📄 FlowBind: Efficient Any-to-Any Generation with Bidirectional Flows
#跨模态生成 #音频生成 #流匹配 #多模态模型
🔥 9.5/10 | 前10% | #跨模态生成 | #流匹配 | #音频生成 #多模态模型
学术质量 6.5/7 | 选题价值 2.0/2 | 复现加成 1.0 | 置信度 高
👥 作者与机构
- 第一作者:Yeonwoo Cha* (KAIST)
- 通讯作者:Seunghoon Hong (KAIST)
- 作者列表:Yeonwoo Cha (KAIST), Semin Kim (KAIST), Jinhyeon Kwon (KAIST), Seunghoon Hong (KAIST)(*表示同等贡献)
💡 毒舌点评
亮点在于其“共享潜在空间+单模态可逆流”的设计,用近乎暴力的简洁性一举解决了多模态生成中数据配对、计算成本和训练复杂度的“不可能三角”,工程思想非常漂亮。短板是论文为了突出效率,选用的模型体量和训练数据远小于前沿基线,可能在生成质量的绝对上限上有所妥协,且对更复杂的模态交互(如高保真视频生成)的能力尚未被充分验证。
🔗 开源详情
- 代码:论文明确提供了项目主页和代码仓库链接:
https://yeonwoo378.github.io/official_flowbind。 - 模型权重:论文未提及是否公开预训练模型权重。
- 数据集:论文详细描述了使用的训练数据集(LAION-COCO, Flickr-30k, AudioCaps v2, VGGSound)及其来源,但这些是现有公开数据集,FlowBind本身未发布新数据集。
- Demo:项目主页可能包含演示,但论文中未明确提及。
- 复现材料:提供了非常充分的复现材料,包括:详细的模型架构(MLP with AdaLN-zero)、训练配方(优化器、batch size、训练步数、硬件)、所有超参数、评估协议及指标计算细节。
- 论文中引用的开源项目:EmbeddingGemma (Team et al., 2025), CLIP (Radford et al., 2021), Stable-UnCLIP, CLAP (Elizalde et al., 2023), AudioLDM (Liu et al., 2023), Gemma3-1B。
📌 核心摘要
本文旨在解决现有基于流匹配的任意到任意(any-to-any)多模态生成方法效率低下的问题,这些问题包括:对数据配对要求严格(需大量完全配对数据)、计算成本高(需建模联合分布)以及训练流程复杂(多阶段训练)。FlowBind提出一个简洁的框架,其核心思想是学习一个能捕捉跨模态共性的可学习共享潜在空间,并为每个模态配备一个连接该潜在空间的可逆流。所有组件在单一的流匹配目标下联合优化,推理时各模态的可逆流可直接作为编码器/解码器实现跨模态翻译。与基线CoDi和OmniFlow相比,FlowBind通过因式分解相互作用,自然支持使用任意子集模态数据进行训练,在大幅降低数据需求和计算成本的同时,达到了有竞争力的生成质量。实验表明,在文本、图像和音频任务上,FlowBind参数量仅为OmniFlow的约1/6,训练速度快约10倍,且生成质量可比。该框架的意义在于为高效、灵活的多模态生成提供了一种新的通用解决方案。主要局限性在于其当前实验的模型规模较小,在生成细节的保真度上可能不及更庞大的基线模型,且对更复杂、高维的模态(如视频)的泛化能力有待进一步证明。
🏗️ 模型架构
FlowBind的整体架构旨在通过一个可学习的共享潜在空间将任意模态连接起来。
整体输入输出流程:给定一个或多个源模态数据,通过对应模态的可逆流反向积分(ODE求解)将其映射到共享潜在空间,得到对共享潜在表示的估计(多个源时取平均)。然后,通过目标模态的可逆流正向积分,从共享潜在表示生成目标模态的数据。
主要组件:
- 模态特定编码器与解码器:每个模态(文本、图像、音频)使用冻结的预训练编码器(如EmbeddingGemma用于文本,CLIP用于图像,CLAP用于音频)将其映射到紧凑的语义潜在表示。同时,每个模态也有对应的解码器,用于从潜在表示重建原始数据。这些编码器和解码器不参与FlowBind的训练,仅提供高维数据与低维潜在空间之间的桥梁。
- 辅助编码器 Hϕ:这是一个可训练的神经网络(MLP),其功能是在训练阶段,接收某个模态子集(S)的潜在表示
{zi},并生成一个共享潜在表示z*。其边际分布近似于需要学习的跨模态共享分布。 - 模态特定漂移网络 {vθi}:为每个模态 i 训练一个独立的漂移网络 vθi。它的核心功能是学习一个向量场,定义从共享潜在表示
z*到该模态潜在表示zi的直线插值路径(或反向路径)上的速度。在训练时,它学习预测给定插值点zit和时间t时的目标速度。
组件间数据流与交互:
- 训练时:对于一批部分配对的多模态数据
zS(例如,只有文本-图像对),辅助编码器 Hϕ 接收zS中所有模态的潜在表示,输出共享潜在z。对于S中的每个模态i,在其潜在表示zi和共享潜在z之间进行线性插值得到zit。漂移网络vθi预测zit上的速度,并与目标速度(zi - z*)计算流匹配损失。关键技巧在于,对 t=0 时的损失梯度会回传更新辅助编码器 Hϕ,而对 t>0 的情况则停止梯度传播,仅更新漂移网络,以此稳定训练并防止编码器坍缩。 - 推理时:辅助编码器 Hϕ 不再使用。对于单个源模态 i,其数据经编码后得到
zi,通过vθi反向积分(t=1→0)得到对共享潜在的估计ẑ。然后,将ẑ作为输入,通过目标模态 j 的漂移网络vθj正向积分(t=0→1),生成目标模态 j 的潜在表示,最后经解码器解码为输出。对于多个源模态,分别得到各自的ẑ*(i)后取平均作为共享潜在的估计,再进行生成。
关键设计选择:
- 使用紧凑语义表示而非原始数据或高维特征:降低了计算复杂度,使跨模态对齐在低维空间中更易学习。
- 可学习的共享潜在空间而非固定锚点(如文本):解除了对文本模态的强制依赖,允许模型直接从任意模态对中学习对齐,更灵活。
- 单阶段联合优化:避免了CoDi和OmniFlow等方法中分离的对齐与生成训练阶段,简化了流程。
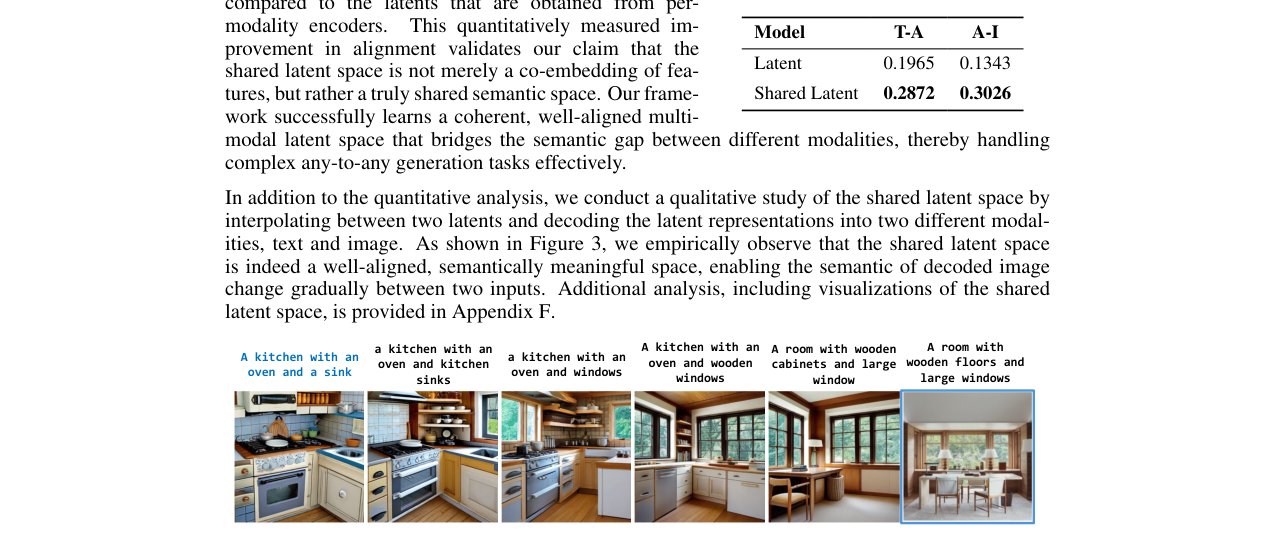
图1展示了FlowBind的整体框架。(a) 训练阶段,共享潜在和各模态漂移网络在单一阶段内联合学习。(b) 推理阶段,利用学习到的各模态漂移网络通过正向/反向求解ODE实现灵活的任意到任意生成。
💡 核心创新点
- 可学习的共享潜在空间作为跨模态锚点:不同于以往方法将所有模态对齐到固定的文本表示,FlowBind引入了一个可学习的共享潜在分布。该空间由辅助编码器在训练中动态塑造,其目标是最大化包含关于各模态的信息(最小化条件方差),从而成为一个更优的跨模态信息中枢。
- 基于单模态可逆流的因式分解建模:将复杂的多模态联合分布建模问题,分解为多个独立的“共享潜在 ↔ 单一模态”的流匹配问题。每个漂移网络只需关注与共享潜在之间的直线变换,极大地降低了模型复杂度与计算量,并使得模型可以自然地利用任意配对的模态数据进行训练。
- 单目标、单阶段的统一训练范式:所有组件(辅助编码器和各漂移网络)仅通过一个流匹配损失函数进行联合优化,无需引入额外的对比损失或复杂的多阶段训练流程。论文通过在t=0时停止梯度这一简洁技巧,有效防止了辅助编码器坍缩到常数,并提供了理论分析(损失分解为未解释方差与漂移近似误差)。
🔬 细节详述
- 训练数据:使用三种配对数据:文本-图像(LAION-COCO子集242K + Flickr30k 30K)、文本-音频(AudioCaps v2 91K)、音频-图像(VGGSound 184K)。未使用三模态完全配对的数据。数据详情见论文Table 8。
- 损失函数:统一的流匹配损失,公式为
L(θ, ϕ) = E[Σ_{i∈S} ||vθi(zit, t) - (zi - z)||²]。其中z = Hϕ(zS)。在训练时,时间采样t从混合分布(1-α)Unif(0,1) + αδ(t=0)中采样(α未明确给出),以平衡漂移网络和编码器的更新。 - 训练策略:
- 优化器:Adam。
- Batch Size:全局batch size为1024。
- 训练步数:200K iterations。
- 训练时长:约48 GPU-hours(NVIDIA H100)。
- 调度策略:论文未提及学习率调度,可能为固定学习率。
- 关键超参数:
- 模型大小:总可训练参数量为568M。所有漂移网络和辅助编码器的特征维度统一为768。
- 架构:基于MLP,带有残差连接。漂移网络使用AdaLN-zero进行时间调制。
- 推理细节:使用ODE求解器积分学习到的向量场。对于多源输入,在共享潜在空间中对各源模态反向积分得到的估计进行简单平均。论文未提及解码时的具体温度或采样步数等。
- 正则化或稳定训练技巧:
- 梯度停止:在计算漂移网络损失时,对t>0的情况,停止从损失向辅助编码器Hϕ传播的梯度。
- t=0时的直接更新:在t=0时,梯度同时更新漂移网络和辅助编码器,以优化共享潜在。
- 端点速度预测:以0.3的概率使用t=1时的速度预测目标进行训练,以增强稳定性(引用自Kim et al., 2024)。
- 固定方差正则化:辅助编码器中引入了固定的方差项作为超参数,以正则化学习到的表示。
📊 实验结果
论文在文本、图像、音频的任意到任意生成任务上进行了评估,重点对比了CoDi和OmniFlow这两个强基线。
主要定量结果(One-to-One生成): 下表总结了模型在六个一对一生成任务上的质量(表2)和对齐(表3)性能。FlowBind在多数任务上取得了最佳或接近最佳的质量指标,同时在大部分对齐指标上表现优异。
表2:生成质量评估 (One-to-One)
| 模型 | T→I (FID↓) | I→T (CIDEr↑) | T→A (FAD↓) | A→T (CIDEr↑) | I→A (FAD↓) | A→I (FID↓) |
|---|---|---|---|---|---|---|
| Specialists | ||||||
| SD3-Medium | 25.40 | - | - | - | - | - |
| FLUX.1 | 22.06 | - | - | - | - | - |
| LLaVA-NeXT | - | 109.3 | - | - | - | - |
| TangoFlux | - | - | 1.41 | - | - | - |
| AudioX | - | - | 3.09 | - | - | - |
| Seeing & Hearing | - | - | - | - | 5.31 | - |
| Sound2Vision | - | - | - | - | - | 42.55 |
| Generalists | ||||||
| UnifiedIO2-L | 21.54 | 134.7* | 8.31 | 12.15 | - | - |
| CoDi | 24.80 | 16.40 | 9.84 | 6.62 | 14.58 | 50.4 |
| OmniFlow | 22.97 | 44.20 | 4.20 | 31.79 | 5.67 | 106.03 |
| FlowBind | 17.39 | 46.26 | 4.19 | 55.11 | 2.50 | 26.60 |
表3:跨模态对齐评估 (One-to-One)
| 模型 | T→I (CLIP↑) | I→T (CLIP↑) | T→A (CLAP↑) | A→T (CLAP↑) | I→A (AIS↑) | A→I (AIS↑) |
|---|---|---|---|---|---|---|
| Specialists | ||||||
| SD3-Medium | 31.60 | - | - | - | - | - |
| FLUX.1 | 31.06 | - | - | - | - | - |
| LLaVA-NeXT | - | 32.14 | - | - | - | - |
| TangoFlux | - | - | 42.71 | - | - | - |
| AudioX | - | - | 29.29 | - | - | - |
| Seeing & Hearing | - | - | - | - | 75.11 | - |
| Sound2Vision | - | - | - | - | - | 62.39 |
| Generalists | ||||||
| UnifiedIO2-L | 30.71 | 30.73 | 13.48 | 18.68 | - | - |
| CoDi | 30.26 | 26.24 | 10.79 | 17.94 | 61.55 | 74.26 |
| OmniFlow | 31.52 | 27.71 | 24.23 | 45.08 | 71.71 | 59.22 |
| FlowBind | 28.35 | 29.74 | 29.08 | 36.70 | 82.89 | 78.17 |
训练效率对比 (Table 1):这是论文的关键论据。
| 模型 | 训练参数量 | GPU-hr | 训练数据量 | 联合训练 |
|---|---|---|---|---|
| CoDi | 4.3B | - | #(T-I): 400M, #(T-A): 3.5M, #(I-A): 1.9M | 否 |
| OmniFlow | 3.2B | 480hr* | #(T-I): 28M, #(T-A): 2.4M, #(T-A-I): 2.2M | 否 |
| FlowBind | 568M | 48hr | #(T-I): 310K, #(T-A): 96K, #(I-A): 180K | 是 |
| FlowBind的参数量仅为OmniFlow的17.8%,训练时间仅为10%,训练数据量不足1.8%,且支持联合训练。 |
Many-to-Many生成定量结果:论文构建了合成三元组数据集进行评估。结果显示FlowBind在多输入生成中能更均衡地利用所有条件模态。 表4:多对一生成对齐性能 (Many-to-One)
| 模型 | (I+A)→T | (T+A)→I | (T+I)→A | |||
|---|---|---|---|---|---|---|
| CLIP (I→T) | CLAP (A→T) | CLIP (T→I) | AIS (A→I) | CLAP (T→A) | AIS (I→A) | |
| CoDi | 24.04 | 20.66 | 25.17 | 57.52 | 4.85 | 61.28 |
| OmniFlow | 26.38 | 36.07 | 24.06 | 54.90 | 7.68 | 59.32 |
| FlowBind | 27.83 | 35.21 | 25.57 | 57.93 | 28.13 | 76.02 |
表5:一对多生成对齐性能 (One-to-Many)
| 模型 | T→(I+A) | I→(T+A) | A→(T+I) | |||
|---|---|---|---|---|---|---|
| CLIP (T→I) | CLAP (T→A) | CLIP (I→T) | AIS (I→A) | CLAP (A→T) | AIS (A→I) | |
| CoDi | 26.61 | 10.99 | 25.73 | 58.65 | 18.03 | 57.14 |
| OmniFlow | 24.71 | 12.92 | 26.36 | 63.99 | 36.07 | 54.22 |
| FlowBind | 25.02 | 29.12 | 27.98 | 74.34 | 36.79 | 59.99 |
定性结果分析:
- 图2展示了FlowBind处理复杂一对多、多对一生成的能力,能够忠实反映输入条件。
- 附录中的定性结果(图8-16)表明,FlowBind在保持内容一致性方面通常优于CoDi和OmniFlow,尤其是在多对一任务中,基线模型容易忽略某个输入模态。
消融与分析实验:
- 固定锚点 vs. 可学习锚点 (Table 6):证明使用可学习的共享潜在空间比使用固定的文本锚点(如CoDi的做法)能获得更好的跨模态对齐。
- 共享潜在空间对齐度分析 (Table 7):使用CKNNA指标测量,发现共享潜在空间的跨模态对齐度显著高于各模态单独编码的潜在空间,验证了其语义一致性。
- 共享潜在空间插值可视化 (图3):展示了在共享潜在空间中进行插值并解码为文本和图像时,内容平滑过渡,证明了其语义有意义。
- 鲁棒性分析 (图4):在文本和音频条件冲突时,FlowBind能较好地融合信息,而非崩溃或忽略一个模态。
图2展示了FlowBind在多对一(a)和一对多(b)生成任务中的定性结果,显示了其忠实反映复杂输入条件的能力。
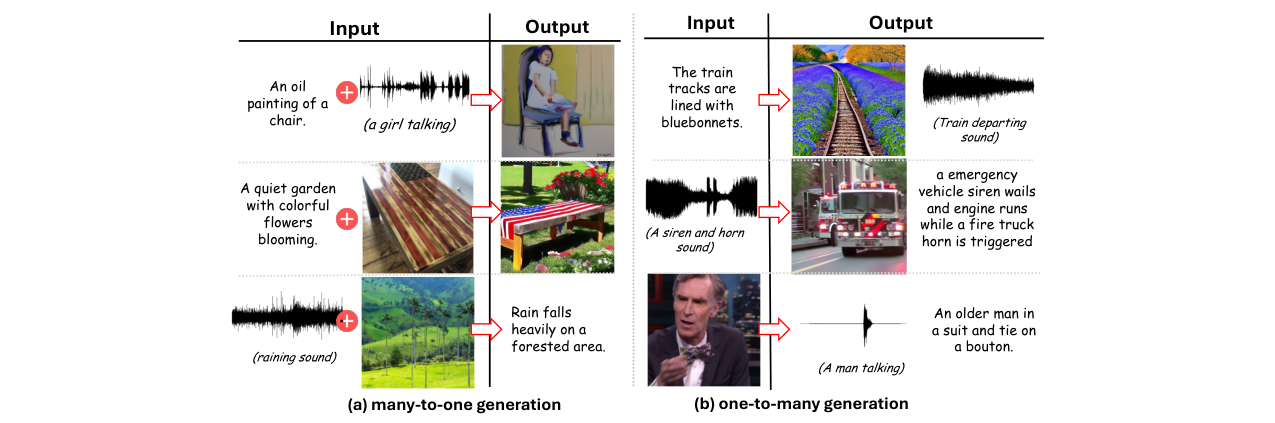
图3展示了在FlowBind的共享潜在空间中插值并解码为文本和图像的结果,显示了语义内容的平滑过渡。
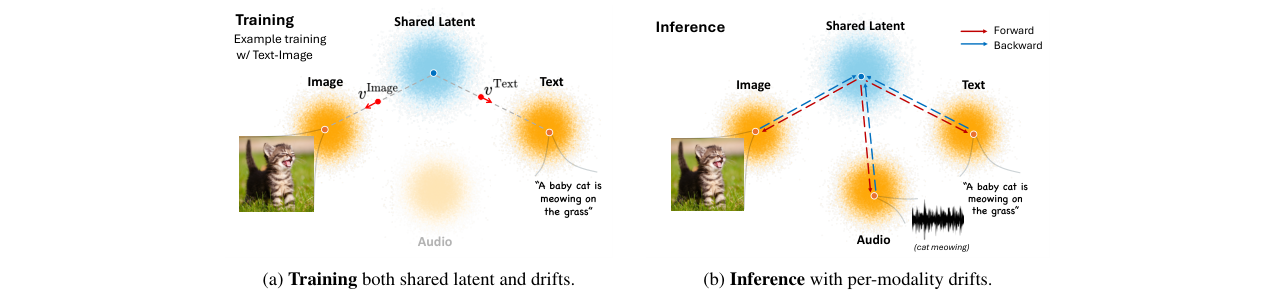
图4展示了在文本与音频条件冲突时,FlowBind的生成结果,表明其鲁棒性。
⚖️ 评分理由
- 学术质量:6.5/7:论文的核心创新(共享潜在+单模态流)清晰、优雅且有效,理论分析(损失分解)为设计选择提供了坚实支撑。实验在效率维度(参数、数据、计算)上提供了压倒性的证据,并在生成质量上展示了竞争力。主要扣分点是:1)为了凸显效率优势,模型和训练数据规模远小于最强基线,其生成质量的绝对上限有待在更充裕资源下验证;2)部分基线(CoDi)未开源,严格意义上的可复现对比受限。
- 选题价值:2.0/2:直击多模态生成的核心瓶颈(效率与灵活性),提出的解决方案具有高度通用性和可扩展性(已展示扩展至3D点云),对学术界和工业界构建实用多模态系统都有重要启发。
- 开源与复现加成:+1.0:提供了详尽的复现信息:完整代码仓库链接、项目主页、模型架构细节、所有训练数据集描述与来源、关键超参数。论文本身可作为一份优秀的复现指南。