📄 Entropy-Monitored Kernelized Token Distillation for Audio-Visual Compression
#音视频事件检测 #知识蒸馏 #多模态模型 #音频分类 #模型压缩
🔥 8.5/10 | 前25% | #音视频事件检测 | #知识蒸馏 | #多模态模型 #音频分类
学术质量 6.2/7 | 选题价值 1.6/2 | 复现加成 0.5 | 置信度 中
👥 作者与机构
- 第一作者:Hyoungseob Park (Yale University, Amazon AGI 实习期间完成)
- 通讯作者:未明确说明(论文未标注通讯作者信息)
- 作者列表:
- Hyoungseob Park (Yale University)
- Lipeng Ke (Amazon AGI)
- Pritish Mohapatra (Amazon AGI)
- Huajun Ying (Amazon AGI)
- Sankar Venkataraman (Amazon AGI)
- Alex Wong (Yale University)
💡 毒舌点评
亮点:将蒸馏对象从“特征本身”或“输出概率”巧妙地转换为“特征间的成对关系矩阵”(核化令牌),从而绕开了师生模型维度必须匹配的硬约束,这个思路非常实用且有效。短板:尽管实验全面,但核心方法(计算Gram矩阵 + 熵加权)更像是经典技术(核方法、信息熵)在现代Transformer蒸馏场景下的工程化应用组合,理论创新深度有限,更像是一个优秀、扎实的“系统解决方案”。
🔗 开源详情
- 代码:论文中明确表示“we will release the code and the pretrained weights”,但未提供具体仓库链接(如GitHub)。论文中未提及具体代码链接。
- 模型权重:承诺发布预训练权重,但未提供下载地址。
- 数据集:使用公开数据集VGGSound和AVS-Bench,并引用了获取方式。
- Demo:未提及。
- 复现材料:提供了极其详细的附录(Appendix E),包括:
- 训练数据划分(VGGSound: 182,536训练,15,331测试)。
- 模型架构规格(如教师/学生的维度、深度、MLP比率)。
- 全部超参数(学习率、损失权重、批量大小等)。
- 训练硬件(单卡A100 GPU,训练时长)。
- 评估指标定义。
- 论文中引用的开源项目:引用了CAVMAE(Gong et al., 2022b)、UFE-AVS(Liu et al., 2024a)等作为教师模型基础,以及VGGSound和AVS-Bench数据集。
- 总体开源状态:论文承诺开源并提供了高水平的复现文档,是积极的信号,但当前版本中缺少可直接访问的代码和权重链接。
📌 核心摘要
- 问题:如何将大型、复杂的音频-视觉教师模型高效压缩成小型学生模型,同时在资源受限的边缘设备上保持高性能,尤其需要解决师生模型架构/维度不同以及不同模态(音频、视觉)信息重要性动态变化带来的挑战。
- 方法核心:提出熵监控的核化令牌蒸馏(EM-KTD)。首先,核化令牌蒸馏(KTD):不直接蒸馏特征向量,而是将每个模态的特征令牌化后,计算其成对相似度矩阵(Gram矩阵,使用线性、多项式或RBF核),然后最小化师生模型该矩阵的差异。其次,熵监控(EM):为每个模态添加一个任务头,通过测量其输出熵来量化该模态当前输入的信息量(不确定性),并以此为权重自适应地调节该模态的蒸馏损失。
- 与已知方法相比新在:相较于传统的输出空间蒸馏(KD)或需要维度匹配的潜在特征蒸馏,KTD通过蒸馏关系矩阵实现了架构无关的潜在空间蒸馏。相较于同样基于关系的MTST方法,KTD保留了完整的、未经掩码和Softmax归一化的原始相似度信息。EM则提供了动态、自适应的蒸馏强度调节,避免了对不信息模态的过度监督。
- 主要实验结果:在VGGSound音频-视觉事件分类上,EM-KTD(+KD)使用仅6%的教师参数(学生10M vs 教师164M),保留了96.9%的准确率和97.5%的mAP。在AVS-Bench音频-视觉分割的S4(单源)和MS3(多源)任务上,EM-KTD学生模型以仅4%的教师视觉编码器参数,达到了97.1%的教师性能(S4 MJ指标)。所有消融实验均证实了KTD、核函数选择以及熵监控的有效性。
- 实际意义:提供了一种高效、通用的多模态模型压缩方案,特别适用于计算资源有限的边缘AI设备(如智能手机、物联网设备),使得复杂的音视频理解模型得以实际部署。
- 主要局限性:KTD的计算复杂度随令牌数平方增长(O(N^2)),论文通过实例级计算和滑动窗口近似进行缓解,但仍是潜在瓶颈。熵监控的线性探针性能可能影响加权质量,尽管实验证明其鲁棒性。方法的有效性高度依赖于教师模型本身能为每个模态提供有意义的特征,且在回归等任务上需要重新设计熵监控方式。
🏗️ 模型架构
EM-KTD框架包含教师模型和学生模型,两者均为多模态Transformer架构(如视觉编码器、音频编码器、融合模块)。蒸馏过程如下:
- 输入与编码:将同一音频-视觉样本分别输入教师和学生的视觉编码器、音频编码器,得到各模态的特征令牌序列(如视觉特征
f_T_v(I),f_S_v(I))。 - 关系计算(KTD):对每个模态(视觉、音频、融合后),计算特征令牌间的成对相似度矩阵(Gram矩阵)。例如,对于视觉模态,计算
φ_T_v[i,j] = z_i^T * z_j(线性核),其中z是归一化后的特征令牌向量。学生模型侧同理计算φ_S_v。 - 熵监控(EM):为教师模型的每个模态分支添加一个轻量级任务头(如线性层),计算该分支预测的概率分布熵
H_m。熵越低,表示该模态在该样本上信息越确定/重要。 - 加权蒸馏损失:计算每个模态Gram矩阵的Huber损失
L_Huber(φ_T_m, φ_S_m),并用熵的负指数w_m = exp(-λ H_m)作为权重。最终损失为加权和L = Σ w_m L_Huber_m。 - 训练:学生模型同时在原始任务损失(如交叉熵)和EM-KTD蒸馏损失下训练。教师模型参数冻结。
架构图:论文图1(Figure 1)和图2(Figure 2)直观展示了传统潜在蒸馏与KTD的区别,以及EM-KTD的完整流程。
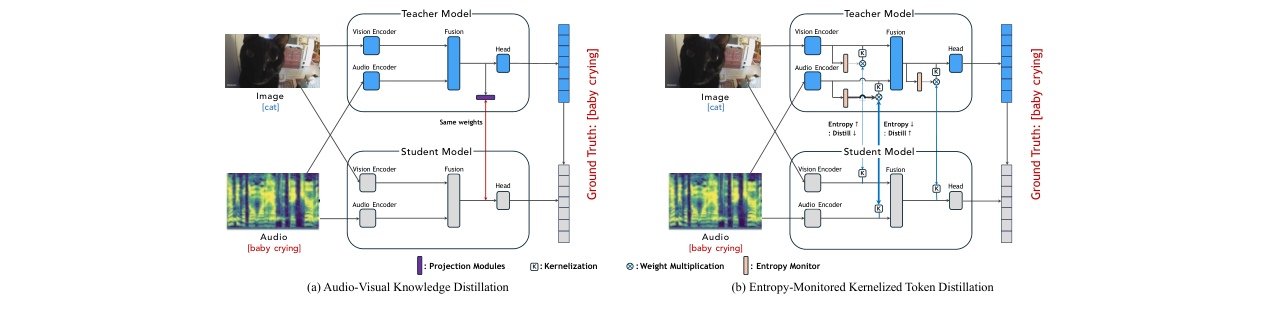
图1对比了传统潜在蒸馏(a)与本文提出的EM-KTD(b)。(a)展示传统方法需要投影模块来匹配维度。(b)展示本文方法通过核化计算关系矩阵(K),并通过熵监控自适应调节每个模态的蒸馏权重(虚线表示弱化,实线表示增强)。
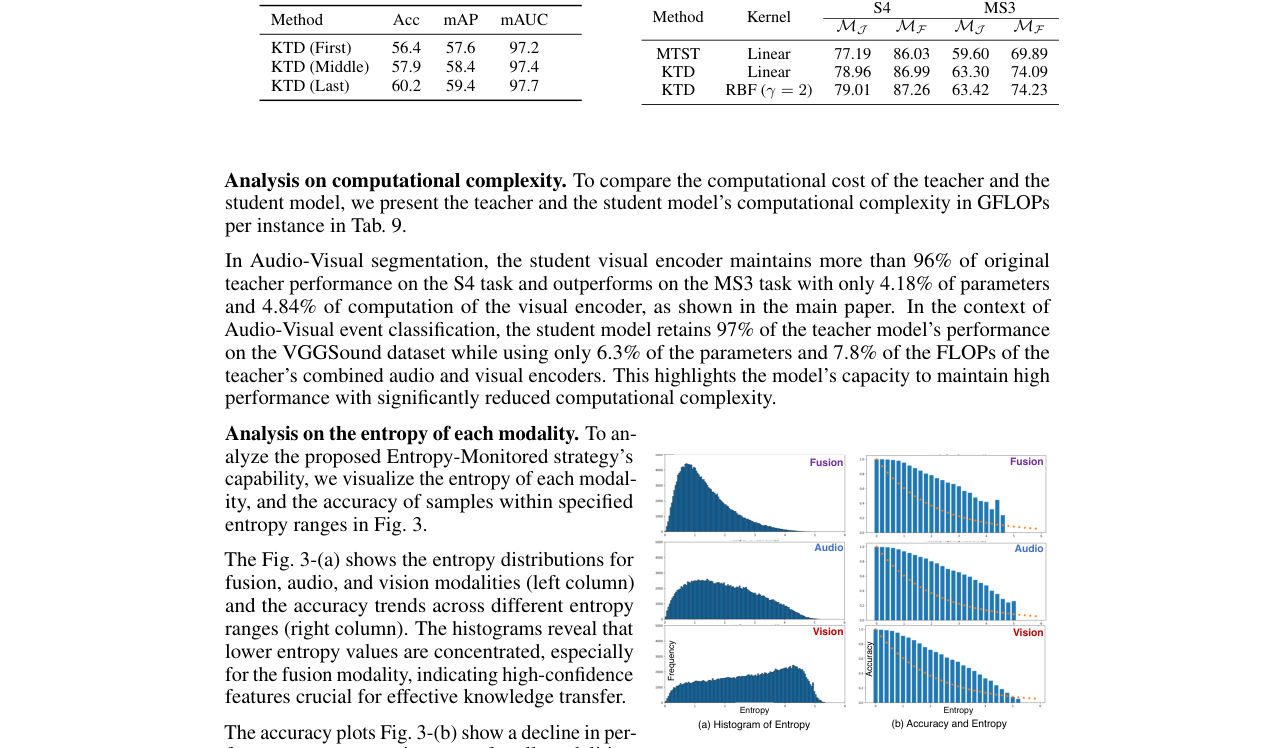
图2详细展示了EM-KTD的流程。左侧为学生模型,右侧为教师模型。输入图像和音频后,分别通过视觉和音频编码器。核心步骤包括:1)对每个模态的特征令牌计算核化关系矩阵(Kernelization);2)使用熵监控模块(Entropy Monitor)计算每个模态的熵(Hv, Ha, HF);3)熵值通过负指数转换为蒸馏权重(透明箭头),用于加权各模态的KTD损失。
💡 核心创新点
核化令牌蒸馏(KTD):
- 是什么:一种新的蒸馏对象,即蒸馏特征令牌间的成对关系矩阵(Gram矩阵),而非特征向量或输出概率。
- 之前方法局限:输出蒸馏(KD)损失信息量大;潜在特征蒸馏要求师生维度匹配;使用投影模块会引入额外参数和不确定效果;MTST方法使用Softmax和随机掩码会丢失原始关系信息。
- 如何起作用:通过核函数(线性、多项式、RBF)将特征映射到关系空间,使维度不同的师生模型能在同一度量空间(Gram矩阵)上进行比较和学习。
- 收益:实现了架构无关的潜在空间蒸馏,保留了完整的特征间关系信息,实验证明其性能显著优于MTST等基线。
熵监控自适应蒸馏加权(EM):
- 是什么:一种动态调节蒸馏强度的机制,根据每个模态特征的熵(不确定性)为其蒸馏损失分配权重。
- 之前方法局限:传统蒸馏对所有模态、所有样本施加相同强度的监督,当某个模态在当前样本中信息不充分或有噪声时,会引入干扰信号,损害学生模型性能。
- 如何起作用:为教师每个模态分支添加线性探针头,预测任务分布并计算熵。熵低意味着该模态信息确定、重要,获得更高蒸馏权重;熵高则权重低。
- 收益:使蒸馏过程更智能,聚焦于教师提供的可靠、高价值信息,提升了最终性能,尤其在处理模态不平衡样本时。消融实验证明其对KTD和传统KD均有提升。
架构无关的统一框架:
- 是什么:KTD与EM结合的框架,不假设师生模型具有相同架构或维度。
- 之前方法局限:大多数高性能的潜在蒸馏方法受限于师生同构。
- 如何起作用:KTD处理维度差异,EM处理模态重要性差异,两者解耦。
- 收益:可灵活应用于各种异构的师生模型对,具有广泛适用性。
🔬 细节详述
- 训练数据:
- VGGSound:约18.2万训练样本,1.5万测试样本,10秒视频,200个类别。
- AVS-Bench:包含S4(单源)和MS3(多源)两个子集,用于音频-视觉分割任务,提供像素级标注。
- 预处理:遵循教师模型(CAVMAE, UFE-AVS)的原始预处理流程,对图像和音频进行分块(tokenize)。
- 数据增强:沿用教师模型的增强策略。
- 损失函数:
- 任务损失:分类用交叉熵损失,分割用二元交叉熵损失。
- 蒸馏损失:KTD损失(公式3),为各模态Gram矩阵Huber损失之和。
- EM-KTD损失(公式7):在KTD损失基础上,乘以熵权重
w_m = exp(-λ * H_m)。论文中λ为超参数。
- 训练策略:
- 学习率:VGGSound上,从头训练为2e-4,微调为1e-4,KD方法为1e-4到5e-4不等。AVS-Bench上为2.5e-5。
- 优化器:未明确说明,但提到了使用余弦退火调度(cosine annealing schedule)训练熵监控头
g_m。 - 蒸馏损失权重:与任务损失的相对权重,不同方法设置不同,如KTD为333,EM-KTD为666。
- 熵监控头训练:在蒸馏前,先冻结教师模型,用线性探针任务训练
g_m直至收敛。
- 关键超参数:
- 核函数:主要使用RBF核(γ=0.5),也测试了线性核和多项式核。
- 模型大小:教师(如CAVMAE-ViT-Base)约164M参数,学生(ViT-Tiny)约10M参数,压缩比约94%。
- 学生模型深度:主要测试了23层(11模态+1融合+11模态)的ViT-Tiny,也测试了更浅的13层(6+1+6)模型。
- 训练硬件:论文提到在NVIDIA A100 GPU上训练KTD约需6.75小时(单卡)。也提及在NVIDIA A10G 24GB GPU上测试推理速度。
- 推理细节:未说明特殊解码策略,模型为前向传播。
- 正则化技巧:熵监控本身可视为一种自适应正则化,防止学生学习到教师中不稳定的特征。训练中使用了数据增强。
📊 实验结果
主要结果: 表1:VGGSound音频-视觉事件分类结果对比
| 方法 | 教师模型 (参数) | 学生骨干网络 (参数) | Acc | mAP | mAUC |
|---|---|---|---|---|---|
| CAVMAE (教师) | CAVMAE-ViT-Base (164M) | - | 63.9 | 65.0 | 97.9 |
| KD | 同上 | ViT-Tiny (10M) | 56.1 | 57.3 | 97.1 |
| AT + KD | 同上 | ViT-Tiny (10M) | 56.6 | 56.9 | 96.8 |
| SPKD + KD | 同上 | ViT-Tiny (10M) | 55.6 | 56.1 | 96.6 |
| MTST + KD | 同上 | ViT-Tiny (10M) | 57.6 | 58.5 | 97.0 |
| KTD + KD (Ours) | 同上 | ViT-Tiny (10M) | 61.4 | 62.3 | 97.6 |
| EM-KTD + KD (Ours) | 同上 | ViT-Tiny (10M) | 62.0 | 63.4 | 97.9 |
结论:EM-KTD以6%的教师参数,达到了教师96.9%的准确率和97.5%的mAP,显著优于所��基线。
表2:AVS-Bench音频-视觉分割结果对比
| 方法 | 教师视觉骨干 | AVS-Bench-S4 (MJ/MF) | AVS-Bench-MS3 (MJ/MF) |
|---|---|---|---|
| UFE-AVS (教师) | PVTv2-b5 (81.4M) | 83.15 / 90.4 | 61.95 / 70.9 |
| MTST | PVTv2-b0 (3.4M) | 77.19 / 86.03 | 59.60 / 69.89 |
| KTD (Ours) | PVTv2-b0 (3.4M) | 79.01 / 87.26 | 63.42 / 74.23 |
| EM-KTD (Ours) | PVTv2-b0 (3.4M) | 79.81 / 87.86 | 64.43 / 74.73 |
结论:EM-KTD学生模型以仅4.18%的教师视觉编码器参数,在多源分割(MS3)上甚至超越了教师模型的性能(MJ 64.43 > 61.95)。
关键消融实验: 表3:核函数消融(VGGSound)
| 方法 | 核函数 | Acc | mAP | mAUC |
|---|---|---|---|---|
| MTST+KD | Linear | 57.6 | 58.5 | 97.0 |
| KTD | Linear | 60.2 | 59.4 | 97.7 |
| KTD | RBF (γ=0.5) | 61.4 | 62.3 | 97.6 |
| 结论:即使使用最简单的线性核,KTD也显著优于MTST。更复杂的RBF核能带来进一步提升。 |
图3(对应文中Table 3)展示了不同核函数(线性、多项式、RBF)对KTD性能的影响。使用RBF核(γ=0.5)取得了最佳的Acc和mAP。
表4:输入分辨率(令牌数)消融(VGGSound)
| 输入分辨率 | 方法 | Acc | mAP |
|---|---|---|---|
| 224×224 | EM-KTD | 62.0 | 63.9 |
| 112×112 | EM-KTD | 60.0 | 59.9 |
| 结论:降低输入分辨率(减少令牌数)后,EM-KTD性能有所下降但仍远强于基线,证明其鲁棒性。 |
熵分析图:论文图3(Figure 3)展示了熵分布及其与准确率的关系。
图3(对应文中Figure 3)显示了不同模态(融合、音频、视觉)的熵分布直方图(a)和不同熵值区间的样本准确率(b)。图(b)明确显示,随着熵增加(不确定性增加),所有模态的分类准确率均下降,证实了熵监控作为信息量指标的合理性。融合模态的低熵部分与高准确率强相关,是蒸馏的关键。
⚖️ 评分理由
- 学术质量:6.2/7。论文创新性地提出了KTD和EM两个模块,并进行了系统整合,解决了异构蒸馏和动态模态加权问题。技术实现正确,实验设计全面,覆盖了分类和分割任务,并在多个基线和消融实验中验证了有效性。扣分点在于核心思想(基于关系矩阵和熵的加权)并非全新,更多是现有技术的创造性应用。
- 选题价值:1.6/2。音频-视觉模型压缩是AIoT时代的迫切需求,论文直面这一挑战,并给出了高效的解决方案,具有明确的应用前景和产业化价值。其方法对音频-视觉社区和通用多模态蒸馏研究均有参考意义。
- 开源与复现加成:0.5/1。论文明确承诺开源,并在附录中提供了堪称详尽的复现指南(数据集划分、模型配置、所有超参数、训练时间),这极大地增加了研究的可信度和可复现性。未给出即时可访问的代码仓库链接,但复现准备已十分充分。