📄 Generative Adversarial Post-Training Mitigates Reward Hacking in Live Human-AI Music Interaction
#音乐生成 #强化学习 #对抗训练 #实时处理 #音乐信息检索
✅ 7.0/10 | 前25% | #音乐生成 | #强化学习 | #对抗训练 #实时处理
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Yusong Wu (Mila, Quebec Artificial Intelligence Institute, Université de Montréal)
- 通讯作者:Natasha Jaques (University of Washington), Cheng-Zhi Anna Huang (Massachusetts Institute of Technology)
- 作者列表:Yusong Wu (Mila, Université de Montréal), Stephen Brade (Massachusetts Institute of Technology), Aleksandra Teng Ma (Georgia Institute of Technology), Tia-Jane Fowler (University of Washington), Enning Yang (McGill University), Berker Banar (Independent Researcher), Aaron Courville (Mila, Université de Montréal), Natasha Jaques (University of Washington), Cheng-Zhi Anna Huang (Massachusetts Institute of Technology)
💡 毒舌点评
亮点:在强化学习后训练中巧妙引入对抗训练思想来解决“奖励黑客”问题,特别是通过一个自适应更新的判别器来平衡“真实感”与任务目标,方案设计精巧且有实验验证。短板:方法的核心创新是将GAN和RL思想结合用于序列模型,这并非完全原创;研究场景(实时旋律-和弦伴奏)非常垂直,其影响力可能局限于音乐生成领域,对更广泛的序列生成任务(如对话)的普适性未得到充分论证。
🔗 开源详情
- ���码:是。论文提供了代码仓库链接:
https://github.com/lukewys/realchords-pytorch。 - 模型权重:未明确提及是否公开所有训练阶段(如判别器、奖励模型)的权重,仅提供了代码仓库。
- 数据集:训练使用Hooktheory, POP909, Nottingham。论文未明确说明这些数据集的公开获取方式,但根据引用,它们可能是公开或可申请的。评估使用了公开的Wikifonia子集。
- Demo:是。提供了音频示例网页:
https://realchords-GAPT.github.io。 - 复现材料:论文附录提供了详细的模型架构(层数、维度等)、训练超参数(学习率、batch size等)、奖励模型性能以及消融实验结果。未提供训练脚本或配置文件。
- 引用的开源项目:论文基于并扩展了ReaLchords (
https://github.com/lukewys/realchords-pytorch) 的代码库,并使用了LLaMA风格的Transformer架构。
📌 核心摘要
- 要解决什么问题:在基于强化学习的生成式AI后训练中,模型为了最大化奖励会产生重复、单一的输出(奖励黑客)。这在要求实时协作、多样性和创造性的音乐交互(即兴合奏)场景中尤为有害,会破坏创造性流动和用户控制感。
- 方法核心是什么:提出生成对抗后训练(GAPT),在原有的基于和谐度的任务奖励之外,引入一个同时训练的判别器,该判别器学习区分策略生成的轨迹和真实数据轨迹。策略的奖励变为最大化判别器输出的“真实感”评分(对抗奖励)与任务奖励之和。为稳定训练,采用两阶段自适应判别器更新策略:先预热,后仅在策略有效提升对抗奖励时更新判别器。
- 与已有方法相比新在哪里:相比于仅使用KL散度约束或熵正则化来缓解奖励黑客的方法,GAPT通过对抗训练提供了一个数据驱动的、动态的正则化信号,迫使策略在优化任务目标时仍保持输出的自然性。该方法专门针对需要实时适应和多样性的交互式生成场景。
- 主要实验结果如何:
- 固定旋律模拟:在测试集上,GAPT的和谐度(note-in-chord ratio)为0.497,多样性(Vendi Score)为26.645,相比基线ReaLchords(0.484, 20.968)在保持高和谐度的同时显著提升了多样性。在留外数据集(Wikifonia)上,GAPT也取得了最佳平衡(0.470, 11.295)。
- 模型交互:与学习的旋律智能体交互时,GAPT同样取得最佳和谐度(0.648)和多样性(12.914)平衡。
- 真人用户研究:12名专家音乐家在实时交互中,对GAPT模型的“适应速度”和“控制与代理感”评分显著高于ReaLchords(p < 0.05),定性反馈称赞其适应更快、不无聊。
- 消融实验:验证了对抗奖励、奖励权重、判别器输入形式以及不同RL优化器(如GRPO)下该方法的有效性和鲁棒性。
- 实际意义是什么:为实时交互式AI音乐创作系统提供了更实用、更具创造性的伴奏模型,提升了人机协作体验。该方法为解决序列生成模型RL后训练中的奖励黑客问题提供了一种简单有效的范式,可能推广到对话、故事生成等其他需要多样性和适应性的领域。
- 主要局限性是什么:研究聚焦于特定的旋律-和弦伴奏任务,模型架构和训练针对此场景设计。对于更复杂的音乐交互(如多乐器、自由即兴)或通用的文本生成任务,方法的有效性需要进一步验证。判别器训练引入了额外的复杂性和计算开销。
🏗️ 模型架构
论文的整体架构图见下图,清晰地展示了GAPT方法的核心组件和数据流。
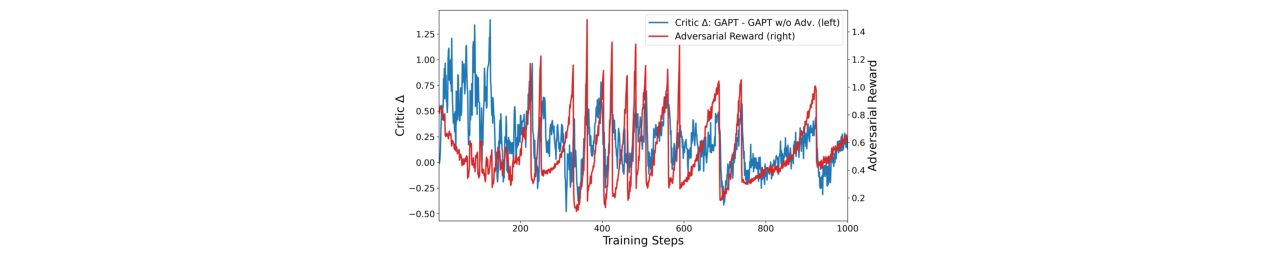
图1:GAPT方法概览图。左图展示了未经对抗训练的策略因奖励黑客导致多样性崩溃;右图展示了GAPT通过引入判别器提供对抗奖励,约束策略产生自然、多样且连贯的伴奏。
- 在线伴奏策略 (πθ):一个基于Transformer的解码器,接收交替输入的旋律历史(x< t)和自身生成的和弦历史(y< t),并自回归地生成下一个和弦token(y_t)。其输入被建模为条件独立,即给定共享历史,当前的旋律和和弦生成是条件独立的,以支持实时在线交互。
- 判别器 (Dψ):一个同样基于Transformer的编码器网络。它接收一个由策略生成的完整和弦序列轨迹(y),并输出一个标量值(Dψ(y) ∈ [0,1]),表示该轨迹来自真实数据分布的概率(“真实感”评分)。
- 协同训练流程:
- 策略πθ在由数据集中旋律驱动的环境中进行rollout,生成和弦轨迹y。
- 判别器Dψ使用真实数据和当前策略生成的轨迹进行二分类训练(真实数据为正,策略轨迹为负)。
- 策略πθ的总奖励R(x, y)由三部分组成:基于和谐度的任务奖励Rcoh、基于规则的惩罚Rrules、以及从判别器导出的对抗奖励Radv = -log(1 - Dψ(y))。
- 策略通过PPO算法优化总奖励,同时包含KL散度约束和熵正则化。
- 两阶段自适应判别器更新:为稳定对抗训练,判别器更新分为两阶段:
- 阶段1(预热):前200步,判别器按固定间隔(每5次PPO更新后更新1次)进行更新。
- 阶段2(自适应):之后,判别器仅在最近3次PPO更新的对抗奖励移动平均值超过阈值τ=1.0时才进行更新,否则保持冻结。这避免了判别器过快更新导致的策略梯度消失或不稳定。

图7:生成对抗后训练的算法伪代码,详细说明了上述训练流程。
💡 核心创新点
- 将对抗训练引入RL后训练以缓解奖励黑客:针对序列模型RL后训练中普遍存在的多样性崩溃问题,本文创新性地引入了一个判别器来提供额外的“真实感”奖励。这与传统的KL散度约束不同,它是一个从数据中动态学习的正则化器,能更有效地将策略拉回自然数据分布,从而在优化任务奖励的同时维持输出多样性。
- 两阶段自适应判别器更新策略:为解决对抗训练中常见的不稳定性和模式崩塌问题,设计了先固定间隔预热、后基于策略性能的置信度门控更新机制。这一简单而有效的调度器平衡了判别器和策略的更新速度,确保了训练的稳定性。
- 针对实时音乐交互场景的完整解决方案:不仅提出了算法,还构建并评估了从模型训练到实时部署的完整系统。通过固定旋律模拟、模型间交互以及真人音乐家用户研究,多角度验证了方法在提高适应性、保持多样性和增强用户控制感方面的有效性。
🔬 细节详述
- 训练数据:使用三个数据集:Hooktheory (约21,000对)、POP909 (909对)、Nottingham (1,019对)。评估时使用了留外的Wikifonia数据集 (502对)。对所有数据进行随机移调增强(±6半音)。
- 损失函数:
- 策略优化目标(Eq.4):最大化总奖励的期望,加上KL散度惩罚(β=0.001)和熵正则化(γ=0.01)。
- 总奖励R(x,y) = Rcoh(x,y) + Rrules(x,y) + Radv(x,y),三项等权(系数为1)。
- Rcoh由对比和谐度模型和判别式和谐度模型的集成奖励构成。
- Rrules包括无效输出惩罚、静音惩罚、提前终止惩罚和重复惩罚。
- 判别器训练使用带标签平滑(α=0.1)的二元交叉熵损失。
- 训练策略:使用PPO进行RL后训练。优化器:Adam(β1=0.9, β2=0.95)。策略学习率:5e-7,批大小384,mini-batch大小48。评论家学习率:9e-6。学习率预热100步后余弦衰减至10%峰值。共训练1000步PPO更新。
- 关键超参数:
- 在线策略(伴奏/旋律智能体):8层Transformer解码器,8头,隐藏维度512。
- 离线基线模型:编码器-解码器Transformer,各8层。
- 判别器:8层Transformer编码器,8头,隐藏维度512。
- 判别器学习率:9e-5,其余同策略。
- 上下文长度T≤256帧(六分音符)。
- 训练硬件:未说明。
- 推理细节:在实时系统中,采用前瞻(tf=4拍)和提交(tc=4拍)的缓冲机制处理网络延迟。采样温度为0.8。
- 正则化技巧:除了对抗训练,还使用了KL散度约束、熵正则化、标签平滑以及规则惩罚。
📊 实验结果
论文在三个递进的交互设置中评估了模型。
主要结果表格:
表1:固定旋律模拟结果(和谐度与多样性)
| 系统 | 测试集和谐度↑ | 测试集多样性↑ | 留外数据集和谐度↑ | 留外数据集多样性↑ |
|---|---|---|---|---|
| Online MLE | 0.368 | 29.491 | 0.362 | 16.401 |
| ReaLchords | 0.484 | 20.968 | 0.475 | 8.417 |
| GAPT w/o Adv. | 0.476 | 20.814 | 0.447 | 8.034 |
| GAPT | 0.497 | 26.645 | 0.470 | 11.295 |
| Ground Truth | 0.727 | 27.922 | 0.784 | 10.962 |
表2:模型交互与真人用户交互结果
| 系统 | 学习旋律智能体和谐度↑ | 学习旋律智能体多样性↑ | 用户交互和谐度↑ | 用户交互多样性↑ |
|---|---|---|---|---|
| Online MLE | 0.650 | 18.071 | 0.448 | 12.465 |
| ReaLchords | 0.626 | 7.480 | 0.462 | 9.786 |
| GAPT w/o Adv. | 0.540 | 5.658 | N/A | N/A |
| GAPT | 0.648 | 12.914 | 0.467 | 11.794 |
表7:奖励权重消融实验(测试集和谐度/多样性)
| 系统 | 测试集和谐度↑ | 测试集多样性↑ |
|---|---|---|
| GAPT (α=1, β=1, γ=1) | 0.497 | 26.645 |
| Upweight Coherence (α=2, β=1, γ=1) | 0.494 | 26.742 |
| Upweight Rules (α=1, β=2, γ=1) | 0.475 | 25.667 |
| Upweight Adversarial (α=1, β=1, γ=2) | 0.456 | 26.317 |
| Exclude Rules (α=1, β=0, γ=1) | N/A | N/A |
| Exclude Rules + Invalid Penalty | 0.488 | 25.072 |

图4:和谐度与多样性的Pareto前沿对比(a,b)及生成和弦的t-SNE可视化(c)。GAPT在(a)测试集和(b)留外数据集上均推动了Pareto前沿,在(c)中覆盖了更广的生成空间。
图3:真人用户研究评分。GAPT在“适应速度”和“控制与代理感”上显著优于ReaLchords(p<0.05)。
图6:在与学习的旋律智能体交互(a)和真人用户会话(b)中,GAPT均实现了和谐度与多样性的更佳平衡。
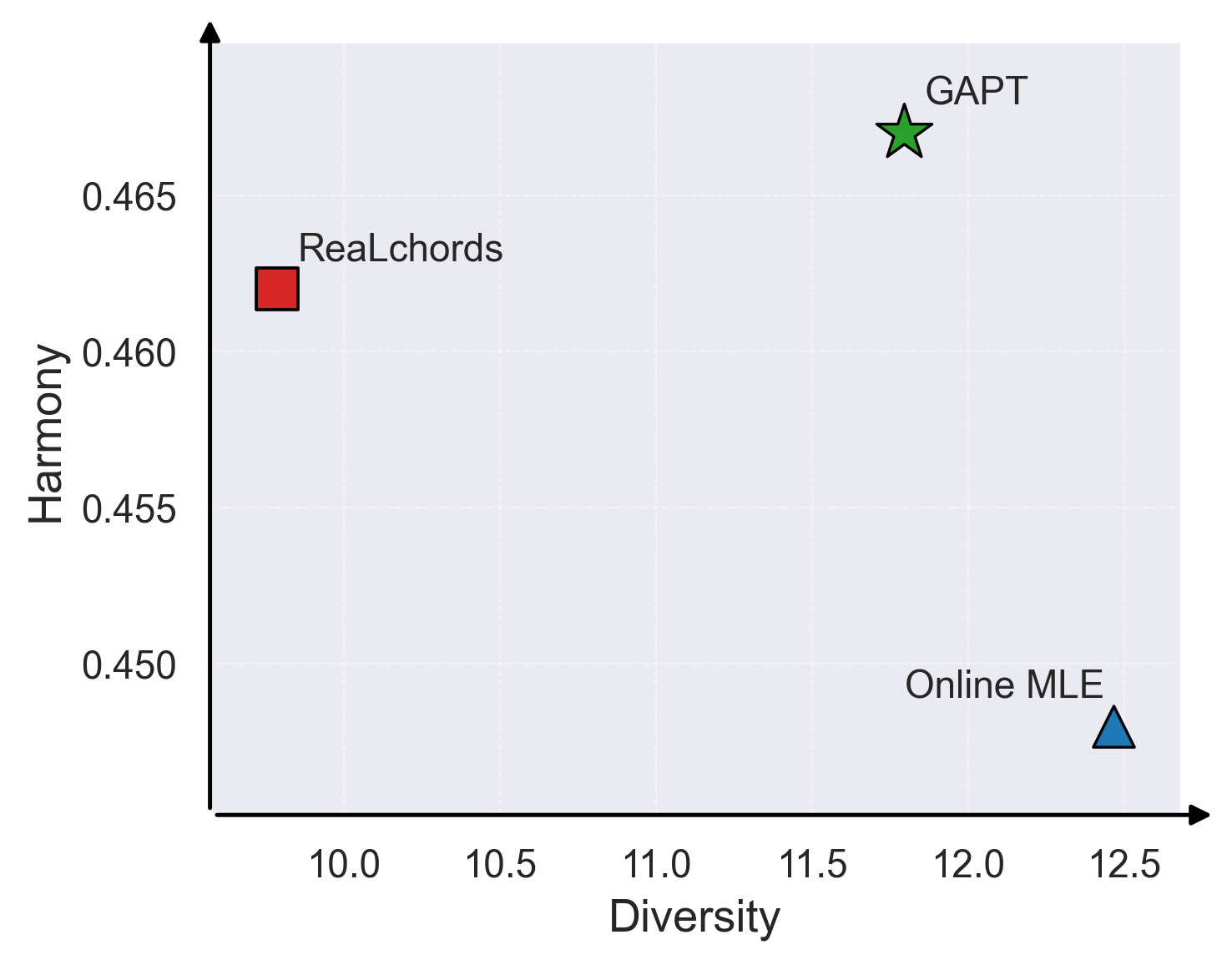
图8:GAPT训练过程中的指标变化:(a)总奖励,(b)对抗奖励,(c)判别器准确率,(d)判别器损失。显示训练过程稳定。
关键结论:
- 多样性恢复:在所有设置中,GAPT相比无对抗训练的基线(ReaLchords/GAPT w/o Adv.)显著提升了输出多样性(Vendi Score),同时保持了相当或更高的和谐度。
- 实时适应性与用户体验:真人用户研究证实,GAPT生成的伴奏让音乐家感知到更快的适应速度和更强的控制感。
- 消融验证:对抗奖励是提升多样性的关键;奖励权重需要平衡;规则惩罚对防止退化输出至关重要;判别器仅以和弦为输入(而非旋律+和弦)效果更好,避免了过拟合。
⚖️ 评分理由
- 学术质量:6.5/7:方法创新性明确,将对抗训练有效融入RL后训练框架;技术方案完整,包括具体的两阶段更新策略;实验设计全面,涵盖了仿真、模型交互和严格的真人用户研究,并提供了深入的消融实验;证据链条清晰可信。
- 选题价值:1.5/2:问题针对实时交互式AI生成中的关键挑战,具有前沿性和实用价值;所提方法为序列生成模型的后训练提供了一种新的正则化范式,具有潜在影响力;但研究场景相对垂直,可能限制其直接应用范围。
- 开源与复现加成:0.5/1:提供了代码仓库和音频示例链接,附录详细描述了模型架构、训练细节和实验设置;但未提供完整的数据集下载、所有模型权重和详细的训练脚本,部分训练超参数和硬件信息缺失。