📄 Continuous Audio Language Models
#语音合成 #音乐生成 #自回归模型 #一致性模型 #流匹配
✅ 7.0/10 | 前25% | #语音合成 | #自回归模型 | #音乐生成 #一致性模型
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 -0.5 | 置信度 高
👥 作者与机构
- 第一作者:Simon Rouard(Kyutai; UMR STMS, IRCAM-CNRS, Sorbonne Univ.)
- 通讯作者:未明确说明(Alexandre Défossez 提供了邮箱,且为资深作者,通常为通讯作者)
- 作者列表:
- Simon Rouard(Kyutai; UMR STMS, IRCAM-CNRS, Sorbonne Univ.)
- Manu Orsini(Kyutai)
- Axel Roebel(UMR STMS, IRCAM-CNRS, Sorbonne Univ.)
- Neil Zeghidour(Kyutai)
- Alexandre Défossez(Kyutai)
💡 毒舌点评
论文核心亮点在于其精巧的“双头”架构设计——用带噪声的长上下文Transformer保证生成稳定性,用干净的短上下文Transformer保留细节,并用高效的一致性模型头取代传统的RQ-Transformer,在多个任务上实现了质量与速度的双赢。然而,其宣称的“超越SOTA”在音乐生成等任务上部分依赖于使用自家训练的数据集重新训练的基线模型,且最关键的音乐数据集未开源,这使得最令人兴奋的实验结果难以被独立社区完全验证和比较,削弱了其作为通用方法的说服力。
🔗 开源详情
- 代码:论文提及了Pocket TTS的代码仓库:
github.com/kyutai-labs/pocket-tts。对于CALM主框架的开源情况未在主文明确说明。 - 模型权重:Pocket TTS模型权重计划通过上述GitHub仓库开源。
- 数据集:论文使用的主要音乐数据集(LAION-Disco-12M子集)未公开。语音和TTS数据集部分来源公开,但完整混合数据集的获取方式未详细说明。
- Demo:提供了示例页面:
iclr-continuous-audio-language-models.github.io。 - 复现材料:提供了详细的超参数设置(表14, 15)、损失函数公式、架构描述和技术报告(
kyutai.org/pocket-tts-technical-report)。 - 论文中引用的开源项目:依赖的开源项目包括:Mimi (Défossez et al., 2024b), Helium-1 (Kyutai, 2025), SentencePiece, Whisper, WavLM, Mistral 7B, CLAP, fairseq等。
📌 核心摘要
- 问题:当前主流的音频语言模型(ALM)依赖离散化的音频token(如RVQ),这造成了音频质量与计算成本之间的权衡。提高质量需要增加token数量(更高码率),从而导致模型计算负担加重,难以在边缘设备上实现实时高质量生成。
- 方法:提出连续音频语言模型(CALM),在VAE的连续隐空间中直接建模,避免了量化损失。其架构由三部分组成:1)一个因果Transformer骨干网络,处理长程依赖,并在训练时对输入施加噪声以抑制推理时的误差累积;2)一个轻量级短上下文Transformer,提供局部、干净的细节信息;3)一个基于一致性模型的小型MLP头部,用于快速生成下一个连续帧。
- 创新:相比先前基于扩散的MAR方法,CALM引入了噪声注入的长上下文与干净短上下文结合的双Transformer设计,并用一致性模型(Consistency Model)取代了扩散头,实现了1步快速采样。此外,还提出了高斯温度采样、潜在分类器自由引导(Latent CFG)和潜在蒸馏等技巧,进一步提升质量和效率。
- 结果:在语音续写、文本转语音(TTS)和音乐续写三个任务上进行了评估。实验表明,CALM在多个指标上优于强基线。例如,在语音续写中,1步一致性模型在声学质量MOS(3.45)和意义性Elo(2023)上优于8-RVQ的RQ-Transformer基线(2.75,1870),且采样头速度快12.3倍。在音乐续写中,1步一致性模型FAD(0.83)优于32-RVQ基线(1.06),整体速度快2.2倍。最终,通过蒸馏得到的100M参数Pocket TTS模型可在笔记本CPU上实时运行。
- 意义:为高质量、高效率的音频生成提供了新的范式,摆脱了对离散token的依赖。特别是Pocket TTS证明了在资源受限设备上实现高性能TTS的可行性,具有广泛的应用前景。
- 局限:论文中的部分最先进对比(如TTS任务中的F5-TTS, DiTAR)并非在同一数据集上复现的结果;音乐生成所用的核心数据集未公开;论文主要关注生成质量与效率,对于模型的可控性、编辑能力等探讨较少。
🏗️ 模型架构
CALM的整体架构如图1所示,主要包含三个核心组件,数据流如下:输入音频序列被预训练的VAE编码器转换为连续隐向量序列。在训练阶段,骨干Transformer处理的是被噪声污染的隐向量历史序列,以增强鲁棒性。短上下文Transformer则处理最近的几个干净隐向量。两者的输出相加,形成条件信号。这个条件信号被送入一致性模型头部,该头部是一个小型MLP网络,负责在给定当前噪声样本和条件信号的情况下,预测下一个干净的隐向量。在推理时,头部仅需一步即可从随机噪声生成下一个隐向量,最后由VAE解码器重建音频。
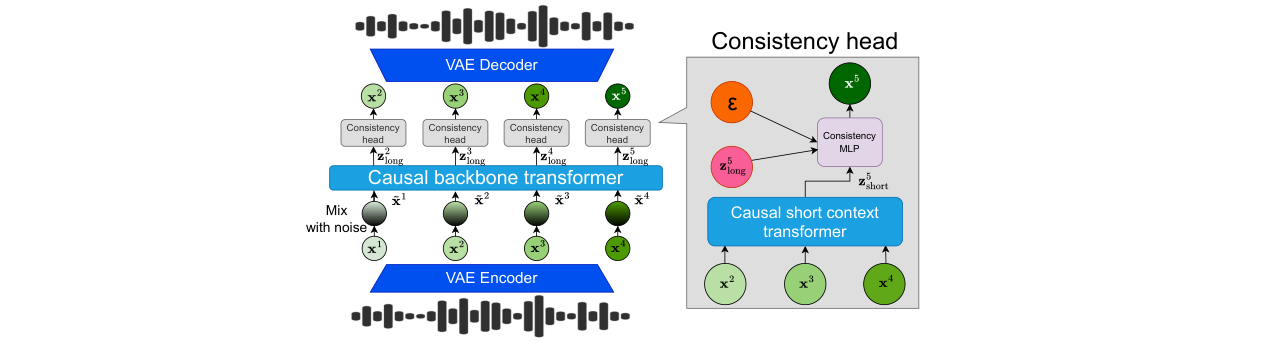
图1:CALM模型架构概览。展示了训练阶段的数据流:隐向量经过噪声混合后输入“Causal backbone transformer”,同时最近的干净隐向量输入“Causal short context transformer”。两者输出相加,条件化“Consistency head”(一个MLP)。推理时,头部直接从噪声样本ε生成下一个隐向量。
- 因果骨干Transformer (T_long):这是一个大型Transformer,负责建模长程依赖关系。其关键创新在于训练时输入噪声:对于历史序列
(x1, ..., x_{s-1}),每个向量x_i会与噪声ε_i按比例混合(~x_i = √k_i ε_i + √(1-k_i) x_i)。这迫使模型学习更鲁棒的表示,避免推理时因错误累积而快速退化。 - 短上下文Transformer (T_short):这是一个更小、更轻量的因果Transformer,仅关注最近的K个干净隐向量(实验中K=10,约0.4秒)。其作用是为一致性头部提供局部的、高分辨率的细节信息,弥补骨干Transformer因噪声注入而可能丢失的精细结构。
- 一致性模型头部 (f_φ):这是一个小型MLP网络,其参数量远小于骨干Transformer。它以骨干和短上下文Transformer输出的和(
Z_s = z_s^long + z_s^short)作为条件,执行1步一致性建模。训练时使用特定的连续时间一致性损失;推理时,只需从标准高斯分布采样一个噪声ε,令t=1,即可得到预测的下一隐向量~x_s = f_φ(ε, t=1, Z_s)。这极大地加速了采样过程。 - 关键设计选择动机:这种双Transformer设计解决了先前连续自回归模型(如MAR)的两个核心痛点:1) 骨干Transformer的噪声注入解决了推理时的误差累积和模式坍塌问题;2) 短上下文Transformer弥补了噪声注入造成的细节损失,确保了生成保真度。一致性模型头部则直接针对采样速度瓶颈。
💡 核心创新点
- 带噪声注入的骨干与干净短上下文结合:这是架构上最核心的创新。通过将噪声注入的长上下文与干净的短上下文相结合,CALM在训练稳定性和生成细节保真度之间取得了优异的平衡。消融实验(表6)显示,移除任何一部分都会导致性能显著下降。
- 一致性模型取代扩散/流匹配头:在连续自回归生成框架中,首次系统性地应用一致性模型(和LSD)作为生成头部。这将采样步数从数百步(扩散)或十数步(流匹配)减少到1步或几步,在质量可比的情况下,采样速度提升高达20倍(表8),使得实时流式生成成为可能。
- 潜在分类器自由引导(Latent CFG)与潜在蒸馏:提出了在骨干Transformer的隐变量空间(而非输出概率空间)应用CFG的方法。进而,通过知识蒸馏,将应用了CFG的教师模型(双份计算)蒸馏到一个更小的学生模型中,使得学生模型在单次前向传播中就能获得CFG的效果,推理时计算量减半。
- 高斯温度采样启发式:为连续模型提出了类似离散模型中温度采样的方法,通过调节输入噪声的方差来控制生成多样性和质量之间的权衡,使得连续模型的生成行为更易于调控。
🔬 细节详述
- 训练数据:
- 语音续写:使用法语和英语语音数据,数据集细节未在主文完全说明,但提到基于Helium-1模型和先前工作。
- 文本转语音(TTS):使用88k小时混合数据集,包括AMI, EARNINGS22, GIGASpeech, SPGISpeech, TED-LIUM, VoxPopuli, LibriHeavy, Emilia(详见附录D)。
- 音乐续写/生成:使用从LAION-Disco-12M中随机选取的约40万首歌曲(约20k小时,32kHz单声道)。数据集未公开。
- 损失函数:
- CALM训练损失:核心是连续时间一致性损失(公式3),结合了自适应权重函数
w_ψ(t)。其本质是让模型学习概率流ODE的轨迹。 - VAE训练损失:包括重建损失
L_t,L_f、对抗损失L_adv、特征匹配损失L_feat、KL正则化L_KL(权重0.01),对于语音VAE还有知识蒸馏损失L_distill(教师为WavLM)。 - LSD损失(用于TTS):结合了流匹配损失
L_FM(公式5)和Lagrangian自蒸馏损失L_LSD(公式6),在实验中比标准一致性损失效果更好(表10)。
- CALM训练损失:核心是连续时间一致性损失(公式3),结合了自适应权重函数
- 训练策略:
- 优化器:AdamW (β1=0.9, β2=0.95)。
- 学习率调度:余弦退火。
- 学习率:骨干Transformer为1e-4(音乐)或5e-5(语音续写)或1e-4(TTS)。
- 批大小:48-144不等(见表15)。
- Head Batch Multiplier:对于每个序列的骨干输出
z_s^long,会独立采样N个(实验中N=8)不同的(t, ε)进行头部损失计算,以提高训练效率。 - 训练步数:500k步(音乐)、150k步(语音续写)、400k步(TTS)。
- 关键超参数:
- 骨干Transformer:维度1536-2560,层数24-48,参数量300M-2.2B。
- 一致性头部MLP:维度512-3072,层数6-12,参数量10M-601M。
- 短上下文Transformer(仅音乐):维度1536,4层,上下文长度10,参数113M。
- 训练硬件:使用8到48块NVIDIA H100 GPU。
- 推理细节:
- 采样:一致性模型支持1步或少数几步采样。实验中常用1步或4步。
- 温度:通过将输入噪声的标准差乘以
√τ来实现,例如语音续写中τ=0.8。 - 流式设置:论文未明确说明流式推理的实现细节,但架构本身是因果的,且短上下文设计有利于低延迟生成。
- 正则化技巧:噪声注入是主要的稳定训练技巧;VAE中的KL正则化(权重0.01)确保了隐空间的平滑性。
📊 实验结果
主要实验结果对比表格:
表2:语音续写模型对比(30秒生成)
| 模型类型 | 采样温度 | 总体加速比 | 采样头加速比 | 采样头耗时占比 | PPX (↓) | VERT (↓) | 声学质量MOS (↑) | 意义性Elo (↑) | 排名 (↓) |
|---|---|---|---|---|---|---|---|---|---|
| 参考 | – | – | – | – | 20.2 | 25.2 | 4.02 ± 0.11 | 2180 ± 30 | – |
| RQ-transformer 8 RVQ | 1.0 | ×1.0 | ×1.0 | 26.7% | 52.4 | 36.3 | 2.42 ± 0.12 | 1841 ± 25 | 4 |
| RQ-transformer 8 RVQ | 0.8 | ×1.0 | ×1.0 | 26.7% | 26.8 | 33.1 | 2.75 ± 0.14 | 1870 ± 30 | 3 |
| CALM - Consistency - 1 step | 1.0 | ×1.3 | ×12.3 | 2.9% | 42.9 | 34.3 | 2.82 ± 0.13 | 1947 ± 28 | 2 |
| CALM - Consistency - 1 step | 0.8 | ×1.3 | ×12.3 | 2.9% | 23.8 | 31.2 | 3.45 ± 0.14 | 2023 ± 27 | 1 |
| 结论:CALM在声学质量和意义性上均超越基线,且采样速度快一个数量级。 |
表3:文本转语音模型对比(Librispeech test-clean)
| 模型 | 参数量 | WER (↓) | CER (↓) | SIM (↑) | 声学质量MUSHRA (↑) | 说话人相似度Elo (↑) |
|---|---|---|---|---|---|---|
| 参考 | – | 2.23 | – | 0.69 | 61.8 ± 2.4 | 1953 ± 24 |
| F5 TTS (NFE=32) | 336M | 2.42 | – | 0.66 | 54.7 ± 2.8 | 2032 ± 18 |
| DSM (16 RVQ CFG=3) | 750M | 1.95 | – | 0.67 | 60.2 ± 2.4 | 2112 ± 20 |
| DITAR (NFE=10) | 600M | 2.39 | – | 0.67 | – | – |
| SALAD (NFE=20) | 350M | – | 0.74 | 0.54 | – | – |
| CALM w/ LSD (NFE=1, CFG=1.5) | 313M | 1.81 | 0.57 | 0.52 | 61.1 ± 2.3 | 1966 ± 23 |
| 结论:CALM在WER、CER和声学质量上达到最优。 |
表4:音乐续写模型对比(30秒生成)
| 模型 | 总体加速比 | 采样头加速比 | 采样头耗时占比 | FAD (↓) | 声学质量MOS (↑) | 享受度Elo (↑) | 排名 (↓) |
|---|---|---|---|---|---|---|---|
| 参考 | – | – | – | – | 3.84 ± 0.08 | 2166 ± 33 | - |
| RQ-TRANSFORMER 32 RVQ (基线) | ×1.0 | ×1.0 | 57.7% | 1.06 ± 0.06 | 2.85 ± 0.07 | 1824 ± 29 | 4 |
| CALM - CONSISTENCY - 1 STEP | ×2.2 | ×19.3 | 6.6% | 0.83 ± 0.04 | 2.90 ± 0.07 | 1857 ± 28 | 2 |
| CALM - TRIGFLOW - 100 STEPS | ×0.3 | ×0.2 | 86.6% | 0.64 ± 0.04 | 3.12 ± 0.07 | 1921 ± 29 | 1 |
| MUSICGEN MEDIUM | ×1.3 | – | 0.0% | 1.72 ± 0.12 | 2.62 ± 0.07 | 1761 ± 33 | 6 |
| 结论:1步一致性CALM在FAD和速度上显著优于32-RVQ基线。多步TrigFlow质量更好但极慢。 |
表6:音乐CALM消融实验(250K步后)
| 模型变体 | FAD (↓) |
|---|---|
| 基础 (CALM - Consistency - 4 steps) | 0.93 ± 0.06 |
| 无 Head Batch Multiplier | 1.32 ± 0.09 |
| 无噪声增强 | 1.63 ± 0.11 |
| 无短上下文Transformer | 4.03 ± 0.16 |
| 无上述任意组件 | 8.38 ± 0.17 |
| 结论:每个组件(尤其是短上下文Transformer)对最终性能都至关重要。 |
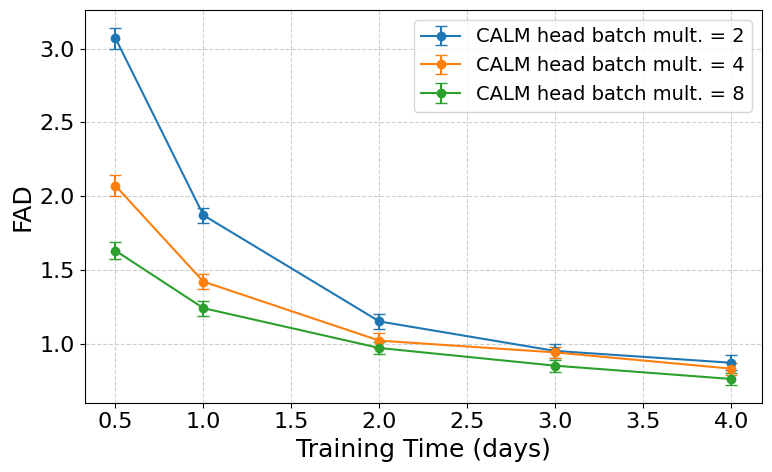
图:不同Head Batch Multiplier值下,音乐CALM模型的FAD指标随训练步数变化的曲线。更高的批处理乘数(如8)能显著加速收敛。
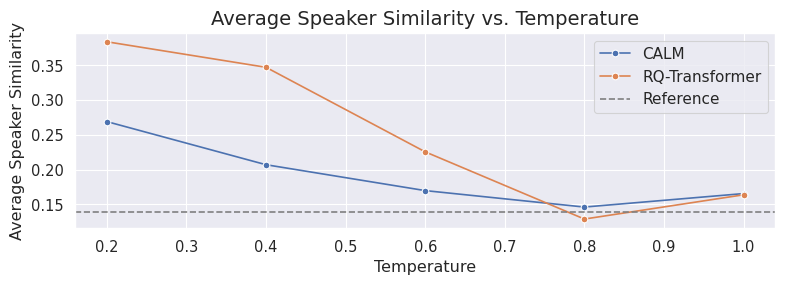
表:不同短上下文Transformer上下文长度K经过500K步训练后的FAD值。K=10和20表现较好,但差异不巨大。
图:高斯温度采样对说话人多样性的影响。随着温度升高,平均说话人相似度降低,表明生成多样性增加,与离散模型趋势一致。
表:TrigFlow和Consistency模型在音乐续写任务中不同采样步数下的生成时间、实时因子(RTF)和FAD值。一致性模型在低步数(<10)下优势明显,是实时流式生成的关键。
⚖️ 评分理由
- 学术质量:6.0/7:论文提出了一个完整、有说服力的框架,通过多项技术创新有效解决了连续音频生成的稳定性和速度问题。实验设计全面,包含多个任务、充分的消融研究和人类评估。主要扣分点在于:1)部分最先进基线(TTS任务)使用了论文外部的结果,未在完全相同条件下复现;2)音乐任务的核心数据集未公开,限制了结果的独立验证。
- 选题价值:1.5/2:直接针对当前音频生成领域的核心瓶颈(质量-效率权衡),提出了一种有前景的解决方案。其方法具有通用性(语音、音乐),且最终落地的Pocket TTS模型展示了实际应用潜力。与音频/语音研究社区高度相关。
- 开源与复现加成:-0.5/1:优点是宣布开源了特定模型(Pocket TTS)并提供了详细的技术报告。缺点是核心代码库(如CALM训练框架)的提供情况不明确,且最关键的音乐数据集未公开。这使得复现论文主要实验结果存在障碍。