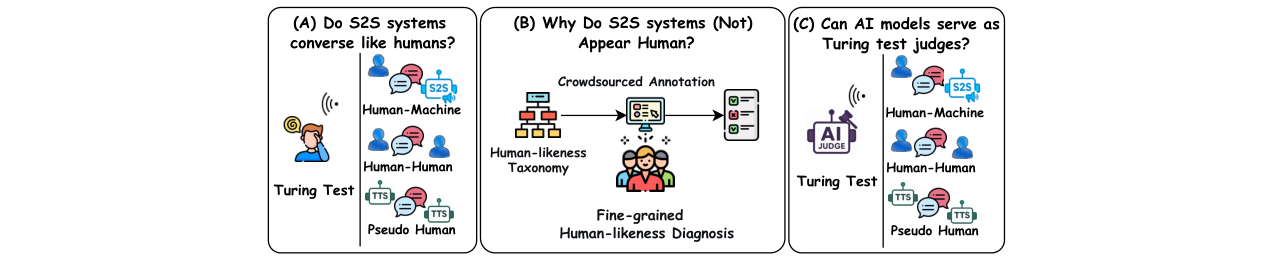
本文旨在回答一个关键问题:当前的语音到语音(S2S)系统能否像人类一样进行对话?为解决此问题,作者首次对S2S系统实施了图灵测试。核心方法是构建一个包含人-人、人-机和伪人(TTS合成)对话的高质量数据集,通过一个游戏化的在线平台收集了近3000次人类判断。与已有工作相比,新在于将图灵测试范式首次全面引入端到端S2S评估,并超越二元通过/失败的结论。主要实验结果显示,所有评估的9个最先进的S2S系统均未通过图灵测试,成功率最高仅为0.31(人类为0.87)。为了诊断失败原因,论文提出了一个包含5大类18个细粒度维度的“拟人度”分类法,并对数据进行了人工标注。分析表明,当前S2S系统的瓶颈不在语义理解(如逻辑连贯性、记忆一致性接近人类水平),而在于韵律特征(如节奏、重音)、情感表达不足以及过度恭维、书面化的“机械人格”。此外,论文探索了使用AI作为评委的可能性,发现9个现成多模态模型表现不佳,因此提出了一个基于Qwen2.5-Omni微调的可解释评委模型,该模型先预测18个细粒度维度分数,再通过线性分类器做出人/机判断,其在测试集上的二分类准确率达到96.05%,显著优于人类评委(72.84%)和基线模型。这项工作的意义在于为S2S系统建立了一个系统化的拟人度评估与诊断框架,并指明了超越语义理解、在副语言和情感个性化方面突破的研究方向。主要局限性是评估的系统和场景覆盖范围可能无法代表整个S2S领域,且伪人对话的脚本部分依赖大语言模型生成。
🏗️ 模型架构
论文的核心技术贡献在于提出的“可解释的AI评委模型”,用于自动化且透明地评估S2S系统的拟人度。其架构并非一个端到端的语音生成或理解模型,而是一个针对特定评估任务设计的多阶段分类器。
整体架构与流程: 该模型采用两阶段微调框架,基于预训练的音频-语言模型Qwen2.5-Omni进行构建。
- 输入:原始的语音对话音频片段。
- 第一阶段(细粒度评分投影):首先,使用预训练的Qwen2.5-Omni编码器(一个融合了音频和语言信息的模型)对输入对话进行编码,得到一个固定维度的隐藏表示(论文中称为“融合池化”)。这个表示随后被送入一个“序数离散层”(Ordinal Discretization Layer, ODL)。ODL的作用是将隐藏表示映射到K个(K=18)可解释的分数上,每个分数对应“拟人度”分类法中的一个维度。ODL通过有序切割点将每个潜在分数转化为一个有序概率分布,从而学习尊重1-5分评级的序数关系。训练目标是最小化序数负对数似然,使预测分数与人工标注的细粒度评分对齐。
- 第二阶段(可解释的二分类):第一阶段输出的K个分数被视为高度可解释的特征。这些分数被输入一个带有正则化约束的线性分类器。该分类器通过交叉熵损失进行训练,目标是做出最终的“人类 vs. 机器”判断。线性分类器的权重矩阵(W_F)的设计使得最终决策可以透明地追溯到哪些细粒度维度贡献了关键证据。
关键组件与设计动机:
- 融合池化:这是论文通过消融实验确定的最佳隐藏表示读取策略。它将模型第一步的全局平均池化(捕获声学和长程上下文)与最后一步的隐藏状态(捕获高级语义摘要)进行可学习的加权融合,性能优于单独使用任一策略。
- 序数离散层:这是模型可解释性的核心。它不是将18个维度的分数作为独立的分类目标,而是建模分数之间的有序关系,这更符合人类评分的认知过程,并确保了输出的分数具有与人类评级一致的可解释方向。
- 带正则化的线性分类器:使用线性层而非复杂的非线性网络,是为了保持决策过程的透明度,可以直接分析每个分数维度(特征)对最终分类(人类/机器)的贡献权重和方向。
架构图:

💡 核心创新点
- 首次针对语音到语音(S2S)系统进行图灵测试:之前图灵测试主要用于文本或文本到语音领域。本工作首次将图灵测试范式完整应用于输入和输出均为语音的S2S对话系统,填补了在该交互模态下评估“拟人度”的空白。
- 提出细粒度拟人度诊断分类法:构建了一个包含5大类(语义语用习惯、非生理性副语言特征、生理性副语言特征、机械人格、情感表达)和18个具体维度(如记忆一致性、韵律节奏、情感声学表达等)的分类体系。这超越了简单的通过/失败判断,能够系统性地诊断当前S2S系统的具体缺陷所在。
- 开发可解释的AI评委模型:针对现成多模态模型作为评委表现不佳的问题,设计了一个基于序数回归的可解释模型。该模型不仅能在二分类任务上超越人类和基线,还能输出透明的细粒度分数,为评估和改进S2S系统提供了可解释的自动化工具。
- 构建专用的多模态图灵测试数据集与评测平台:收集了包含真实人-人、人-机对话以及TTS合成的伪人对话的高质量数据集,并设计了一个游戏化的在线评测平台,实现了可扩展、可重复的大规模人类评估。
🔬 细节详述
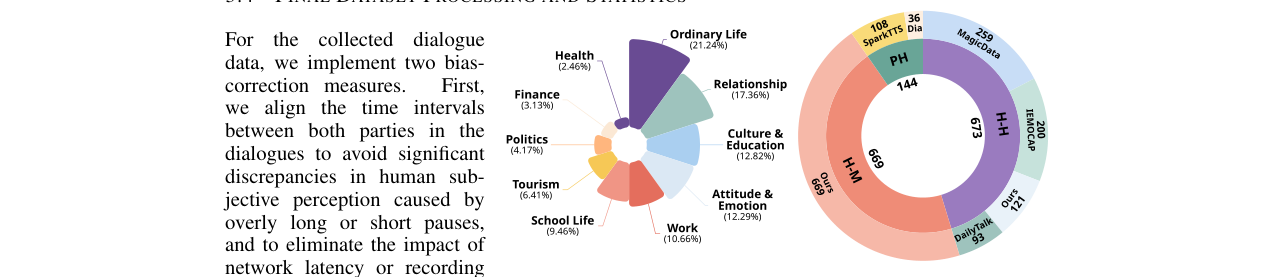
- 训练数据:
- AI评委模型训练集:使用自建数据集的子集,包含525个人-机对话和531个人-人对话,总计约13.1小时,按1:1比例平衡。
- 评测集:包含剩余的430个对话(人-人、人-机、伪人对话平衡)约4.7小时,用于最终图灵测试和模型评估。
- 数据增强与处理:对所有对话进行了时间对齐和音量均衡,以消除录音差异带来的偏差。
- 损失函数:
- ODL阶段:最小化所有样本和维度上的序数负对数似然损失。
- 分类阶段:使用交叉熵损失(LCE)进行训练,并加入对称性正则化项(R(W_F)=||W_F1+W_F2||2,λ=0.1)以提高可解释性。
- 训练策略:
- 优化器:Adam。
- 学习率:ODL模块为1e-5,线性层为1e-3(通过网格搜索确定)。
- 批大小:ODL为64,线性层为128。
- Dropout:在ODL中为0.3。
- 训练轮数:未明确说明总轮数,但通过早停法在验证集上确定。
- 关键超参数:
- 模型骨干:Qwen2.5-Omni-7B。
- 细粒度维度数(K):18。
- 评分等级(r):5。
- ODL中的可学习尺度(s_k):通过网格搜索在{1, 1.05, …, 5}中选择最优。
- 训练硬件:8张NVIDIA A40 GPU(每卡48GB显存)。
- 推理细节:未详细说明解码策略,但评测平台使用游戏化Web界面收集人类判断。AI评委模型直接进行前向传播得到分类结果。
- 正则化技巧:线性分类器中使用了对称性正则化。
📊 实验结果
论文主要围绕三个核心问题展开实验,并以表格和图表形式呈现了详细结果。
问题一:S2S系统能否通过图灵测试? 实验通过人类评委的“成功率”(被判断为人类的比例)来评估。下表总结了各系统在英文和中文上的成功率:
| 模型 | 英文成功率 | 中文成功率 |
|---|---|---|
| GPT-4o | 0.259 | 0.230 |
| Claude-Sonnet 4 | 0.229 | 0.000 |
| Qwen3 | 0.067 | 0.164 |
| Gemini-2.5 pro | 0.190 | 0.133 |
| Kimi-K1.5 | 0.308 | 0.110 |
| ChatGLM-4.5 | 0.118 | 0.096 |
| Hunyuan-TurboS | 0.200 | 0.209 |
| Doubao-Pro 1.5 | 0.219 | 0.219 |
| iFLYTEK-Spark | 0.000 | 0.140 |
| Spark-TTS (伪人) | 0.256 | 0.366 |
| Nari-TTS (伪人) | 0.378 | 0.000 |
| 人类说话者 | 0.867 | 0.700 |
结论:所有S2S系统的成功率均远低于0.5的随机阈值,最高仅为0.31(Kimi-K1.5英文),而人类说话者成功率高达0.87(英文)和0.70(中文)。这证实了没有现有系统通过测试。
问题二:为何S2S系统不拟人? 通过18个维度的细粒度评分(5分制)分析发现,模型在语义层面(如记忆一致性、逻辑连贯性)得分接近人类,但在非生理性副语言特征(如韵律、重音)、情感表达和人格(如过度恭维)方面得分显著低于人类。
问题三:AI能否作为评委? 首先测试了9个现成多模态模型作为评委,其整体准确率远低于人类。然后,论文提出的可解释AI评委模型表现如下:
| 数据类型 | Qwen2.5-Omni | Qwen2.5-Omni (LoRA) | 人类评委 | 本文模型 |
|---|---|---|---|---|
| 人-人 ↑ | 0.7817 | 0.9230 | 0.7028 | 0.9507 |
| 人-机 ↑ | 0.2361 | 0.6319 | 0.8357 | 0.9722 |
| 伪人 ↑ | 0.2361 | 0.0972 | 0.6384 | 0.9306 |
| 整体准确率 ↑ | 0.4163 | 0.5744 | 0.7284 | 0.9605 |
结论:本文提出的模型整体准确率达到96.05%,显著高于人类评委(72.84%)和最佳微调基线(57.44%),展示了其卓越的判别能力和泛化性(在伪人对话上准确率93.06%)。
⚖️ 评分理由
- 学术质量:6.5/7:创新性强,首次系统性地将图灵测试应用于S2S领域,并提出了具有诊断价值的18维分类法。技术路线清晰,从人类评估、问题诊断到自动化工具开发形成完整闭环。实验设计严谨,数据集构建(包含三种对话类型、多语言、多策略)和评估平台设计(游戏化、大规模)值得称道。模型的可解释性设计(ODL)有理论依据且通过消融实验验证了有效性。主要扣分点在于:S2S系统作为评估对象,其“拟人度”本身是主观且复杂的,实验结论高度依赖于当前人类评委的感知;细粒度评分的人工标注虽经专家校正,但仍可能存在噪声。
- 选题价值:1.5/2:选题非常前沿且具有实际意义。随着语音交互成为主流,评估其“拟人度”而非仅仅“准确性”至关重要。该工作为研究社区提供了一个关键的评估基准和问题诊断框架,对推动S2S系统向更自然、更像人的方向发展有明确的指导价值。与音频/语音读者高度相关,因为它直接关系到语音助手、社交伴侣等应用的终极体验。扣分点在于,该评估框架和诊断结论的有效性需要时间检验,且其提出的方法更偏向于评估工具,而非直接提升S2S系统性能的方法。
- 开源与复现加成:1.0/1:论文明确声明在GitHub上公开了代码、数据和模型,提供了良好的复现基础。附录详细说明了数据收集、标注指南、模型训练超参数、硬件环境以及消融实验,复现信息充分。因此给予满分加成。