📄 Deep Learning with Learnable Product-Structured Activations
#神经网络架构 #隐式神经表示 #深度学习理论 #信号处理 #可解释AI
🔥 8.0/10 | 前10% | #神经网络架构 | #神经网络架构 | #隐式神经表示 #深度学习理论
学术质量 7.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Saanjali Maharaj(University of Toronto)
- 通讯作者:Prasanth B. Nair(University of Toronto)
- 作者列表:Saanjali Maharaj(University of Toronto)、Prasanth B. Nair(University of Toronto)
💡 毒舌点评
亮点在于LRNN架构将低秩函数分解思想巧妙地引入深度学习,其理论分析严谨(证明了通用逼近和维度诅咒缓解),并且实验设计得极为全面,从ImageNet图像到PDE求解,几乎“打穿”了隐式表示领域的主流基准。短板则是,尽管架构思想优美,但其每个“神经元”内部实际嵌套了一个小型MLP(用于参数化一元函数),这无疑显著增加了计算复杂度和训练时间,论文在性能与效率的权衡上讨论稍显不足,可能限制其在大规模实时应用中的部署。
🔗 开源详情
- 代码:论文明确提供了公开的代码仓库链接:https://github.com/dacelab/lrnn。
- 模型权重:论文中未提及公开预训练模型权重。
- 数据集:使用了公开的数据集(ImageNet, DIV2K, GTZAN, LibriSpeech等),但论文中未说明是否提供处理后的特定任务数据集。
- Demo:论文中未提及在线演示。
- 复现材料:论文提供了极其详尽的复现信息,包括:
- 所有实验的具体超参数设置(学习率、调度器、模型尺寸等)。
- 架构的实现细节(如组件MLP的结构、LayerNorm的使用、方差控制缩放)。
- 各类消融研究的设计和结果。
- 训练硬件信息(单张RTX 4090 GPU)。
- 论文中引用的开源项目:论文依赖并对比了多个开源基准模型,包括SIREN、SPDER、WIRE、Gaussian Activated Networks等的官方实现。其实现基于PyTorch框架。
📌 核心摘要
- 问题:现代神经网络受限于固定激活函数,难以自适应地捕捉任务特定的高阶交互结构,且在表示高频信号时存在频谱偏差。
- 方法核心:提出“深度低秩分离神经网络”(LRNN)。其核心是每个神经元使用一个可学习的乘积结构激活函数,即多个可学习的一元变换的乘积,而非传统的固定标量激活。
- 新意:与传统MLP和固定激活的INR方法相比,LRNN的激活函数是高度灵活且数据依赖的,能自然地通过乘法合成丰富的频谱成分。该架构是标准MLP的推广,并建立了与低秩函数分解的理论联系。
- 主要实验结果:LRNN在多个任务上达到SOTA。在图像表示上,对1000张ImageNet图像达到40dB PSNR的成功率为100%,远超SIREN(1.8%)和SPDER(26.4%)。在音频表示上,MSE比基线低3-11倍。在PDE求解上,用SIREN 1/8的参数量实现同等或更低误差。在稀疏视图CT重建中,获得最高PSNR(29.13 dB)和SSIM(0.7455),且无伪影。
- 实际意义:提供了一种通用、表达能力强且理论清晰的神经网络构建模块,能显著提升信号表示、科学计算和成像任务的性能,有助于减少医疗CT的辐射剂量。
- 主要局限性:其反向传播需要存储中间乘积项,导致内存占用高于标准MLP;架构增加了每层的计算复杂度;虽然提供了消融实验,但对于如何在不同任务中最优地设置超参数(如分离秩r和投影宽度\(\bar{d}\))的指导不够充分。
🏗️ 模型架构
LRNN(Low-Rank Separated Neural Network)是一种对多层感知机(MLP)的推广。其核心创新在于用可学习的乘积结构激活函数替代了固定激活函数。
整体流程: 输入数据 \(x \in \mathbb{R}^d\) 依次通过多个LRNN隐藏层,最后通过一个线性输出层得到预测 \(\hat{y}\)。
单层LRNN结构: 以第 \(k\) 层为例,该层有 \(r_k\) 个神经元。对于第 \(\ell\) 个神经元:
- 线性投影:将上一层的输出 \(\phi^{(k-1)}\) 投影到一个 \(\bar{d}_k\) 维的向量 \(z_{\ell,(k)} = W_{\ell,(k)} \phi^{(k-1)} + b_{\ell,(k)}\)。
- 乘积结构激活函数:该神经元的输出为一个标量,计算为:
\[
\phi_\ell^{(k)}(z_{\ell,(k)}) = \prod_{j=1}^{\bar{d}_k} \left(1 + \gamma \, g_{\ell,j}^{(k)}\left(z_{\ell,(k),j}\right)\right)
\]
其中:
- \(\gamma = \bar{d}_k^{-1/2}\) 是一个缩放因子,用于控制方差(类似Xavier初始化)。
- \(g_{\ell,j}^{(k)}: \mathbb{R} \rightarrow \mathbb{R}\) 是可学习的一元函数。在实际实现中,每个 \(g_{\ell,j}^{(k)}\) 通常由一个小型MLP(例如一层隐藏层)来参数化。这个MLP的输入是标量 \(z_{\ell,(k),j}\),其第一层可以使用周期性激活(如SIREN的sin或SPDER的sin(x)√|x|)以捕捉高频信息。
- 项 \((1 + \gamma g_{\ell,j}^{(k)}(...))\) 引入了“自动相关性确定”机制:如果某个特征不重要,其对应的 \(g_{\ell,j}^{(k)}\) 可以学习到接近0,从而使整个乘积因子接近1。
- LayerNorm:在实现中,对所有 \(r_k\) 个神经元的输出组成的向量 \(\phi^{(k)}\) 应用层归一化(LayerNorm),以稳定深层网络的训练。这是一个关键技巧,因为乘积结构的统计特性比加法激活更复杂。
深度LRNN: 通过堆叠上述LRNN层构成深层网络。最终输出层是线性变换:\(\hat{y} = S_{out} \phi^{(L)}\)。
关键设计选择:
- 乘积结构 vs. 加法结构:标准MLP是加法组合(\(\sigma(w^Tx+b)\)),而LRNN在神经元内部是乘法组合。这使得单个LRNN神经元就能生成基频的和频、差频等丰富组合(如Lemma 2所述),具有更强的频谱表达能力。
- 可学习激活 vs. 固定激活:每个 \(g_{\ell,j}^{(k)}\) 都是可学习的,使得激活函数能自适应于数据分布,理论上比固定函数(如ReLU、sin)更具表达力。
- 参数化一元函数:将复杂的多元激活分解为多个可学习一元函数的乘积,这借鉴了低秩函数分解的思想,旨在以紧凑的参数量逼近复杂函数。
架构图:
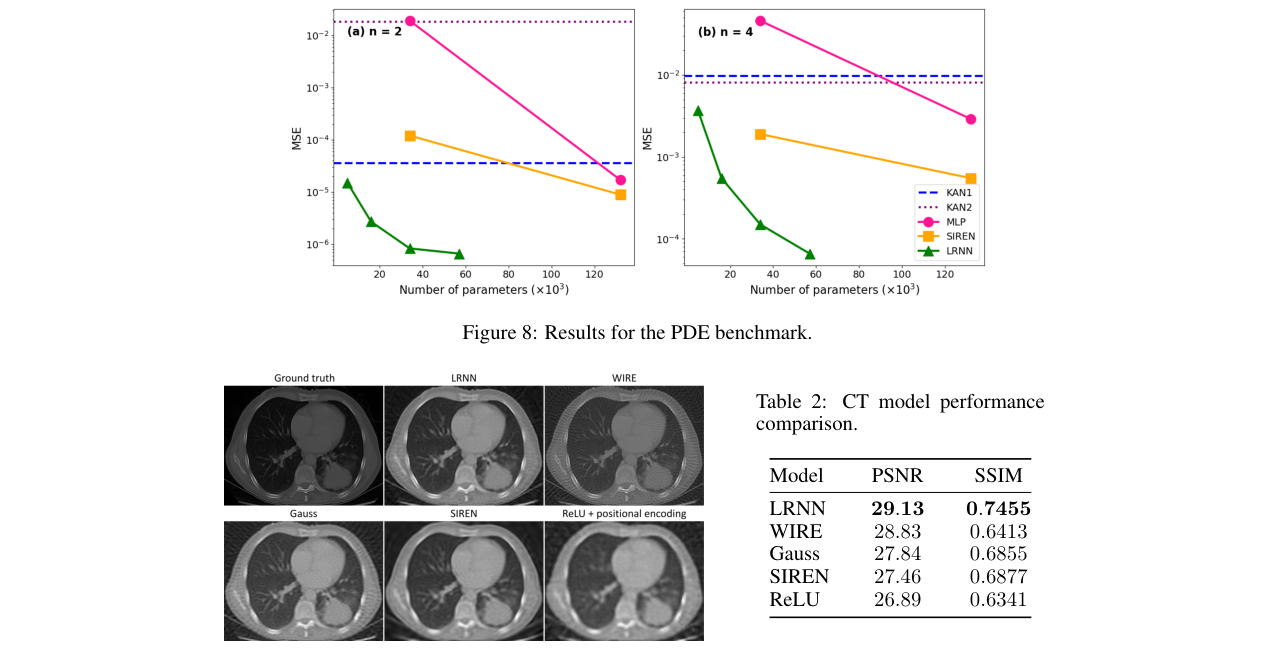
图10:深度LRNN架构图。展示了从输入x开始,依次经过多个LRNN隐藏层(每个层由多个具有乘积结构激活函数的神经元构成),最终通过线性层输出y的完整数据流。
💡 核心创新点
- 可学习的乘积结构激活函数:这是最核心的创新。不同于传统固定标量激活或KANs在边上学习激活,LRNN在每个神经元上学习一个由多个一元函数乘积构成的、高维到一维的激活函数。这使得神经元能高效建模变量间的乘性交互。
- 统一理论框架与强理论保证:论文不仅提出了架构,还提供了坚实的理论分析:证明了LRNN具有通用逼近能力(Theorem 1);证明了对具有低阶交互结构的函数(ANOVA分解衰减),LRNN能以多项式复杂度逼近,缓解维度诅咒(Theorem 2);分析了其乘积结构带来的组合频率合成能力(Lemma 2),能自适应控制频谱偏差。
- 即插即用且性能显著的通用架构:LRNN可作为MLP的直接替代品。通过在多个差异极大的任务(图像、音频、PDE、CT)上取得一致且显著的性能提升(如在ImageNet图像上PSNR成功率从基线的~20-70%提升至100%),证明了其作为通用构建模块的强大性和实用性。
🔬 细节详述
- 训练数据:论文在多个独立任务上进行了评估:
- 图像表示:灰度图(Cameraman 256x256),彩色图(Retina 256x256),以及ImageNet数据集的1000张图像(均下采样至256x256)。还使用DIV2K数据集进行超分辨率演示。
- 音频表示:四个音频片段:古典音乐(bach)、男声朗读(counting)、雷鬼音乐(reggae)、女声朗读(reading)。
- PDE求解:高频泊松方程基准测试(频率参数n=2, 4)。
- CT重建:256x256的胸腔CT图像。
- 损失函数:根据任务使用不同的损失函数。图像和音频表示任务通常使用均方误差(MSE)损失。PDE求解使用基于物理的MSE损失(在网格点上)。分类任务使用交叉熵损失。
- 训练策略:
- 优化器:统一使用Adam优化器。
- 学习率:基线模型(SIREN, SPDER)使用论文推荐的 \(1 \times 10^{-4}\);LRNN使用 \(1 \times 10^{-3}\)。
- 调度器:基线模型无调度器;LRNN使用StepLR调度器(如步长100,衰减因子0.8或0.9)。
- 训练步数:图像和音频表示任务通常训练1000步。
- 批量大小:对于图像表示,可能使用全图像作为一个批次(对于小图像),或使用像素子集。
- 关键超参数:
- 分离秩 (r):控制模型的表达能力,通常设为106左右。
- 投影宽度 (\(\bar{d}\)):每个神经元内部乘积的维度,通常设为16。
- 组件MLP结构:用于参数化 \(g_{\ell,j}^{(k)}\) 的小MLP通常包含1层隐藏层,宽度为1,第一层激活使用SIREN的sin或SPDER的sin(x)√|x|,并设置特征频率 \(\omega_0=30\)。
- 网络深度:LRNN模型通常使用2层隐藏层,就能超越3-5层的基线模型。
- 训练硬件:所有实验在单张NVIDIA 4090 GPU上完成。
- 推理细节:对于INR任务,训练好的模型可以直接在连续坐标上推理,实现任意分辨率的上采样(如DIV2K实验所示)。
- 正则化与稳定技巧:核心技巧包括:1) 方差控制的缩放因子 \(\gamma = \bar{d}^{-1/2}\);2) 在LRNN层输出后应用LayerNorm,这对稳定乘积结构的训练至关重要(消融实验见表3);3) 在一元函数MLP中使用周期性激活以减少频谱偏差。
📊 实验结果
论文通过大量实验验证了LRNN的有效性,以下列出关键结果。
- 图像表示任务
Cameraman图像(~197k参数):LRNN-SPDER达到 107.9 dB PSNR,SPDER为49.0 dB,SIREN为35.3 dB。
ImageNet大规模鲁棒性研究(~200k参数,1000图像,3000次运行):
模型 PSNR目标: 33dB 成功率 / 耗时 PSNR目标: 35dB 成功率 / 耗时 PSNR目标: 40dB 成功率 / 耗时 LRNN-SPDER 100% / 较快 100% / 较快 100% / 较快 SPDER ~95% ~80% 26.4% SIREN ~90% ~70% 1.8% 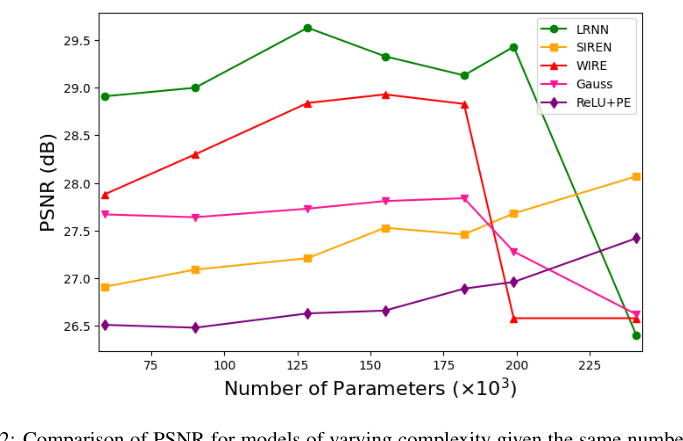
图4:在1000张ImageNet图像上,达到不同PSNR目标的成功率对比。LRNN在最具挑战性的40dB目标上达到100%成功率,而基线方法失败率很高。
音频表示任务(4个数据集,10次运行取平均)
LRNN-SPDER在所有音频片段上均实现了显著更低的MSE(3-11倍)和更高的频谱相似度(ρAG)。方法 MSE Loss (×10⁻⁴) bach MSE Loss counting MSE Loss reggae MSE Loss reading SIREN 1.21(0.28) 2.77(0.56) 21.5(6.3) 9.98(1.57) SPDER 1.12(0.05) 2.29(0.55) 24.8(7.7) 8.88(2.45) LRNN-SPDER 0.10(0.01) 0.72(0.03) 7.93(0.11) 1.86(0.30) PDE求解任务
图8:不同模型在高频泊松PDE上的MSE。LRNN(约16k参数)的误差可与参数量多8倍的SIREN(约132k参数)相当甚至更低。对于n=4,57k参数的LRNN比132k参数的SIREN误差低近一个数量级。所有测试中,LRNN均远优于KANs(水平线)。
稀疏视图CT重建任务
LRNN在PSNR和SSIM上均取得最佳,且定性结果显示其重建图像更清晰、无伪影。模型 PSNR (dB) SSIM LRNN 29.13 0.7455 WIRE 28.83 0.6413 Gauss 27.84 0.6855 SIREN 27.46 0.6877 ReLU+PE 26.89 0.6341 
图9:CT重建结果对比。LRNN的输出最接近真实图像(Ground Truth),而SIREN和ReLU+PE的输出较模糊。
⚖️ 评分理由
- 学术质量:7.0/7:创新性(提出LRNN这一新颖架构)突出;技术正确性(理论分析严谨,实验设计合理)高;实验充分性(覆盖四大类任务,与众多强基线对比,包含消融研究)强;证据可信度(数字结果显著,定性可视化支持结论)高。
- 选题价值:1.5/2:研究神经网络基础架构具有很高的前沿性;LRNN作为通用构建模块,对提升信号处理、科学计算、医学成像等多个领域的模型性能具有直接影响和广泛应用潜力;与音频/语音读者的潜在相关性在于其强大的信号表示能力可用于音频超分辨率、特征提取等。
- 开源与复现加成:0.5/1:提供了可访问的GitHub代码仓库链接,并在论文和附录中给出了非常详细的实现细节(包括超参数、层归一化技巧、组件MLP结构),大大降低了复现难度。扣分点在于未提供预训练模型和处理好的数据集。