📄 EmotionThinker: Prosody-Aware Reinforcement Learning for Explainable Speech Emotion Reasoning
#语音情感识别 #强化学习 #语音大模型 #数据集 #可解释AI
🔥 8.0/10 | 前25% | #语音情感识别 | #强化学习 | #语音大模型 #数据集
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Dingdong Wang (香港中文大学、微软)
- 通讯作者:未明确说明
- 作者列表:Dingdong Wang (香港中文大学、微软), Shujie Liu (微软), Tianhua Zhang (未说明), Youjun Chen (未说明), Jinyu Li (微软), Helen Meng (香港中文大学)
💡 毒舌点评
亮点在于将RL范式引入语音情感推理,并提出了一个新颖的“渐进式信任感知”奖励机制来约束推理过程,思路清晰且具有启发性。短板在于其核心的“推理质量”高度依赖一个由合成数据训练的奖励模型和GPT-4o的自动评估,这种“用AI评AI”的闭环验证其可靠性和泛化性仍需更多元的外部检验。
🔗 开源详情
- 代码:论文提供了项目主页和GitHub仓库链接(https://github.com/dingdongwang/EmotionThinker)。
- 模型权重:论文中未明确说明是否会开源EmotionThinker或EmotionThinker-Base的模型权重。
- 数据集:论文构建了EmotionCoT-35K数据集,并描述了构建方法,预计会公开。
- Demo:未提及。
- 复现材料:在附录中提供了详细的数据构建流程、模型训练细节(SFT和RL)、奖励模型训练数据构造、评估prompt等,复现信息较为充分。
- 依赖的开源项目:论文明确依赖并提及的开源项目包括:Qwen2.5-Omni(骨干模型)、WhiStress(重音检测)、wav2vec 2.0(说话人属性分类)、GPT-4o API(数据合成与评估)。
📌 核心摘要
这篇论文旨在解决当前语音大语言模型(SpeechLLMs)在情感理解上仅进行简单分类、缺乏可解释性推理的问题。论文首次尝试将情感识别(SER)重新定义为一个深度推理问题,并提出EmotionThinker框架。该框架的核心方法包括:1)构建了首个面向语音情感推理的Chain-of-Thought数据集EmotionCoT-35K;2)通过韵律感知的监督微调(SFT)构建了基础模型EmotionThinker-Base,显著提升了模型对音高、能量等韵律线索的感知能力;3)设计了GRPO-PTR强化学习策略,该策略在标准规则奖励(结果准确性)基础上,逐步引入并动态调整一个评估推理过程质量的奖励模型。实验表明,EmotionThinker在IEMOCAP、MELD等多个基准上,情感识别平均准确率达68.89%,推理质量(由GPT-4o评估的4个维度平均分)达3.98,均显著优于对比的16个开源SpeechLLM。该工作的实际意义是推动SER从“是什么”走向“为什么”,为构建可解释、可信赖的情感AI迈出了一步。主要局限性在于其推理监督和评估对大型语言模型的合成数据和自动评分依赖较重。
🏗️ 模型架构
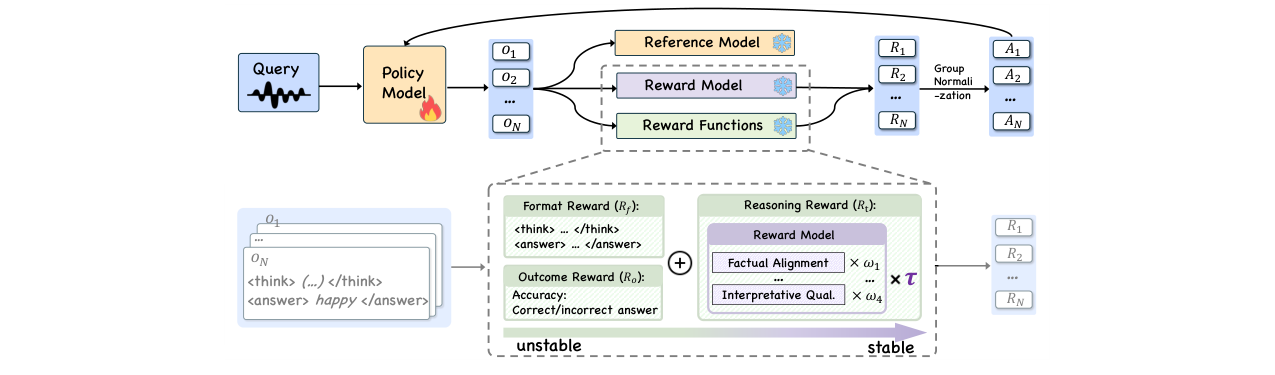
EmotionThinker是一个三阶段框架,旨在赋予SpeechLLM可解释的语音情感推理能力。
阶段一:构建EmotionCoT-35K数据集 这是一个自动化的数据构建流程。首先从多个开源情感数据集中提取原始音频,然后通过一个自动标注管道提取细粒度的声学特征(音高、能量、语速、韵律轮廓、重音)和说话人特征(性别、年龄)。接着,将这些特征作为上下文提示,输入GPT-4o生成符合特定格式(
...</think> <answer>...</answer>)的逐步推理链(CoT)。阶段二:构建EmotionThinker-Base基础模型 以Qwen2.5-Omni-7B为骨干,进行韵律感知的监督微调(SFT)。SFT语料包括单词级重音感知、韵律属性分类、韵律对比增强任务以及部分EmotionCoT样本。这一阶段联合训练了音频编码器、适配器和LLM,旨在让模型获得扎实的韵律感知能力和初步的推理结构认知。
阶段三:GRPO-PTR强化学习训练 这是框架的核心创新。在基础模型上应用基于GRPO(群组相对策略优化)的强化学习。其奖励机制由三部分组成:
- 格式奖励(Rf):强制输出符合预定义XML格式。
- 结果奖励(Ro):验证最终情感预测标签是否与真实标签一致。
- 推理奖励(Rt):这是GRPO-PTR引入的关键。它由一个专门训练的奖励模型(基于Qwen2.5-Omni-3B)对生成的推理链进行四维评分(事实对齐、解释质量、描述完整性、流畅性)。 GRPO-PTR的独特设计在于:1)渐进式引入:先仅用规则奖励训练,待准确率稳定后再加入推理奖励,以稳定训练。2)信任度权重(τ):计算一组采样结果中,正确答案和错误答案的平均推理奖励。如果错误答案的平均推理奖励更高,说明奖励信号不可靠,则通过一个指数衰减的权重τ来降低Rt在总奖励中的贡献,从而抑制“奖励黑客”行为。
下图展示了EmotionThinker的整体框架和GRPO-PTR的细节。

下图展示了EmotionCoT-35K数据集的构建流程。
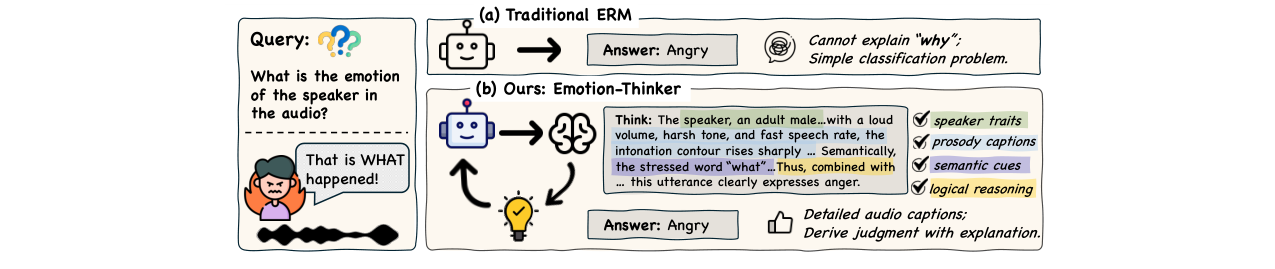
下图展示了传统情感识别与EmotionThinker推理的对比示例。
💡 核心创新点
- 任务范式重构:首次将语音情感识别(SER)从“分类”问题系统地重构为“深度推理”问题,并利用强化学习(RL)来激发和优化SpeechLLM的推理能力,开辟了新方向。
- 构建首个推理数据集:针对现有数据集缺乏推理监督的痛点,构建了EmotionCoT-35K,这是第一个包含细粒度韵律标注和Chain-of-Thought推理注释的语音情感数据集。
- 提出GRPO-PTR强化学习策略:为解决标准RL仅优化结果奖励导致的推理过程不可控问题,设计了渐进式信任感知推理奖励(GRPO-PTR)。它通过训练专门的推理奖励模型,并结合动态的“信任度权重”来确保推理质量与结果正确性的对齐,是方法上的主要贡献。
- 系统性增强韵律感知:明确指出当前SpeechLLM韵律感知弱,并通过针对性的SFT(包含对比学习任务)显著提升了模型对音高、能量、重音等关键情感声学线索的感知能力,为推理提供了可靠基础。
🔬 细节详述
- 训练数据:RL阶段使用EmotionCoT-35K中的30K样本。SFT阶段使用约500小时数据,包含Stress-17K、从GigaSpeech衍生的韵律分类/对比数据,以及5K EmotionCoT样本。
- 损失函数:RL训练优化策略模型,总奖励是格式奖励、结果奖励和(带权重的)推理奖励的加权和:
R = αfRf + αoRo + αtτRt。 - 训练策略:采用GRPO框架。RL训练3000步,学习率1e-6,KL散度系数0.04,每个输入采样K=8个候选回复。奖励权重设置为:αo=1.0,αf=0.3,αt=0.5。采用渐进式奖励调度。
- 关键超参数:基础模型骨干为Qwen2.5-Omni-7B。推理奖励模型骨干为Qwen2.5-Omni-3B,训练数据为101,400个(查询,推理,质量评分)三元组。
- 训练硬件:论文中未说明。
- 推理细节:生成内容需包含
...</think>推理过程和<answer>...</answer>最终预测。推理奖励模型输出一个包含四个字段评分的JSON对象。 - 正则化/稳定训练技巧:渐进式奖励引入(先规则奖励后推理奖励)、信任度权重τ(抑制不可靠的推理奖励信号)是两个关键稳定训练的设计。
📊 实验结果
主要实验对比了13个通用SpeechLLM/ OmniLLM和3个情感专用SpeechLLM。
主要性能对比(情感识别准确率%与推理质量平均分):
| 模型 | IEMOCAP | MELD | RAVDESS | SAVEE | 平均准确率 | 推理质量平均分 |
|---|---|---|---|---|---|---|
| Kimi-Audio | 57.72 | 59.13 | 61.07 | 55.21 | 58.83 | 2.72 |
| Qwen2.5-Omni-7B | 45.70 | 54.64 | 64.77 | 52.49 | 50.83 | 2.87 |
| BLSP-Emo | 76.00 | 57.30 | 72.00 | 63.73 | 65.41 | 2.73 |
| EmotionThinker | 77.68 | 59.71 | 71.56 | 73.96 | 68.89 | 3.98 |
消融实验结果:
| 变体 | 训练策略 | SER平均准确率 | ER平均分 |
|---|---|---|---|
| Baseline 2 | EmotionThinker-Base | 52.63 | 3.41 |
| V1 | SFT | 53.91 | 3.78 |
| V2 | GRPO (仅规则奖励) | 62.91 | 3.45 |
| V3 | GRPO-PTR (无训练奖励模型) | 66.67 | 3.36 |
| V4 | GRPO-PTR (无信任权重τ) | 67.71 | 3.74 |
| V5 | GRPO-PTR (无渐进式) | 62.80 | 3.76 |
| V6 | GRPO-PTR (完整) | 68.89 | 3.98 |
韵律感知能力对比(准确率%):
| 模型 | 音高 | 语速 | 能量 | 韵律 | 重音 |
|---|---|---|---|---|---|
| Qwen2.5-Omni-7B | 25.71 | 29.94 | 27.67 | 25.83 | 30.24 |
| EmotionThinker-Base | 75.11 | 68.70 | 69.42 | 60.25 | 71.50 |
关键结论:
- EmotionThinker在情感识别准确率和推理质量上均显著优于所有基线模型。
- 消融实验验证了GRPO-PTR中训练好的奖励模型、信任度权重τ和渐进式策略的有效性,缺少任一组件都会导致性能下降。
- 通过SFT构建的EmotionThinker-Base在韵律感知上远超原始骨干模型。
- 案例分析表明,EmotionThinker能生成更准确、更贴合声学线索的推理过程,而其他模型可能产生表面或错误的解释。
⚖️ 评分理由
- 学术质量:6.0/7:创新性强(将RL引入情感推理、提出GRPO-PTR),技术路线完整(数据-模型-优化),实验对比充分,消融研究清晰。主要扣分点在于推理监督和评估对合成数据与自动评分的重度依赖。
- 选题价值:1.5/2:方向前沿(可解释情感AI),影响潜力大,对学术和工业界(可信人机交互)均有参考价值。
- 开源与复现加成:0.5/1:提供了代码仓库链接、数据集构建方法、完整的训练策略和超参数,复现友好。但未明确承诺开源预训练模型权重。