📄 Hierarchical Semantic-Acoustic Modeling via Semi-Discrete Residual Representations for Expressive End-to-End Speech Synthesis
#语音合成 #自回归模型 #流匹配 #预训练 #端到端
🔥 8.0/10 | 前25% | #语音合成 | #自回归模型 | #流匹配 #预训练
学术质量 7.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Yixuan Zhou(清华大学深圳国际研究生院)
- 通讯作者:Zhiyong Wu(清华大学深圳国际研究生院)
- 作者列表:Yixuan Zhou(清华大学深圳国际研究生院),Guoyang Zeng(ModelBest Inc),Xin Liu(ModelBest Inc),Xiang Li(清华大学深圳国际研究生院),Renjie Yu(清华大学深圳国际研究生院),Ziyang Wang(ModelBest Inc),Runchuan Ye(清华大学深圳国际研究生院),Weiyue Sun(ModelBest Inc),Jiancheng Gui(ModelBest Inc),Kehan Li(清华大学深圳国际研究生院),Zhiyong Wu(清华大学深圳国际研究生院),Zhiyuan Liu(清华大学计算机科学与技术系)
💡 毒舌点评
亮点:论文提出的“半离散残差表示”框架设计精巧,通过一个可微的量化瓶颈在单一端到端模型中优雅地实现了语义和声学的隐式解耦,有效规避了传统连续模型的误差累积和离散模型的信息损失,堪称“鱼与熊掌兼得”的架构设计典范。短板:模型的高性能(VoxCPM)严重依赖海量内部数据(1百万小时),而公开验证(VoxCPM-Emilia)的性能与SOTA仍有差距,这使得其宣称的“架构优越性”在多大程度上可迁移到受限数据场景存疑,也削弱了其作为普适解决方案的说服力。
📌 核心摘要
- 解决的问题:现有端到端语音合成模型面临一个根本权衡:离散token方法稳定但会丢失声学细节(量化天花板),而连续表示方法保留了丰富声学信息但容易在长序列上因语义和声学任务纠缠而产生误差累积,影响稳定性。
- 方法核心:提出VoxCPM,一个端到端的层次化语义-声学建模框架。其核心是一个可微的有限标量量化(FSQ)瓶颈,它自然诱导出两个专门化模块:文本-语义语言模型(TSLM) 负责生成稳定的语义韵律骨架,残差声学语言模型(RALM) 负责恢复FSQ量化后丢失的精细声学细节。最终,由层次化表示共同引导一个局部扩散Transformer解码器(LocDiT) 生成高保真语音隐变量。
- 新意:与依赖外部离散语音token化器的多阶段管道不同,该框架将量化作为正则化机制内置于连续数据流中,实现了在单一端到端训练框架内的功能分离,消除了对外部预训练token化器的依赖,并缓解了连续模型中的任务纠缠。
- 主要结果:在超过1百万小时的双语数据上训练的0.5B参数VoxCPM,在SEED-TTS-EVAL基准上取得了开源系统中的最优性能,英语WER为1.85%,中文CER为0.93%,说话人相似度SIM分别为72.9%和77.2%。关键消融实验证明,去除FSQ瓶颈(w/o FSQ)会导致在困难测试集上性能急剧恶化(中文CER从18.19%升至24.92%),验证了其核心作用。
- 实际意义:该工作为构建表达力强、稳定性高的端到端语音合成系统提供了新的架构范式,有望推动更自然、更具情感的语音交互技术发展。
- 主要局限性:SOTA性能严重依赖大规模内部训练数据,在较小公开数据集上的验证(VoxCPM-Emilia)表现虽具竞争力但非顶尖,表明其对数据规模可能较为敏感。此外,框架的整体复杂度(包含LM、RALM、扩散解码器)对部署资源有一定要求。
详细分析
VoxCPM是一个层次化、端到端的自回归语音生成模型,其核心设计是通过内部半离散瓶颈实现语义和声学建模的解耦。
整体架构与数据流:
- 输入:文本序列T。
- 历史上下文编码:对于已生成的语音隐变量序列Z_{<i},通过一个轻量级的局部音频编码器(LocEnc) 压缩为紧凑的声学嵌入E_{<i}。
- 层次化建模生成当前隐变量:
- TSLM:接收文本T和历史声学嵌入E_{<i},生成连续的语义-韵律表示h_TSLM。
- FSQ瓶颈:对h_TSLM进行标量量化,得到稳定的半离散“骨架”表示h_FSQ。这一步强制TSLM专注于编码稳定的、高层级的内容与韵律。
- RALM:接收文本部分的TSLM隐藏状态、历史半离散表示H_FSQ_{<i}以及历史声学嵌入E_{<i},专门恢复量化过程中丢失的精细声学细节(如说话人音色、频谱微结构),生成残差表示h_residual。
- 融合:将语义骨架h_FSQ与声学细节h_residual相加,得到最终的层次化条件信号h_final。
- 高保真解码:局部扩散Transformer(LocDiT) 以h_final和前一个隐变量z_{i-1}为条件,通过去噪扩散过程生成当前语音隐变量z_i。这是一个双向Transformer,可对局部patch进行完整建模。
- 训练目标:整个模型使用流匹配(Flow Matching)损失进行端到端训练,并辅以停止预测损失。梯度通过所有模块(包括FSQ,通过直通估计)反向传播,实现协调优化。
关键设计选择与动机:
- FSQ作为归纳偏置:与传统将离散token作为预测目标不同,本文将FSQ作为正则化瓶颈,其作用是约束TSLM的隐藏状态空间,迫使模型将稳定语义信息通过瓶颈,而将易变声学信息分配给RALM,从而隐式实现任务分离,解决连续模型中的纠缠问题。
- 残差学习策略:RALM显式建模被FSQ过滤掉的“声学残差”,与TSLM形成分工协作,而非简单的级联或并行,这使模型能更 holistic 地捕捉语音的多层次信息。
- 因果VAE:使用因果VAE将原始波形压缩到低帧率连续隐空间,既保证了信息保真度,又支持流式合成。
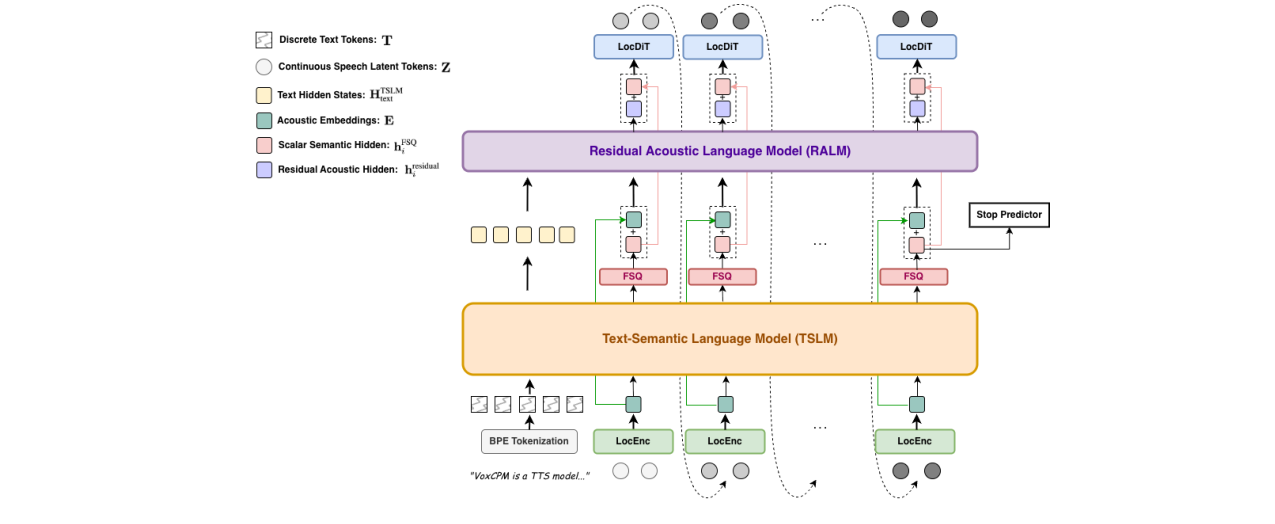
图1:VoxCPM的整体架构图。模型层次化地生成语音:首先通过LocEnc处理音频隐变量,然后通过TSLM和FSQ生成半离散语音骨架,接着由RALM细化声学细节,最后由LocDiT生成高保真隐输出。
- 可微半离散瓶颈实现隐式解耦:利用FSQ在连续数据流中创建一个瓶颈,自然诱导TSLM(语义规划)和RALM(声学渲染)的功能分离,无需显式多阶段训练或外部离散化器,从根本上缓解了连续自回归模型的任务纠缠和误差累积。
- 端到端统一框架下的残差声学建模:将残差学习策略集成到上述瓶颈架构中,使RALM专注于恢复量化损失的精细声学特征。这实现了“功能性分离”而不造成“架构碎片化”,简化了训练流水线。
- 无需外部离散语音token化器的端到端训练:整个层次化模型在扩散目标下端到端训练,消除了对预训练离散语音token化器的依赖,避免了其信息损失(量化天花板)和与语言模型之间的语义-声学鸿沟。
- 大规模训练验证的有效性与可扩展性:在超过100万小时数据上训练0.5B模型达到SOTA,并通过模型缩放实验(0.5B, 1B, 3B)证明了该架构能有效利用增加的参数量提升性能。
- 训练数据:
- 大规模双语语料库:内部收集,超过100万小时,主要为中英文语音。
- Emilia数据集:公开数据集,9.5万小时,用于对比和消融研究。
- 预处理:所有音频重采样至16kHz单声道,经过声源分离、语音活动检测(VAD)和自动语音识别(ASR)以获得文本-音频对齐。
- 损失函数:
- 主要损失:条件流匹配损失L_FM(公式5),用于优化LocDiT生成语音隐变量的分布。
- 辅助损失:停止预测损失L_Stop(公式6),二分类交叉熵,用于训练模型预测序列结束点。
- 总损失:L = L_FM + λL_Stop。
- 训练策略:
- 优化器:AdamW。
- 学习率调度:采用Warmup-Stable-Decay(WSD)策略。稳定阶段学习率1e-4,衰减阶段从1e-4降至5e-6,并伴随batch size加倍。
- Batch Size:稳定阶段4096 tokens,衰减阶段8192 tokens。
- 训练步数:主模型(1M数据)训练500K步;Emilia模型(95K数据)训练200K步;消融实验均训练200K步。
- 关键超参数与模型配置(VoxCPM-0.5B):
- TSLM:24层,隐藏维度1024,FFN维度4096,由MiniCPM-4-0.5B初始化。
- RALM:6层,隐藏维度1024,FFN维度4096,随机初始化。
- FSQ:维度256,标量量化级别9。
- LocDiT:4层,隐藏维度1024,FFN维度4096。
- LocEnc:4层,隐藏维度1024,FFN维度4096。
- Patch大小:2帧(TSLM和RALM工作在12.5Hz token率)。
- 总参数量:约5.5亿(LocEnc 59M + TSLM 433M + FSQ 0.5M + RALM 89M + LocDiT 64M + 其他)。
- 训练硬件:
- 主模型(VoxCPM):40个NVIDIA H100 GPU。
- Emilia模型(VoxCPM-Emilia):24个NVIDIA H100 GPU。
- 消融实验:8个NVIDIA H100 GPU。
- 推理细节:
- 解码:LocDiT使用扩散采样,迭代10次。
- Classifier-Free Guidance (CFG):在训练时以一定概率屏蔽来自TSLM和RALM的引导信号,在推理时使用CFG值(实验得出最佳值为2.0)以提升质量。
- 流式合成:由于使用因果VAE和局部自回归生成,支持流式合成,理论首包延迟低于100ms。
- 实时率(RTF):在单个RTX 4090 GPU上,RTF为0.17。
- 正则化与稳定训练技巧:
- WSD学习率调度:衰减阶段对提升零样本说话人相似度至关重要。
- FSQ作为结构性正则化:约束TSLM的表示空间,防止其过度关注声学细节。
- 停止预测损失:辅助训练以正确终止序列生成。
主要对比实验(与SOTA对比):
表1:在SEED-TTS-EVAL基准上的性能对比
| 模型 | 参数 | 数据/小时 | EN WER↓ | EN SIM↑ | ZH CER↓ | ZH SIM↑ | Hard CER↓ | Hard SIM↑ |
|---|---|---|---|---|---|---|---|---|
| F5-TTS | 0.3B | 100K | 2.00 | 67.0 | 1.53 | 76.0 | 8.67 | 71.3 |
| MaskGCT | 1B | 100K | 2.62 | 71.7 | 2.27 | 77.4 | - | - |
| CosyVoice2 | 0.5B | 170K | 3.09 | 65.9 | 1.38 | 75.7 | 6.83 | 72.4 |
| SparkTTS | 0.5B | 100K | 3.14 | 57.3 | 1.54 | 66.0 | - | - |
| FireRedTTS-2 | - | 1.4M | 1.95 | 66.5 | 1.14 | 73.6 | - | - |
| Qwen2.5-Omni | 7B | - | 2.72 | 63.2 | 1.70 | 75.2 | 7.97 | 74.7 |
| IndexTTS 2 | 1.5B | 55K | 2.23 | 70.6 | 1.03 | 76.5 | 7.12 | 75.5 |
| HiggsAudio-v2 | 3B | 10M | 2.44 | 67.7 | 1.50 | 74.0 | 55.07 | 65.6 |
| VoxCPM-Emilia | 0.5B | 100K | 2.34 | 68.1 | 1.11 | 74.0 | 12.46 | 69.8 |
| VoxCPM | 0.5B | 1.8M | 1.85 | 72.9 | 0.93 | 77.2 | 8.87 | 73.0 |
关键结论:VoxCPM在所有指标上均优于或持平于最强开源基线(如CosyVoice2, IndexTTS 2),特别是在困难测试集(Hard)上展现出显著的稳健性优势(CER更低, SIM更高)。
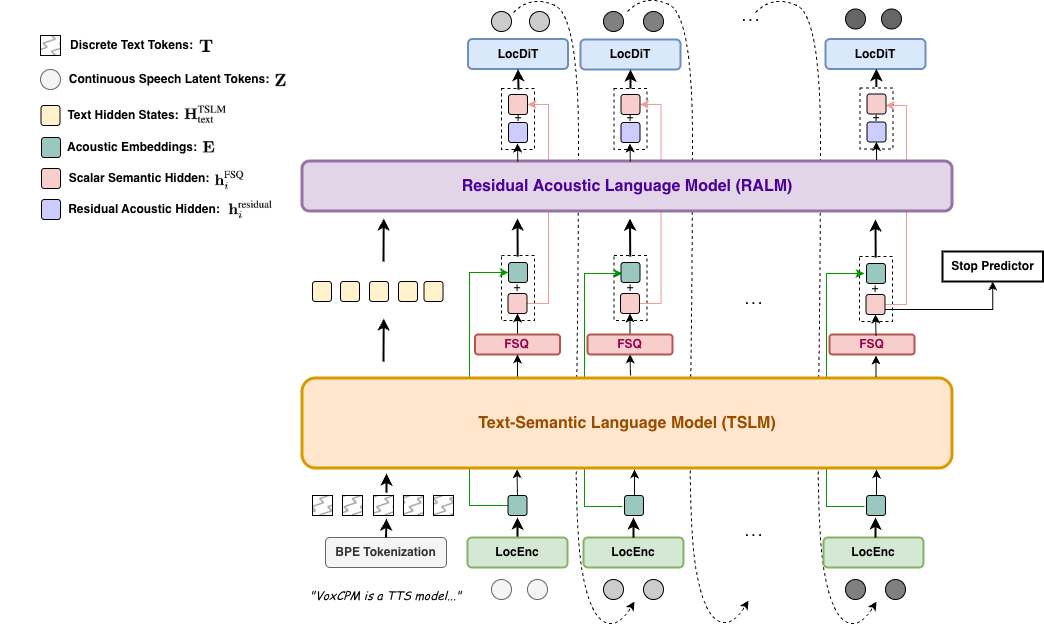
图6(对应论文Table 1):展示了VoxCPM与多个开源/闭源系统在SEED-TTS-EVAL基准上的性能对比,突出了VoxCPM在各项指标上的领先地位。
表2:在CV3-EVAL基准上的性能对比(部分)
| 模型 | CV3-EVAL ZH-CER↓ | CV3-EVAL EN-WER↓ | CV3-Hard-ZH CER↓ | CV3-Hard-EN WER↓ | CV3-Hard-EN SIM↑ |
|---|---|---|---|---|---|
| CosyVoice2 | 4.08 | 6.32 | 12.58 | 11.96 | 66.7 |
| IndexTTS2 | 3.58 | 4.45 | 12.80 | 8.78 | 74.5 |
| VoxCPM | 3.40 | 4.04 | 12.90 | 7.89 | 64.3 |
关键结论:在更具挑战性的表达力和真实场景评测中,VoxCPM同样表现出色,特别是在英语困难集上WER最低(7.89%)。
关键消融实验:
表4:FSQ瓶颈维度与核心架构消融研究(在Emilia数据集上)
| 模型设置 | EN WER↓ | EN SIM↑ | ZH CER↓ | ZH-hard CER↓ |
|---|---|---|---|---|
| 默认设置(w/ FSQ: d256s9) | 2.98 | 62.6 | 1.77 | 18.19 |
| w/o FSQ: d1024s∞ | 3.67 | 62.1 | 2.30 | 24.92 |
| w/o RALM: TSLM (24层) →LocDiT | 4.34 | 61.8 | 3.05 | 25.00 |
| w/o E<i in RALM | 4.91 | 60.9 | 4.94 | 27.17 |
| w/o h_residual in condition | 3.86 | 58.3 | 3.05 | 23.65 |
关键结论:
- FSQ至关重要:去除FSQ(w/o FSQ)导致在困难测试集上中文CER从18.19%飙升至24.92%,证实了瓶颈对稳定性的关键作用。
- 残差建模有效:去除RALM(w/o RALM)或不使用其残差输出(w/o h_residual)均导致性能全面下降,证明其声学细化能力。
- 预训练初始化有益:去除TSLM的预训练初始化(w/o LM init)会导致WER显著升高(5.24% vs 2.98%),表明预训练语言模型知识对稳定性很重要。
表征分析(探测实验):
表12:内部隐藏状态的逐层探测结果
| 隐藏状态位置 | 语音识别PER↓ | 语音识别WER↓ | 说话人验证EER↓ |
|---|---|---|---|
| LocEnc输出 | 59.12 | 65.79 | 15.38 |
| TSLM最后隐藏状态(FSQ前) | 45.60 | 60.43 | 18.70 |
| FSQ输出 | 50.90 | 62.37 | 19.25 |
| RALM最后隐藏状态 | 53.49 | 64.85 | 13.24 |
关键结论:量化实证了“分工”假说:FSQ输出具有最高的说话人验证EER(19.25%),表明它过滤了说话人信息;RALM输出具有最低的EER(13.24%),表明它成功恢复了说话人信息。TSLM则保持了最好的语言内容保真度(最低PER/WER)。
模型缩放性实验: 在Emilia数据集上训练0.5B, 1B, 3B模型,结果显示增大模型规模能稳定提升性能(如3B模型EN-WER降至2.60%),证明架构的可扩展性。
- 学术质量:7.0/7:论文具有清晰的创新思路(半离散瓶颈解耦),技术实现正确,实验设计全面且深入,包括大规模对比、详尽消融和多层次分析,所有主张均有强证据支持。
- 选题价值:1.5/2:聚焦语音合成的核心挑战(表达力与稳定性权衡),提出了有影响力的解决方案,与领域高度相关。但语音合成是一个成熟且竞争激烈的领域,其突破性相比一些全新任务稍显有限。
- 开源与复现加成:0.5/1:提供了代码链接,承诺发布模型权重,并给出了非常详细的训练配置和超参数。最大的不足是核心高性能模型所用的1百万小时训练数据为内部数据未公开,限制了完全复现SOTA性能。
开源详情
- 代码:论文提供了推理代码链接
codes.zip,并承诺未来发布完整代码。 - 模型权重:论文提及将发布代码和模型权重,但具体平台和链接未在文中说明。
- 数据集:核心训练数据(1百万小时)为内部数据集,未公开。对比实验使用的Emilia数据集是公开的。
- Demo:提供了在线演示页面链接:
https://voxcpm.github.io/VoxCPM-demopage/。 - 复现材料:论文提供了极其详细的模型架构(表5)、训练配置(表6)、超参数设置、评估细节(附录H)和复现声明(附录B)。
- 论文中引用的开源项目:依赖了MiniCPM-4作为TSLM的初始化基础;AudioVAE架构灵感来自DAC。
🔗 开源详情
- 代码:论文提供了推理代码链接
codes.zip,并承诺未来发布完整代码。 - 模型权重:论文提及将发布代码和模型权重,但具体平台和链接未在文中说明。
- 数据集:核心训练数据(1百万小时)为内部数据集,未公开。对比实验使用的Emilia数据集是公开的。
- Demo:提供了在线演示页面链接:
https://voxcpm.github.io/VoxCPM-demopage/。 - 复现材料:论文提供了极其详细的模型架构(表5)、训练配置(表6)、超参数设置、评估细节(附录H)和复现声明(附录B)。
- 论文中引用的开源项目:依赖了MiniCPM-4作为TSLM的初始化基础;AudioVAE架构灵感来自DAC。
🏗️ 模型架构
VoxCPM是一个层次化、端到端的自回归语音生成模型,其核心设计是通过内部半离散瓶颈实现语义和声学建模的解耦。
整体架构与数据流:
- 输入:文本序列T。
- 历史上下文编码:对于已生成的语音隐变量序列Z_{<i},通过一个轻量级的局部音频编码器(LocEnc) 压缩为紧凑的声学嵌入E_{<i}。
- 层次化建模生成当前隐变量:
- TSLM:接收文本T和历史声学嵌入E_{<i},生成连续的语义-韵律表示h_TSLM。
- FSQ瓶颈:对h_TSLM进行标量量化,得到稳定的半离散“骨架”表示h_FSQ。这一步强制TSLM专注于编码稳定的、高层级的内容与韵律。
- RALM:接收文本部分的TSLM隐藏状态、历史半离散表示H_FSQ_{<i}以及历史声学嵌入E_{<i},专门恢复量化过程中丢失的精细声学细节(如说话人音色、频谱微结构),生成残差表示h_residual。
- 融合:将语义骨架h_FSQ与声学细节h_residual相加,得到最终的层次化条件信号h_final。
- 高保真解码:局部扩散Transformer(LocDiT) 以h_final和前一个隐变量z_{i-1}为条件,通过去噪扩散过程生成当前语音隐变量z_i。这是一个双向Transformer,可对局部patch进行完整建模。
- 训练目标:整个模型使用流匹配(Flow Matching)损失进行端到端训练,并辅以停止预测损失。梯度通过所有模块(包括FSQ,通过直通估计)反向传播,实现协调优化。
关键设计选择与动机:
- FSQ作为归纳偏置:与传统将离散token作为预测目标不同,本文将FSQ作为正则化瓶颈,其作用是约束TSLM的隐藏状态空间,迫使模型将稳定语义信息通过瓶颈,而将易变声学信息分配给RALM,从而隐式实现任务分离,解决连续模型中的纠缠问题。
- 残差学习策略:RALM显式建模被FSQ过滤掉的“声学残差”,与TSLM形成分工协作,而非简单的级联或并行,这使模型能更 holistic 地捕捉语音的多层次信息。
- 因果VAE:使用因果VAE将原始波形压缩到低帧率连续隐空间,既保证了信息保真度,又支持流式合成。
VoxCPM整体架构图] 图1:VoxCPM的整体架构图。模型层次化地生成语音:首先通过LocEnc处理音频隐变量,然后通过TSLM和FSQ生成半离散语音骨架,接着由RALM细化声学细节,最后由LocDiT生成高保真隐输出。
💡 核心创新点
- 可微半离散瓶颈实现隐式解耦:利用FSQ在连续数据流中创建一个瓶颈,自然诱导TSLM(语义规划)和RALM(声学渲染)的功能分离,无需显式多阶段训练或外部离散化器,从根本上缓解了连续自回归模型的任务纠缠和误差累积。
- 端到端统一框架下的残差声学建模:将残差学习策略集成到上述瓶颈架构中,使RALM专注于恢复量化损失的精细声学特征。这实现了“功能性分离”而不造成“架构碎片化”,简化了训练流水线。
- 无需外部离散语音token化器的端到端训练:整个层次化模型在扩散目标下端到端训练,消除了对预训练离散语音token化器的依赖,避免了其信息损失(量化天花板)和与语言模型之间的语义-声学鸿沟。
- 大规模训练验证的有效性与可扩展性:在超过100万小时数据上训练0.5B模型达到SOTA,并通过模型缩放实验(0.5B, 1B, 3B)证明了该架构能有效利用增加的参数量提升性能。
🔬 细节详述
- 训练数据:
- 大规模双语语料库:内部收集,超过100万小时,主要为中英文语音。
- Emilia数据集:公开数据集,9.5万小时,用于对比和消融研究。
- 预处理:所有音频重采样至16kHz单声道,经过声源分离、语音活动检测(VAD)和自动语音识别(ASR)以获得文本-音频对齐。
- 损失函数:
- 主要损失:条件流匹配损失L_FM(公式5),用于优化LocDiT生成语音隐变量的分布。
- 辅助损失:停止预测损失L_Stop(公式6),二分类交叉熵,用于训练模型预测序列结束点。
- 总损失:L = L_FM + λL_Stop。
- 训练策略:
- 优化器:AdamW。
- 学习率调度:采用Warmup-Stable-Decay(WSD)策略。稳定阶段学习率1e-4,衰减阶段从1e-4降至5e-6,并伴随batch size加倍。
- Batch Size:稳定阶段4096 tokens,衰减阶段8192 tokens。
- 训练步数:主模型(1M数据)训练500K步;Emilia模型(95K数据)训练200K步;消融实验均训练200K步。
- 关键超参数与模型配置(VoxCPM-0.5B):
- TSLM:24层,隐藏维度1024,FFN维度4096,由MiniCPM-4-0.5B初始化。
- RALM:6层,隐藏维度1024,FFN维度4096,随机初始化。
- FSQ:维度256,标量量化级别9。
- LocDiT:4层,隐藏维度1024,FFN维度4096。
- LocEnc:4层,隐藏维度1024,FFN维度4096。
- Patch大小:2帧(TSLM和RALM工作在12.5Hz token率)。
- 总参数量:约5.5亿(LocEnc 59M + TSLM 433M + FSQ 0.5M + RALM 89M + LocDiT 64M + 其他)。
- 训练硬件:
- 主模型(VoxCPM):40个NVIDIA H100 GPU。
- Emilia模型(VoxCPM-Emilia):24个NVIDIA H100 GPU。
- 消融实验:8个NVIDIA H100 GPU。
- 推理细节:
- 解码:LocDiT使用扩散采样,迭代10次。
- Classifier-Free Guidance (CFG):在训练时以一定概率屏蔽来自TSLM和RALM的引导信号,在推理时使用CFG值(实验得出最佳值为2.0)以提升质量。
- 流式合成:由于使用因果VAE和局部自回归生成,支持流式合成,理论首包延迟低于100ms。
- 实时率(RTF):在单个RTX 4090 GPU上,RTF为0.17。
- 正则化与稳定训练技巧:
- WSD学习率调度:衰减阶段对提升零样本说话人相似度至关重要。
- FSQ作为结构性正则化:约束TSLM的表示空间,防止其过度关注声学细节。
- 停止预测损失:辅助训练以正确终止序列生成。
📊 实验结果
主要对比实验(与SOTA对比):
表1:在SEED-TTS-EVAL基准上的性能对比
| 模型 | 参数 | 数据/小时 | EN WER↓ | EN SIM↑ | ZH CER↓ | ZH SIM↑ | Hard CER↓ | Hard SIM↑ |
|---|---|---|---|---|---|---|---|---|
| F5-TTS | 0.3B | 100K | 2.00 | 67.0 | 1.53 | 76.0 | 8.67 | 71.3 |
| MaskGCT | 1B | 100K | 2.62 | 71.7 | 2.27 | 77.4 | - | - |
| CosyVoice2 | 0.5B | 170K | 3.09 | 65.9 | 1.38 | 75.7 | 6.83 | 72.4 |
| SparkTTS | 0.5B | 100K | 3.14 | 57.3 | 1.54 | 66.0 | - | - |
| FireRedTTS-2 | - | 1.4M | 1.95 | 66.5 | 1.14 | 73.6 | - | - |
| Qwen2.5-Omni | 7B | - | 2.72 | 63.2 | 1.70 | 75.2 | 7.97 | 74.7 |
| IndexTTS 2 | 1.5B | 55K | 2.23 | 70.6 | 1.03 | 76.5 | 7.12 | 75.5 |
| HiggsAudio-v2 | 3B | 10M | 2.44 | 67.7 | 1.50 | 74.0 | 55.07 | 65.6 |
| VoxCPM-Emilia | 0.5B | 100K | 2.34 | 68.1 | 1.11 | 74.0 | 12.46 | 69.8 |
| VoxCPM | 0.5B | 1.8M | 1.85 | 72.9 | 0.93 | 77.2 | 8.87 | 73.0 |
关键结论:VoxCPM在所有指标上均优于或持平于最强开源基线(如CosyVoice2, IndexTTS 2),特别是在困难测试集(Hard)上展现出显著的稳健性优势(CER更低, SIM更高)。
不同模型在SEED-TTS-EVAL基准上的性能对比图] 图6(对应论文Table 1):展示了VoxCPM与多个开源/闭源系统在SEED-TTS-EVAL基准上的性能对比,突出了VoxCPM在各项指标上的领先地位。
表2:在CV3-EVAL基准上的性能对比(部分)
| 模型 | CV3-EVAL ZH-CER↓ | CV3-EVAL EN-WER↓ | CV3-Hard-ZH CER↓ | CV3-Hard-EN WER↓ | CV3-Hard-EN SIM↑ |
|---|---|---|---|---|---|
| CosyVoice2 | 4.08 | 6.32 | 12.58 | 11.96 | 66.7 |
| IndexTTS2 | 3.58 | 4.45 | 12.80 | 8.78 | 74.5 |
| VoxCPM | 3.40 | 4.04 | 12.90 | 7.89 | 64.3 |
关键结论:在更具挑战性的表达力和真实场景评测中,VoxCPM同样表现出色,特别是在英语困难集上WER最低(7.89%)。
关键消融实验:
表4:FSQ瓶颈维度与核心架构消融研究(在Emilia数据集上)
| 模型设置 | EN WER↓ | EN SIM↑ | ZH CER↓ | ZH-hard CER↓ |
|---|---|---|---|---|
| 默认设置(w/ FSQ: d256s9) | 2.98 | 62.6 | 1.77 | 18.19 |
| w/o FSQ: d1024s∞ | 3.67 | 62.1 | 2.30 | 24.92 |
| w/o RALM: TSLM (24层) →LocDiT | 4.34 | 61.8 | 3.05 | 25.00 |
| w/o E<i in RALM | 4.91 | 60.9 | 4.94 | 27.17 |
| w/o h_residual in condition | 3.86 | 58.3 | 3.05 | 23.65 |
关键结论:
- FSQ至关重要:去除FSQ(w/o FSQ)导致在困难测试集上中文CER从18.19%飙升至24.92%,证实了瓶颈对稳定性的关键作用。
- 残差建模有效:去除RALM(w/o RALM)或不使用其残差输出(w/o h_residual)均导致性能全面下降,证明其声学细化能力。
- 预训练初始化有益:去除TSLM的预训练初始化(w/o LM init)会导致WER显著升高(5.24% vs 2.98%),表明预训练语言模型知识对稳定性很重要。
表征分析(探测实验):
表12:内部隐藏状态的逐层探测结果
| 隐藏状态位置 | 语音识别PER↓ | 语音识别WER↓ | 说话人验证EER↓ |
|---|---|---|---|
| LocEnc输出 | 59.12 | 65.79 | 15.38 |
| TSLM最后隐藏状态(FSQ前) | 45.60 | 60.43 | 18.70 |
| FSQ输出 | 50.90 | 62.37 | 19.25 |
| RALM最后隐藏状态 | 53.49 | 64.85 | 13.24 |
关键结论:量化实证了“分工”假说:FSQ输出具有最高的说话人验证EER(19.25%),表明它过滤了说话人信息;RALM输出具有最低的EER(13.24%),表明它成功恢复了说话人信息。TSLM则保持了最好的语言内容保真度(最低PER/WER)。
模型缩放性实验: 在Emilia数据集上训练0.5B, 1B, 3B模型,结果显示增大模型规模能稳定提升性能(如3B模型EN-WER降至2.60%),证明架构的可扩展性。
⚖️ 评分理由
- 学术质量:7.0/7:论文具有清晰的创新思路(半离散瓶颈解耦),技术实现正确,实验设计全面且深入,包括大规模对比、详尽消融和多层次分析,所有主张均有强证据支持。
- 选题价值:1.5/2:聚焦语音合成的核心挑战(表达力与稳定性权衡),提出了有影响力的解决方案,与领域高度相关。但语音合成是一个成熟且竞争激烈的领域,其突破性相比一些全新任务稍显有限。
- 开源与复现加成:0.5/1:提供了代码链接,承诺发布模型权重,并给出了非常详细的训练配置和超参数。最大的不足是核心高性能模型所用的1百万小时训练数据为内部数据未公开,限制了完全复现SOTA性能。