📄 End-to-end Listen, Look, Speak and Act
#语音对话系统 #端到端 #多模态模型 #大语言模型 #流式处理
🔥 8.5/10 | 前25% | #语音对话系统 | #端到端 | #多模态模型 #大语言模型
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.8 | 置信度 高
👥 作者与机构
- 第一作者:Siyin Wang (清华大学), Wenyi Yu (清华大学) [论文中注明两人贡献相等]
- 通讯作者:Chao Zhang (清华大学)
- 作者列表:Siyin Wang (清华大学), Wenyi Yu (清华大学), Xianzhao Chen (字节跳动), Xiaohai Tian (字节跳动), Jun Zhang (字节跳动), Lu Lu (字节跳动), Yuxuan Wang (字节跳动), Chao Zhang (清华大学)
💡 毒舌点评
这篇论文的亮点在于其清晰的架构设计(SA-MoE)和全面的任务验证,成功地将“说”和“做”这两个通常分离的能力整合到了一个全双工框架中,向类人交互迈出了扎实的一步。但短板也同样明显:目前所有验证都停留在模拟环境(LIBERO, CALVIN),缺乏真实世界复杂场景的考验,且“同时说话和操作”时性能出现可感知的下降,暴露出当前模型在处理真正高强度并发多任务时仍显吃力。
🔗 开源详情
- 代码:论文明确承诺将在GitHub (https://github.com/bytedance/SALMONN) 上开源所有代码。
- 模型权重:论文明确承诺将开源模型检查点(checkpoints)。
- 数据集:论文明确承诺将开源数据,并在附录中详细列出了训练所用的所有公开数据集。
- Demo:论文中未提及在线演示。
- 复现材料:提供了极其充分的复现材料,包括:详细的模型架构图与规格(Section 3, Appendix A),三阶段训练策略与具体超参数(Section 3.3, Appendix B),完整的训练数据集列表与处理方式(Appendix B),评估基准、指标和详细结果(Section 4, Appendix C),以及所有高级任务的具体设计、示例和Prompt模板(Appendix D, E)。
- 论文中引用的开源项目:LLaMA-3.1-8B-Instruct, Emu3(及其VisionTokenizer), UniVLA, CosyVoice2-0.5B, Mamba, FAST action tokenizer, Whisper(用于ASR过滤和评估), Gemini-2.5-Pro(用于数据生成和评估)。
📌 核心摘要
本文旨在解决当前AI模型在类人多模态交互方面的根本缺陷:要么是只能“听、看、说”但不能“做”的对话模型,要么是只能根据文本指令“做”但不能自然语音交互的VLA模型。核心方法是提出了ELLSA模型,其核心是SA-MoE(自注意力混合专家)架构,通过将处理语音/文本的“语音专家”和处理视觉/动作的“动作专家”通过统一的自注意力机制连接起来,实现了在单一架构中同时进行多模态感知和并发生成。与现有方法相比,ELLSA是首个支持全双工、流式、多输入多输出(MIMO)的端到端模型,能够实现诸如“边说边做”、基于上下文的视觉问答、拒绝错误指令和动作被打断等前所未有的交互行为。实验表明,ELLSA在语音交互(如TriviaQA S2T准确率45.2%)和机器人操作(LIBERO平均成功率89.4%)等基础任务上匹配或超越了专用基线模型,并在高级交互任务上取得了高成功率(例如,在执行动作时处理中断指令的成功率达94.3%-100%)。该工作的实际意义在于验证了统一全双工多模态交互模型的可行性,为构建更自然、通用的交互式智能体提供了新范式。主要局限性在于尚未在真实物理世界中进行验证,且在同时执行多任务(边说边做)时性能会有所下降。
🏗️ 模型架构
ELLSA的整体架构旨在实现流式全双工多输入多输出(MIMO)交互。其核心是通过将多模态数据组织成交错的时序序列(如图1(b)所示)来处理:在每个1秒的时间块内,模型按固定顺序处理语音输入、图像输入,然后生成文本输出和动作输出。
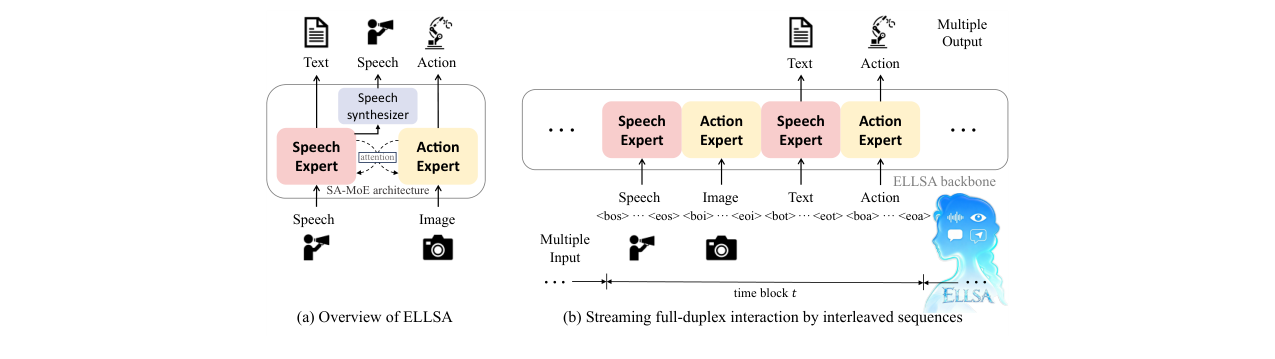
图1:(a) ELLSA概览图。在ELLSA中,不同模态由不同专家处理,专家们通过SA-MoE架构集成以进行模态交互。(b) 通过交错时序多模态序列实现的流式全双工MIMO交互。
其核心架构是SA-MoE(自注意力混合专家)。SA-MoE的设计动机是解决多模态学习中常见的模态干扰问题,并高效融合预训练组件。它包含两个主要专家模块:
- 语音专家:负责处理语音和文本模态。它由一个流式Mamba语音编码器、一个适配器和一个冻结的LLaMA-3.1-8B-Instruct语言模型骨干组成,通过LoRA进行微调。
- 动作专家:负责处理视觉和动作模态。它使用Emu3-VisionTokenizer处理图像,使用FAST对动作进行分词,骨干网络为Emu3-Base,同样通过LoRA微调。
SA-MoE的运作机制如图2所示:每个模态的token被路由到其对应的专家进行处理(如图像token进入动作专家)。然而,这些专家并不是孤立的,它们通过统一的自注意力机制进行交互。具体来说,所有专家共享一个统一的键值(KV)缓存。在计算注意力时,每个专家的查询(Q)可以关注来自所有专家(包括自身和其他专家)的键(K)和值(V),从而实现了跨模态的信息融合。这种设计使得每个专家既能专注于自己的领域以保持高性能,又能理解其他模态的信息以支持复杂的跨模态任务。
图2:SA-MoE的工作机制。每个模态被路由到其指定的专家,跨模态交互通过注意力机制实现。在推理时,所有专家共享统一的KV缓存。通过关注KV缓存,每个专家可以整合跨模态信息并实现连贯的多模态理解。
为了构建ELLSA,采用了三阶段训练策略(如图3所示):
- 阶段一:训练单独专家。分别构建并训练语音专家(在ASR和语音QA任务上)和动作专家(使用预训练的UniVLA)。
- 阶段二:训练SA-MoE。将两个专家集成到SA-MoE框架中,并在从基础到高级的多样化任务上进行训练,使专家们学会通过注意力机制协同工作。
- 阶段三:连接语音合成器。将CosyVoice2-0.5B语音合成器以端到端方式与ELLSA连接,使模型能够生成语音,完成交互闭环。
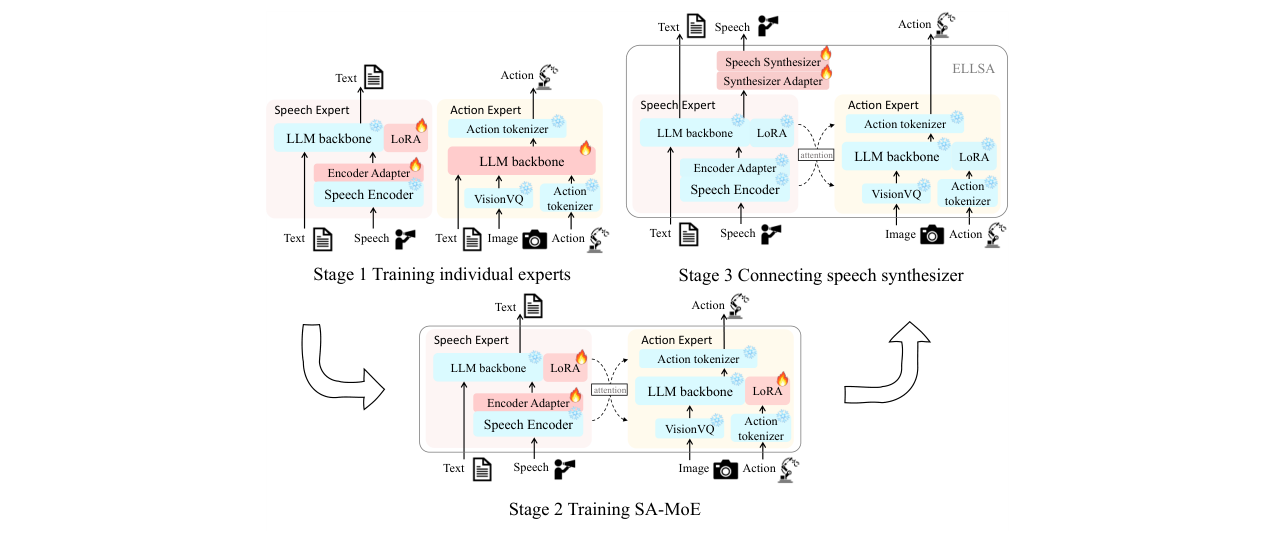
图3:ELLSA的训练策略。首先训练单个专家,然后通过集成这些专家构建SA-MoE骨干,最后连接语音合成器。在这些阶段中,训练任务和可训练参数根据模型不断增长的能力进行调整。
💡 核心创新点
- 提出SA-MoE架构以解决模态干扰:针对多模态联合建模中常见的性能退化问题,SA-MoE通过将不同模态分配给专门的专家(分工明确),再通过统一的注意力机制进行融合(高效协作)。这种设计既保留了预训练专家的强能力,又通过注意力实现了灵活的跨模态交互,相比单一的密集模型,它在训练数据量有限的情况下表现出显著优越的性能和更低的训练成本。
- 首个端到端全双工多模态MIMO模型(ELLSA):与之前只能半双工(轮流对话)或单模态输出的模型不同,ELLSA首次在一个架构内实现了视觉、语音、文本和动作的并发感知与生成。它采用流式设计,能够自己决定何时开始/停止说话或行动,支持对话轮换、动作轮换、中断响应等复杂交互动态。
- 解锁了一系列前所未有的高级交互能力:基于其全双工和MIMO特性,ELLSA实现并验证了多项高级能力,包括:
- 同时说话与操作:在执行动作指令的过程中,能同时回答语音提问或响应中断指令。
- 上下文感知的视觉问答:在操作物体过程中,能根据实时视觉场景回答关于物体状态或位置的问题。
- 缺陷指令拒绝:能够识别并拒绝不合理、无法执行的指令(如引用不存在的物体或属性),并给出理由。
- 动作被打断:在执行动作时听到中断命令,能立即停止动作并确认。
🔬 细节详述
- 训练数据:数据来自多个公开数据集,涵盖了ASR(LibriSpeech, GigaSpeech)、问答(Alpaca-52k, Web Questions, TriviaQA, SQuAD, Natural Questions, VoiceAssistant-400k, UltraChat)和机器人操作(LIBERO)。其中,语音问答数据集的部分回答语音是使用CosyVoice2从文本重新合成的。对于高级任务(如缺陷指令拒绝、上下文VQA),使用了Gemini-2.5-Pro生成标注。数据集规模庞大,例如ASR部分有超过48万样本,QA部分总样本数超过80万。
- 损失函数:论文未明确说明损失函数的具体形式,但根据其自回归生成文本和动作token的建模方式,推断为标准的下一token预测交叉熵损失。训练目标是使模型在给定交错的多模态历史序列下,最大化生成正确文本/动作token的概率。
- 训练策略:
- 阶段一(专家训练):语音专家在ASR和语音QA上训练40k步,批量大小512,学习率2e-4,仅训练连接器和LoRA。动作专家直接使用预训练的UniVLA。
- 阶段二(SA-MoE训练):在所有混合任务上训练500步,批量大小1024,学习率4e-4。两个专家均使用LoRA(秩256,缩放1.0)进行微调。
- 阶段三(连接合成器):训练20k步,批量大小256,学习率2e-4。仅微调语音合成器的语言模型部分及其连接器。
- 优化器:AdamW(β1=0.9, β2=0.95),线性预热前1%的步数。
- 精度与硬件:使用bfloat16精度,在NVIDIA A100 GPU上训练。
- 关键超参数:
- 时间块:默认1秒,也可配置为0.48秒。
- 模型大小:语音专家骨干为LLaMA-3.1-8B-Instruct(约80亿参数),动作专家骨干为Emu3-Base(参数规模未说明,但与LLaMA-8B配置相同:32层,隐藏维度4096)。因此,SA-MoE本身不引入额外参数。
- LoRA参数:秩256,缩放因子1.0。
- 生成规格:每个1秒时间块生成8个文本token(或1个
<silence>token)和1秒的动作输出。
- 推理细节:模型以1秒(或0.48秒)为时间块进行流式推理。每个时间块的输入输出交错进行。在历史上下文处理上,保留完整的语音输入和文本输出历史,但仅保留最近2秒的视觉输入和动作输出历史,以控制序列长度。解码策略未详细说明,但推测为贪婪解码或温度采样。
- 正则化技巧:未明确提及,但使用LoRA本身就是一种参数高效的正则化方法,可以防止在微调时过拟合或灾难性遗忘。
📊 实验结果
论文在基础能力和高级全双工能力上进行了全面评估。
基础能力 - 语音交互(S2T):
| 模型 | Llama Q. | Web Q. | TriviaQA | AlpacaEval |
|---|---|---|---|---|
| Moshi | 60.8 | 23.4 | 25.6 | 1.84 |
| Freeze-Omni | 74.2 | 40.8 | 45.1 | 3.90 |
| ELLSA | 74.7 | 39.5 | 45.2 | 3.09 |
| 表1:ELLSA与全双工语音交互大模型在语音交互任务上的对比。ELLSA在大多数任务上达到了最佳或接近最佳的水平,尤其在TriviaQA上优势明显。 |
基础能力 - 语音条件机器人操作(成功率):
| 模型 | SPATIAL | OBJECT | GOAL | LONG | 平均 |
|---|---|---|---|---|---|
| π0-FAST | 96.4% | 96.8% | 88.6% | 60.2% | 85.5% |
| ELLSA | 90.8% | 95.8% | 86.4% | 84.4% | 89.4% |
| 表2:ELLSA与文本条件VLA模型在LIBERO基准上的对比。ELLSA在最具挑战性的LONG任务上大幅领先,平均成功率最高。值得注意的是,ELLSA的评估设置更难(语音指令,需自主决定动作起始)。 |
高级全双工能力:

图4:ELLSA高级能力示例:从语音指令开始,模型执行动作,参与上下文VQA,并支持动作被打断。此实例不仅展示了ELLSA的核心技能,还展示了其独特的能力:处理多模态输入输出的MIMO能力,以及管理复杂对话动态(如轮换、中断)的全双工能力。
| (a) 对话轮换成功率 | (b) 动作轮换成功率与缺陷指令拒绝率 | (c) 动作执行期间处理不同语音输入的成功率 |
|---|---|---|
| 模型 | Llama Q. | Web Q. |
| Freeze-Omni | 99.7% | 99.8% |
| ELLSA | 100.0% | 100.0% |
| - | - | - |
| 表3:ELLSA在双工场景下的性能。ELLSA在所有对话轮换任务上达到100%成功率,并能可靠地区分动作执行期间的不同语音输入并做出正确反应。 |
同时说话与操作: 当ELLSA在执行动作的同时进行语音交互时,其性能有所下降,但仍保持较高水平。
| (a) 说话时的语音交互性能 | (b) 说话时的机器人操作性能(成功率) |
|---|---|
| 数据集 | S2T |
| Llama Q. | 68.9 (-5.8) |
| Web Q. | 32.8 (-6.7) |
| TriviaQA | 35.1 (-10.1) |
| AlpacaEval | 2.66 (-0.43) |
| 表4:同时说话与操作任务的性能。括号内为相较于单独说话的性能下降值。性能下降在更复杂的任务(如LONG, TriviaQA)上更明显。 |
上下文感知的视觉问答:ELLSA在上下文VQA任务上取得了约82.5%(人工评估)或83.3%(Gemini评估)的准确率,展示了其整合所有模态进行实时交互问答的能力。
消融实验:
- 时间块时长:将时间块从1秒缩短至0.48秒,SA-MoE在语音任务上性能接近,但在机器人操作任务上性能明显下降,表明更短的动作序列影响了时序连贯性。
- 专家数量:2专家(语音+动作)的设计与3专家(如语音+视觉+动作)的变体性能相当,证明了当前设计的简洁有效性。
- 语音编码器:用更强的SPEAR编码器替换Mamba编码器后,基础性能提升,且“同时说话与操作”的性能下降幅度显著减小,表明性能瓶颈部分源于模型容量。
⚖️ 评分理由
- 学术质量:6.0/7:论文创新性高,提出了SA-MoE架构优雅地解决了模态干扰问题,并首次实现了端到端全双工多模态MIMO模型。技术路线正确,实验设计非常全面,覆盖了从基础到高级的多种能力评估,数据详实,证据可信。主要扣分点在于“同时说话与操作”等高级能力仍存在性能下降,且所有实验均在模拟环境中进行,真实世界有效性待验证。
- 选题价值:1.5/2:研究方向处于具身智能和人机交互的前沿,具有重要的理论意义和应用潜力,旨在构建更接近人类的交互智能体。挑战性大,当前成果迈出了关键一步。
- 开源与复现加成:0.8/1:论文承诺开源代码、模型和数据,并在附录中提供了极其详细的模型规格、训练配置、数据集处理、评估方法和提示词模板。这为社区的复现和后续研究提供了极大便利。