📄 From Natural Alignment to Conditional Controllability in Multimodal Dialogue
#语音合成 #多模态模型 #预训练 #多任务学习 #基准测试
🔥 8.0/10 | 前25% | #语音合成 | #多任务学习 | #多模态模型 #预训练
学术质量 5.5/7 | 选题价值 2.0/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Zeyu Jin(清华大学计算机科学与技术系)(论文标注共同贡献)
- 通讯作者:Xiaoyu Qin(清华大学计算机科学与技术系)、Jia Jia(清华大学计算机科学与技术系/BNRist)
- 作者列表:
- Zeyu Jin(清华大学计算机科学与技术系)
- Songtao Zhou(清华大学计算机科学与技术系)(共同贡献)
- Haoyu Wang(清华大学计算机科学与技术系)
- Minghao Tian(Rice University)
- Kaifeng Yun(清华大学深圳国际研究生院)
- Zhuo Chen(字节跳动)
- Xiaoyu Qin(清华大学计算机科学与技术系)
- Jia Jia(清华大学计算机科学与技术系/BNRist)
💡 毒舌点评
论文在数据集构建和任务定义上表现出色,其提出的数据整理管道和“情感三元组”标注范式为可控多模态对话研究提供了坚实基础,但核心模型创新有限,且部分实验局限于验证数据集有效性,未能充分探索更先进的生成架构。
🔗 开源详情
- 代码:论文在摘要和结论中明确提到将公开代码和数据整理管道,GitHub仓库链接已在论文中给出(https://github.com/jessyjinzy/MM-Dia)。
- 模型权重:论文未提及将公开其微调后的模型(如Higgs-Audio-V2-SFT)权重。
- 数据集:MM-DIA和MM-DIA-BENCH已承诺开源,但具体获取方式需联系作者或等待发布。
- Demo:论文提到了一个演示页面(https://mmdiaiclr26.github.io/mmdiaiclr26/),展示了不同控制变量下的语音合成样本。
- 复现材料:论文在“Reproducibility Statement”中承诺提供数据集、代码、模型配置、训练过程和评估协议的细节。附录包含了管道实现的部分算法和消融实验,但完整的训练超参数和硬件信息缺失。
- 引用的开源项目:论文中提到了多个依赖的开源工具和模型,包括:Higgs-Audio-V2 (Boson AI)、Dia-1.6B (Nari Labs)、Gemini-2.5系列、Qwen2.5-VL、InsightFace工具包、多个基线模型(HarmoniVox, FLOAT, MultiTalk, Sonic, Wan-2.2, HunyuanVideo)以及UTMOS、WER等评估工具。
📌 核心摘要
这篇论文旨在解决可控多模态对话生成中面临的三个核心挑战:高质量原生多模态对话数据稀缺、交互级语义的可扩展标注方法缺失,以及系统性评估基准不足。 其核心方法是构建了一个从电影和电视剧中自动提取、标注对话的“数据整理管道”,并据此创建了大规模多模态对话数据集 MM-DIA(360+小时,54,700段对话)。该数据集首次专注于跨模态的对话表达力,提供了句子级和对话级的细粒度交互标注,包括说话人身份、非语言声音和两种表达力标注范式:“情感三元组”(关系、互动模式、情感基调)和“自由描述”。同时,论文提出了 MM-DIA-BENCH 作为评估跨模态风格一致性的基准。 论文正式定义了多模态对话生成(MDG)任务,并将其应用于三个具体任务:1)风格可控对话语音合成(显式控制),2)视觉条件对话语音合成(隐式控制),3)语音驱动对话视频生成(隐式控制)。 主要实验结果显示:在MM-DIA上微调预训练模型(如Higgs-Audio-V2)后,风格可控对话语音合成任务在可懂度(WER从31.25降至4.45)和指令遵循度上显著提升。然而,在MM-DIA-BENCH上的测试表明,现有模型在维持隐式跨模态风格一致性方面存在明显不足,特别是在音视频对齐和对话级表达力方面。 这项工作的实际意义在于为可控、富有表现力的多模态对话生成研究建立了首个大规模数据集、统一任务框架和评估基准,指明了未来需要加强跨模态语义对齐和长程推理的研究方向。主要局限性是MDG任务仍处于初步定义阶段,且现有基线模型在隐式控制任务上表现不佳,表明这是一个开放且具挑战性的领域。
🏗️ 模型架构
本文的核心贡献并非一个单一的生成模型,而是一个完整的数据集构建系统(数据整理管道)和任务定义框架。整体架构可分为数据侧和模型侧两部分。
数据整理管道架构(图2):这是论文的核心系统,用于从原始影视数据中提取带有细粒度标注的多模态对话片段。
- 输入:原始视频、音频、字幕文件(官方或非校准版)、ASR转录文本。
- 关键组件与流程:
- 多模态对话提取:首先,使用容忍增强的场景边界检测方法,结合视觉语言模型(VLM,如Qwen2.5-VL)和大型语言模型(LLM)来识别连续的对话场景。此过程引入了“动态关键帧池”缓冲机制(算法1),以跨越快速镜头切换等视觉中断,保持对话连续性。
- 句子级细粒度标注:在确定的边界内,使用多模态(音视频+字幕)LLM(如Gemini-2.5-flash)进行说话人归属(利用预设的角色库),并标注非语言声音和主说话人在关键帧中的可见性。
- 对话级表达力标注:使用更强大的多模态LLM(如Gemini-2.5-pro)对提取出的对话片段进行两种范式的标注:a) 情感三元组(关系、互动模式、情感基调);b) 自由描述(每个说话人每个轮次的风格轨迹)。
- 数据流与设计动机:整个管道的设计旨在克服影视数据中常见的噪声(背景音、画外音)、镜头语言复杂(闪回、视角变化)和音视频异步问题。通过结合视觉连续性、字幕对齐和LLM的语义理解能力,实现从“野外”数据到结构化多模态对话数据的自动化转换。
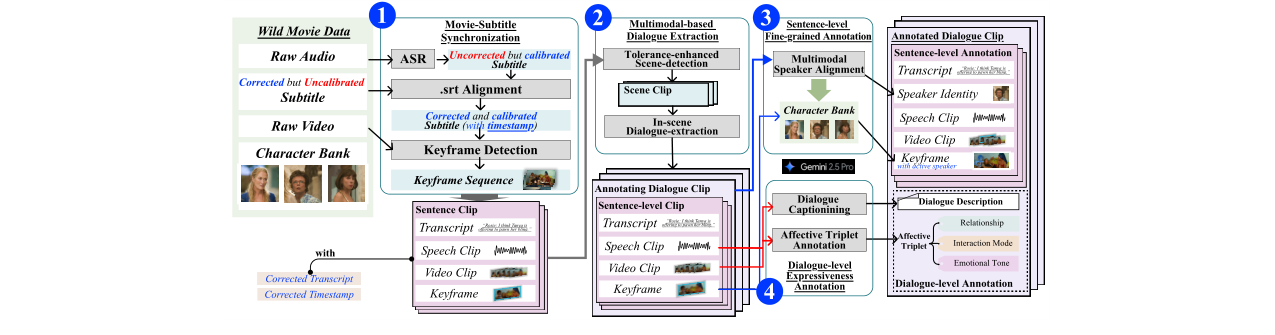
图2:从电影/TV原始数据中提取并标注多模态对话的管道框架。展示了从字幕校准、基于多模态的对话提取、句子级细粒度标注到对话级表达力标注的四个步骤。
下游生成任务架构:论文并未提出新的端到端生成模型,而是基于现有预训练骨干模型(如Higgs-Audio-V2, Dia-1.6B)通过微调或添加轻量级适配器来适配不同的MDG任务。例如,在风格可控语音合成任务中,将风格条件(情感三元组或自由描述)通过适配器投影到生成模型的解码器中。
💡 核心创新点
- 首个专注于对话表达力的大规模多模态数据集(MM-DIA)与基准(MM-DIA-BENCH):
- 局限性:此前数据集要么局限于单模态(文本对话、语音对话),要么在多模态(如MELD)中缺乏对交互级风格和跨模态一致性的细粒度标注。
- 创新与收益:MM-DIA提供了前所未有的360+小时、带精细标注的对话数据,其标注不仅包含内容,更强调交互行为(关系、互动模式、情绪动态)。MM-DIA-BENCH则专门用于评估跨模态风格一致性。这为训练和评估可控多模态对话模型提供了必要基础。
- 创新的对话表达力标注范式:
- 局限性:传统标注多为离散标签(如情感分类),难以捕捉连续、多粒度的交互风格。
- 创新与收益:提出情感三元组(结构化、场景级控制)和自由描述(自然语言、轮次级控制)两种互补范式。前者便于结构化建模,后者提供灵活、细粒度的控制。量化维度(情感强度、情感波动度)进一步丰富了表达力的衡量。
- 提出多模态对话生成(MDG)统一框架与三大任务:
- 局限性:现有对话生成研究常将语义生成与模态映射分离,忽视跨模态交互风格的系统性建模。
- 创新与收益:正式将MDG定义为给定多模态上下文,生成在语义、跨模态对齐和可控性上均合格的对话。明确了显式(风格描述)和隐式(跨模态线索)两种控制模式,并衍生出三个具体任务,为该领域建立了清晰的研究图景。
🔬 细节详述
- 训练数据:
- 数据集:主要使用作者构建的 MM-DIA 数据集(360.26小时,54,700对话片段),来源于200+部电影和9部电视剧。另构建了包含309个高表达性双说话人对话的 MM-DIA-BENCH 作为测试集。
- 预处理与增强:通过复杂的多模态管道(字幕校准、VLM+LLM边界检测、说话人对齐)从原始影视数据中提取。校准过程结合了多源字幕和ASR结果,以平衡时间准确性和文本保真度。
- 损失函数:论文中未明确说明下游生成任务微调所使用的具体损失函数。通常,语音生成任务可能使用扩散模型或流匹配的损失,但此处未提供细节。
- 训练策略:论文聚焦于数据集构建和任务验证,对于生成模型的微调细节描述有限。提到对Higgs-Audio-V2和Dia-1.6B进行监督微调(SFT),并为后者引入轻量级适配器以支持条件输入。具体的学习率、优化器、训练轮数等未说明。
- 关键超参数:数据整理管道中的缓冲区大小
b在消融实验中测试(表9),最终选择b=3。生成模型的具体参数(如Higgs-Audio-V2的参数量)未说明。 - 训练硬件:未说明。
- 推理细节:在风格可控语音合成任务中,推理时直接建模连续的对话语音流,而非逐句拼接。对于Dia-1.6B,通过适配器注入风格条件。具体解码策略未说明。
- 正则化或稳定训练技巧:未说明。
📊 实验结果
论文实验分为两部分:验证数据集对显式控制任务的有效性,以及使用基准测试集揭示隐式控制任务的挑战。
任务1:风格可控对话语音合成(显式控制) 在Test集上,以“自由描述”为风格控制条件的结果如下(表4):
| 模型 | 语音质量 (WER↓/UTMOS↑) | 对话质量 (sa-SIM↑/cp-WER↓) | 人工MOS (质量/指令遵循) | Gemini-as-Judge (质量/指令遵循) |
|---|---|---|---|---|
| Dia-Base | 19.991 / 2.272 | 0.389 / 51.713 | 2.41 / 2.50 | 4.25 / 3.81 |
| Dia-SFT | 29.071 / 1.974 | 0.447 / 57.813 | 2.89 / 2.88 | 3.97 / 3.60 |
| Higgs-Audio-V2-Base | 31.251 / 3.093 | 0.475 / 104.867 | 3.58 / 3.11 | 3.87 / 4.01 |
| Higgs-Audio-V2-SFT | 4.450 / 3.280 | 0.447 / 33.765 | 4.44 / 4.13 | 4.85 / 4.71 |
| 表4:以“自由描述”为控制条件,在Test集上的对话语音合成结果。Higgs-Audio-V2-SFT在WER、cp-WER及所有主观指标上均取得最佳。 |
关键结论:在MM-DIA上微调显著提升了模型性能,特别是Higgs-Audio-V2-SFT,WER从31.25大幅降至4.45,指令遵循度大幅提升,证明了数据集的有效性。
任务2&3:隐式控制任务(视觉条件语音合成 & 语音驱动视频生成) 在MM-DIA-BENCH(133个样本)上进行测试,部分结果如下(表5、表6):
视觉条件对话语音合成(表5):
| 模型 | 语音质量 (WER↓) | 对话质量 (cp-WER↓) | 标签召回↑ | Gemini-as-Judge (指令遵循↑) |
|---|---|---|---|---|
| HarmoniVox | 21.223 | 30.981 | 40.47% | 2.410 |
| Cascaded GPT+Higgs | 5.793 | 14.583 | 52.17% | 3.522 |
| 表5:视觉条件对话语音合成结果。级联方法(先用VLM生成描述再合成语音)在各项指标上优于端到端方法HarmoniVox。 |
语音驱动对话视频生成(表6):
| 模型 | 视觉质量 (FVD↓) | 唇音同步 (LSE-C↑/LSE-D↓) | Gemini-as-Judge (质量/指令遵循) |
|---|---|---|---|
| Ground Truth | - | 6.275 / 8.333 | 5.000 / 4.902 |
| MultiTalk | 124.543 | 5.305 / 8.795 | 4.922 / 4.631 |
| Sonic | 117.096 | 4.986 / 8.503 | 4.833 / 4.750 |
| HunyuanVideo (T2V) | 335.591 | - | 4.309 / 2.293 |
| 表6:语音驱动对话视频合成结果。现有模型在质量、唇音同步和对话级语义对齐(指令遵循)上均与真实视频有差距。 |
关键结论:在隐式控制任务中,虽然语音合成质量尚可,但跨模态的风格一致性(如音视频情感匹配)是当前系统的显著瓶颈(表5中指令遵循分远低于显式控制任务)。视频生成任务则面临身份连续性、多粒度对齐和场景规划等多重挑战(表6)。
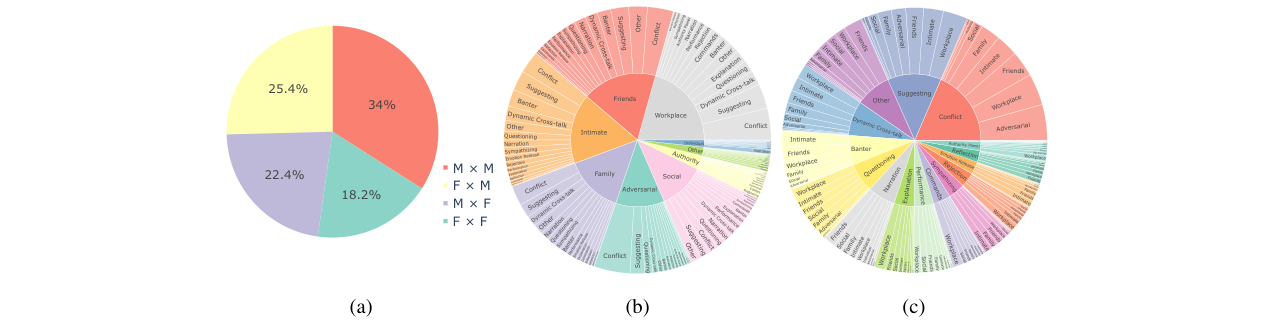
图3:MM-DIA数据集分布。(a) 双说话人性别组合;(b) 人物关系分布;(c) 不同关系下的互动模式分布。图表展示了数据集的多样性。
⚖️ 评分理由
- 学术质量:5.5/7:论文的贡献主要体现在系统构建(数据整理管道、数据集、基准、任务定义)而非算法创新。它解决了该领域一个真实且重要的基础设施问题,实验设计合理,数据集构建过程严谨,验证了数据集的有效性。然而,在生成模型本身未提出新架构,且部分实验(如视频生成)更多是评估而非提出解决方案,技术深度略显不足。
- 选题价值:2.0/2:选题非常前沿且关键。“可控多模态对话生成”是实现自然人机交互和创意内容制作的核心挑战。本文提供的基础设施(数据、基准、统一定义)对该方向的研究具有很高的实用价值和推动作用,与音频/语音研究者高度相关。
- 开源与复现加成:0.5/1:论文明确承诺将公开数据集MM-DIA、MM-DIA-BENCH以及代码和管道,这极大提升了研究的可复现性。复现细节在附录中有一定说明,但生成模型训练的具体细节仍缺失,扣分项在此。因此给予正向但非满分的加成。