📄 Compose and Fuse: Revisiting the Foundational Bottlenecks in Multimodal Reasoning
#多模态推理 #基准测试 #大语言模型 #跨模态
✅ 7.5/10 | 前25% | #多模态推理 | #基准测试 | #大语言模型 #跨模态
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Yucheng Wang, Yifan Hou(苏黎世联邦理工学院计算机系,标注为同等贡献)
- 通讯作者:Mrinmaya Sachan(苏黎世联邦理工学院计算机系)
- 作者列表:Yucheng Wang(苏黎世联邦理工学院计算机系)、Yifan Hou(苏黎世联邦理工学院计算机系)、Aydin Javadov(苏黎世联邦理工学院计算机系)、Mubashara Akhtar(苏黎世联邦理工学院计算机系)、Mrinmaya Sachan(苏黎世联邦理工学院计算机系)
💡 毒舌点评
亮点:论文构建了一套精妙的逻辑推理框架,将模态交互分解为六种可控模式,这种“解剖学”式的系统评估在当前多模态评估中少见且有价值。短板:依赖高度简化的合成逻辑数据来揭示“根本瓶颈”,其结论能否无缝迁移到复杂、开放的真实世界多模态推理场景中,存疑。
🔗 开源详情
- 代码:论文声明代码和数据公开可用(附录提到GitHub仓库),提供了生成脚本和评估协议。
- 模型权重:未提供。使用的是四个公开的开源模型(Baichuan-Omni, Qwen2.5-Omni, MiniCPM-o, Phi-4 Multimodal)。
- 数据集:合成数据,论文提供了生成代码,但未提及独立的数据集下载包。
- Demo:未提及。
- 复现材料:提供了详细的实验设置、提示模板(附录A.3)、线性探针设置(附录A.2),复现材料充分。
- 论文中引用的开源项目:依赖CosyVoice2 TTS进行音频生成,依赖GraphViz进行视觉图表生成,引用了Clark et al. (2020)和Liang et al. (2023)的代码用于事实和规则生成。
📌 核心摘要
- 要解决什么问题:解决多模态大语言模型(MLLM)在推理时,额外模态有时有帮助、有时有害的矛盾现象,缺乏一个可控的评估框架来隔离分析其内部原因。
- 方法核心是什么:提出一个基于逻辑推理的评估框架,将多模态交互系统性地分为六种模式(等价、替代、蕴含、独立、矛盾、互补),通过合成数据控制事实信息在模态间的分布与组合逻辑,以隔离不同因素的影响。
- 与已有方法相比新在哪里:超越了将模型视为黑盒的性能评估,转向对模态交互模式的系统性诊断和内部机制(注意力、层内表征)的探针分析。新在提出了任务组合瓶颈和融合瓶颈这两个核心诊断概念,并通过干预实验验证。
- 主要实验结果如何:
- 整体发现:文本单模态基线通常已接近天花板性能。多模态仅在提供独立且充分的推理路径(替代模式)时略有帮助(平均+12.7%至+14.8% vs 视觉/音频单模态基线);冗余信息(等价模式)无益甚至有害;跨模态多跳链(蕴含模式)严重损害性能(平均下降7.1%-12.8%)。
- 瓶颈诊断:独立模式暴露性能偏差(如文本最强,视觉最弱);矛盾模式暴露偏好偏差(模型在冲突时倾向某些模态,与其自身单模态性能不一致);互补模式暴露融合偏差(性能低于任何单模态基线,平均仅52.0% vs 文本94.6%)。
- 内部机制分析:注意力模式无法有效编码信息的“有用性”;两步提示法(先识别后推理)显著缓解了任务组合瓶颈;模态身份在早期层高度可辨识,调整早期层注意力温度可改善融合偏差。
- 实际意义是什么:指明了MLLM的核心障碍在于信息整合而非感知。未来的模型设计应关注组合感知的训练目标、早期融合的控制机制以及显式的证据选择能力。
- 主要局限性:实验完全基于精心构造的合成逻辑推理任务(单步演绎),其结论是否能泛化到更复杂、更开放的真实世界多模态推理(如视觉问答、文档理解)有待验证。所选模态(文本、TTS音频、图表视觉)过于简化,未涵盖自然图像、视频等更常见的模态。
🏗️ 模型架构
本文并非提出一个新的端到端多模态大语言模型架构,而是提出一个用于诊断现有MLLM推理瓶颈的评估与分析框架。其“架构”主要指实验设置和分析流程。
- 整体输入输出流程:核心流程如图1c所示。系统提示符引导模型,输入包括来自三个模态(文本、音频、视觉)的事实块(顺序随机化)、一组始终以文本呈现的逻辑规则、以及一个四选一的多项选择题。模型输出推理过程和最终答案。
- 主要组件:
- 事实呈现组件:将同一个事实(如“Bob is curious”)渲染为三种受控模态:(i) 文本句子;(ii) 通过CosyVoice2 TTS生成的语音;(iii) 通过GraphViz生成的简单实体-属性图示。目的是减少感知层干扰,聚焦推理整合。
- 交互模式定义组件:根据事实信息在模态间的分布和组合逻辑,定义六种交互模式(见§2.2),这是框架的核心。例如,在“蕴含”模式下,推理链A→B→C被分割到三个模态。
- 分析组件:包括对模型内部注意力的线性探针分析(用于检测模态身份和信息有用性)和因果干预实验(调整不同层注意力温度)。
- 关键设计选择及动机:
- 使用合成逻辑推理任务:动机是能够精确控制变量,隔离模态分布和组合逻辑的影响,避免真实数据中复杂的混杂因素。
- 规则始终为文本:确保推理规则本身不引入模态差异,只改变事实的分布。
- 控制视觉和音频的复杂度:使用简单的图表和清晰的TTS,确保感知准确,使瓶颈更可能出现在整合阶段。

图1展示了从逻辑推理示例(a)、三种模态渲染(b)到评估提示模式(c)的整体流程,清晰地呈现了该框架的控制变量设计思路。
💡 核心创新点
- 基于逻辑的可控评估框架:首次系统性地将多模态推理交互分解为六种基于命题逻辑的原型模式(等价、替代、蕴含、独立、矛盾、互补)。此前工作要么评估笼统,要么只关注特定交互(如冲突)。该框架允许精确地“测试”模型在不同信息分布下的推理能力。
- 识别并实证两个核心瓶颈:超越现象描述,明确提出了多模态推理的两个根本性限制:(i) 任务组合瓶颈:模型能分别完成识别和推理,但难以在一次前向传播中跨模态地联合执行;(ii) 融合瓶颈:模型缺乏鲁棒机制来选择、加权和组合异构信息,导致性能偏差、偏好偏差和融合偏差。
- 从诊断到缓解的闭环验证:不仅识别瓶颈,还通过内部探针分析(注意力无法编码有用性、模态身份在早期层保留)和简单干预(两步提示、调整早期层注意力温度)验证了瓶颈的因果性和可缓解性,为模型改进提供了具体方向。
🔬 细节详述
- 训练数据:使用合成数据。事实和规则基于Clark et al. (2020)和Liang et al. (2023)的代码生成,包含13个姓名、14种动物、15种水果作为主语,34个形容词属性。每个实验条件生成1000个样本。视觉由GraphViz生成,音频由CosyVoice2 TTS生成。
- 损失函数:未说明。本文为评估论文,不涉及训练。
- 训练策略:未说明。所评测的模型(Baichuan-Omni-1.5d, Qwen2.5-Omni, MiniCPM-o-2.6, Phi-4 Multimodal)均为已发布的开源预训练模型,本文未进行训练。
- 关键超参数:评测模型大小从5.6B到8B不等。推理时使用贪心解码(
do_sample=False),最大生成长度1024。线性探针使用逻辑回归(C=1.0,l2正则化,5折交叉验证)。 - 训练硬件:未说明。
- 推理细节:所有模型使用统一的提示模板(附录A.3提供示例),采用float16精度运行,禁止音频输出以保持纯文本输出。
- 正则化或稳定训练技巧:不适用(评测论文)。
📊 实验结果
主要实验结果(基于表格数据):
表1(对应论文Table 1):多模态输入是否有助于推理?三种交互模式下的准确率(%)与相对单模态基线的变化(Δ)。
| 交互模式 | 模型 | 多模态准确率 | Δ视觉, Δ听觉, Δ文本 (与相应单模态基线比) |
|---|---|---|---|
| 等价(≡) | Baichuan | 84.8 | +5.4, +9.8, -11.1 |
| Qwen | 98.9 | +2.6, +4.5, +0.9 | |
| MiniCPM | 94.8 | +5.4, +5.2, -0.2 | |
| Phi4 | 84.1 | +25.3, +23.9, -12.5 | |
| 平均 | 90.7 | +9.7, +10.9, -5.7 | |
| 替代(∨) | Baichuan | 97.6 | +19.6, +17.8, +0.3 |
| Qwen | 100.0 | +3.7, +6.1, +2.6 | |
| MiniCPM | 99.1 | +7.1, +8.0, +2.9 | |
| Phi4 | 97.9 | +20.3, +26.3, +1.0 | |
| 平均 | 98.7 | +12.7, +14.8, +1.7 | |
| 蕴含(→) | Baichuan | 79.5/75.6/80.7 | 视觉最终事实-2.0,听觉最终事实-6.4,文本最终事实-13.6 |
| Qwen | 78.4/86.6/83.9 | 视觉最终事实-15.7,听觉最终事实-8.2,文本最终事实-12.8 | |
| MiniCPM | 81.8/80.0/88.4 | 视觉最终事实-11.4,听觉最终事实-12.0,文本最终事实-6.8 | |
| Phi4 | 73.0/69.3/79.7 | 视觉最终事实-2.2,听觉最终事实-0.7,文本最终事实-18.0 | |
| 平均 | 78.2/77.9/83.2 | 视觉最终-7.8,听觉最终-7.1,文本最终-12.8 |
关键结论:多模态仅在“替代”(独立路径)时一致提升性能,在“等价”(冗余)和“蕴含”(跨模态链)时通常有害。
表2(对应论文Table 2):独立交互模式性能。单一决定性事实位于不同模态,其他模态包含干扰项。
| 模型 | 单模态准确率 | 多模态(∅)准确率 | Δ视觉, Δ听觉, Δ文本 |
|---|---|---|---|
| 视觉 | 听觉 | 文本 | |
| Baichuan | 60.2 | 72.0 | 94.8 |
| Qwen | 73.3 | 94.3 | 95.5 |
| MiniCPM | 77.6 | 83.7 | 91.2 |
| Phi4 | 49.9 | 48.9 | 96.3 |
| 平均 | 65.3 | 74.7 | 94.5 |
关键结论:多模态性能介于最强(文本)和最弱(视觉)模态之间,弱模态会拉低整体表现(性能偏差)。
表4(对应论文Table 4):互补交互模式性能。每个模态提供一个必要事实。
| 模型 | 单模态准确率 | 多模态(∧)准确率 | Δ视觉, Δ听觉, Δ文本 |
|---|---|---|---|
| 视觉 | 听觉 | 文本 | |
| Baichuan | 50.5 | 59.4 | 87.7 |
| Qwen | 87.5 | 98.8 | 98.8 |
| MiniCPM | 74.8 | 89.3 | 92.4 |
| Phi4 | 80.0 | 82.2 | 99.6 |
| 平均 | 73.2 | 82.4 | 94.6 |
关键结论:多模态性能低于任何单模态基线,证明存在独立的“融合偏差”。
内部探针与干预实验结果:

图2(a)显示模型注意力模式对“信息有用性”的识别准确率中等(60-80%),表明模型难以仅靠注意力区分相关事实。图2(b)显示,在“独立”设置下,模型在事实识别和文本推理上表现优异,但在联合多模态推理(MM)上性能骤降,证实了任务组合瓶颈。两步提示法(Two-Step Prompt)显著恢复了性能。
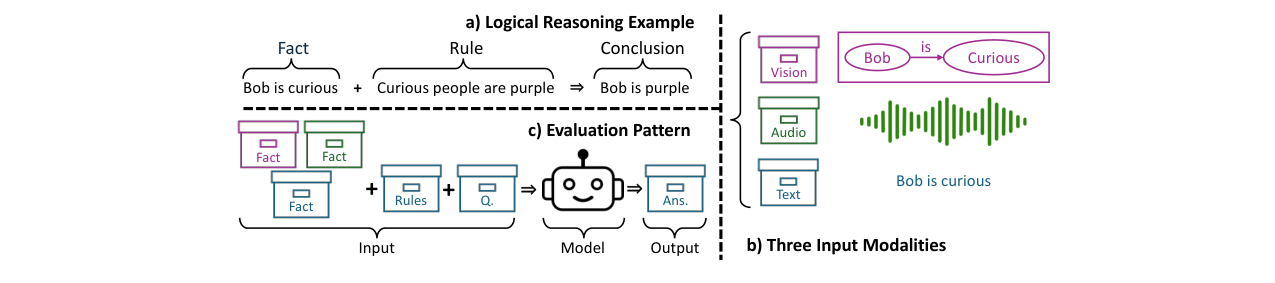
图3(a)显示模型能近乎完美地通过注意力模式识别输入事实的模态(视觉、听觉、文本)。图3(b)的线性探针权重图(以Qwen为例)表明,模态信息主要编码在前四个解码层。图3(c)显示,仅调整这前四个层的注意力温度(从0.4到1.8)即可大幅提升推理准确率,而调整中后期层无效,证实了早期融合引入偏差的融合瓶颈。
⚖️ 评分理由
- 学术质量:5.5/7
- 创新性(1.5/2):提出的逻辑推理交互框架具有很好的系统性和诊断价值,是对现有评估方法的显著深化。两个瓶颈的识别清晰有力。
- 技术正确性(1.5/2):实验设计严谨,控制变量得当,从性能分析到内部探针再到因果干预,形成了完整的证据链。所有结论都有数据支撑。
- 实验充分性(1.5/2):在选定的合成任务和模型上实验充分,每种交互模式都进行了系统性测试。但实验范围局限于合成数据和特定模态组合。
- 证据可信度(1/1):实验可复现性高(提供了详细代码和数据生成脚本),内部机制分析(探针、干预)提供了强有力的因果解释。
- 选题价值:1.5/2
- 前沿性(0.5/1):多模态推理的可解释性与瓶颈分析是当前热点,该工作切中要害。
- 潜在影响与应用(1/1):为理解MLLM推理失败提供了诊断工具和理论框架,明确指出了模型改进的方向(组合感知训练、融合控制),对社区有指导意义。
- 开源与复现加成:0.5/1
- 论文提供了代码和数���生成脚本,复现细节描述详细(附录包含完整提示模板、探针设置),符合可复现性声明。但未提供评测用的合成数据集下载链接,也未提供模型权重(使用公开模型)或在线Demo,加成有限。