📄 Echo: Towards Advanced Audio Comprehension via Audio-Interleaved Reasoning
#音频大模型 #强化学习 #音频问答 #多模态模型 #数据集
🔥 8.5/10 | 前10% | #音频问答 | #强化学习 | #音频大模型 #多模态模型
学术质量 6.0/7 | 选题价值 1.8/2 | 复现加成 0.7 | 置信度 高
👥 作者与机构
- 第一作者:Daiqing Wu(中国科学院信息工程研究所 IIE, ByteDance中国)
- 通讯作者:Yangyang Kang(ByteDance中国), Yu Zhou(南开大学 VCIP & TMCC & DISSec)
- 作者列表:
- Daiqing Wu(IIE, ByteDance中国, 中国科学院大学)
- Xuan Zhang(ByteDance中国)
- Dongbao Yang(IIE)
- Jiashu Yao(ByteDance中国)
- Longfei Chen(上海科技大学信息科学与技术学院)
- Qingsong Liu(ByteDance中国)
- Sicheng Zhao(清华大学心理学与认知科学系)
- Can Ma(IIE)
- Yangyang Kang(浙江大学, ByteDance中国)(带†和‡标注,应为共同通讯或同等贡献)
- Yu Zhou(南开大学 VCIP & TMCC & DISSec)(带†和‡标注,应为共同通讯或同等贡献)
💡 毒舌点评
这篇论文最亮眼的是提出了一个符合人类认知直觉的“音频交错推理”框架,并用一套从数据生成到训练的完整工程化方案将其落地,实验也做得扎实全面。然而,其性能提升高度依赖于自动合成的训练数据(EAQA),这本质上是用一个强大的“教师”(DeepSeek-R1)的知识来蒸馏模型,而数据生成的“天花板”和潜在偏差可能限制模型的上限;此外,模型当前只能“回放”原始音频片段,无法进行更复杂的音频分析操作(如慢放、滤波),这为未来的扩展留下了空间,但也是当前的局限。
🔗 开源详情
- 代码:提供了代码仓库链接:https://github.com/wdqqdw/Echo。
- 模型权重:论文中提到“We present Echo, a LALM…”,结合开源仓库链接,可推断已公开模型权重。
- 数据集:论文详细介绍了EAQA-SFT和EAQA-RL两个数据集的构建过程,并提及发布,应包含在开源仓库中。
- Demo:论文中未提及在线演示链接。
- 复现材料:提供了详尽的复现材料,包括:
- 详细的训练超参数和配置(学习率、批量大小、KL系数等)。
- 数据生成管道的完整提示词(prompt)。
- 奖励函数的具体计算方式。
- 推理伪代码(Algorithm 1)。
- 评估使用的标准提示模板。
- 硬件环境信息(NVIDIA A100 GPU)。
- 模型评估的设置细节。
- 论文中引用的开源项目:在实现细节中提及使用了以下开源工具/引擎:ms-swift(用于SFT), VERL(用于RL), vLLM(用于推理评估)。
📌 核心摘要
这篇论文旨在解决当前大音频语言模型(LALM)在处理复杂音频推理任务时,因“一次编码”策略导致的信息丢失和推理瓶颈问题。核心方法是提出“音频交错推理”范式,使模型能在推理过程中根据需要动态“重听”原始音频的关键片段,将音频从静态上下文变为推理的主动组件。为实现此目标,作者设计了一个两阶段训练框架:首先通过监督微调(SFT)让模型学会定位关键音频片段并输出带时间戳标签的推理链,然后通过强化学习(RL)利用可验证奖励信号(包括准确性、格式、一致性和片段奖励)进一步优化模型灵活调用音频片段的能力。同时,作者开发了一套自动化的数据生成管道,利用现有音频数据集和LLM合成了大规模、高质量的音频问答(Audio-QA)及推理链数据集(EAQA)。在MMAR、MMAU等专家级和通用级音频理解基准上的实验表明,Echo模型在整体性能上超越了包括GPT-4o和Gemini-2.0-Flash在内的多个先进基线模型,证明了音频交错推理的有效性和高效性。该工作为提升LALM的复杂音频理解能力提供了一个有前景的新方向,其主要局限在于训练数据完全依赖自动合成,可能引入偏差,且模型目前仅限于重放原始音频,未探索更复杂的音频处理操作。
🏗️ 模型架构
Echo是一个基于Qwen2.5-Omni (7B)构建的大音频语言模型(LALM),其核心创新在于赋予了模型“音频交错推理”的能力。模型整体架构和训练流程如图2所示。
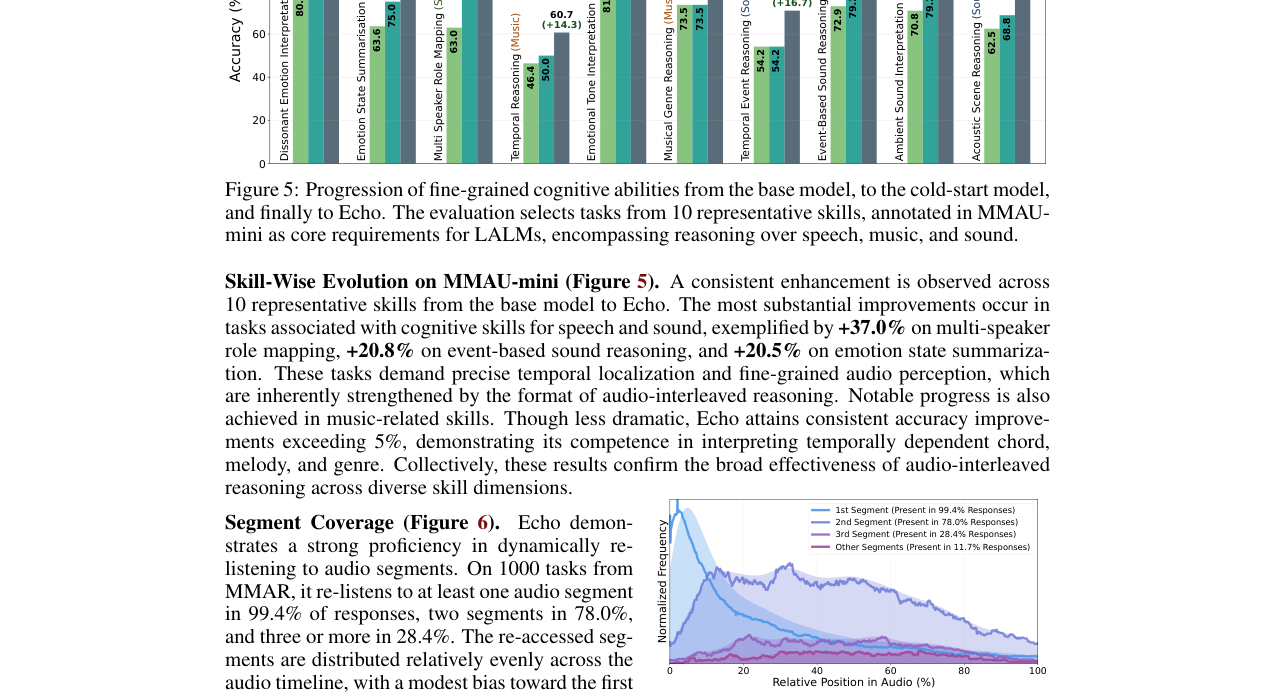
图2展示了Echo从基础模型到最终形态的完整训练框架。
- 基础模型(图2a):标准的LALM架构,包含音频编码器、投影层、tokenizer和大语言模型(LLM)。输入为音频和文本提示,输出为文本响应。
- 第一阶段:监督微调(SFT, 图2b):使用精心构造的EAQA-SFT数据集对基础模型进行微调。数据集中的每个样本包含音频、问题和带有``标签的音频定位推理链(CoT)及答案。SFT的目标是让模型学会生成包含
<seg>start, end</seg>时间戳标签对的文本推理链,以引用关键音频片段。这一步产生了“冷启动模型”。 - 冷启动模型(图2c):已具备生成包含时间戳标签的文本推理链的能力,但推理过程仍限于文本模态。
- 推理适应:激活音频交错推理(图2d):这是音频交错推理的核心。在推理时,模型生成文本,一旦解码出一对
<seg>标签,生成过程即暂停。系统从原始音频中裁剪出对应的音频片段,并将其作为新的音频令牌序列插入到当前上下文中,然后继续生成。这个过程循环进行,直到生成<eos>。这使得模型的推理真正成为多模态的。 - 第二阶段:强化学习(RL, 图2e):在冷启动模型的基础上,应用RL来优化其在音频交错推理格式下的表现。使用EAQA-RL数据集。奖励函数设计包括:
- 格式奖励:检查响应是否正确使用了标签。
- 一致性奖励:鼓励在
</seg>标签后保持语义连续性。 - 准确率奖励:答案与真实值匹配。
- 片段奖励:鼓励使用片段引用并答对。 采用分组相对策略优化(GRPO)算法进行策略更新,最终得到Echo模型。
该架构的关键设计在于推理时的动态插入机制,它打破了文本推理的封闭循环,允许模型在推理中途直接访问原始音频信号,从而缓解信息瓶颈。
💡 核心创新点
- 提出“音频交错推理”范式:这是最核心的创新。它将音频从需要一次性压缩编码的静态上下文,转变为推理过程中可按需多次、直接访问的主动组件。这模仿了人类听觉认知中的循环重听机制,解决了传统“音频条件文本推理”模式下的信息瓶颈问题。
- 设计了实现该范式的两阶段训练框架:创新性地结合了监督微调和强化学习。SFT阶段通过模仿学习快速赋予模型生成音频定位推理链的冷启动能力;RL阶段通过可验证的奖励信号,引导模型学会灵活、准确地在推理中调用音频片段,是激活模型潜力的关键。
- 构建了高质量、自动生成的音频问答数据集:针对现有数据集缺乏精细时间推理和CoT标注的问题,设计了一套完整的数据生成管道。该管道利用Qwen2.5-Omni提取音频信息,结合原始数据集的时间元数据,由DeepSeek-R1合成极具挑战性的QA-CoT三元组,并经过严格的自动过滤。最终产生了EAQA-SFT和EAQA-RL两个数据集,为训练提供了有效监督。
🔬 细节详述
- 训练数据:
- SFT数据集(EAQA-SFT):包含75,862个高质量Audio-QA样本,附带CoT标注。数据来源为AudioSet-Strong(79.8%)和MusicBench(20.2%)。平均音频长度9.85秒。99.5%的样本为4选1问题。平均CoT长度87.5词。
- RL数据集(EAQA-RL):包含21,900个Audio-QA样本,无CoT。来源为AudioSet-Strong(7.5%)、AVQA(46.8%)和MusicBench(45.7%)。题目选项数量从2到4不等。
- 损失函数:
- SFT损失(公式1):标准的交叉熵损失,优化模型预测CoT和答案中每个令牌的概率。
- RL损失(公式3):采用PPO风格的裁剪代理目标函数,包含KL散度正则项,以约束策略模型不偏离参考模型太远。
- 训练策略:
- SFT:使用ms-swift引擎,学习率5e-6,批量大小16,训练1个epoch。前5%步骤线性warm-up。音频编码器全程冻结。
- RL:使用VERL引擎,学习率1e-6,批量大小64,小批量大小32,KL系数0.04。每次查询进行8次采样(rollout),训练1个epoch。采样温度1.0。
- 关键超参数:基础模型为Qwen2.5-Omni(7B参数)。RL中奖励权重:格式0.5分,准确率0.5分,片段奖励0.5分(需答对且使用片段),一致性奖励最多扣0.5分。
- 训练硬件:SFT和RL训练均在单台配备NVIDIA A100 GPU的机器上完成(论文未明确说明具体数量,但提及评估使用单卡A100)。
- 推理细节:评估时解码温度0.7。采用音频交错推理机制,推理过程中动态插入音频片段。评估指标为精确匹配准确率(忽略大小写和特殊字符)。
- 正则化技巧:RL训练中使用了梯度裁剪(PPO中的clip机制)和KL散度惩罚,以确保训练稳定性(如图4f所示,KL散度接近0)。
📊 实验结果
论文在三个主要基准上进行了评估,重点评估高级音频理解和推理能力。
主要结果:
| 模型 | 类别 | MMAR (平均准确率 %) | MMAU-mini (平均准确率 %) | MMAU (平均平均准确率 %) |
|---|---|---|---|---|
| 随机猜测 | - | 28.61 | 26.00 | 25.92 |
| Qwen2.5-Omni (7B) | 开源基座模型 | 57.33 | 71.53 | 71.00 |
| GPT-4o-Audio | 闭源模型 | 64.09 | 62.51 | 60.82 |
| Gemini-2.0-Flash | 闭源模型 | 67.90 | 70.51 | 67.03 |
| Audio-Thinker (7B) | 适配模型 | 67.25 | 78.00 | 76.60 |
| Echo (7B, Ours) | 适配模型 | 69.99 | 80.41 | 76.61 |
关键发现:
- Echo在MMAR基准上取得了最佳的平均准确率(69.99%),超越了所有开源、适配模型以及GPT-4o-Audio(64.09%)和Gemini-2.0-Flash(67.90%)等闭源系统。
- 在通用音频理解基准MMAU-mini和MMAU上,Echo也取得了领先的性能(MMAU-mini: 80.41%, MMAU: 76.61%)。
- 消融实验(表3)清晰地展示了训练路径的效果:
- SFT(A→B)带来4.97%的准确率提升。
- 直接切换到音频交错推理格式(B→C)会导致性能下降。
- RL(C→D)不仅恢复了性能,还将其提升至峰值69.99%。
- 与使用相同RL数据但不同推理格式的模型(B‘和E)相比,音频交错推理格式(D)表现最佳,证明了格式本身的优势。
分析实验与可视化:
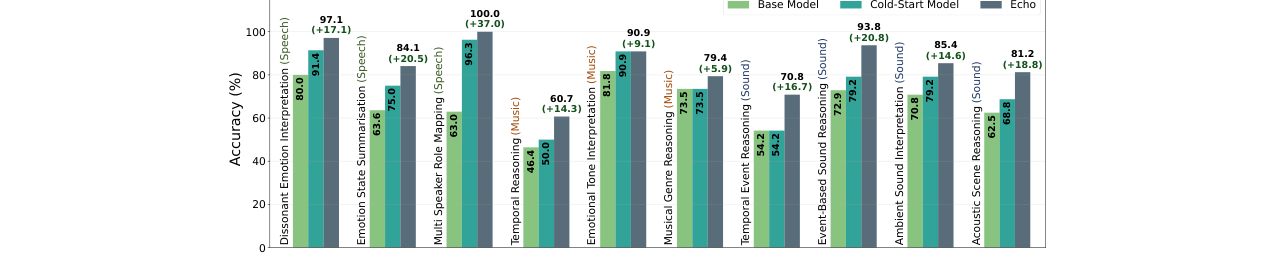
图1直观对比了音频条件文本推理(a)与音频交错推理(b)在推理过程中模型对音频令牌的注意力分配。后者能维持对音频的持续关注。

图5展示了从基座模型到冷启动模型再到Echo,在MMAR-mini的10项代表性技能上的准确率进步,尤其在“多说话人角色映射”(+37.0%)和“事件推理”等需要精细时序分析的任务上提升显著。
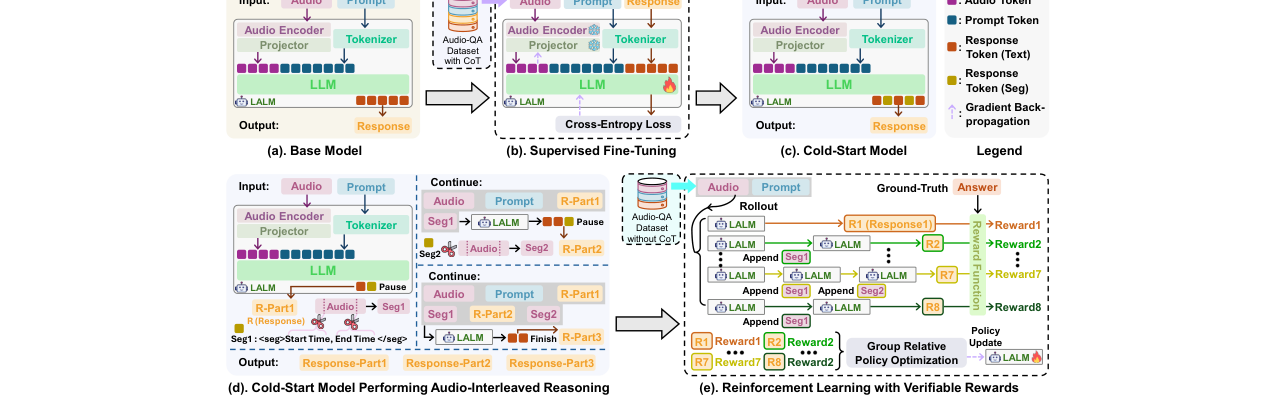
图6显示了在MMAR任务中,Echo的响应引用音频片段��分布情况。99.4%的响应包含至少一个片段引用,且覆盖了音频的各个时间区域。
图4展示了RL训练过程中,准确率奖励(a)、格式奖励(b)、每响应片段数(c)、平均片段时长(d)、片段重叠率(e)和KL散度(f)的变化曲线,表明训练过程稳定且有效。
⚖️ 评分理由
- 学术质量:6.0/7:工作完整度高,创新性强,实验设计科学且充分,证据链完整。扣分点在于数据合成完全依赖LLM,其质量上限可能受限于LLM本身的能力和偏差;且对模型的“推理”能力评估主要通过QA准确率间接反映,缺乏对推理过程本身逻辑性、合理性的深入量化评估。
- 选题价值:1.8/2:选题紧扣前沿,针对LALM性能提升的核心瓶颈提出解决方案。潜在影响较大,可推广到其他模态的推理。应用空间明确。相关性高。
- 开源与复现加成:0.7/1:开源了代码、模型、数据集,并提供了极其详细的复现说明,极大降低了复现门槛,复现可行性高。