📄 Efficient Audio-Visual Speech Separation with Discrete Lip Semantics and Multi-Scale Global-Local Attention
#语音分离 #音视频 #多模态模型 #自监督学习
✅ 7.5/10 | 前25% | #语音分离 | #多模态模型 | #音视频 #自监督学习
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Kai Li(清华大学计算机系,IDG/McGovern脑研究院)、Kejun Gao(清华大学计算机系)(论文注明两人贡献相等)
- 通讯作者:Xiaolin Hu(清华大学计算机系,IDG/McGovern脑研究院,中国脑研究中心)
- 作者列表:Kai Li(清华大学计算机系,IDG/McGovern脑研究院)、Kejun Gao(清华大学计算机系)、Xiaolin Hu(清华大学计算机系,IDG/McGovern脑研究院,中国脑研究中心)
💡 毒舌点评
亮点在于将“效率”作为核心优化目标并做到了极致,通过精心设计的轻量视频编码器(DP-LipCoder)和全局-局部注意力(GLA)模块,在大幅降低计算成本的同时保持了顶尖的分离性能,工程优化思路清晰且效果显著。短板则是核心创新略显“拼盘”,即DP-LipCoder(结合VQ与蒸馏)和GLA(结合CSA与HDA)更多是现有技术的针对性组合与优化,缺乏从第一性原理出发的突破性架构革新,理论深度有限。
🔗 开源详情
- 代码:论文明确承诺“在文章被接受后,将在GitHub上以Apache-2.0许可证发布Dolphin的代码”,并提供了演示页面链接(https://cslikai.cn/Dolphin)。当前可视为“未提供”但承诺提供。
- 模型权重:承诺发布“预训练权重(用于视频骨干)和Dolphin的源代码”。
- 数据集:使用公开数据集LRS2、LRS3、VoxCeleb2,但论文未提及是否提供预处理好的数据,表示“需要根据引用的参考文献独立获取”,但会提供预处理脚本。
- Demo:提供了在线演示页面链接(https://cslikai.cn/Dolphin)。
- 复现材料:论文提供了极其详尽的训练细节:包括完整的超参数配置(附录E)、损失函数公式(附录D)、训练硬件规格、数据处理流程、评估指标定义等。这些信息足以支持复现。
- 引用的开源项目:论文提及并依赖的开源工具/模型包括:AV-HuBERT(用于知识蒸馏)、VQ实现(来自PyPI的vector-quantize-pytorch)、FlashAttention(可选)、MTCNN(人脸检测)等。
- 开源计划:论文明确说明了开源计划,但代码和模型权重需待论文正式接受后发布。
📌 核心摘要
本文针对音视频语音分离(AVSS)模型参数量大、计算成本高、难以部署的问题,提出了一种高效模型Dolphin。其核心方法包含两部分:1) 设计了双路径轻量视频编码器DP-LipCoder,通过引入向量量化(VQ)和AV-HuBERT知识蒸馏,将连续的唇部视频流映射为与音频语义高度对齐的离散视觉token;2) 构建了一个单次迭代的轻量级编码器-解码器分离器,在其每层引入全局-局部注意力(GLA)块,分别使用粗粒度自注意力(CSA)和热扩散注意力(HDA)来捕捉长程依赖和局部细节。与已有SOTA方法(如IIANet)相比,Dolphin在LRS2、LRS3、VoxCeleb2三个基准数据集上的分离指标(SI-SNRi, SDRi, PESQ)全面更优,同时实现了参数量减少超50%、MACs降低2.4倍以上、GPU推理速度提升6倍以上的显著效率提升。这证明了Dolphin是一个性能优越且具备实际部署可行性的AVSS解决方案。主要局限性包括对清晰、同步的唇部视频的依赖,以及在资源极度受限的边缘设备上部署仍存挑战。
🏗️ 模型架构
Dolphin的整体流程如图1所示,包含五个主要组件:

图1:Dolphin的整体流程图。视觉流V通过预训练视频编码器得到重建特征Vr和语义特征Vs。音频流A通过音频编码器得到特征X。Vr、Vs与X一同输入AVF模块进行融合,得到特征F。F随后送入分离器处理,最终由音频解码器还原为目标说话者信号Ŝ。
- 预训练视频编码器(DP-LipCoder):这是本文的核心创新之一,结构如图2所示。它是一个双路径自编码器,两条路径(重建路径和语义路径)共享编码器结构但参数不共享。
- 编码器:由级联的3D残差块(图6(a))和空间注意力块(图6(b))组成,交替进行空间下采样。3D残差块整合了局部时空建模与通道注意力。空间注意力块则在每个时间步对空间维度进行自注意力计算,以捕捉长程空间依赖。
- 语义路径:在编码器输出Ze后,引入一个单步VQ模块,将其量化为离散的语义token Vs。VQ模块通过承诺损失(Lcommit)训练,迫使编码器输出与码本条目对齐。
- 训练:通过重建损失(Lrecon)、基于AV-HuBERT的蒸馏损失(Ldistill)和VQ的承诺损失(Lcommit)联合优化,确保输出特征既可重建视频又与音频语义对齐。推理时,仅使用两条路径的编码器和VQ模块。
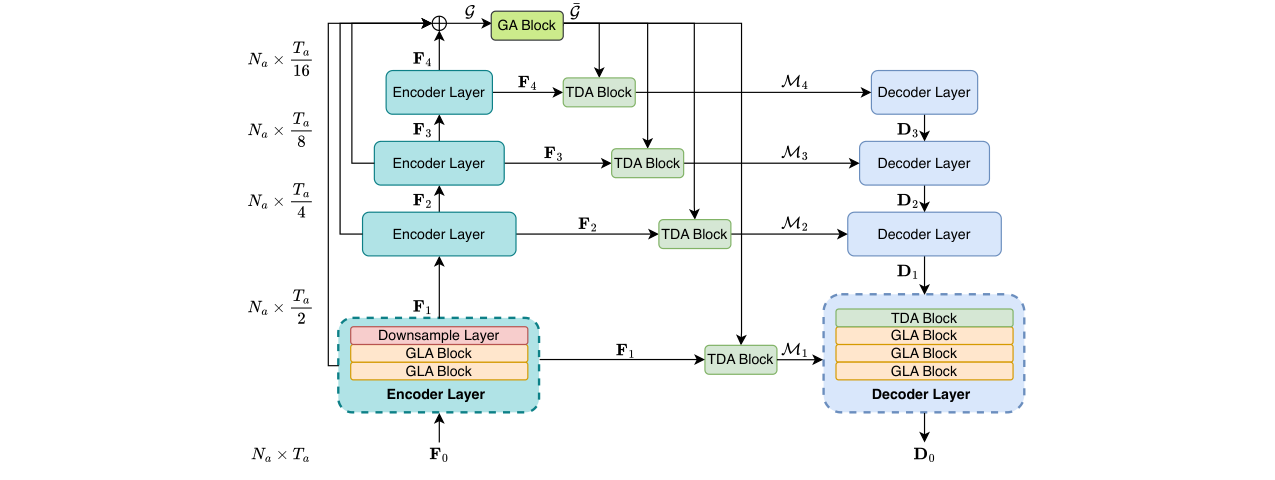
图2:DP-LipCoder的网络架构图。展示了重建路径和语义路径的编码器-解码器结构,以及语义路径中AV-HuBERT教师模型指导和VQ模块的集成。
音频编码器与解码器:均为简单的1D卷积层,分别将原始波形映射到高维特征空间,以及将分离后的特征还原回波形。
音视频融合(AVF)模块:整合了视频引导的门控融合和跨多视觉特征空间的注意力融合两种机制,并扩展到时域处理。其作用是将丰富的视觉语义(Vr, Vs)与音频特征(X)进行有效融合。
分离器:这是另一个核心组件,基于TDANet构建,但进行了重要改进。其架构如图3所示。
- 设计:采用编码器-解码器结构,但仅执行单次迭代(而非原版TDANet的多次迭代),通过增强每层的能力来补偿。
- 关键模块 - GLA块:如图4所示,这是分离器每层的核心。每个GLA块包含两个子模块:
- 全局注意力(GA)块:内含粗粒度自注意力(CSA)。CSA层首先对输入进行下采样以降低序列长度,在低分辨率空间上应用多头自注意力(MHSA)来捕捉全局长程依赖,然后再上采样回原长度。这大幅降低了注意力机制的计算复杂度。
- 局部注意力(LA)块:内含热扩散注意力(HDA)层。HDA层先将特征通过离散余弦变换(DCT)投影到伪频域(公式3),然后应用一个可学习的、基于热扩散方程的衰减函数(公式4)进行自适应平滑滤波,最后通过逆DCT(IDCT)变换回时域。这种设计用物理先验(热扩散)约束了滤波器的形状,使其能高效、低参数地建模多尺度局部特征。

图3:分离器的架构图。展示了编码器-解码器结构,其中编码器每层包含两个GLA块和一个下采样层,解码器每层包含一个TDA块和三个GLA块。
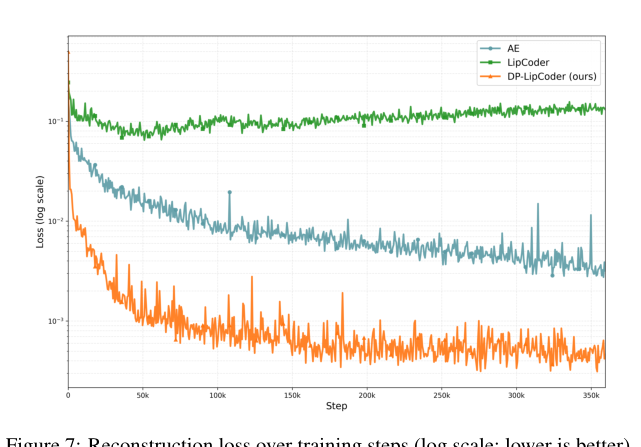
图4:分离器中GLA块的详细架构。(a) GA块,包含CSA层和FFN;(b) LA块,包含HDA层和FFN。详细展示了CSA中的下采样-注意力-上采样流程,以及HDA中的DCT-热扩散-逆DCT流程。
* 编码器:由Q层堆叠,每层包含两个GLA块和一个下采样层,逐步捕获多尺度特征。
* 解码器:与编码器对称,每层包含一个自上而下的注意力(TDA)块(用于上采样和特征调制)和三个GLA块,逐步重建特征。
💡 核心创新点
双路径离散语义视频编码器(DP-LipCoder):
- 之前局限:大型预训练视频编码器(如3D ResNet)计算昂贵;直接压缩或轻量化设计又会导致语义信息丢失,性能下降。
- 如何工作:通过双路径设计,一条路径专注视频重建以保留辅助线索(如面部表情),另一条路径通过VQ和知识蒸馏学习离散的、与音频对齐的语义token。VQ的离散化起到了正则化作用,增强了表示的紧凑性和判别性。
- 收益:在远低于3D ResNet-18的参数量(减少93%)和MACs(减少70%)下,达到了接近的分离性能(SI-SNRi差距<0.2dB),并显著优于轻量化连续自编码器基线。
带全局-局部注意力(GLA)的单次迭代轻量分离器:
- 之前局限:基于多次迭代的分离器(如原TDANet、RTFSNet)计算开销大,推理慢;而简单减少迭代次数会导致性能骤降。
- 如何工作:将分离器简化为单次迭代,但在每一层引入GLA块。GA块(通过CSA)高效建模全局上下文,LA块(通过HDA)高效建模多尺度局部细节,两者互补。这使得单次前向传播就能获得高质量分离。
- 收益:相比迭代16次的AV-TDANet,Dolphin在MACs相当的情况下,SI-SNRi提升了4.0dB(从12.8到16.8dB),并且推理速度大幅提升。
基于热扩散方程的局部注意力机制(HDA):
- 之前局限:大核卷积是建模局部特征的常用方法,但参数多,且感受野固定。
- 如何工作:将特征变换到频域,利用物理先验(热扩散方程)施加一个可学习的、通道自适应的频域衰减滤波。模型只需学习少量的缩放和门控参数,而非整个卷积核。
- 收益:相比使用大核卷积(Conv1D),HDA层在参数更少的情况下,所有指标均有提升(SI-SNRi +0.4dB),且更有效避免过拟合。
🔬 细节详述
- 训练数据:使用LRS2、LRS3、VoxCeleb2三个公开数据集。预处理包括人脸检测裁剪唇部区域为96x96灰度图(最终输入88x88),音频重采样至16kHz。默认使用2秒片段,25FPS,训练和评估涉及双说话者混合。
- 损失函数:
- DP-LipCoder预训练损失:
L = Lcommit + λdistill Ldistill + λrecon Lrecon。其中Lcommit为VQ的承诺损失,Ldistill为与AV-HuBERT教师模型输出的MSE损失,Lrecon为重建视频的L2损失。λdistill和λrecon均设为1.0。 - 分离器训练损失:结合时域和频域SI-SNR的加权和。
L(S, Ŝ3) = (1-λ) SI-SNRt(S, Ŝ) + λ SI-SNRf(S, Ŝ3)。λ采用动态衰减策略(公式28),前80个epoch为0.4,之后按指数衰减。
- DP-LipCoder预训练损失:
- 训练策略:
- 优化器:Adam,初始学习率1e-3。
- 学习率调度:验证损失停滞15个epoch则学习率减半,停滞30个epoch则早停。
- 梯度裁剪:L2范数阈值为5。
- DP-LipCoder训练:在4x RTX 3090上训练500 epoch,全局batch size 32。
- 分离器训练:在8x RTX 5090上训练,batch size 48。
- 关键超参数:
- DP-LipCoder:输入88x88x50(2秒@25FPS),通道数4->32,码本大小256,嵌入维度64。
- 分离器:编码器/解码器深度Q=4,CSA中MHSA头数8,头维度128;GLA块中FFN通道数128,卷积核大小3。
- 训练硬件:DP-LipCoder预训练使用4x NVIDIA RTX 3090;分离器训练使用8x NVIDIA RTX 5090。
- 推理细节:单次前向传播,无需迭代。视频编码器冻结,仅提取Vr和Vs。
- 正则化/稳定技巧:VQ中使用随机码本采样(温度0.1)缓解码本崩溃;L2梯度裁剪防止梯度爆炸。
📊 实验结果
主要性能对比(表3):在LRS2、LRS3、VoxCeleb2三个数据集上,Dolphin在SI-SNRi、SDRi、PESQ三项指标上均超越所有对比方法(包括IIANet、AV-Mossformer2等SOTA)。
| 方法 | LRS2 (SI-SNRi↑) | LRS3 (SI-SNRi↑) | VoxCeleb2 (SI-SNRi↑) |
|---|---|---|---|
| IIANet (SOTA) | 16.0 | 18.3 | 13.6 |
| AV-Mossformer2 | 15.1 | 17.7 | 14.0 |
| Dolphin (Ours) | 16.8 | 18.8 | 14.6 |
效率对比(表4):与最强基线IIANet相比,Dolphin在包含视频编码器的情况下,总MACs降低(10.89G vs 26.51G),GPU推理延迟降低(33.24ms vs 142.30ms)。
| 方法 | 总MACs (G) | GPU推理延迟 (ms) | GPU推理显存 (MB) |
|---|---|---|---|
| IIANet (w/ 视频编码器) | 26.51 | 142.30 | 148.14 |
| AV-Mossformer2 (w/ 视频编码器) | 124.46 | 62.30 | 398.76 |
| Dolphin (Ours) | 10.89 | 33.24 | 251.12 |
消融实验:
- GLA块组件(表5):同时使用GA和LA(完整GLA)时性能最优(SI-SNRi 16.8dB),移除任一模块均导致性能下降(GA-only: 15.9dB, LA-only: 15.6dB),证明全局与局部建模互补。
- HDA层(表6):使用HDA层比使用大核卷积(Conv1D)在更少参数下获得更高性能(SI-SNRi: 16.9 vs 16.5dB)。
- 视频编码器泛化(表2):将DP-LipCoder替换其他模型的原始视频编码器后,所有模型的效率大幅提升,性能略有下降但可接受,证明了其通用性。
- 分离器迭代次数(表11):单次迭代的Dolphin性能(16.8dB)远超迭代1次的AV-TDANet(6.4dB),并接近迭代16次的版本(12.8dB),且计算��更小。
- 输出形式(表13):直接特征映射(Mapping)优于掩码(Mask)方法(SI-SNRi: 16.8 vs 16.3dB)。
- 融合位置(表14):在分离器编码器早期(F0)融合视觉特征性能最佳(16.8dB),越深融合性能越差。
补充实验(附录):
- 多说话人场景(表8):在LRS2-3Mix和4Mix数据集上,Dolphin同样超越IIANet等方法。
- 复杂噪声场景(表9):在环境噪声、音乐噪声及两者混合且伴有多个干扰说话人的四种极端场景下,Dolphin均显著优于IIANet和AV-Mossformer2。
- 真实重叠语音主观评估(表10):在真实辩论视频重叠语音上,Dolphin获得最高MOS分(3.86),远高于IIANet(2.24)和AV-Mossformer2(2.85)。
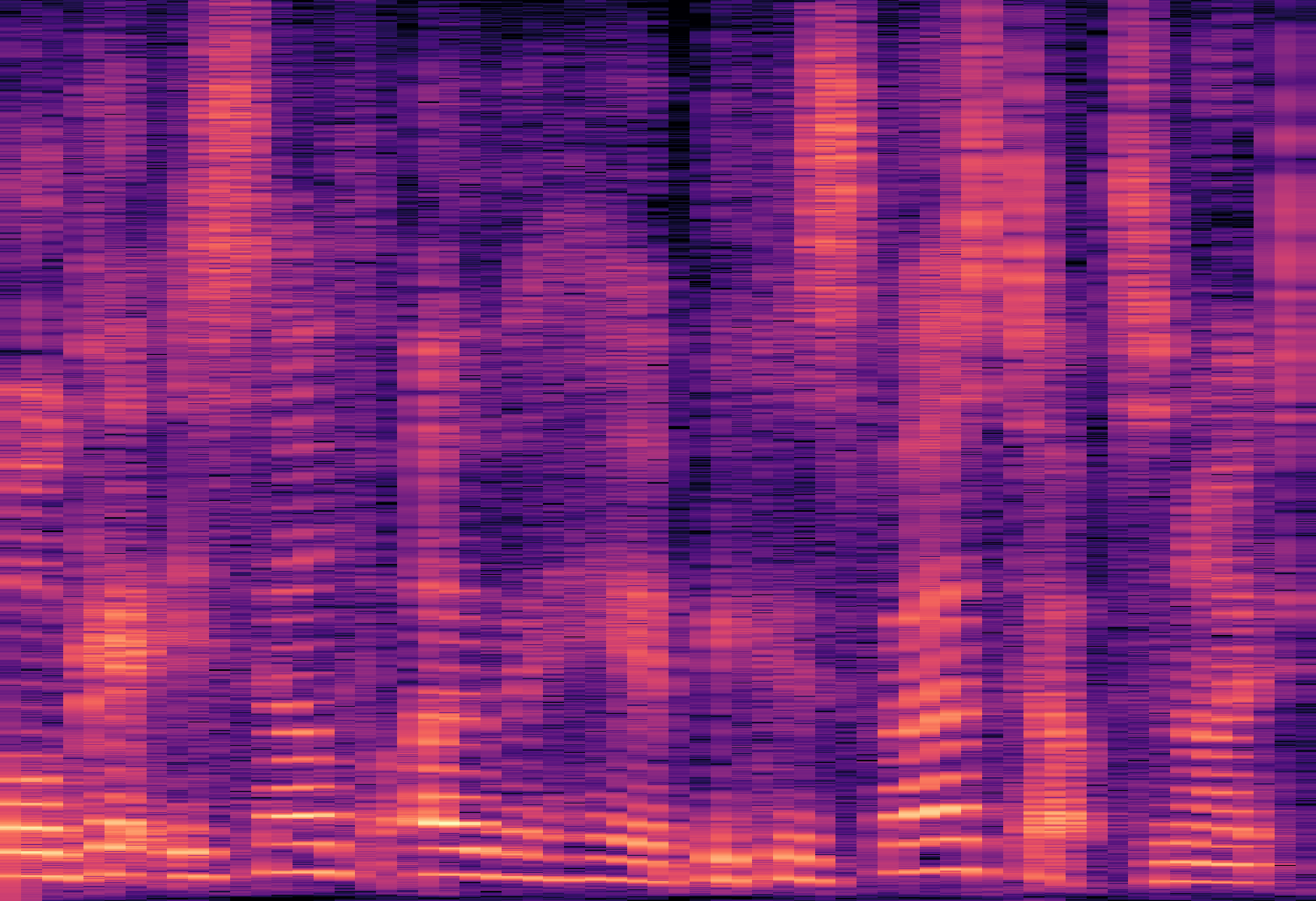
图7(论文中图7):不同视频编码器在LRS2训练集上的重建损失曲线。DP-LipCoder收敛最快且最终误差最低。
图8(论文中图9):分离结果的频谱图可视化对比。Dolphin的输出在谐波结构完整性和背景噪声抑制方面明显优于IIANet和AV-Mossformer2。
⚖️ 评分理由
- 学术质量:6.0/7。论文技术路线完整,设计了针对性模块(DP-LipCoder, GLA)并进行了严谨的消融实验验证其有效性。实验设置公平,对比充分,在性能和效率上取得了有说服力的结果。创新性主要在于工程整合与优化,提出了一个高效实用的解决方案,但未提出颠覆性的新概念。
- 选题价值:1.5/2。AVSS是语音处理的重要子领域,提升其效率对于实际应用(如助听器、通信设备)至关重要。本文直接针对效率瓶颈进行优化,成果具有明确的工程价值和应用前景。
- 开源与复现加成:0.5/1。论文明确承诺开源,并提供了详细的超参数、硬件配置和训练细节,有利于复现。承诺的开源行为给予了正面的加分。