📄 FlexiVoice: Enabling Flexible Style Control in Zero-Shot TTS with Natural Language Instructions
#语音合成 #强化学习 #零样本 #多语言
🔥 8.0/10 | 前25% | #语音合成 | #强化学习 | #零样本 #多语言
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Dekun Chen (The Chinese University of Hong Kong, Shenzhen; Shenzhen Loop Area Institute)
- 通讯作者:未明确说明(论文中未明确指出通讯作者)
- 作者列表:Dekun Chen (香港中文大学(深圳)/深圳湾实验室), Xueyao Zhang (香港中文大学(深圳)), Yuancheng Wang (香港中文大学(深圳)), Kenan Dai (Huawei Technologies Co., Ltd.), Li Ma (Huawei Technologies Co., Ltd.), Zhizheng Wu (香港中文大学(深圳)/澳门城市大学/Amphion Technology Co., Ltd.)
💡 毒舌点评
这篇论文的核心亮点在于其系统性地将“风格、音色、内容”的解耦问题,转化为一个可分阶段优化的强化学习课程(PPT),技术路径设计精巧且实验证据扎实。不过,其最终效果高度依赖奖励模型的质量,而论文中使用的7B开源奖励模型与闭源前沿模型仍存在代差,这在一定程度上限制了其在最复杂指令上的表现上限,也为未来工作留下了明确的改进方向。
🔗 开源详情
- 代码:论文中提到将发布全部训练和推理代码。提供在线演示网站:https://flexi-voice.github.io/。但未提供具体代码仓库链接(如GitHub)。
- 模型权重:论文中承诺将发布模型检查点,但未提及具体权重文件或下载地址。
- 数据集:承诺发布FlexiVoice-Instruct数据集,未说明具体获取方式(如Hugging Face)。
- Demo:提供了在线演示网站链接。
- 复现材料:附录A.10详细列出了训练硬件(8×A800)、各阶段训练时长、学习率、轮数、超参数(β, G)等关键复现信息。
- 引用的开源项目:模型核心使用Phi-3.5-mini-instruct,语音分词使用DualCodec,声码器使用Vocos,奖励模型使用Emotion2vec-Large、CAM++和Kimi-Audio-7B-Instruct。
📌 核心摘要
- 要解决什么问题:在零样本文本转语音(TTS)中,当同时使用自然语言指令控制风格(如情绪)和参考语音控制音色时,模型容易受到文本内容或参考语音中内含风格的干扰,无法准确遵循目标指令,即“风格-音色-内容冲突”。
- 方法核心是什么:提出FlexiVoice系统,以大语言模型为核心。核心创新是“渐进式后训练(PPT)”框架,包含三个递进阶段:1)使用多模态DPO进行初步对齐;2)使用多目标GRPO在冲突数据上强制解耦风格、音色与内容;3)使用基于音频语言模型奖励的GRPO提升对复杂、开放式指令的遵循能力。
- 与已有方法相比新在哪里:不同于以往简单条件化或单一阶段对齐,PPT通过课程学习策略,显式地、分阶段地解决模态冲突,实现了更鲁棒的解耦。同时,构建了大规模高质量指令-语音数据集FlexiVoice-Instruct。
- 主要实验结果:在解耦任务上,FlexiVoice在TR-hard(参考语音与指令冲突)任务上的指令准确率(ACC-I)在英语和中文上分别达到78.2%和75.8%,远超基线模型(如VoxInstruct的23.9%和18.7%)。在复杂指令基准InstructTTSEval上,FlexiVoice的英文平均准确率达79.3%,接近闭源系统Gemini-pro的80.3%,并超越所有开源基线。消融实验表明,PPT的渐进式顺序(S1→S2→S3)优于其他顺序或联合训练。
- 实际意义是什么:为需要高度定制化语音生成的应用(如有声书、游戏配音、虚拟助手)提供了灵活、可控的TTS解决方案,能够仅通过自然语言描述和任意音色参考,生成符合要求的语音。
- 主要局限性是什么:性能上限受限于开源奖励模型(Kimi-Audio-7B)的能力,其判断准确性与最强闭源模型仍有差距。此外,为遵循风格指令对语音进行的声学改造,不可避免地会对说话人音色相似度造成轻微影响。
🏗️ 模型架构
FlexiVoice的整体架构(图3)采用两阶段设计:自回归LLM 和 流匹配解码器。
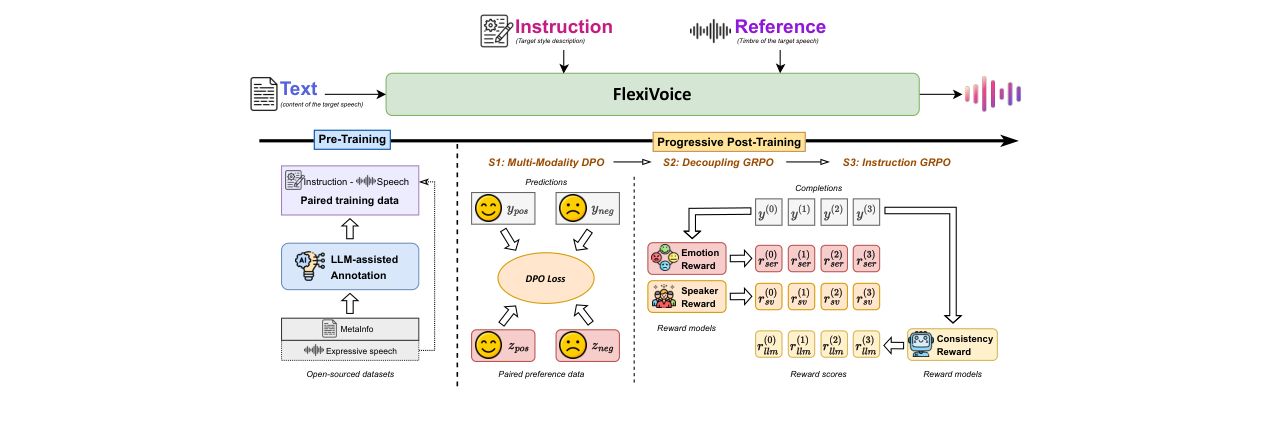
完整输入输出流程:
- 输入:自然语言文本、可选的风格指令(如“请用开心的语气朗读”)、可选的参考语音(用于提供音色)。
- 预处理:参考语音通过DualCodec语音分词器转换为离散语义码元(token)。文本和指令按照LLM的输入模板进行格式化,参考语音的文本转录被拼接在目标文本之前。
- LLM核心:格式化后的文本/指令序列与参考语音的离散码元一起,作为输入送入LLM。LLM(采用Phi-3.5-mini-instruct架构)以自回归方式生成目标语音的离散码元序列。
- 流匹配解码:生成的离散码元通过一个流匹配模块(在Emilia数据集上预训练),转换为梅尔频谱图。此过程以参考语音的码元为条件,以保持音色一致性。
- 波形合成:梅尔频谱图通过Vocos声码器转换为最终的波形音频。
主要组件与功能:
- LLM核心:负责理解文本、指令和参考语音的上下文,并生成控制语音合成的离散表示。它是系统的控制中枢,继承了预训练LLM强大的指令遵循能力。
- DualCodec语音分词器:将连续语音波形转换为离散码元,实现了语音信号在离散空间的表示,便于LLM处理。
- 流匹配模块:一个条件生成模型,负责将离散码元高效、高质量地解码为连续的声学特征(梅尔频谱图)。使用参考语音码元作为条件,是保持音色一致性的关键。
- Vocos声码器:将梅尔频谱图转换为人耳可听的波形。
关键设计选择与动机:
- 基于LLM的架构:利用LLM强大的上下文理解、指令跟随和泛化能力,这是实现灵活自然语言控制的基础。
- 双阶段生成(离散码元->梅尔频谱->波形):分离了“高级控制”(LLM处理)和“高质量声学生成”(流匹配+声码器)两个任务,让每个组件专注于其最擅长的部分。
- 渐进式后训练(PPT):这是模型训练的核心策略,而非架构组件,但至关重要。它通过分阶段的强化学习,逐步解决多模态控制中的冲突问题。
💡 核心创新点
- 渐进式后训练(PPT)框架:这是最主要的创新。它借鉴课程学习思想,设计了S1(多模态DPO对齐)、S2(多目标GRPO解耦)、S3(指令GRPO泛化)三个递进阶段。不同于以往的一阶段对齐,PPT系统性地、从易到难地解决了风格、音色、内容三者纠缠的核心矛盾,实现了更鲁棒的解耦与控制。
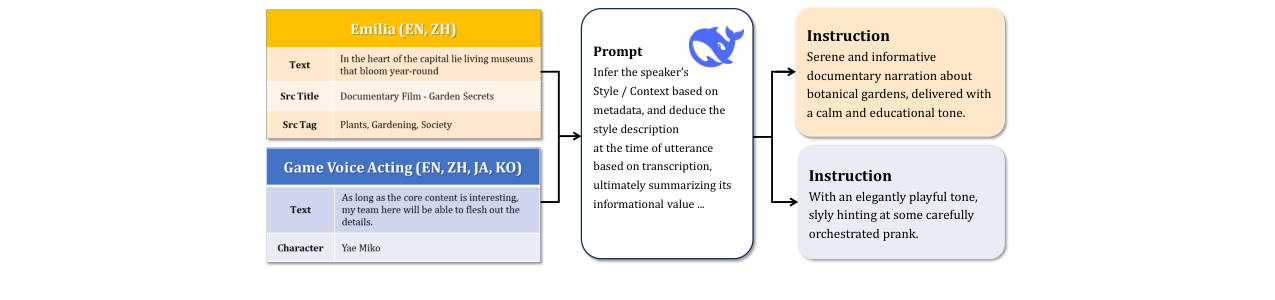
- 大规模高质量指令-语音数据集FlexiVoice-Instruct:为支撑预训练,团队构建了包含4316小时语音的数据集。创新点在于利用LLM(Deepseek-V3)基于语音的元数据(如视频标题、标签)和转录文本,自动生成自然、多样化的风格指令,覆盖了丰富表达场景,为模型奠定了强大的指令理解基础。
- 多目标强化学习解耦策略:在PPT的S2阶段,通过精心构造“指令与参考语音风格冲突”的训练场景,并设计联合奖励(情绪分类奖励rser用于确保风格遵循,说话人验证奖励rsv用于确保音色保持),使用多目标GRPO迫使模型学习分离这些冲突因素,而非简单地跟随某一模态。
🔬 细节详述
- 训练数据:
- 预训练数据:FlexiVoice-Instruct(4316小时,自建)、Emilia(大规模多语言数据集)、NVSpeech(带副语言标签)、ParaSpeechCaps、以及多个情感/辩论/方言数据集(见附录表6)。总计覆盖广泛风格。
- PPT训练数据:
- S1(DPO):使用ESD等情感语音数据集,构造(指令,文本,中性参考语音,目标情感语音,冲突情感语音)偏好对。
- S2(解耦GRPO):使用NCSSD对话数据集构造文本,并随机组合情感/中性参考语音,制造冲突场景。
- S3(指令GRPO):使用Deepseek-V3生成14000条复杂指令-文本对,并混入部分S2数据以防止遗忘。
- 损失函数:
- 预训练:标准自回归语言模型损失(交叉熵)。
- S1 (DPO):使用DPO损失函数(论文公式),直接在偏好数据上优化策略模型与参考模型的似然比。
- S2/S3 (GRPO):使用组相对策略优化。优势函数计算基于每个任务组的奖励归一化。S2的优势函数(Ai)联合归一化了情绪奖励和说话人验证奖励。S3使用单一的LLM判断奖励(rllm)。
- 训练策略:
- 优化器:未明确说明。
- 学习率:S1和S2阶段为1×10^-5。
- 训练轮数:S1: 3 epochs; S2: 2 epochs; S3: 2 epochs。
- KL惩罚系数β:在DPO和GRPO中均为0.1。
- GRPO组大小:S2阶段G=8,S3阶段G=6。
- 关键超参数:
- 模型大小:基于Phi-3.5-mini-instruct,约38亿参数。
- 码本大小:LLM词汇表扩展为16384,与DualCodec的码本大小一致。
- 训练硬件:8× NVIDIA A800 (80GB) GPU。
- 训练时长:总后训练流程约3.5天(S1
2小时,S236小时,S3~42小时)。 - 推理细节:未明确说明解码策略(如温度、beam search)的具体参数。
- 正则化技巧:在S3阶段混入部分S2任务数据,是一种任务混合的正则化,旨在缓解灾难性遗忘。
📊 实验结果
论文在多模态控制解耦和复杂指令遵循两个维度进行了全面评估。
- 多模态控制与解耦评估(表2) 在自建的英中双语评估集上,任务分为仅文本输入(TO)和文本+参考语音输入(TR),并各分简单(Easy)和困难(Hard)两档。
| 模型 | TO-Easy | TO-Hard | TR-Easy | TR-Hard |
|---|---|---|---|---|
| ACC-I↑ | ACC-I↑ ACC-T↓ | ACC-I↑ E-SIM↑ SV↑ | ACC-I↑ ACC-R↓ E-SIM↑ SV↑ | |
| 英语 | ||||
| Ground-truth | 93.4 | - | 93.4 1.00 | 93.4 0.6 1.00 - |
| VoxInstruct | 70.6 | 17.8 41.2 | 58.5 0.81 89.0 | 23.9 0.80 90.6 |
| FlexiVoice-Base | 72.4 | 39.4 30.6 | 58.8 0.81 99.2 | 32.2 0.78 99.4 |
| FlexiVoice | 97.4 | 89.4 6.6 | 89.4 0.90 91.0 | 78.2 10.6 0.87 95.8 |
| 中文 | ||||
| Ground-truth | 61.6 | - | 61.6 1.00 | 61.6 4.4 1.00 - |
| VoxInstruct | 48.6 | 29.0 21.2 | 19.4 0.75 46.8 | 18.7 0.73 59.8 |
| FlexiVoice-Base | 78.4 | 66.8 14.2 | 25.2 0.78 99.6 | 22.4 0.74 99.2 |
| FlexiVoice | 99.8 | 98.4 0.8 | 81.8 0.85 98.8 | 75.8 13.2 0.80 98.4 |
关键结论:FlexiVoice在指令准确率(ACC-I)上全面大幅超越基线。特别是在最困难的TR-hard任务(参考语音情感与指令冲突)上,英语ACC-I从基线的23.9%提升至78.2%,同时保持了高说话人验证(SV)分数(95.8%),证明了其强大的风格解耦与音色保持能力。
- 可懂度与主观评价(表3)
模型 TO-Easy (EN) TR-Easy (EN) TR-Hard (EN) TO-Easy (ZH) TR-Easy (ZH) TR-Hard (ZH) WER↓ Q-MOS↑ CMOS↑ WER↓ Q-MOS↑ CMOS↑ WER↓ Ground-truth 4.50 3.16 0.00 4.50 3.50 0.00 FlexiVoice-Base 5.01 3.72 -0.12 5.31 3.90 -1.25 FlexiVoice 5.99 4.08 +0.91 5.23 3.62 +0.89
关键结论:FlexiVoice的WER/CER略有上升(符合情感语音ASR更难的观察),但其感知质量(Q-MOS)普遍高于基线,且主观比较(CMOS)得分为正,表明其生成的语音在自然度和情感表达上更受评判者青睐。
- 复杂指令遵循评估(InstructTTSEval,表4)
模型 InstructTTSEval-EN InstructTTSEval-ZH APS DSD RP Gemini-flash 92.3 93.8 Gemini-pro 87.6 86.0 MiMo-Audio-7B-Instruct 80.6 77.6 VoxInstruct 54.9 57.0 FlexiVoice-Base 63.6 75.0 FlexiVoice 81.2 85.2
关键结论:FlexiVoice在复杂指令任务上超越所有开源基线,其英文平均准确率(79.3%)已接近闭源Gemini-pro(80.3%),中文准确率(70.8%)甚至略超MiMo-Audio-7B-Instruct(70.5%)。
- 消融实验(表5 & 图9) 消融实验验证了PPT各阶段顺序和策略的有效性。
不同训练策略在解耦任务和复杂指令任务上的性能对比。
关键结论:
- 顺序重要性:直接以S3(复杂指令)开始或顺序混乱(如S3→S1→S2)会导致性能下降,证明了S1作为“冷启动”的必要性。
- 渐进优于联合:将S2和S3联合训练(+S1→S2+S3 Joint)的效果(Avg 75.5)劣于逐步训练(Avg 79.3),表明存在任务冲突。
- 逐步提升:从Base到+S1(Avg 69.0),再到+S1→S2(Avg 71.7),最后到+S1→S2→S3(Avg 79.3),性能稳步提升,证明了PPT课程的有效性。
- 奖励信号选择(附录图10)
在解耦GRPO阶段,使用说话人验证(二值)作为奖励信号比使用说话人相似度(连续值)能带来更稳定和显著的性能提升。
⚖️ 评分理由
- 学术质量 (6.0/7):创新性(PPT框架)明确且有效,技术方案(LLM + RL)选择得当,实验设计全面、结果对比有力,消融研究充分。主要扣分点在于最终效果部分依赖于开源奖励模型的能力,其与最先进闭源模型的差距可能构成了性能上限。此外,论文未提供与最新零样本TTS模型(如VALL-E、CosyVoice 2的更强版本)在无指令风格控制场景下的基线对比。
- 选题价值 (1.5/2):研究问题是TTS领域当前的核心挑战之一,具有高度的前沿性和明确的应用价值。解决方案具有普适性,对相关领域的研究者(音频大模型、可控生成)均有参考意义。但“使用RL对齐大模型来解决控制问题”本身并非全新范式。
- 开源与复现加成 (0.5/1):论文明确承诺开源数据集、模型、代码和在线演示,附录提供了详尽的训练细节,复现指引非常清晰。由于是会议论文,代码权重可能尚未正式上线,因此给予部分加分。