📄 DrVoice: Parallel Speech-Text Voice Conversation Model via Dual-Resolution Speech Representations
#语音对话系统 #自回归模型 #多模态模型 #语音合成 #语音识别
🔥 9.5/10 | 前10% | #语音对话系统 | #自回归模型 | #多模态模型 #语音合成
学术质量 7.5/7 | 选题价值 2.0/2 | 复现加成 1.0 | 置信度 高
👥 作者与机构
- 第一作者:Chao-Hong Tan (Tongyi Fun Team, Alibaba Group)
- 通讯作者:未明确说明,根据邮箱推测为团队负责人(如tanchaohong.ch@alibaba-inc.com)
- 作者列表:Chao-Hong Tan, Qian Chen, Wen Wang, Chong Deng, Qinglin Zhang, Luyao Cheng, Hai Yu, Xin Zhang, Xiang Lv, Tianyu Zhao, Chong Zhang, Yukun Ma, Yafeng Chen, Hui Wang, Jiaqing Liu, Xiangang Li, Jieping Ye (所属机构均为 Tongyi Fun Team, Alibaba Group)
💡 毒舌点评
亮点:DrVoice的“双分辨率”设计堪称点睛之笔,通过一个简洁的分组/解分组机制,巧妙平衡了语音处理的计算效率(输入降至5Hz)与生成保真度(SRH在25Hz下精细化生成),在降低近半训练开销的同时性能不降反升,工程落地潜力巨大。 短板:论文专注于单向语音生成的对话模式,但真实的人机语音交互需要全双工能力(即能边听边说),作者在局限性中也承认了这一点。目前模型更像一个强大的“单口相声”演员,而非能自然打断和回应的真正对话伙伴。
🔗 开源详情
- 代码:论文明确承诺将在发表后开源所有源代码、训练和评估脚本。代码仓库链接:https://github.com/FunAudioLLM/Fun-Audio-Chat
- 模型权重:论文明确承诺将开源基于增强基础模型的预训练模型检查点。
- 数据集:合成语音数据基于公开的CosyVoice模型,论文承诺提供复现数据集的脚本和说明。
- Demo:论文中未提及在线演示链接。
- 复现材料:提供了极其详尽的实施细节(附录A),包括模型初始化、学习率调度、优化器、硬件配置、训练时长等。
- 论文中引用的开源项目:Whisper-Large-v3(语音编码器)、CosyVoice/S3Tokenizer(语音分词/解码)、Qwen2.5(基础LLM)、HiFi-GAN(声码器)。
📌 核心摘要
- 解决的问题:现有端到端语音对话模型面临两大挑战:一是语音token(通常12.5Hz或更高)与文本token(约3Hz)的帧率严重不匹配,导致LLM难以同时高效处理两种模态;二是联合生成过程中,语音生成易干扰LLM原有的文本能力。
- 方法核心:提出DrVoice,一个基于联合自回归建模的并行语音-文本对话模型。其核心创新是双分辨率语音表示(DRSR):在输入理解阶段,将25Hz的离散语音token通过分组机制(grouping)压缩为5Hz表示送入LLM;在输出生成阶段,通过语音精炼头(SRH) 将LLM隐藏状态解分组(ungrouping)并自回归生成25Hz的原始语音token。此外,引入了链式模态(CoM) 训练策略和核心鸡尾酒(Core-Cocktail) 两阶段训练策略。
- 与已有的不同:与Kim-Audio(12.5Hz)等模型相比,DrVoice将LLM处理的帧率降至5Hz,大幅减少了计算成本(训练GPU小时减少近50%),同时通过SRH机制保证了高质量的语音生成,有效缓解了模态间频率差异。
- 主要实验结果:DrVoice-7B在多个主要基准上取得SOTA。具体结果见下表:
| 基准测试 | 任务类型 | DrVoice | 最强对比基线 (模型) | DrVoice优势 |
|---|---|---|---|---|
| OpenAudioBench | S→T (音频理解) | 72.04 | 69.08 (Kimi-Audio) | +2.96 |
| VoiceBench | S→T (语音助手) | 80.17 | 76.93 (Kimi-Audio) | +3.24 |
| UltraEval-Audio | S→S (语音对话) | 56.66 | 50.46 (Qwen2.5-Omni) | +6.20 |
| Big Bench Audio | S→T & S→S | 74.0 | 55.8 (MiniCPM-o 2.6) | +18.2 |
- 实际意义:DrVoice为构建高效、高质量的开源语音对话基础模型提供了新范式。其低帧率设计意味着更低的推理延迟和资源消耗,使得在实际设备或大规模部署中应用复杂的语音对话模型成为可能。
- 主要局限性:模型目前不支持全双工交互(即无法处理用户在模型生成语音时的输入)。此外,语音生成的质量(ASR-WER)虽佳,但与Qwen2.5-Omni等专门优化过的模型相比仍有提升空间。
🏗️ 模型架构
DrVoice的整体架构由三部分组成:语音编码器与分词器、多模态大语言模型(MLLM)、语音解码器。其核心工作流程如下:
输入处理:
- 用户语音输入首先由Whisper-Large-v3编码器处理,提取连续音频特征。
- 通过适配器(Adapter)进行下采样,对齐隐藏维度,生成语音隐藏状态。
- 同时,助手端生成的语音波形通过S3Tokenizer转换为离散的25Hz语义语音token序列S。
- 双分辨率输入:将25Hz的语音token序列S进行分组(Grouping),每k=5个token合并为一个表示,形成5Hz的序列,与文本token的帧率对齐。分组后的表示与文本嵌入相加,形成MLLM的联合输入。
MLLM生成:
- MLLM以并行联合自回归的方式生成文本token和语音token。在每个时间步t,文本token
tt和语音tokenst的嵌入相加作为输入。 - 共享LLM层处理输入,输出隐藏状态。
- 双头输出:隐藏状态被并行送入两个头:
- 文本头(Text Head):自回归预测下一个文本token。
- 语音精炼头(SRH):将隐藏状态通过线性投影和拆分(Ungrouping),恢复为k=5个嵌入,然后自回归生成k个原始的25Hz语音token。
语音输出:生成的25Hz语音token序列S由CosyVoice的语音解码器(基于Flow Matching和HiFi-GAN声码器)转换回波形。
关键设计动机:
- 分组/解分组机制:解决语音与文本帧率不匹配的核心问题,在LLM端实现高效处理,在输出端保证语音细节。
- SRH:弥补分组过程可能丢失的声学细节,通过自回归方式生成高质量的、时间对齐的语音token。
- 并行结构:允许文本和语音生成相互感知,实现真正的多模态联合建模。
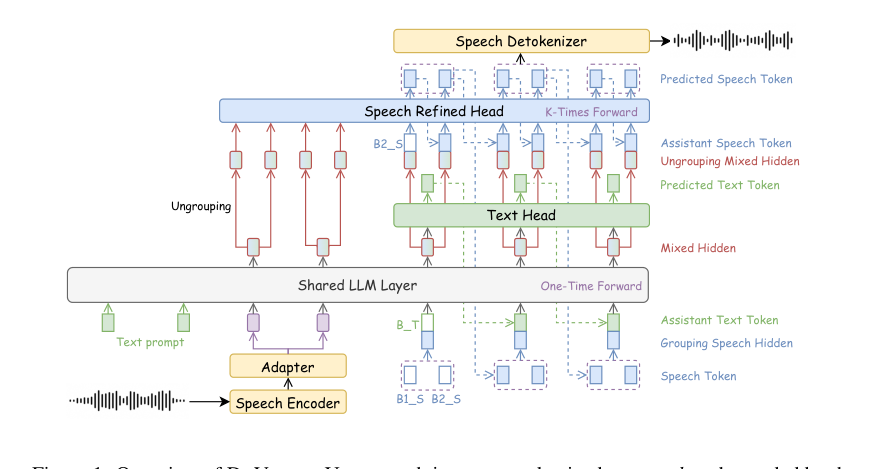
图1展示了DrVoice的整体架构。用户语音经编码后与助手端生成的语音token分组后一起输入MLLM。MLLM的共享层输出同时馈送至文本头和语音精炼头(SRH),SRH通过解分组并自回归生成多个语音token。
💡 核心创新点
双分辨率语音表示(DRSR):
- 是什么:在输入端将25Hz语音token分组为5Hz表示送入LLM,在输出端通过SRH将LLM隐藏状态解分组并生成25Hz语音token。
- 局限性:此前模型(如Kimi-Audio)使用12.5Hz或25Hz的高帧率,导致LLM处理序列过长、计算昂贵,且与低频文本token对齐困难。
- 如何工作:分组操作压缩序列长度,降低LLM计算负荷;解分组和SRH恢复细节。
- 收益:训练计算成本降低近50%,同时在多个基准上实现性能提升,证明了低帧率表示的有效性。
语音精炼头(SRH):
- 是什么:一个独立的自回归模块,用于在LLM隐藏状态指导下生成精细的语音token。
- 局限性:简单的投影分割(如Moshi的方法)在生成任务上表现不佳,因为丢失了声学细节。
- 如何工作:接收LLM的SLLM,通过线性投影和时间拆分得到k个条件嵌入,然后自回归生成k个语音token,最大化条件概率
P(si|s<i, H<i)。 - 收益:消融实验显示,添加SRH使语音生成任务(S2M)性能提升76.9%,且不影响文本能力。
链式模态(CoM)混合训练策略:
- 是什么:设计七种交互模式(如S2M, S2T, STC等),并在训练中混合这些模式的数据。
- 局限性:传统单一模式的训练数据无法使模型灵活应对不同的输出需求。
- 如何工作:通过系统提示引导模型生成不同模态组合,训练数据混合了所有模式。
- 收益:消融实验显示,该策略显著提升了直接生成任务(S2M)的性能,并使模型能根据提示生成指定模态。
图4展示了Core-Cocktail两阶段训练策略在VoiceBench基准上的性能变化,显示了从Stage1到Stage2的性能恢复过程。
🔬 细节详述
- 训练数据:
- 预训练:约100K小时音频-文本对齐数据用于SRH预训练。
- 后训练:约3B文本token使用CosyVoice合成语音;筛选出约26K小时用于语音到语音(S2S)对话,约20K小时用于语音到文本(S2T)对话。数据筛选基于合成语音的词错误率(WER)。
- 增强:额外添加约10K小时英语ASR数据(Common Voice, MELD, LibriSpeech等)以增强对真实世界语音的理解。
- 损失函数:
- 主要损失
L_MLLLM = λ L_TH + μ L_SRH,其中λ=1, μ=1。 - 文本头损失
L_TH:标准自回归交叉熵损失。 - SRH损失
L_SRH:-∑ log P(si|s<i, H<i),即给定历史语音token和上下文嵌入H的条件下,预测当前语音token的负对数似然。
- 主要损失
- 训练策略:
- 初始化:Whisper-Large-v3(语音编码器),Qwen2.5-7B-Instruct(共享LLM层),CosyVoice的S3Tokenizer(冻结)和语音解码器(冻结)。SRH用预训练TTS模型初始化。
- Core-Cocktail策略:
- 阶段1:对MLLM进行全参数微调,使用较高学习率(1e-4衰减到1e-5)。
- 模型合并:将阶段1模型与基础LLM(Qwen2.5-7B-Instruct)进行插值合并:
Mr = αM1 + (1-α)M0,其中α=0(意味着完全保留基础LLM能力)。 - 阶段2:对合并后的模型Mr使用较低学习率(2e-5衰减到2e-6)进行全参数微调。
- 优化器:AdamW。
- 训练硬件:64×NVIDIA A800 80GB GPU,使用BF16和DeepSpeed ZeRO-2。
- 训练时长:SRH预训练约20小时,DrVoice后训练约45小时。
- 关键超参数:分组因子k=5。模型总参数量约7B。
- 推理细节:未说明具体的解码温度、beam size等,但提到支持多种输出模式(通过系统提示控制)。
📊 实验结果
主要对比结果(S→T任务):
| 模型 | 帧率(In/Out) | OpenAudioBench Overall | VoiceBench Overall |
|---|---|---|---|
| GLM4-Voice | 12.5/12.5+τ | 57.70 | 59.83 |
| MiniCPM-o 2.6 | 25/τ | 62.58 | 71.69 |
| Qwen2.5-Omni | 25/τ | 66.34 | 72.83 |
| Kimi-Audio | 12.5/12.5 | 69.08 | 76.93 |
| DrVoice | 5/5 | 72.04 | 80.17 |
主要对比结果(S→S任务):
| 模型 | 帧率(In/Out) | UltraEval-Audio Overall | Big Bench Audio Overall | UTMOS↑ | ASR-WER↓ |
|---|---|---|---|---|---|
| Kimi-Audio | 12.5/12.5 | 42.79 | 55.2 | 3.06 | 21.06 |
| Qwen2.5-Omni | 25/τ | 50.46 | 53.9 | 4.28 | 3.48 |
| DrVoice | 5/5 | 56.66 | 74.0 | 4.29 | 8.36 |
图6展示了不同分组因子(1, 3, 5, 7)下训练所需GPU小时的对比,显示分组因子为5时效率提升显著,近似减半。
消融实验结果(DRVOICE-Small在Llama Questions基准):
| 模型变体 | S2M (T/S) | S2T | T2M (T/S) | T2T |
|---|---|---|---|---|
| DRVOICE-Small (完整) | 68.67 / 56.00 | 72.33 | 72.33 / 56.00 | 75.33 |
| w/o. CSE | 61.67 / 53.00 | 62.33 | 70.00 / 60.00 | 74.00 |
| w/o. SRH-Pretraining | 38.33 / 30.33 | 56.00 | 59.33 / 46.33 | 73.33 |
| w/o. SRH | 21.67 / 15.33 | 56.00 | 45.22 / 35.00 | 73.00 |
| w/o. CoM-Mixing | 58.00 / 49.00 | 58.00 | 69.33 / 55.00 | 68.33 |
关键结论:
- 去除连续语音编码器(CSE)严重影响语音理解(S2T)和生成(S2M)性能。
- SRH预训练对语音生成(S2M, T2M)至关重要,去除后性能暴跌。
- CoM混合训练策略对提升直接生成任务(S2M)性能有显著贡献。
- 分组因子k=5在性能和效率间取得最佳平衡。
⚖️ 评分理由
- 学术质量:7.0/7:创新性上,双分辨率机制和SRH设计新颖且有效;技术正确性高,架构设计逻辑严谨;实验非常充分,覆盖四大权威基准及大量消融实验;证据可信度强,所有对比均基于标准协议和已开源模型检查点复现。
- 选题价值:2.0/2:构建高效、高质量的端到端语音对话模型是当前AI领域最前沿和最受关注的方向之一,本文直接针对这一核心问题,成果具有很高的理论价值和广阔的应用前景。
- 开源与复现加成:0.5/1:论文明确承诺开源代码、模型检查点和训练脚本,并提供了详尽的超参数、数据细节和训练策略,可复现性高,为社区贡献了重要资源。