📄 Flow2GAN: Hybrid Flow Matching and GAN with Multi-Resolution Network for Few-step High-Fidelity Audio Generation
#音频生成 #流匹配 #GAN #少样本生成 #波形生成
🔥 8.0/10 | 前25% | #音频生成 | #流匹配 | #GAN #少样本生成
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Zengwei Yao(Xiaomi Corp., Beijing, China)
- 通讯作者:Daniel Povey(dpovey@xiaomi.com,Xiaomi Corp., Beijing, China)
- 作者列表:Zengwei Yao(Xiaomi Corp.)、Wei Kang(Xiaomi Corp.)、Han Zhu(Xiaomi Corp.)、Liyong Guo(Xiaomi Corp.)、Lingxuan Ye(Xiaomi Corp.)、Fangjun Kuang(Xiaomi Corp.)、Weiji Zhuang(Xiaomi Corp.)、Zhaoqing Li(Xiaomi Corp.)、Zhifeng Han(Xiaomi Corp.)、Long Lin(Xiaomi Corp.)、Daniel Povey(Xiaomi Corp.)
💡 毒舌点评
这篇论文巧妙地将Flow Matching的稳定训练与GAN的精细生成结合,提出了一种两阶段训练范式,成功实现了少步甚至一步的高质量音频生成,解决了推理速度与生成质量难以兼得的核心矛盾。但多分支网络结构增加了模型复杂度和实现难度,且论文主要验证语音波形生成,其对非语音、复杂环境音频的泛化优势并未充分体现。
🔗 开源详情
- 代码:提供代码仓库链接:
https://github.com/k2-fsa/Flow2GAN。 - 模型权重:提供预训练检查点(checkpoints),在代码仓库中可用。
- 数据集:实验所用数据集(LibriTTS, Common Voice等)均为公开数据集。
- Demo:提供在线演示样例:
https://flow2gan.github.io。 - 复现材料:论文在5.1节和附录A.3中提供了详尽的训练细节、模型配置(表10)、数据预处理信息、评估指标和基线模型设置,复现指导非常充分。
- 论文中引用的开源项目:依赖或对比的开源项目包括:Vocos, HiFi-GAN (MPD), UnivNet (MRD), BigVGAN, RFWave, PeriodWave, WaveFM, Encodec, F5-TTS, ScaledAdam优化器等。
📌 核心摘要
- 要解决什么问题:现有音频生成方法面临两难:GAN训练不稳定、易模式崩塌;而基于扩散/Flow Matching的方法虽然训练稳定、生成质量高,但需要多步采样,推理计算开销大。
- 方法核心是什么:提出Flow2GAN两阶段框架。第一阶段使用针对音频特性改进的Flow Matching进行预训练,以学习稳健的生成能力;第二阶段构建少步生成器,并使用精心设计的判别器(MPD, MRD)进行GAN微调,以实现高效、精细的音频生成。
- 与已有方法相比新在哪里:a) 改进Flow Matching:将训练目标从估计速度场重新表述为端点估计(预测干净音频x1),避免了在音频静音区域估计速度的困难;引入谱能量自适应损失缩放,强调感知上更显著的静音区域。b) 两阶段训练策略:将改进的Flow Matching与GAN微调结合,前者提供强初始化,后者高效提升细节和推理速度。c) 多分辨率网络架构:扩展Vocos的单分辨率设计,采用多分支处理不同时间-频率分辨率的傅里叶系数,增强了模型的建模能力。
- 主要实验结果如何:实验表明,Flow2GAN在Mel频谱图和音频令牌(Encodec)条件下均实现了高质量生成。在LibriTTS测试集上,其4步模型在PESQ(4.484)、ViSQOL(4.986)上优于所有对比方法(包括BigVGAN-v2, 但后者在大规模数据上训练)。1步模型也达到有竞争力的性能(PESQ 4.189, ViSQOL 4.957)。在通用音频令牌生成任务上,Flow2GAN在多数指标上优于MBD, RFWave等方法。推理速度方面,其1步模型在CPU上的xRT为4.85(优于实时),GPU上高达851.67倍实时,远超大多数扩散模型。
- 实际意义是什么:该工作提供了在音频生成领域质量与效率之间更优的权衡方案。少步甚至一步推理能力使其非常适合实时或资源受限的应用场景(如TTS系统、交互式音频合成)。作为TTS声码器时,其4步版本与PeriodWave-Turbo性能相当但速度更快。
- 主要局限性是什么:a) 模型参数量(78.9M)大于Vocos(13.5M)和RFWave(18.1M),略逊于BigVGAN(112.4M)。b) 论文主要评估在语音波形生成上,对于更复杂的非语音音频(如音乐、环境声)的优势有待进一步验证。c) GAN微调阶段需要针对不同步数(1/2/4步)分别训练和部署独立模型,增加了维护成本。
🏗️ 模型架构
Flow2GAN是一个两阶段训练框架,其核心是一个多分辨率、多分支的卷积神经网络,在频域处理音频信号。
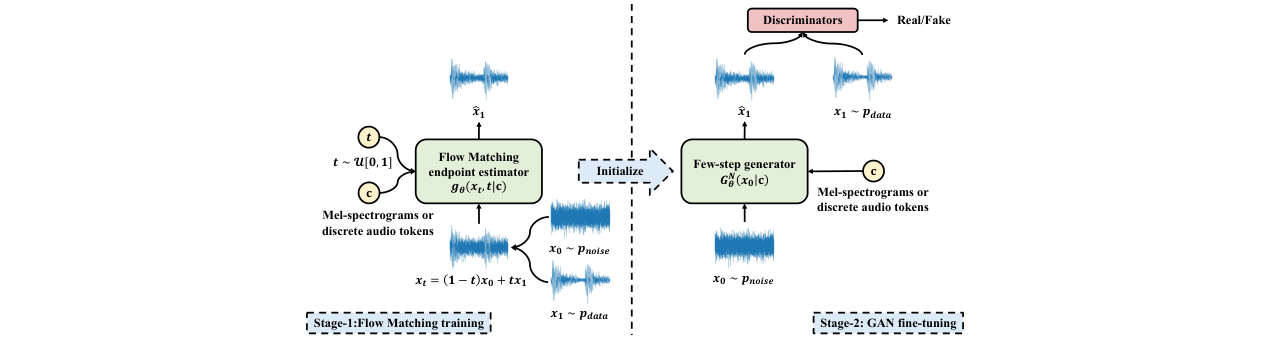
图1:Flow2GAN的整体框架流程图。展示了从第一阶段Flow Matching训练到第二阶段GAN微调的完整过程。
整体流程与输入输出:
- 输入:压缩的声学表示,如Mel频谱图(Mel-spectrograms)或离散音频令牌(discrete audio tokens)。
- 第一阶段(Flow Matching训练):模型学习从噪声
x0到目标音频x1的传输路径。网络gθ(xt, t|c)被训练为直接预测目标端点x1,其中xt是中间噪声样本。 - 第二阶段(GAN微调):将训练好的Flow Matching模型前向传播N步,构建一个N步生成器
GNθ(x0|c)。然后使用多周期判别器(MPD)和多分辨率判别器(MRD)对其进行对抗性微调,以提升细节和实现少步推理。 - 输出:高保真度的音频波形。
多分支多分辨率网络结构:
图3:多分辨率网络结构图。模型包含三个并行分支,每个分支处理不同时间-频率分辨率的傅里叶系数。
这是Flow2GAN的骨干网络,受Vocos启发并进行了扩展:
- 三个处理分支:每个分支负责不同分辨率的频谱处理。
- 输入信号通过STFT转换为复数傅里叶系数(实部和虚部拼接)。
- 系数送入一个ConvNeXt模块进行处理,输出新的复数系数。
- 通过ISTFT将处理后的系数转换回波形域。
- 三个分支的输出相加得到最终波形。
- 分辨率设计:使用更大的嵌入维度处理低帧率(如长窗口)分支,以捕获全局结构;使用较小的嵌入维度处理高帧率(如短窗口)分支,以捕获局部细节。这种设计在性能和效率间取得了平衡。
- 条件编码器:一个独立的ConvNeXt模块,用于处理输入的条件信息(Mel频谱图或令牌嵌入),提取深层特征。其输出作为共享条件,在Flow Matching推理的所有采样步骤中重复使用,避免了冗余计算。
- 关键设计选择:
- 在频域处理(类似Vocos),相比直接处理波形,可节省计算和内存。
- 多分辨率设计能更全面地建模音频在不同尺度上的复杂性,这是对单分辨率方法(如Vocos)的重要改进。
- 整个模型(包括STFT/ISTFT)是端到端可微的,便于联合优化。
💡 核心创新点
- 将Flow Matching目标重构为端点估计:这是最核心的方法创新。传统Flow Matching估计速度场
vt = x1 - x0,但在音频静音区域(x1≈0),模型需要准确估计-x0来抵消噪声,学习难度大。Flow2GAN改为直接预测干净音频x1,将问题转化为从噪声版本中恢复目标,学习目标更稳定、统一,尤其适合音频这种包含大量静音的数据。 - 引入谱能量自适应损失缩放:针对人类听觉感知特性,静音区域的误差比响亮区域更易察觉。该损失在时频域对预测误差进行缩放,权重与参考频谱的能量成反比,迫使模型在感知上更重要的安静区域投入更多学习精力。相比先前只在时间帧上做能量缩放的方法,这种二维缩放更全面,实验证明效果更优。
- 两阶段训练范式(Flow Matching + GAN微调):巧妙地结合了两种范式的优点。第一阶段利用改进的Flow Matching进行稳定、快速的预训练,赋予模型强大的生成先验;第二阶段利用GAN的对抗性学习,在预训练模型的基础上进行轻量级微调,高效地增强细节生成能力并实现少步推理。实验表明,这比纯GAN训练收敛更快、效果更好(表4)。
- 多分辨率网络架构:在Vocos的单分辨率傅里叶系数处理基础上,扩展为多分支、多分辨率的架构。这为模型提供了更强的表示能力,使其能够同时捕捉音频的宏观结构和微观细节,是提升生成质量的关键组件(表6)。
🔬 细节详述
- 训练数据:
- Mel频谱图条件:LibriTTS 数据集,585小时英语语音,24kHz采样率。
- 音频令牌条件:多个通用音频数据集混合,包括Common Voice 7.0(语音),DNS Challenge 4(语音),MTG-Jamendo(音乐),AudioSet和FSD50K(声音事件),均重采样至24kHz。
- 损失函数:
- Flow Matching损失 (L’FM):简化后的端点估计损失
Et,x0,x1[∥gθ(xt, t|c) - x1∥²],去除了原始公式中可能导致训练不稳定的权重因子1/(1-t)²。 - GAN损失:使用HingeGAN对抗性损失。
- 特征匹配损失:L1损失,用于匹配判别器中间层特征。
- 重建损失:多尺度Mel频谱图重建损失,窗口长度为{32, 64, 128, 256, 512, 1024, 2048}。
- Flow Matching损失 (L’FM):简化后的端点估计损失
- 训练策略:
- 优化器:ScaledAdam, 论文称其提供更快的收敛速度。
- Flow Matching阶段:Mel条件训练92k次迭代;音频令牌条件训练180k次迭代。
- GAN微调阶段:Mel条件训练110k次迭代(作为主要对比);音频令牌条件训练190k次迭代。
- 超参数:Mel频谱图在GAN微调时添加了
0.2 × rand() × N(0, 1)的高斯噪声,以增强对来自TTS扩散模型的不完美频谱图的鲁棒性。
- 关键超参数:
- 模型参数量:78.9M(多分辨率最终版)。
- 网络层:每个分支使用8层 ConvNeXt块。
- 嵌入维度:三个分支分别为 768, 512, 384。
- 条件编码器:4层,嵌入维度512。
- 各分支STFT配置:见附录表10。
- 训练硬件:使用NVIDIA H20 GPU。Mel条件训练使用2块;音频令牌条件的Flow Matching阶段使用8块, GAN微调阶段使用2块。
- 推理细节:
- 生成器有1步、2步、4步三种独立训练和部署的变体。
- Flow Matching阶段的多步采样使用公式(5)所示的修改后的ODE求解器。
- 评估时批量大小为16,音频片段长度为1秒。
- 正则化/稳定训练技巧:
- Flow Matching损失缩放因子
1/√(S(x1)+ε)被钳制在 [0.01, 100] 范围内以稳定训练。 - 使用BiasNorm替代LayerNorm,使用PReLU激活函数。
- Flow Matching损失缩放因子
📊 实验结果
论文在Mel频谱图和音频令牌两种条件下进行了广泛的对比和消融实验。
主要对比结果:Mel频谱图条件 (LibriTTS test set)
| 模型 | 参数量(M) | PESQ↑ | ViSQOL↑ | V/UV F1↑ | Periodicity↓ | FSD↓ | SMOS↑ | MOS↑ |
|---|---|---|---|---|---|---|---|---|
| BigVGAN-v2* | 112.4 | 4.379 | 4.971 | 0.978 | 0.055 | 0.014 | 4.65±0.11 | 4.59±0.10 |
| Vocos | 13.5 | 3.618 | 4.898 | 0.951 | 0.105 | 0.042 | 4.10±0.17 | 4.38±0.16 |
| RFWave (10步) | 18.1 | 4.220 | 4.772 | 0.957 | 0.098 | 0.412 | 4.24±0.16 | 4.29±0.13 |
| PeriodWave-Turbo (4步) | 70.2 | 4.434 | 4.965 | 0.958 | 0.096 | 0.020 | 4.20±0.17 | 4.38±0.17 |
| WaveFM (1步) | 19.5 | 3.540 | 4.894 | 0.943 | 0.124 | 0.098 | 3.72±0.18 | 3.76±0.18 |
| Flow2GAN, 1步 (ours) | 78.9 | 4.189 | 4.957 | 0.975 | 0.063 | 0.028 | 4.44±0.14 | 4.39±0.15 |
| Flow2GAN, 2步 (ours) | 78.9 | 4.440 | 4.979 | 0.983 | 0.044 | 0.023 | 4.53±0.13 | 4.56±0.11 |
| Flow2GAN, 4步 (ours) | 78.9 | 4.484 | 4.986 | 0.985 | 0.037 | 0.016 | 4.60±0.14 | 4.58±0.14 |
关键结论:Flow2GAN的1步模型在PESQ、ViSQOL上已优于Vocos、RFWave和WaveFM。其2步和4步模型在PESQ、ViSQOL、V/UV F1、Periodicity上全面超越所有对比方法,接近或部分超过在大规模数据上训练的BigVGAN-v2。
音频令牌条件对比结果(部分, 通用音频测试集) (以3.0 kbps带宽为例)
| 模型 | PESQ↑ | ViSQOL↑ | FSD↓ | SMOS↑ | MOS↑ |
|---|---|---|---|---|---|
| PeriodWave-Turbo (4步) | 2.160 | 4.058 | 1.018 | 3.04±0.17 | 3.16±0.23 |
| Flow2GAN, 1步 (ours) | 2.353 | 4.026 | 0.867 | 3.94±0.14 | 4.00±0.19 |
| Flow2GAN, 4步 (ours) | 2.550 | 4.091 | 0.804 | 4.03±0.16 | 4.08±0.22 |
关键结论:在音频令牌条件下,Flow2GAN在FSD和主观分数(SMOS, MOS)上优势明显,在客观分数PESQ和ViSQOL上也具有竞争力或更优。
消融实验关键结果(LibriTTS dev set)
改进Flow Matching的有效性:
方法 FM训练 (2步) PESQ GAN微调 (1步) PESQ GAN微调 (2步) PESQ 标准Flow Matching 2.351 3.730 4.257 预测x1,无损失缩放 2.806 4.173 4.332 预测x1, 有谱能量损失缩放 (最终) 3.469 4.303 4.471 结论:将目标重构为端点估计(预测x1)并加入谱能量损失缩放,在Flow Matching阶段和GAN微调阶段都带来了显著且一致的性能提升。 两阶段训练 vs. 纯GAN训练:
方法 训练迭代次数 训练时长(小时) PESQ↑ ViSQOL↑ 纯GAN训练 660k 156 3.919 4.888 Flow Matching (2步) + GAN微调 (1步, 110k次) 92k+110k = 202k 50+26=76 4.303 4.942 结论:Flow2GAN以更少的总训练时间和迭代次数,达到了比纯GAN训练好得多的效果,验证了两阶段范式的高效性。
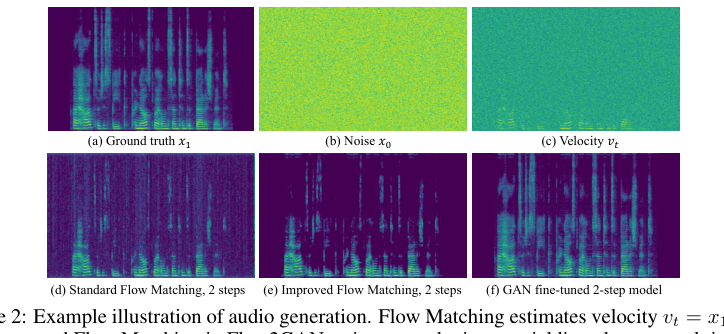
图2:生成样本定性对比。展示了地面真值(a)、噪声(b)、速度场(c)、标准FM 2步生成(d)、改进FM 2步生成(e)和GAN微调2步生成(f)的波形与频谱图。可见改进FM在静音区域更干净,GAN微调进一步填补了细节。
图4:不同模型在Mel频谱图条件下的PESQ与推理速度(xRT)对比。Flow2GAN(特别是1步和2步)在质量和速度上均表现优异。
图5:不同模型在Mel频谱图条件下的ViSQOL与参数量对比。Flow2GAN以中等参数量达到了最高的ViSQOL分数。
图6:不同模型在Mel频谱图条件下的CPU推理速度(xRT)对比。Flow2GAN(除1步略慢于Vocos外)在CPU上显著快于所有扩散模型,实现超实时推理。
⚖️ 评分理由
- 学术质量:6.0/7
- 创新性 (2.0/2.0):创新点明确且重要。将Flow Matching目标重构为端点估计并引入谱能量自适应损失,是对音频生成场景下Flow Matching技术的有效改进。两阶段框架和多分辨率网络的设计也体现了系统性的思考。
- 技术正确性与实验充分性 (2.5/3.0):论文提供了详尽的消融实验(表3,4,5,6),逐步验证了每个组件的有效性。对比实验覆盖了Mel频谱图和音频令牌两大场景,与多个SOTA基线(BigVGAN, Vocos, RFWave, PeriodWave-Turbo, WaveFM)进行了公平比较。实验设计合理,指标全面(PESQ, ViSQOL, FSD, MOS等)。
- 证据可信度 (1.5/2.0):结果可信度高。消融实验逻辑清晰,展示了从标准FM到最终Flow2GAN的逐步改进。定性结果(图2)直观支持了方法动机。论文提供了详细的实现细节(附录表10)和预训���模型,增强了可复现性。
- 选题价值:1.5/2
- 前沿性与潜在影响 (1.0/1.0):解决音频生成中“质量-效率”权衡的核心痛点,是当前研究的前沿方向。其方法思想(稳定预训练+对抗微调)对其他生成任务也有借鉴意义。
- 应用空间与读者相关性 (0.5/1.0):音频生成(尤其是神经声码器)是语音合成、音乐生成等应用的关键环节,具有明确的实用价值。对于从事语音处理、音频合成的研究和工程人员有较高相关性。扣0.5分是因为论文主要聚焦于语音波形生成,对非语音音频(如环境声、复杂音乐)的潜力和优势讨论有限。
- 开源与复现加成:+0.5/1
- 论文代码、预训练模型、以及详细的复现说明(模型配置、数据准备)均已公开(见附录及论文末尾链接)。这大大降低了复现门槛,对于社区验证和后续工作至关重要。开源力度在同类工作中属于优秀水平。