📄 Human Behavior Atlas: Benchmarking Unified Psychological And Social Behavior Understanding
#多模态模型 #音频分类 #音视频 #预训练 #模型评估
🔥 8.5/10 | 前25% | #多模态模型 | #预训练 | #音频分类 #音视频
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 1.0 | 置信度 高
👥 作者与机构
- 第一作者:Keane Ong(MIT;National University of Singapore)
- 通讯作者:未说明
- 作者列表:Keane Ong(MIT;National University of Singapore)、Wei Dai(MIT)、Carol Li(MIT)、Dewei Feng(MIT)、Hengzhi Li(MIT;Imperial College London)、Jingyao Wu(MIT)、Jiaee Cheong(Harvard University)、Rui Mao(Nanyang Technological University)、Gianmarco Mengaldo(National University of Singapore)、Erik Cambria(Nanyang Technological University)、Paul Pu Liang(MIT)
💡 毒舌点评
亮点:在行为理解领域,该工作首次系统性地将分散在情感、认知、病理和社会过程等多个维度的异构数据集、任务和评估指标统一成一个标准化基准,为构建行为基础模型提供了至关重要的“数据-任务-评估”三位一体的基础设施。短板:论文更像是一个扎实的工程整合工作,其核心创新在于“统一”而非提出解决行为理解某一具体子任务(如深度讽刺识别或复杂社交推理)的新算法或架构,对于寻求领域内技术深度突破的读者来说,可能略显“广而不深”。
🔗 开源详情
- 代码:论文明确提供了代码仓库链接:
https://github.com/MIT-MI/human_behavior_atlas。 - 模型权重:论文声明将发布“HUMAN BEHAVIOR ATLAS”基准及其相关的“OMNISAPIENS-7B”模型。
- 数据集:论文声明将发布“HUMAN BEHAVIOR ATLAS”基准数据集。
- Demo:论文中未提及在线演示。
- 复现材料:论文在附录中提供了极其详尽的复现信息,包括:
- 所有13个子数据集的训练/验证/测试集划分数量(表7)。
- 完整的训练超参数(学习率、batch size、LoRA配置、优化器设置等)。
- 评估指标的详细计算公式(加权F1、加权准确率)。
- 用于评估开放式生成任务的LLM评判器(GPT-5-nano)的具体提示模板。
- 模型架构的数学形式化描述(附录B.1)。
- 强化学习GRPO算法的详细推导和奖励函数设计(附录B.2)。
- 论文中引用的开源项目/工具:
- 骨干模型:Qwen2.5-Omni-7B。
- 行为描述符提取:MediaPipe(用于面部和身体关键点),OpenSMILE(使用ComParE 2016配置提取声学特征)。
- 语音转录:Whisper v3 Large模型。
- 评估工具:GPT-5-nano(作为LLM裁判)。
- 训练框架:PyTorch,Accelerate。
- 优化器:Adam,AdamW。
📌 核心摘要
本文旨在解决当前人类心理与社会行为理解领域中存在的任务专业化、数据集异构、评估标准不一以及缺乏统一基础模型训练框架的问题。为此,作者构建了HUMAN BEHAVIOR ATLAS,这是一个涵盖情感、认知、病理、社会过程四大维度,包含超过101k个文本、音频、视觉多模态样本的统一基准。核心方法包括:1)定义统一的行为分类体系;2)将所有数据集样本重新组织为标准化的“提示-目标”格式;3)统一跨数据集的评估指标;4)提取行为描述符(如面部关键点、声学特征)以丰富数据。基于此基准,论文训练并评估了三个7B参数的模型变体:OMNISAPIENS-7B SFT(监督微调)、OMNISAPIENS-7B BAM(集成行为描述符适配器)和OMNISAPIENS-7B RL(强化学习)。实验结果表明,在HUMAN BEHAVIOR ATLAS上训练的模型在10个行为任务中的多数上优于现有的通用多模态大模型(如Qwen2.5-Omni-7B),例如在情绪识别(EMO)任务上,OMNISAPIENS-7B BAM达到0.651(CREMA-D数据集),而Qwen2.5-Omni-7B仅为0.521。此外,在该基准上的预训练能显著提升模型到新数据集(如MUStARD讽刺检测)的迁移能力,即使微调仅一个epoch,OMNISAPIENS-7B SFT的加权F1也能达到0.658,远高于从头微调的Qwen2.5-Omni-7B的0.473。该工作为行为理解领域提供了首个大规模的统一基准、标准化的建模范式和经过验证的模型,推动了通用行为基础模型的发展,但其模型规模(7B)和主要针对分类任务的设计可能限制了其在更复杂生成或推理场景下的应用。
🏗️ 模型架构
论文提出了OMNISAPIENS-7B系列模型,均基于预训练的Qwen2.5-Omni-7B多模态大语言模型骨干网络。
整体架构与数据流:
- 输入处理:模型接收文本转录、音频波形和视频帧(图像序列)作为输入。视频和音频输入首先通过各自的编码器(Evis, Eaud)提取特征,然后通过投影层(Pvis, Paud)映射到与文本嵌入(Etext)相同的共享嵌入空间,形成统一的多模态嵌入序列
z = [ztext; zaud; zvis]。 - 骨干网络处理:该融合序列被送入多层Transformer LLM骨干网络(F)。论文特别关注倒数第二层(
h_penult)的输出表示。 - 输出头部:根据任务类型,采用不同的输出头部:
- 分类任务(如情绪、情感极性):从
h_penult经过掩码平均池化得到固定维度的表示,然后送入每个任务特定的分类器头部(Ct),产生分类 logits 并用交叉熵损失训练。 - 生成任务(如社交推理):
h_penult直接送入LLM自身的解码器头部(G),以自回归方式生成文本,使用教师强制损失训练。
- 分类任务(如情绪、情感极性):从
三个模型变体的关键区别:
- OMNISAPIENS-7B SFT:使用上述完整的“分类器+解码器”混合头部架构进行多任务监督微调。
- OMNISAPIENS-7B BAM:在SFT模型冻结的基础上,引入一个残差式行为适配器模块(BAM)。该模块接收经过时序池化(均值和标准差)和归一化的行为描述符(来自MediaPipe和OpenSMILE),通过一个轻量级的前馈网络(隐藏维度256)生成残差更新
Δhf,并将其加到固定的h_penult上,形成适应后的表示h_adapt = h_penult + Δhf。适配后的表示再送入原有的分类器或解码器头部。BAM的设计旨在以即插即用的方式增强模型,而不改变骨干网络表示。 - OMNISAPIENS-7B RL:与SFT架构类似,但摒弃了所有分类器头部,所有任务均统一使用单个解码器头部以自由文本形式生成答案。模型使用组相对策略优化(GRPO) 进行强化学习训练,奖励函数结合了准确性奖励、格式奖励和语义相似度奖励。

图1:HUMAN BEHAVIOR ATLAS基准的总览图,展示了从行为分类体系定义、数据集收集、格式标准化到评估框架建立的完整流程。
图2:不同模型在10个行为任务上的多任务性能对比热力图。颜色越深代表性能越好。结果表明,在HUMAN BEHAVIOR ATLAS上训练的三个OMNISAPIENS-7B变体在大多数任务上优于通用基线模型。
💡 核心创新点
- 构建首个大规模、多维度、标准化的行为理解统一基准:不同于以往聚焦单一任务(如情感识别)的数据集,本文系统性地整合了情感、认知、病理、社会过程四大维度、13个异构数据集,并通过统一的“提示-目标”格式和评估指标进行标准化,为训练通用行为基础模型奠定了数据基础。
- 提出即插即用的行为描述符适配器(BAM):BAM模块以残差方式将传统的行为分析特征(面部关键点、声学特征)无缝集成到端到端多模态大模型中,在不改变骨干网络表征的前提下,为目标任务提供显著的性能增益,调和了端到端模型与特征工程方法。
- 系统比较SFT、BAM、RL三种范式在行为理解任务上的效能与权衡:论文不仅训练了模型,还深入对比了监督微调、特征增强微调和强化学习三种方法在跨任务、跨数据集迁移上的表现差异,揭示了SFT/BAM在结构化分类任务上的优势以及RL在开放式生成任务上的潜力。
🔬 细节详述
- 训练数据:使用整理后的HUMAN BEHAVIOR ATLAS基准,包含13个公开数据集,共101,964个样本。数据集分布见图1(b)和表2,涵盖文本、音频、视频模态,并附加了行为描述符。所有数据集按原始分割或随机分割为训练、验证、测试集,具体数量见附录表7。
- 损失函数:
- SFT模型:联合优化分类损失(L_cls,交叉熵)和问答生成损失(L_qa,教师强制交叉熵)。 RL模型(GRPO):使用复合奖励函数训练,奖励 r = r_acc + λ_format r_format + λ_sim * r_sim。其中λ_format=0.2, λ_sim=0.5。策略优化目标包含带裁剪的优势估计和KL散度惩罚项。
- 训练策略:
- SFT & BAM:使用LoRA(rank=32, α=64)进行参数高效微调。优化器为Adam,学习率1e-4,余弦调度带50步warmup。有效批大小为512。在8块Nvidia H200 GPU上训练5个epoch。
- RL:从Qwen2.5-Omni-7B初始化,使用GRPO算法训练10个epoch。优化器为AdamW,学习率5e-7。批大小256,每个提示采样5个响应。最大序列长度4096。未启用KL惩罚(β=0)。
- 关键超参数:模型基础为7B参数。BAM适配器的前馈网络隐藏维度为256,使用Dropout(0.10)正则化。
- 训练硬件:SFT和BAM训练在8块Nvidia H200 141GB GPU上完成。RL训练硬件未明确说明。
- 推理细节:对于分类任务,直接取softmax概率最高的类别;对于生成任务(RL和部分SFT),以自由文本形式解码答案。RL评估时,从生成的``和
\boxed{}中提取最终答案。 - 正则化/稳定训练技巧:LoRA、Dropout、余弦学习率调度、训练初期warmup。BAM采用残差连接避免骨干网络表征灾难性遗忘。
📊 实验结果
主要实验(表4):多任务学习性能对比
| 模型 | CREMA-D (EMO) | MELD (EMO) | MOSEI (EMO) | TESS (EMO) | UR-FUNNY (HUM) | IntentQA (INT) | PTSD-WILD (PTSD) | DAIC-WOZ (DEP) | MELD (SEN) | CH-SIMSv2 (SEN) | MOSEI (SEN) | MUStARD (SAR) | Social-IQ (SOC) | MimeQA (NVC) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Qwen2.5-Omni-7B | 0.521 | 0.661 | 0.580 | 0.568 | 0.543 | 0.254 | 0.760 | 0.793 | 0.791 | 0.636 | 0.700 | 0.714 | 0.602 | 0.656 |
| HumanOmniV2-7B | 0.560 | 0.633 | 0.558 | 0.637 | 0.638 | 0.263 | 0.824 | 0.527 | 0.672 | 0.636 | 0.768 | 0.825 | 0.633 | 0.395 |
| Ours SFT | 0.542 | 0.709 | 0.614 | 0.658 | 0.532 | 0.256 | 1.00 | 0.909 | 0.839 | 0.626 | 0.746 | 0.813 | 0.744 | 0.624 |
| Ours BAM | 0.548 | 0.711 | 0.607 | 0.715 | 0.644 | 0.177 | 1.00 | 0.909* | 0.839 | 0.738 | 0.744 | 0.837 | 0.775 | 0.795 |
| Ours RL | 0.501 | 0.699 | 0.581 | 0.510 | 0.639 | 0.486 | 0.968 | 0.919 | 0.814 | 0.729 | 0.571 | 0.393 | 0.224 | 0.647 |
表4(部分):在HUMAN BEHAVIOR ATLAS测试集上的多任务结果。Ours BAM和Ours SFT在多个分类任务上取得最佳或接近最佳性能。Ours RL在开放式生成任务(如IntentQA)上表现突出。表示无BAM。
关键结论:
- 在行为理解任务上,经过HUMAN BEHAVIOR ATLAS专门训练的模型普遍优于通用多模态模型。
- BAM在NVC(+33%)、SAR(+29%)、HUM(+21%)等任务上带来显著增益(见表6)。
- RL在需要开放式推理的任务(INT, SOC)上更具优势。
迁移学习实验(表5):少样本微调性能
| 数据集 | OMNISAPIENS-7B SFT | Qwen 2.5-Omni-7B SFT |
|---|---|---|
| MOSEI (SEN) | 0.724 | 0.612 |
| MELD (EMO) | 0.711 | 0.684 |
| DAIC-WOZ (DEP) | 0.749 | 0.579 |
| MUStARD (SAR) | 0.658 | 0.473 |
表5:在保留数据集上进行1个epoch微调后的迁移性能。预训练过的模型展现出显著的迁移优势。
零样本迁移实验(表8):
| 数据集 | OMNISAPIENS-7B RL | Qwen 2.5-Omni-7B |
|---|---|---|
| MOSEI (SEN) | 0.247 | 0.201 |
| MELD (EMO) | 0.549 | 0.403 |
| DAIC-WOZ (DEP) | 0.499 | 0.108 |
| MUStARD (SAR) | 0.596 | 0.445 |
表8:零样本评估。在HUMAN BEHAVIOR ATLAS上预训练为模型提供了强大的零样本泛化能力。
消融实验(表6 & 10):BAM的增益对依赖细微行为线索的任务(如面部表情、韵律)明显,但对纯文本推理任务(SOC, INT)可能无益甚至有害。移除原始音视频特征的BAM消融(表10)显示行为描述符是补充而非替代原始信号。
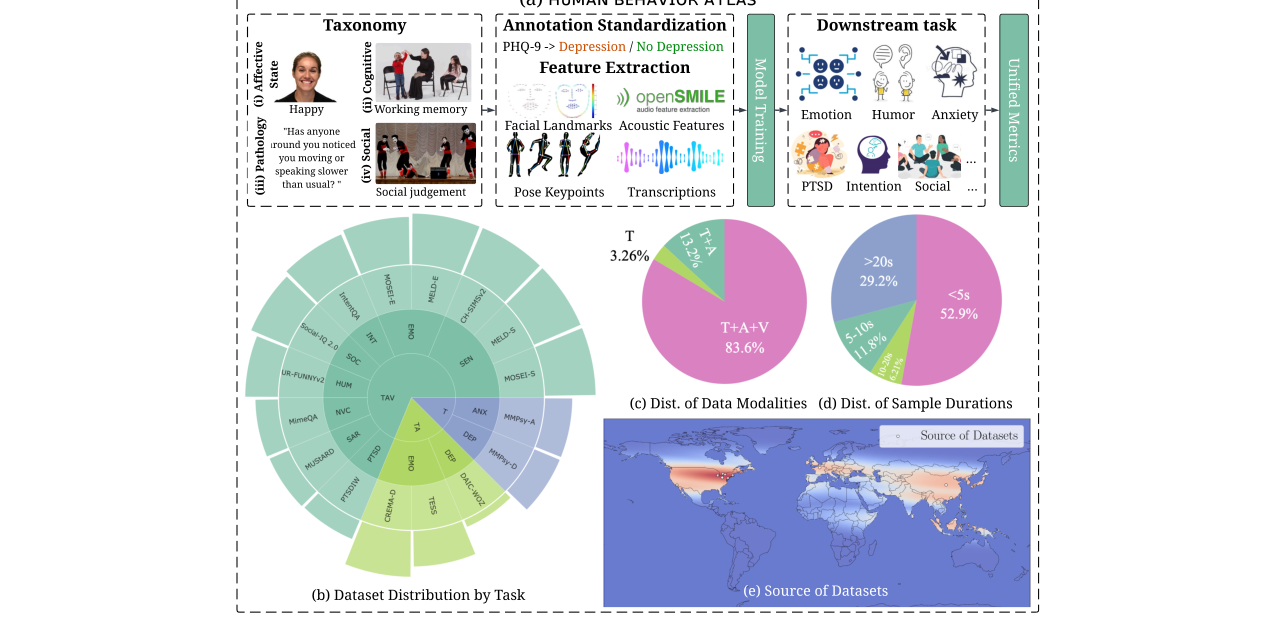
图4:BAM定性分析示例。BAM帮助模型捕捉到了SFT模型忽略的转瞬即逝的微笑,从而正确预测了积极情感。
⚖️ 评分理由
- 学术质量:6.0/7:论文的核心贡献是系统性地构建了一个高质量、标准化的统一基准(HUMAN BEHAVIOR ATLAS),并在此基础上进行了充分、严谨的多模型、多范式实验验证,包括多任务学习、迁移学习、零样本学习和消融研究,提供了丰富的实证数据。其技术实现(如BAM残差适配器设计)合理且有效。主要扣分点在于,该工作更侧重于数据集工程和现有模型范式的应用与对比,在算法创新和理论深度上相对有限。
- 选题价值:1.5/2:人类行为理解是人工智能与社会计算交叉的核心前沿领域,构建统一基础模型具有重要科学和应用价值。该基准覆盖了从情感病理到社会交互的广泛维度,潜在影响较大。但对于音频/语音领域的读者而言,其直接相关性不如专注于语音情感识别或对话分析的工作。
- 开源与复现加成:1.0/1:论文明确承诺公开基准数据集、预训练模型(SFT, BAM, RL)和代码(链接已提供)。附录中提供了极其详细的训练超参数、数据集划分、评估指标公式和LLM评判提示,复现性极高。这是该论文一个非常突出的优势。