📄 Data-Centric Lessons To Improve Speech-Language Pretraining
#语音问答 #预训练 #语音大模型 #多模态模型 #数据中心
🔥 8.0/10 | 前25% | #语音问答 | #预训练 | #语音大模型 #多模态模型
学术质量 6.2/7 | 选题价值 1.8/2 | 复现加成 0.2 | 置信度 高
👥 作者与机构
- 第一作者:Vishaal Udandarao (Apple, University of Cambridge, University of Tübingen)
- 通讯作者:未明确说明
- 作者列表:Vishaal Udandarao (Apple, University of Cambridge, University of Tübingen), Zhiyun Lu (Apple), Xuankai Chang (Apple), Yongqiang Wang (Apple), Albin Madappally Jose (Apple), Fartash Faghri (Apple), Joshua P Gardner (Apple), Chung-Cheng Chiu (Apple)
💡 毒舌点评
亮点:论文的实验设计堪称“数据中心”研究范式的典范,通过精心设计的控制变量消融实验(如仅改变交错粒度或采样策略),清晰地量化了每个数据处理步骤的独立贡献,结论扎实可信。短板:所谓的“合成数据集”构建方法(从文本生成问答对再用TTS合成语音)相对基础,未探索利用更先进的端到端语音生成模型或更强的指令遵循能力,其提升可能受限于TTS的自然度和多样性。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:论文提及训练了SpeLangy模型,但未提及将公开其预训练权重。
- 数据集:论文详细描述了Web-crawl、Krist和Quest数据集的构建方法,但未提及公开原始音频或构建后的数据集。伦理声明部分提及数据来源于公开播客。
- Demo:论文中未提及在线演示。
- 复现材料:附录中提供了大量细节,包括数据预处理流程图、合成数据构建提示、训练超参数、评估数据集细节、污染分析代码等,复现信息非常详尽。
- 论文中引用的开源项目:使用了MeloTTS进行语音合成,Whisper和Parakeet进行转录,pyannote进行说话人日志,SentencePiece进行分词,以及引用了多个开源SpeechLM和文本模型作为基线。
📌 核心摘要
- 问题:当前语音-语言模型(SpeechLMs)在预训练数据的处理、构建和交错方式上缺乏系统性的控制研究,导致性能提升的关键因素不明确。
- 方法核心:本文对语音-语言预训练的数据进行了系统性的“数据中心”研究,聚焦三个关键问题:(1)如何将原始网页爬取音频处理成交错的语音-文本数据;(2)如何利用纯文本数据集构建合成语音-文本数据以增强网络爬取数据;(3)如何在训练中交错语音和文本片段。
- 新意:这是首个在受控设置下系统比较不同语音-语言数据策略的工作。与以往仅描述建模选择的工作不同,本文通过严谨的消融实验,分离并量化了数据处理、合成和采样策略的独立影响。
- 主要结果:基于洞察,作者训练了一个3.8B参数的模型SpeLangy,在平均语音问答(SQA)性能上比参数量高达其3倍的模型(如Kimi-Audio, Qwen-2-Audio)高出10.2%绝对值。关键消融实验结果见下表:
| 数据策略/方法 | 文本理解 (CoreEN/MMLU) | SQA (SWQ/STQ/SLQ) 平均准确率 |
|---|---|---|
| 基线 (粗粒度交错) | 60.4 / 63.9 | 37.6% |
| + 细粒度交错 | 60.4 / 64.1 | 40.7% (+3.1%) |
| + 确定性采样 | 60.1 / 65.2 | 42.4% (+4.8%) |
| + 混合Quest合成数据 | 60.4 / 66.2 | 47.9% (+10.3%) |
图1展示了SpeLangy模型(3.8B参数)在平均SQA准确率上超越了参数量更大的竞争对手(Voxtral-mini, GLM-4-Voice, Qwen-2-Audio等)。
- 实际意义:为SpeechLM社区提供了经过验证的数据处理和构建的最佳实践,强调了有效数据整理在提升模型性能中的核心作用,能指导未来更高效、更强模型的开发。
- 主要局限性:研究主要围绕单一的SQA任务和特定的基准测试展开;合成数据方法依赖于TTS模型,其质量可能成为瓶颈;论文未公开模型权重和代码,限制了完全复现。
🏗️ 模型架构
论文采用的架构是标准的“语音编码器 + 连接器 + 大语言模型”范式,其主要创新和重点在于数据处理流程。
- 整体输入输出流程:输入为交织的语音-文本序列。语音部分经过编码器和量化器变为离散的语音标记,文本部分为文本标记。模型在下一个标记预测任务上进行训练,损失在语音和文本标记上计算(或在理解专用设置中对语音标记进行掩码)。
- 主要组件:
- 语音分词器:包含一个约1B参数的Conformer编码器,进行8倍下采样,后接一个有限标量量化器(FSQ)。输出离散的语音标记,每个标记代表80ms音频(12.5Hz)。
- 大语言模型:初始化自一个预训练的2.8B参数稠密语言模型,上下文长度16,384个标记。词汇表被扩展以包含语音标记,新嵌入使用Xavier正态初始化。
- 数据处理流程架构:这是本文的核心。下图详细展示了如何将原始网页爬取音频转换为可训练的交错数据。

图9(论文中标记为图9)展示了完整的预处理流程:从原始音频开始,经过说话人日志、语言识别、使用ROVER进行转录本集成与过滤,最终进行交错分块。
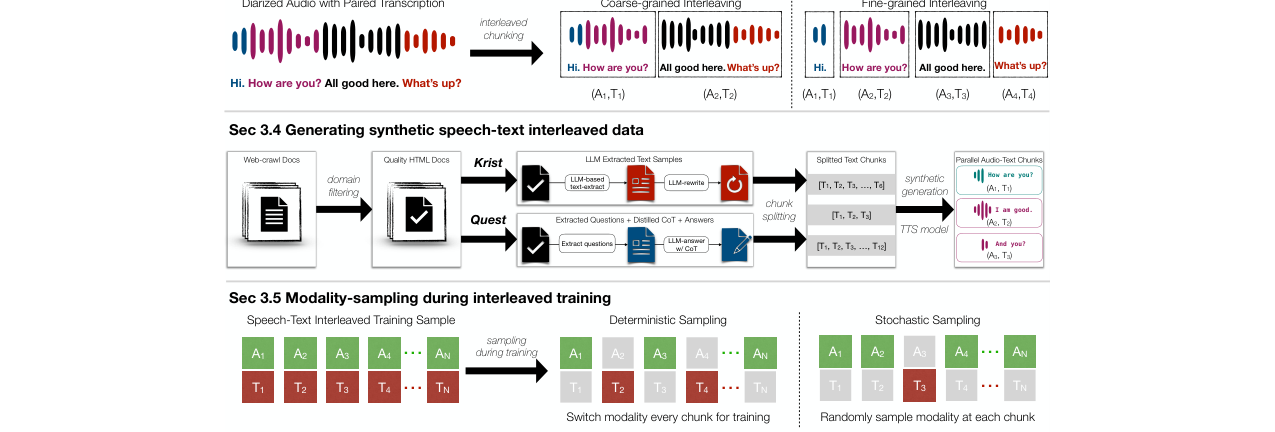
图2(论文中标记为图2)展示了三个研究问题的具体方法:(A)粗粒度与细粒度交错策略;(B)从文本数据集构建合成语音数据集Krist和Quest的流程;(C)交错训练中的随机与确定性模态采样方案。
- 关键设计选择:细粒度交错(保持短片段)优于粗粒度(合并长片段),因为它提升了模态对齐。确定性交替采样优于随机采样,因为它增加了训练中的模态切换次数,促进了跨模态学习。
💡 核心创新点
- 系统性的数据消融研究范式:首次在受控条件下(单一交错预训练目标,固定模型架构)对SpeechLM数据处理的三个关键环节(原始音频处理、合成数据构建、训练采样)进行定量消融,填补了该领域的方法论空白。
- “细粒度交错”原则:发现保持短的、句级的语音-文本块(平均5.2秒)进行交错训练,相比合并长块(平均19.2秒),能将SQA性能提升3.1%。这挑战了先前工作中合并说话人片段的默认做法。
- 合成数据的有效利用策略:证明了从高质量文本语料库(通过领域过滤和LLM处理)生成的“知识丰富型”(Krist)和“问答型”(Quest)合成语音数据,能有效补充和提升网络爬取数据。Quest格式尤其有效,使平均SQA提升7.2%。
- “确定性模态采样”策略:提出在交错训练中,确定性地交替使用语音和文本块(A1, T2, A3, T4…),相较于随机采样,能显著提升SQA性能(+1%),原因在于最大化了训练序列中的模态切换次数。
🔬 细节详述
- 训练数据:
- 网络爬取音频:超过1000万小时原始音频,主要来自播客、访谈、独白。经过说话人日志、语言过滤、转录本集成(使用Whisper、SIRI、Parakeet的ROVER集成)和过滤后,处理成交错数据。最终使用约8.03M小时,约361.3B语音标记。
- 合成数据集:
- Krist:从经过领域过滤的网页文档中,使用GPT-4o-mini提取并轻度重写文本,用Melo-TTS为每个句子分块合成语音(使��5种不同口音)。规模约4.72M小时,约212.4B语音标记。
- Quest:从同一文档库中挖掘问题,用GPT-4o验证问题有效性并生成带思维链的回答,同样分块合成语音。规模约0.86M小时,约38B语音标记。
- 文本数据:使用一个约2.2T标记的文本继续预训练数据集,以维持基础语言能力。训练混合比例:60%文本,40%语音-文本。
- 损失函数:标准的下一个标记预测损失,在语音和文本标记上计算。在“仅理解”设置中,对语音标记进行损失掩码。
- 训练策略:
- 全局批次大小:512
- 打包序列长度:16,384个标记
- 训练步数:200k步(消融实验),1.67T标记(SpeLangy最终训练)
- 优化器:标准设置(具体未说明),解耦权重衰减。
- 仅训练语言模型部分,语音分词器保持冻结。
- 关键超参数:模型总参数约3.8B(1B语音编码器 + 2.8B语言模型)。语音标记率为12.5Hz(每标记80ms)。
- 训练硬件:未明确说明,但根据规模和细节描述,推测使用了大规模GPU/TPU集群。
- 推理细节:评估使用多选题格式,基于对数似然评估选择正确选项。
- 正则化:未特别说明,采用标准训练技巧。
📊 实验结果
主要结果(语音问答 S→T):在三个基准测试上的平均准确率对比如下表:
| 模型 | 参数量 | SWQ | STQ | SLQ | 平均 |
|---|---|---|---|---|---|
| Kimi-Audio | 10.5B | 44.0 | 33.8 | 47.0 | 41.6 |
| Qwen-Audio | 8.4B | 45.7 | 30.3 | 46.0 | 40.7 |
| Qwen-2-Audio | 8.4B | 45.7 | 33.4 | 47.0 | 42.0 |
| SpeLangy (Ours) | 3.8B | 45.7 | 44.6 | 65.0 | 51.8 |
| Voxtral-mini (SFT) | 4.7B | 41.6 | 46.6 | 65.3 | 51.2 |
| GLM-4-Voice (SFT) | 9.9B | 43.3 | 52.4 | 64.7 | 53.4 |
关键消融实验结果:展示了每个数据处理干预的累积收益(平均SQA准确率)。
- 基线(粗交错):37.6%
- 细粒度交错:40.7% (+3.1%)
- 细粒度 + 确定性采样:42.4% (+1.7%)
- 细粒度 + 确定性采样 + 混合Quest数据:47.9% (+5.5%)
文本理解能力保持:SpeLangy在核心文本理解基准(CoreEN, MMLU, GSM8k, HumanEval)上与同规模甚至更大规模的纯文本模型(Gemma-2/3, Qwen-2.5)具有竞争力,证明语音预训练未损害语言能力。
模态对齐分析:下图显示了不同数据策略下,文本条件与音频条件输出分布之间的Reverse KL散度。
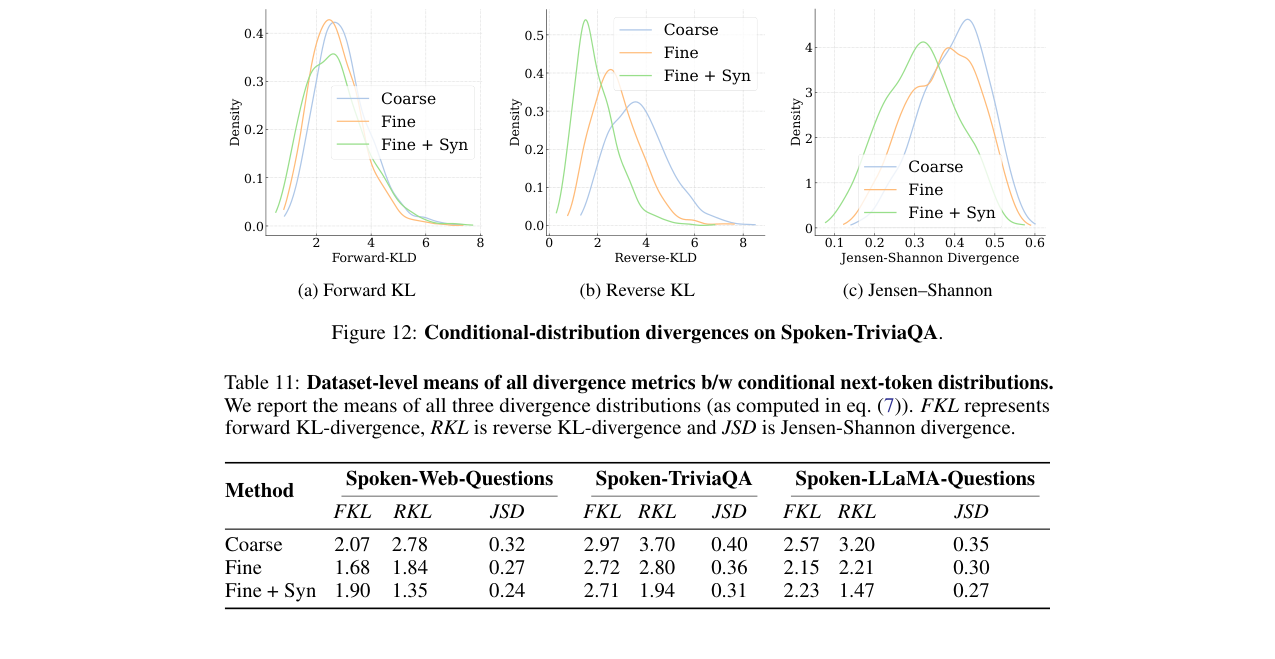
图5(论文中标记为图5)显示,细粒度交错和合成数据的引入显著降低了文本与语音模态输出分布之间的KL散度(从3.20降至1.47),表明模态对齐得到改善。
数据集主题分析:下图对比了网络爬取数据和合成数据在不同主题领域的分布。

图6(论文中标记为图6)表明,网络爬取数据在娱乐、体育等领域偏斜严重,而合成数据(Krist, Quest)在科学、健康、教育、金融等知识密集型领域提供了更好的覆盖,从而缩小了训练数据与评估数据集之间的分布差距。
测试集污染分析:下图展示了污染检测结果及其对性能的统计影响。

图7(论文中标记为图7)显示,合成数据集造成的测试集污染比例较低(SWQ 0.4%, STQ 2.5%, SLQ 7.7%)。
图8(论文中标记为图8)的统计检验表明,在STQ和SWQ上,污染对性能提升没有显著贡献;在SLQ上影响微小(<2.1%)且不显著,证明性能提升主要来自数据策略而非过拟合。
⚖️ 评分理由
- 学术质量:6.2/7 - 实验设计严谨,控制变量得当,消融实验清晰揭示了每个数据策略的贡献,结果可信。主要创新在于系统性的数据方法论和实证发现,而非模型架构的根本性革新。
- 选题价值:1.8/2 - 直击SpeechLM发展的核心瓶颈——数据处理方法论。提出的问题和验证的解决方案对指导社区高效构建高质量训练数据具有很高的实践价值,影响直接。
- 开源与复现加成:0.2/1 - 论文提供了详尽的数据处理流程、合成数据方法、训练配置,复现指南性强。但扣分是因为未提供代码和预训练模型权重,降低了完全复现的便利性。