📄 Discovering and Steering Interpretable Concepts in Large Generative Music Models
#音乐生成 #稀疏自编码器 #预训练 #可解释性
🔥 8.0/10 | 前25% | #音乐生成 | #稀疏自编码器 | #预训练 #可解释性
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 中
👥 作者与机构
- 第一作者:Nikhil Singh (Dartmouth College),Manuel Cherep (MIT) —— 共同第一作者
- 通讯作者:未明确标注,但Pattie Maes (MIT) 可能为项目负责人
- 作者列表:Nikhil Singh (Dartmouth College),Manuel Cherep (MIT),Pattie Maes (MIT)
💡 毒舌点评
亮点:首次将稀疏自编码器(SAE)技术从大语言模型(LLM)的可解释性研究成功迁移到音频/音乐生成领域,并构建了端到端的自动化发现、标注与验证流水线,方法论上具有清晰的开创性和系统性。
短板:对于所发现的“概念”的边界(monosemanticity)控制和负样本分析不够深入,且部分自动化标注和评估高度依赖外部模型(如Gemini、CLAP),可能引入偏置;概念引导生成的成功率(约15-35%)虽证明可行性,但作为“强干预”实验,其鲁棒性和泛化性仍有很大提升空间。
🔗 开源详情
- 代码:论文中未提供明确的代码仓库链接。
- 模型权重:实验使用了预训练的MusicGen模型(Large和Small版本),以及Essentia和CLAP的预训练模型。论文训练的SAE权重未提及是否公开。
- 数据集:使用了公开的MusicSet数据集。
- Demo:论文中未提及在线演示。
- 复现材料:附录提供了部分技术细节(如Gemini的提示词和响应格式、Essentia使用的标签模型列表、人类验证指南),但核心的SAE训练超参数(学习率、优化器等)未详细说明。
- 依赖的开源项目:论文明确依赖并提及了MusicGen、Essentia、CLAP、Gemini API等开源模型或工具。
📌 核心摘要
这篇论文旨在解决大型自回归音乐生成模型(如MusicGen)内部表示不透明、难以与人类音乐概念对齐的问题。核心方法是利用稀疏自编码器(SAE) 对Transformer残差流的激活进行重构,从中提取出稀疏、可解释的潜在特征(概念),并构建了一套自动化标注与评估流程(结合多模态大语言模型和预训练音频分类器)来大规模识别这些概念。与已有工作主要关注“探测已知概念”不同,本文提出了一个无监督的概念发现流水线,能够发现模型隐式学习的、甚至超越现有理论描述的音乐规律。实验结果表明,该方法在两个不同规模的MusicGen模型上都能发现熟悉的音乐概念(如鼓点、流派、乐器音色)和新兴的、难以用现有术语定义的规律(如特定的电子音效、音乐织体单元)。关键量化结果包括:在MusicGen-Large上,过滤后可保留数千个可解释特征;自动化标注质量通过CLAP分数进行评估(详见图4);通过引入特征进行引导生成,15%-35%的特征能提升生成音频与目标概念的CLAP对齐分数(表2),并且人类听辨实验(66/100的正确率)证实了引导效果的可感知性。该工作为理解生成模型如何组织音乐信息提供了实证工具,并指向了可控生成的可能性。
🏗️ 模型架构
本文的核心并非提出一个新的生成模型架构,而是提出了一个用于解释现有生成模型的分析流程。该流程的完整架构如图1所示。
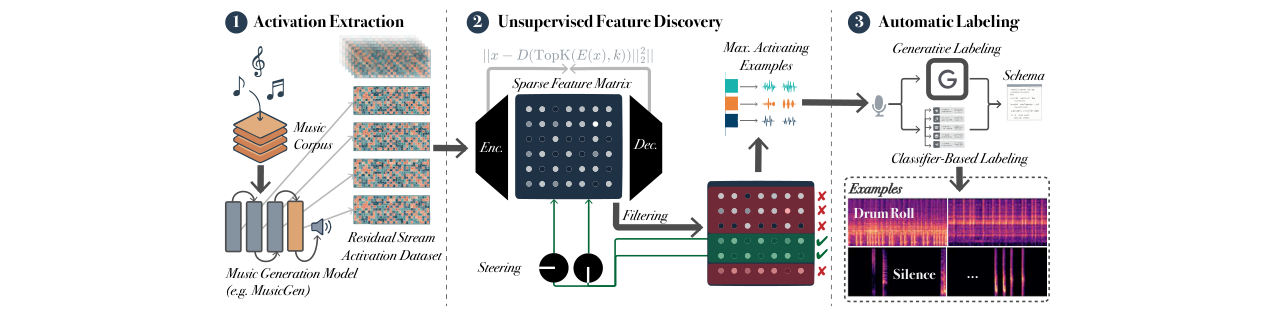
图1:在自回归音乐模型中发现和引导可解释概念的多阶段管道流程图。该图完整展示了从数据输入、特征提取、概念发现到最终引导生成的整个端到端流程。
整个流程分为三个主要阶段:
- 激活提取与数据集构建:将大规模音乐语料库(MusicSet)输入预训练的MusicGen模型(如MusicGen-Large或MusicGen-Small),从其Transformer的多个残差流层(如早期、中期、晚期层)中提取激活向量,构建激活数据集。
- 特征发现与过滤:使用稀疏自编码器(SAE) 处理上述激活数据。SAE的架构由一个编码器(
h = ReLU(Wex + be))和一个解码器(x̂ = Wdh + bd)构成,中间施加一个k-sparse投影操作以强制稀疏性。训练目标是最小化重构损失与L1稀疏惩罚的加权和(公式1)。训练后,对潜在特征进行过滤,剔除不活跃(激活率ri=0)、过于普遍(ri > 0.25)或过于罕见(ri < 0.01)的特征,保留具有可解释潜力的特征。过滤后的特征被表示为一个稀疏特征矩阵,并为每个特征提取其最大激活样本(Top-10)。 - 特征标注与验证:为过滤后的特征自动分配标签。采用两种策略:1) 生成式标注:将每个特征的Top-10音频样本输入多模态大语言模型(如Gemini Flash 1.5),要求其识别共性并输出概念名称、描述和置信度。2) 基于分类器的标注:使用预训练的音频分析工具(如Essentia)提取标签。最后,利用CLAP模型计算生成标签与特征音频之间的语义对齐分数,进行定量评估。此外,进行了人类验证研究以评估标注质量。
最终,该流程发现的特征(概念)可以被用于生成引导(图1右侧)。引导方法是在生成过程中,将特定特征的解码器权重向量(Wd,j)按一定强度(α β)加到原始残差流激活上(x' = x + α β * Wd,j),从而操纵生成输出偏向该概念。
💡 核心创新点
- 首次在音频领域应用稀疏自编码器进行概念发现:将SAE这一在大语言模型可解释性中取得进展的技术,成功迁移到复杂、具有时序层级结构的音乐生成模型(MusicGen)中,证明了其在提取音频可解释特征上的有效性。这填补了该方法在非文本、非视觉领域的应用空白。
- 构建可扩展的自动化标注与评估流水线:针对音乐概念难以手动标注的问题,设计了结合多模态LLM(生成开放式标签) 和预训练音频分类器(提取固定标签) 的混合标注策略,并利用CLAP跨模态对齐分数进行大规模自动化评估。这使得对成千上万个潜在概念的评估成为可能,是支撑研究规模化的关键。
- 实现从概念发现到可控生成的闭环验证:不仅发现了概念,还通过特征引导(steering)实验,验证了这些由SAE发现的特征在因果上可操作。人类听辨研究(66/100的选择率)证实引导效果显著优于随机方向引导和无引导基线,建立了该方法在可控生成中的实用潜力。
🔬 细节详述
- 训练数据:使用MusicSet数据集(约16万样本,大多约10秒长),它由MTG-Jamendo、MusicCaps和MusicBench组合而成,均为Creative Commons许可。选择它是因为其风格多样性和规模。
- 损失函数:SAE的损失函数为重构MSE损失加上L1稀疏惩罚(公式1):
min_{E,D} E[||x - D(E(x))||^2 + λ||E(x)||_1]。实际实现中采用k-sparse变体,通过保留隐藏层激活中前k大的值并置零其余,来显式强制稀疏性。 - 训练策略:论文未说明SAE具体的优化器、学习率、batch size等超参数。仅提及在4x NVIDIA L40s GPU的节点上进行训练。
- 关键超参数:SAE的扩展因子(EF) 实验了4和32;稀疏度(k) 实验了32和100。原始模型MusicGen的残差流维度为1024(Small)和2048(Large)。提取激活的层深包括早期(如Layer 2)、中期和晚期。
- 训练硬件:未详细说明,仅提及使用AWS RES和MIT HPC资源。
- 推理细节:生成引导时,使用中性提示“Simple melody”,固定随机种子,测试引导强度α=0.0(基线)和α=1.0(最大引导)。计算引导特征的β(最大激活强度)来自其Top-10激活样本。
- 正则化/稳定训练技巧:通过过滤机制(激活率ri在0.01到0.25之间)来确保特征的可解释性,这本身是一种重要的后处理正则化。
📊 实验结果
- 特征统计与过滤效果(表1): 论文报告了不同模型、层深和SAE配置下过滤后保留的特征数量(表1)。MusicGen-Large(MGL)在特定配置(如EF=32, k=100, Layer 2)下可保留超过2000个特征,而MusicGen-Small(MGS)通常保留少于100个。这表明模型规模显著影响可提取的可解释特征数量。
| MusicGen Large | MusicGen Small |
|---|---|
| 配置 (EF, k) | L2 |
| (4, 32) | 12 |
| (4, 32) | 30 |
| (4, 100) | 407 |
| (32, 100) | 2344 |
| 表1:过滤后的特征数量统计。加粗数字为该配置下的最大值。 |
- 自动化标注质量评估(图3, 图4):
- 层间差异:对于MGL,更深层产生的特征平均CLAP分数更高(图3),表明其特征更容易与人类可解释的概念对齐。
- 标注策略对比:图4展示了所有SAE中特征的最大CLAP分数分布。Essentia标签和Gemini概念的对齐分数分布有相当大的重叠,整体上没有单一策略完全占优。
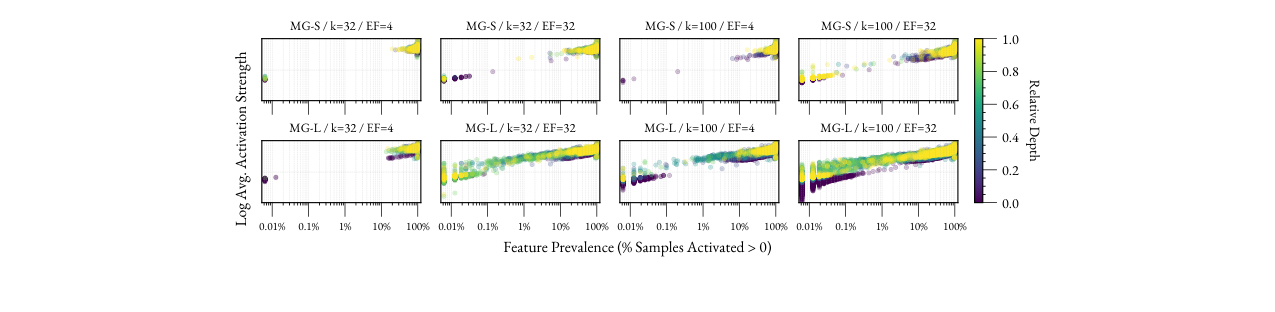
图3:不同层深和模型下,特征音频与自动生成标签的平均CLAP分数。图中显示,对于MGL,较深的层(相对深度较大)倾向于产生CLAP分数更高的特征。
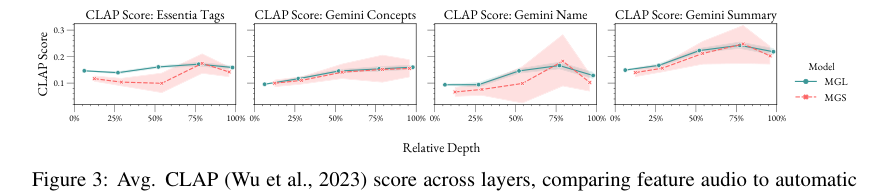
图4:跨所有SAE的最大CLAP分数分布(累积分布函数图)。图中显示Essentia标签在高分段(如>0.3)的累积占比略高于Gemini标签,反映了两种策略在置信度与覆盖范围上的权衡。
- 概念发现示例(图2): 论文展示了通过该方法发现的典型音乐概念,包括已知概念(如Taiko鼓、Hardstyle Techno、巴洛克羽管键琴、摇滚吉他独奏)和新兴概念(如电子哔哔声、单一乐器单音、振荡铃声、浪漫流行MIDI钢琴)。
图2:使用稀疏自编码器发现的概念示例图。左列为已知音乐概念,右列为新兴规律。每个概念通过几个代表性音频的语谱图展示其共同特征。
- 概念引导生成实验(表2): 在MGL的SAE(EF=32, k=100)上,对多个层(24, 36, 46)进行引导。结果显示,有15.3%至35.1% 的特征在引导后,其生成音频与特征Top-10样本的CLAP相似度相比基线有所提升。
| 模型 | EF | k | 层 | 引导成功率 |
|---|---|---|---|---|
| MGL | 32 | 100 | 24 | 96/408 (23.5%) |
| MGL | 32 | 100 | 36 | 46/131 (35.1%) |
| MGL | 32 | 100 | 46 | 27/177 (15.3%) |
| 表2:概念引导生成的成功比例(以CLAP分数提升为准)。 |
图5:概念引导生成示例图。对比了基线生成、目标特征的典型样本、以及引导后的生成结果(谱图),显示引导成功地将生成内容拉向目标概念(如“Synthwave”)。
⚖️ 评分理由
- 学术质量:5.5/7:创新性强,首次将SAE引入音频生成模型解释,方法论系统。技术正确性好,SAE训练、过滤、标注流程设计合理。实验充分性较好,覆盖了两个模型规模、多个层、多种SAE配置,并进行了人类评估。证据可信度较高,但自动化评估依赖CLAP等外部模型,且引导成功率偏低,部分结果(如层间差异)更多是相关性观察而非机制证明。
- 选题价值:1.5/2:前沿性高,是AI可解释性与AI音乐生成交叉的热点。潜在影响较大,对提升生成模型透明度、实现可控生成、甚至反哺音乐理论研究均有价值。应用空间明确,面向音乐制作、人机协作。读者相关性:对音频/音乐AI和可解释性研究的读者高度相关。
- 开源与复现加成:0.5/1:论文未明确提供代码仓库链接,但提到了项目网站(musicdiscovery.media.mit.edu)和使用的预训练模型(MusicGen, Essentia, CLAP, Gemini)。使用了公开数据集(MusicSet)。训练细节(如SAE的具体优化参数)不够完整,可能影响完全复现。