📄 From Text to Talk: Audio-Language Model Needs Non-Autoregressive Joint Training
#语音对话系统 #扩散模型 #端到端 #多模态模型 #大语言模型
🔥 8.5/10 | 前25% | #语音对话系统 | #扩散模型 | #端到端 #多模态模型
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Tianqiao Liu(好未来教育集团 TAL Education Group,暨南大学 Guangdong Institute of Smart Education)
- 通讯作者:Xueyi Li(暨南大学 Guangdong Institute of Smart Education)
- 作者列表:Tianqiao Liu(好未来教育集团,暨南大学)、Xueyi Li(暨南大学)、Hao Wang(北京大学)、Haoxuan Li(北京大学)、Zhichao Chen(北京大学)、Weiqi Luo(暨南大学)、Zitao Liu(暨南大学)
💡 毒舌点评
论文对端到端语音模型中文本与音频生成范式错配问题的洞察一针见血,并给出了一个理论上优雅、实验上有效的混合训练框架,是当前S2S建模思路的一次重要升级。但论文对模型推理时块级扩散的计算开销分析着墨不多,且训练数据依赖大量合成语音(如CosyVoice2生成),其在真实复杂声学环境下的泛化能力仍是潜在挑战。
🔗 开源详情
- 代码:论文明确提供了代码仓库链接:
https://github.com/ai4ed/TtT。 - 模型权重:论文中未提及预训练模型权重(如Pretrain+TtT的检查点)的公开下载链接。
- 数据集:论文中使用的训练数据大多为公开数据集(如AISHELL, LibriSpeech, VoiceAssistant-400K等),但具体的数据处理脚本和混合配方未完全开源。评估数据集如URO-Bench、Audio-QA集等为公开基准。
- Demo:论文中未提及提供在线演示(Demo)。
- 复现材料:论文提供了极其详细的训练细节(超参数、优化器设置、训练策略概率)、模型配置(基于Qwen2.5)、以及架构和注意力机制的示意图(图2, 3),并附有详尽的附录。这些构成了坚实的复现基础。
- 引用的开源项目:论文依赖并引用了多个开源项目作为基础组件,主要包括:
- 音频分词器/解码器:GLM-4-Voice (Zeng et al., 2024)。
- 主干LLM:Qwen2.5系列。
- ASR评估工具:Whisper (Radford et al., 2023)、Paraformer。
- TTS数据生成:CosyVoice2。
- 训练框架:DeepSpeed。
- 论文中提及的开源计划:论文中未提及额外的开源计划(如未来发布模型权重或扩展数据)。
📌 核心摘要
本文针对现有端到端语音到语音(S2S)模型用统一自回归(AR)方法建模文本和音频所存在的范式错配问题,提出了“Text-to-Talk”(TtT)框架。核心问题在于,文本生成是强序列依赖的(目标-目标依赖),而音频生成更依赖输入源(源-目标依赖),强行用AR约束音频会引入不必要的误差传播。方法核心是设计一个混合生成框架,在同一个Transformer中,对文本使用标准AR建模,对音频段使用吸收离散扩散(一种NAR范式)建模,并证明了这种联合训练目标是目标联合分布的上界。与已有方法相比,新在两点:1)首次识别并形式化了文本与音频在依赖结构上的不对称性;2)提出了一个统一的架构和训练框架来适配这种不对称性,而非强行统一生成范式。主要实验结果显示,TtT在Audio-QA、ASR、AAC和URO-Bench等多个基准上,一致超越了纯AR和纯NAR的基线模型。例如,在3B参数规模下,TtT在多个ASR数据集上的WER大幅优于Qwen2.5-3B (AR),在Audio-QA任务上也显著提升。实际意义在于,为构建更自然、高效、符合生成特性的端到端语音交互系统提供了新思路。主要局限性包括:1)块级扩散推理的效率需要进一步评估;2)模型性能对大规模多模态预训练数据(约200B tokens)有一定依赖;3)尽管在轻量级模型中表现优异,但与某些超大参数量模型(如GLM-4-Voice)在综合基准上仍有差距。
关键实验结果表格(摘录):
| 模型 | 参数量 | Audio-QA (LQ.) ↑ | ASR (AISHELL-2) ↓ | URO-Bench Basic Understanding ↑ |
|---|---|---|---|---|
| Qwen2.5-3B (AR) | 3B | 10.00 | 54.94 | 34.32 |
| Qwen2.5-3B (NAR) | 3B | 0.67 | 212.27 | 7.22 |
| TtT (Pretrain+TtT) | 3B | 40.07 | 6.80 | 57.63 |
| GLM-4-Voice | 9B | 62.67 | - | 85.82 |
🏗️ 模型架构
TtT是一个基于预训练大语言模型(LLM,如Qwen2.5)初始化的统一音频-文本多模态大模型(MLLM),其核心在于支持在单一Transformer内交替进行AR文本生成和NAR音频合成。
完整输入输出流程:
- 输入:系统提示(文本)和用户查询(文本或音频)。若为音频,由音频编码器转化为离散音频标记。
- 统一处理:模型处理交错的文本-音频标记序列。序列由文本段(Tm)、音频段(Am)和特殊控制标记(
<SOA>,<EOA>,<EOS>)组成。 - 交替生成:
- AR文本生成:从起始处开始,模型以标准因果注意力方式自回归生成文本标记,直到遇到
<SOA>。 - NAR音频合成:切换到NAR模式,使用基于吸收离散扩散的块级生成(Algorithm 1)并行合成音频标记。在此期间,模型对当前音频块内的所有位置使用双向注意力,同时对之前的文本和音频上下文使用因果注意力。
- 重复循环:当预测出
<EOA>时,当前音频段生成结束,丢弃该块剩余位置,并切换回AR模式生成下一段文本,直至生成<EOS>。
- AR文本生成:从起始处开始,模型以标准因果注意力方式自回归生成文本标记,直到遇到
- 输出:交错的文本和音频标记序列。音频标记送入音频解码器(如HiFi-GAN)转换为波形。
主要组件与内部结构:
- 统一Transformer主干(fθ):一个从预训练LLM初始化的单一Transformer解码器。其词汇表V扩展了离散音频码本标记和特殊标记。它共享一个输出头来预测所有标记。
- 音频编码器与解码器:采用GLM-4-Voice的预训练分层残差向量量化(RVQ)编码器和解码器,用于将原始音频波形转换为离散标记,以及将生成的离散标记还原为波形。
- 模态感知注意力机制(Modality-Aware Attention):这是关键设计,支持混合生成范式。
- 输入提示:使用标准因果注意力。
- 文本标记(Tm):对提示、所有先前段、以及当前段内的前驱标记使用严格因果注意力。
- 音频标记(Am):在段内使用双向注意力,同时对提示和所有更早的段使用因果注意力。这使得同一音频段内的所有标记可以在一次前向传播中并行训练,且防止了跨段干扰。
- 块级扩散解码器(NAR推理核心):在推理时实现NAR音频生成。它将音频生成分解为固定长度(如B=32)的块,每个块通过T步(如200步)迭代去噪生成。在每一步,模型预测块内所有被掩码位置的标记,然后基于置信度或随机采样选择部分预测进行“提交”(解掩码),其余位置重新掩码以继续去噪。此过程支持早期终止(当块内出现
<EOA>时)。
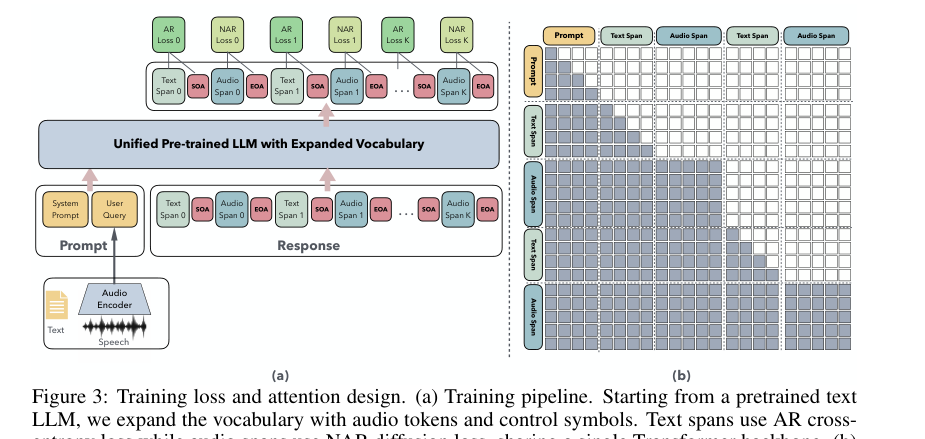
图2:(a) TtT框架概览。一个统一的MLLM在AR文本解码和NAR音频合成之间交替。(b) 扩散反向过程。通过迭代去噪实现NAR音频生成。
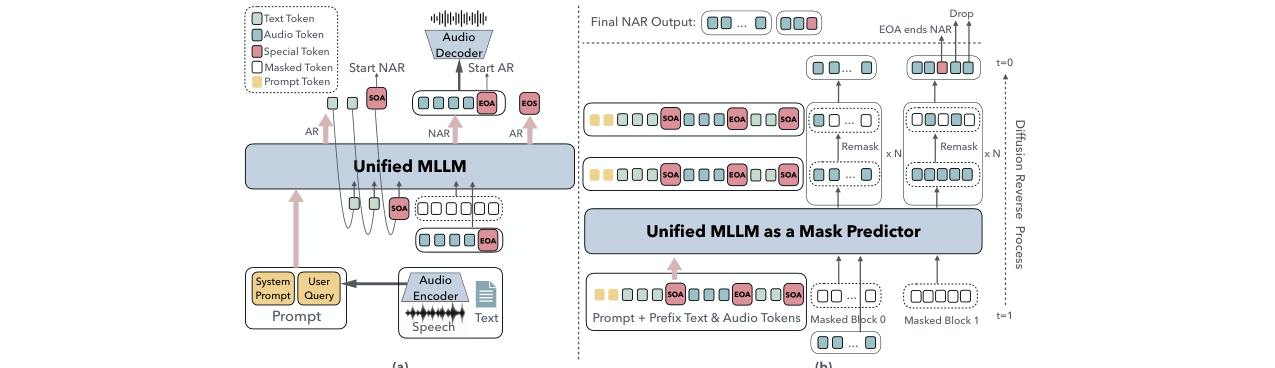
图3:(a) 训练流程示意图。从预训练LLM出发,扩展词汇表,文本段使用AR损失,音频段使用NAR扩散损失。(b) 注意力模式示意图。文本段使用因果注意力,音频段在段内使用双向注意力,在跨段时使用因果注意力。
关键设计选择与动机:
- 单一Transformer:保持架构简洁,最大化复用LLM的推理与指令遵循能力。
- 扩散用于音频段:源于音频生成的“源-目标”依赖特性,扩散的“任意顺序AR”特性与之天然匹配,能实现并行生成并减少误差累积。
- 模态感知注意力:是融合两种生成范式的工程关键,确保了训练时并行处理的效率,以及推理时生成的正确依赖关系。
- 块级推理:平衡了生成并行度与可控性,并支持变长输出(通过
<EOA>早退)。
💡 核心创新点
- 识别并建模模态依赖不对称性:首次明确指出并形式化了文本(目标-目标依赖)与音频(源-目标依赖)在生成过程中根本不同的依赖结构。这是整个工作的理论出发点,超越了以往工作中将两者统一处理的做法。
- 提出混合AR-NAR统一训练框架(TtT):设计了一个单一的Transformer架构,通过偏序集建模,将文本的确定性AR生成与音频的任意顺序AR(通过吸收离散扩散实现)生成无缝结合。并通过理论证明,该框架的联合训练目标是理想联合分布的上界,为其有效性提供了数学保证。
- 设计针对混合范式的训练策略:为了缓解混合AR-NAR训练带来的训练-测试不一致问题,提出了三项具体策略:批量级目标混合(BANOM)、前缀保持掩码(PPM)和随机段截断(SST)。这些策略从不同角度(历史上下文的干净度、生成终止点的学习)稳定了训练并提升了模型在变长输出场景下的鲁棒性。
🔬 细节详述
- 训练数据:总规模约630万样本,涵盖ASR、TTS、音频聊天、文本聊天、音频描述(AAC)、语音情感分类(SEC)、声学场景分类(ASC)及交错文本-音频数据。具体包括AISHELL-1/2、CommonVoice、LibriSpeech等语音数据集,Emilia中文/英文TTS数据集,以及利用CosyVoice2 TTS模型合成的音频聊天数据。还使用了从FineWeb-Edu等大型预训练语料构建的交错文本-音频数据。为Pretrain+TtT变体进行了约2000亿token的大规模多模态预训练。
- 损失函数:
- AR文本损失(LAR):标准的交叉熵损失,计算于所有文本标记位置(公式2)。
- NAR音频损失(LAO):基于吸收离散扩散的λ-去噪交叉熵损失,等价于任意顺序自回归目标(公式3)。实际训练中,对每个音频段随机采样掩码率λ,对音频标记进行掩码,然后让模型预测被掩码位置的原始标记。
- 联合目标(LUnified):
LAR + LAO,作为理想联合分布负对数似然的上界(公式8)。
- 训练策略:
- BANOM:概率p_mix=0.3下跳过扩散噪声添加,仅计算文本AR损失。让文本生成有机会看到干净的音频上下文。
- PPM:比例p_prefix=0.3的样本中,随机选择一个分界点m,保留前m-1个音频段不加噪,仅对后续段进行扩散训练。模拟推理时前段音频已生成干净的历史条件。
- SST:概率p_trunc=0.5下,随机截断最后一个音频段,移除其原有的
<EOA>及后续标记。迫使模型学习基于内容而非固定位置来预测结束符。
- 关键超参数:
- 主干模型:Qwen2.5-1.5B / Qwen2.5-3B。
- 优化器:AdamW,学习率2e-5,权重衰减0.01,余弦衰减调度,warmup比例0.01。
- 批大小:全局batch size 2048。
- 音频编码:使用GLM-4-Voice的分层RVQ编码器。
- 训练硬件:4个节点,每个节点8张NVIDIA A100 GPU,使用DeepSpeed框架。
- 推理细节:
- 文本解码:核采样(k=10, p=0.95)。
- 音频NAR生成:200个扩散步骤,块长度B=32,总扩散跨度长度640个标记,使用分类器-free guidance(scale=0.1)。
- 正则化/稳定训练:上述三项训练策略(BANOM, PPM, SST)本身就是为稳定混合范式训练、弥合训练-测试差异而设计的核心技巧。
📊 实验结果
论��在四个任务维度上进行了评估:音频问答(Audio-QA)、语音识别(ASR)、自动音频描述(AAC)和端到端语音对话(URO-Bench)。
主要对比结果(TtT vs. 基线):
表1:混合AR-NAR架构验证与消融研究(摘录)
| 模型 | Audio-QA (LQ.) ↑ | ASR (A2.) ↓ | ASR (A1.) ↓ | AAC (Clotho) ↑ |
|---|---|---|---|---|
| Qwen2.5-3B (AR) | 10.00 | 54.94 | 72.01 | 9.73 |
| Qwen2.5-3B (NAR) | 0.67 | 212.27 | 160.58 | 9.54 |
| TtT-3B (AR-NAR) | 34.68 | 12.53 | 13.65 | 12.63 |
| TtT-3B w/o BANOM | 19.87 | 18.58 | 21.35 | - |
| TtT-3B w/o PPM | 22.79 | 15.63 | 18.83 | - |
| TtT-3B w/o SST | 10.20 | 25.43 | 31.03 | - |
| Pretrain+AR | 15.93 | 9.79 | 12.67 | 11.55 |
| Pretrain+TtT | 40.07 | 6.80 | 5.78 | 11.55 |
结论:混合AR-NAR的TtT模型在Audio-QA和ASR上显著优于纯AR和纯NAR基线。三项训练策略均有贡献,移除任一项都会导致性能下降(如移除SST在LQ.上从34.68降至10.20)。多模态预训练(Pretrain+)能进一步提升性能。
表2:与SOTA模型对比(高效模型部分,摘录)
| 模型 | 参数量 | Audio-QA (LQ.) ↑ | ASR (A2.) ↓ | AAC (Clotho) ↑ |
|---|---|---|---|---|
| Mini-Omni | 0.5B | 2.00 | 342.40 | 3.61 |
| SLAM-Omni | 0.5B | 24.75 | - | 54.52 |
| Qwen2.5-3B (AR) | 3B | 10.00 | 54.94 | 9.73 |
| Pretrain+TtT | 3B | 40.07 | 6.80 | 11.55 |
| VITA-Audio | 7B | 54.30 | 5.56 | 6.18 |
| GLM-4-Voice | 9B | 62.67 | - | 13.15 |
结论:Pretrain+TtT(3B)在高效模型(≤3B)中,在Audio-QA和ASR任务上达到SOTA,显著超越Mini-Omni和SLAM-Omni。其性能甚至可与部分7B甚至9B模型(如SpeechGPT, Moshi)相媲美,但在Audio-QA绝对分数上仍落后于GLM-4-Voice等更大规模模型。
表3:URO-Bench语音对话基准对比(摘录)
| 模型 | 参数量 | Basic Understanding ↑ | Pro Reasoning ↑ | NMOS ↑ |
|---|---|---|---|---|
| Qwen2.5-3B (AR) | 3B | 34.32 | 34.99 | 3.96 |
| Pretrain+TtT | 3B | 57.63 | 43.76 | 3.90 |
| VITA-Audio | 7B | 52.08 | 54.77 | 3.95 |
| GLM-4-Voice | 9B | 85.82 | 51.89 | 3.86 |
结论:Pretrain+TtT在高效模型中,在理解与推理任务上领先。其感知质量(NMOS/UTMOS)与VITA-Audio、GLM-4-Voice相当,证明了音频合成质量。但在Pro级理解任务上,与GLM-4-Voice等大型模型仍有差距。
图4:论文性能对比表格截图,展示了TtT(Pretrain+TtT)在多项任务上与大小不同模型的详细得分对比。关键结论是TtT在≤3B模型中表现优异,部分指标超越更大模型。
图7:URO-Bench评估结果表格截图,展示了TtT在理解、推理和感知质量上的得分,证实其在高效模型中的领先地位,但与顶级大模型仍有差距。
⚖️ 评分理由
- 学术质量(6.5/7):创新性很强,提出了有理论支撑的混合生成范式,解决了当前领域的一个核心问题。实验设计全面,覆盖了从理解到生成的多个任务,并进行了详尽的消融研究和超参数分析。结果具有说服力,清晰地展示了框架的优势。扣分点:1)在部分综合性基准上尚未达到最顶尖水平;2)工程实现细节(如块级扩散的具体效率)可进一步深入分析。
- 选题价值(1.5/2):研究处于语音-语言模型发展的核心前沿,旨在打破AR模型在音频生成上的瓶颈,对于实现更自然、高效的实时语音交互至关重要。潜在影响广泛,适用于语音助手、对话系统等。扣分点:方法的实际部署成本与收益需在更广泛场景中验证。
- 开源与复现加成(0.5/1):提供了核心代码仓库和非常详细的训练配置,极大地降低了复现门槛。然而,未提及预训练模型权重和部分大规模训练数据的公开获取方式,这对于完全复现其最佳性能构成了一定障碍。