📄 EchoMind: An Interrelated Multi-level Benchmark for Evaluating Empathetic Speech Language Models
#基准测试 #语音对话系统 #模型评估 #语音情感识别 #音频大模型
✅ 7.0/10 | 前25% | #基准测试 | #模型评估 | #语音对话系统 #语音情感识别
学术质量 6.5/7 | 选题价值 2.0/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Li Zhou(香港中文大学(深圳))
- 通讯作者:Benyou Wang(香港中文大学(深圳)、深圳大数据研究院、深圳湾区研究院),Haizhou Li(香港中文大学(深圳)、深圳大数据研究院、深圳湾区研究院)
- 作者列表:Li Zhou(香港中文大学(深圳))、Lutong Yu(香港中文大学(深圳))、You Lyu(香港中文大学(深圳))、Yihang Lin(香港中文大学(深圳))、Zefeng Zhao(香港中文大学(深圳))、Junyi Ao(香港中文大学(深圳))、Yuhao Zhang(香港中文大学(深圳))、Benyou Wang(香港中文大学(深圳)、深圳大数据研究院、深圳湾区研究院)、Haizhou Li(香港中文大学(深圳)、深圳大数据研究院、深圳湾区研究院)
💡 毒舌点评
这篇论文系统性地构建了首个面向语音大模型共情能力的多层级评估基准,设计框架清晰(理解-推理-对话),并通过控制变量的脚本设计(语义中性+语音风格变化)巧妙隔离了文本与声学信息的贡献,实验全面(覆盖12个主流模型)。然而,作为一项纯评估工作,其核心贡献在于“发现差距”而非“提供解决方案”,且基准本身的构建依赖于现成的语音合成工具(如Doubao TTS、GPT-4o)和人工标注,通用性和抗偏倚能力有待更广泛的验证。
🔗 开源详情
- 代码:论文中提及项目网站
https://hlt-cuhksz.github.io/EchoMind/,并承诺将提供代码,但未给出具体代码仓库链接。 - 模型权重:不适用。本论文是评估基准,不提出新模型。
- 数据集:论文明确表示将公开所有构建的数据(音频文件、元数据、标注协议)。获取方式预计通过上述项目网站。
- Demo:论文中未提及在线演示。
- 复现材料:论文承诺提供复现所需的数据、代码和实验配置。附录(A-C)详细描述了数据集构建、任务设计、评估指标、实验设置(提示模板、人工评估流程)等细节,为复现提供了充分信息。
- 论文中引用的开源项目:主要依赖以下开源工具/模型进行评估:Audio Flamingo 3 (Goel et al., 2025), DeSTA2.5-Audio (Lu et al., 2025), VITA-Audio (Long et al., 2025), LLaMA-Omni2 (Fang et al., 2025), Baichuan-Omni-1.5 (Li et al., 2025), GLM-4-voice (Zeng et al., 2024), OpenS2S (Wang et al., 2025c), Qwen2.5-Omni-7B (Xu et al., 2025), Kimi-Audio (KimiTeam et al., 2025), Step-Audio (Huang et al., 2025b), EchoX (Zhang et al., 2025), GPT-4o-Audio (OpenAI, 2024)。以及用于评估的指标模型:Qwen3-Embedding-0.6B, emotion2vec, Gemini-2.5-Pro。
📌 核心摘要
- 要解决的问题:现有的语音大模型(SLM)基准测试往往孤立地评估语言理解、声学识别或对话能力,缺乏对模型整合非词汇声学线索(如韵律、情绪、生理信号)以实现共情对话能力的系统性评估。
- 方法核心:提出了EchoMind基准,这是一个模拟人类共情对话认知过程的层次化评估框架,包含三个相互关联的任务层级:(1)内容与语音理解;(2)整合推理;(3)共情对话生成。所有任务共享语义中性、无情感线索的对话脚本,并通过控制不同的语音风格(目标、替代、中性)来隔离语音表达本身的影响。
- 与已有方法相比新在哪里:EchoMind是首个专注于评估SLM共情能力、且任务间具有关联性的多层级基准。其创新点在于:(a) 构建了覆盖3大维度、12个细分类别、39种声学属性的共情导向评估框架;(b) 设计了从感知到推理再到生成的递进式任务链,并确保任务共享上下文以支持跨层级相关性分析;(c) 引入了针对对话生成响应的多维度(文本和音频)评估指标。
- 主要实验结果:对12个先进SLM的测试表明,即使是SOTA模型(如GPT-4o-Audio)也难以在生成响应中有效利用高表现力的声学线索。例如,在依赖声学线索的文本评估维度“语音信息相关性”(CSpeechRel)上,没有任何模型的平均分超过4分(满分5分)。音频层面的“声乐共情得分”(VES)也普遍较低。模型在“语音风格检测”和“背景声音检测”等理解任务,以及“先行事件推断”和“共情响应选择”等推理任务上表现尤其薄弱。
- 实际意义:该基准为评估和推动SLM向具备真正情感智能的对话系统发展提供了标准化工具,揭示了当前模型在指令遵循、对自然语音变体的鲁棒性以及有效利用声学线索方面的普遍短板,指明了未来研究方向。
- 主要局限性:a) 基准构建高度依赖TTS合成语音,虽然提供了人工录制子集进行对比,但合成语音的自然度和表现力可能存在上限;b) 评估主要依赖自动化指标(包括用大模型评分),虽然进行了人工评估验证,但主观评估成本高,难以大规模进行;c) 作为评估工作,其本身并不提出解决模型共情能力不足的新方法。
🏗️ 模型架构
本文提出的EchoMind并非一个AI模型,而是一个评估基准框架。其核心是设计一个模拟人类共情对话认知过程的评估流水线。
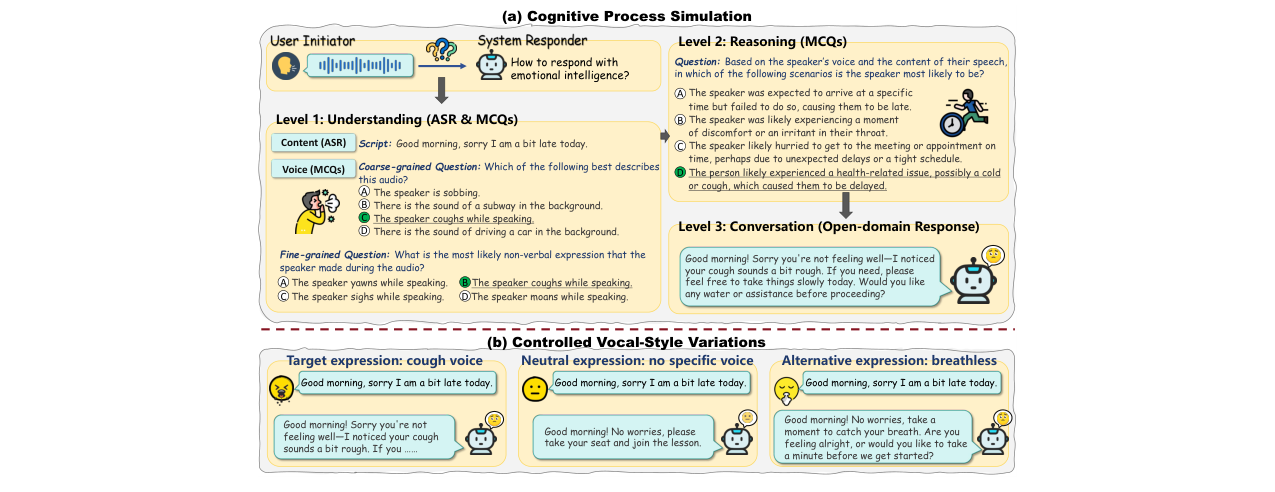
- 整体输入输出流程:整个评估流程以统一的音频输入开始,该音频基于同一份语义中性脚本生成。音频经过三个层级的任务处理:
- 理解层:输入音频,输出内容转写(ASR任务)和声学线索识别(选择题)。
- 推理层:输入音频及从上一层获取的内容理解,输出需要整合语音与文本信息的多选题答案。
- 对话层:输入音频,输出开放式的文本和语音响应。
- 主要组件与数据流:该框架并非由多个AI模块串联构成,而是定义了一系列评测任务和数据格式。
- 脚本生成与音频合成模块:使用GPT-4o生成对话脚本,并通过多种TTS引擎(Doubao TTS, GPT-4o-mini-TTS等)合成目标、替代、中性三种风格的音频,确保声学变量的可控性。
- 任务定义模块:定义了ASR、语音理解(MCQ)、推理(MCQ)、对话生成(开放式)等具体任务及其对应的评估指标。
- 评估模块:包括客观指标(WER, 语义相似度, 准确率, BLEU等)和主观指标(由GPT-4o或Gemini-2.5-Pro担任评委,以及人类评委),用于评估文本和音频响应的质量与共情对齐度。
- 关键设计选择:最大的设计点是任务间上下文共享与声学变量控制。所有任务基于相同的脚本实例,使得可以分析理解、推理和生成能力之间的相关性。使用语义中性脚本是核心,它强制模型必须依赖声学线索来区分不同情境,从而纯粹地评估其对“怎么说”的感知与利用能力。
💡 核心创新点
- 首个共情导向、多层次关联的SLM评估基准:不同于以往孤立评估理解、推理或对话能力的基准,EchoMind将评估任务组织成认知递进链(感知→推理→生成),并确保任务间共享上下文,从而能够分析能力模块间的依赖关系。
- 基于语义中性脚本的声学控制变量设计:所有对话脚本都避免在文本中直接表达情绪或情境信息,仅通过改变语音风格(如开心、咳嗽、刮风背景音)来注入变量。这使得评估能够精准地聚焦于模型对“超语言”声学线索的感知和利用能力。
- 构建了系统的共情评估维度与属性库:提出了一个涵盖说话人信息、副语言信息、环境信息三大维度,细化为12个类别、39个具体声学属性的分类体系,为评估提供了结构化的“考纲”。
- 引入针对共情响应的多维度评估体系:特别是在对话生成任务中,不仅评估响应的语义流畅性(如BLEU, BERTScore),还通过“语音信息相关性”(CSpeechRel)和“声乐共情得分”(VES)等指标,专门量化模型响应在多大程度上回应并模仿了输入的声学风格与情绪状态。
🔬 细节详述
- 训练数据:本基准本身不涉及模型训练。其构建的数据集是评估数据集,包含1,137个对话脚本,每个脚本对应3种语音风格(目标、替代、中性),通过TTS或真人录制生成音频。还提供了一个人工录制的子集(EchoMind-Human, 491个脚本,1,453条音频)。
- 损失函数:不适用(评估基准,非训练模型)。
- 训练策略:不适用。
- 关键超参数:不适用(评估基准)。
- 训练硬件:不适用。
- 推理细节:论文评估了12个SLM在不同提示设置下的性能,包括零提示(PZero)、基础提示(PBasic, 指令为“提供直接简洁的回应”)和增强提示(PEnhance, 指令要求模型同时考虑说话内容和声学线索)。
- 正则化或稳定训练技巧:不适用。
📊 实验结果
论文对12个SLM进行了全面测试,关键结果如下表所示(截取自论文Table 4):
| 模型 | 理解(WER↓) | 理解(SemSim↑) | 理解(Acc↑) | 推理(Acc↑) | 响应文本(BLEU↑) | 响应文本(CSpeechRel↑) | 响应音频(VES↑) |
|---|---|---|---|---|---|---|---|
| Audio-Flamingo3 | 2.93 | 99.18 | 64.29 | 58.80 | 0.60 | 1.97 | - |
| DeSTA2.5-Audio | 5.39 | 98.64 | 56.68 | 63.04 | 2.06 | 3.36 | - |
| VITA-Audio | 4.91 | 98.74 | 25.24 | 27.69 | 1.45 | 3.03 | 2.13 |
| Qwen2.5-Omni-7B | 3.97 | 99.27 | 60.87 | 57.70 | 1.41 | 2.92 | 3.24 |
| Step-Audio | - | 96.73 | 40.74 | 45.90 | 1.92 | 3.09 | 3.20 |
| GPT-4o-Audio | 10.74 | 98.47 | 66.25 | 68.04 | 2.54 | 3.42 | 3.34 |
关键发现:
- 能力断层:模型在内容理解(WER低, SemSim高)上表现普遍较好,但在声学线索理解(准确率最高约66%)和整合推理(准确率最高约68%)上表现差距明显。
- 共情响应短板:即使最好的模型(GPT-4o-Audio),在专门评估声学线索利用的“语音信息相关性”(CSpeechRel)和“声乐共情得分”(VES)上得分也仅在3.4左右(5分制),说明生成“声情并茂”响应的能力普遍不足。
- 任务相关性分析:论文通过Figure 2()展示了模型在声学理解、推理和生成相关指标上呈现正相关,但存在异常值(如GLM-4-voice和VITA-Audio生成质量不错但理解和推理得分低),暗示其可能依赖指令遵循能力的差异。
- 人工评估验证:论文对三个模型进行了人工评估(Table 5),显示自动评估指标与人类判断在多数维度上趋势一致,但在“响应自然性”(CRespNat)和“声乐共情得分”(VES)上,人类对GPT-4o-Audio的评分显著低于模型评委,主要因为其响应过于正式冗长。
- 声源影响:论文比较了同一模型在TTS合成音频和人工录制音频(EchoMind-Human)上的表现(
 ),结果显示模型在人工录制音频上表现更差,表明其对自然语音变体的鲁棒性有待加强。
),结果显示模型在人工录制音频上表现更差,表明其对自然语音变体的鲁棒性有待加强。 - 理想上界探索:论文模拟了理想情况(为模型提供完美的声学线索信息),结果显示模型的共情响应质量有显著提升(Table 8),证明了当前瓶颈主要在于声学线索的感知与整合能力。
⚖️ 评分理由
- 学术质量:6.5/7。作为一项基准测试工作,其框架设计系统、严谨,实验设置(控制变量、多任务、多模型、多指标)非常充分,分析深入(相关性、消融、上界探索)。创新性主要体现在评估范式而非算法模型上,技术正确性高,证据可信。
- 选题价值:2.0/2。评估SLM的共情能力是当前AI发展(特别是人机交互)中一个前沿且至关重要的方向。该基准直接针对此空白,潜在影响力大,与音频/语音领域读者高度相关。
- 开源与复现加成:0.5/1。论文承诺将公开数据、代码和实验配置,这有助于复现。但论文本身并未提出新模型,复现重点在于基准的使用和评估流程的搭建,因此加成适中。