📄 Closing the Gap Between Text and Speech Understanding in LLMs
#语音大模型 #知识蒸馏 #主动学习 #大语言模型 #跨模态
🔥 8.5/10 | 前25% | #语音大模型 | #知识蒸馏 #主动学习 | #知识蒸馏 #主动学习
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Santiago Cuervo(Université de Toulon, Aix Marseille Université, CNRS, LIS)
- 通讯作者:未说明
- 作者列表:Santiago Cuervo(Université de Toulon, Aix Marseille Université, CNRS, LIS)、Skyler Seto(Apple)、Maureen de Seyssel(Apple)、Richard He Bai(Apple)、Zijin Gu(Apple)、Tatiana Likhomanenko(Apple)、Navdeep Jaitly(Apple)、Zakaria Aldeneh(Apple)
💡 毒舌点评
论文对“文本-语音理解差距”的成因(遗忘与失准)进行了教科书级的清晰剖析,并据此设计了针对性的SALAD方法,数据效率极高,这种“分析驱动解决方案”的范式是最大亮点。然而,其主要验证集中于英语语音,对于跨语言泛化能力和TTS生成质量对下游性能的长期影响讨论不足,是一个有待拓展的短板。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开权重。
- 数据集:使用了公开数据集(LibriHeavy, Emilia, FineWeb-Edu),但论文本身未发布新数据集。
- Demo:未提及在线演示。
- 复现材料:论文提供了非常详细的附录,涵盖模型描述(A.1)、训练细节(A.2, A.3)、评估协议(A.5)、数据分析方法(A.4, A.6)等,为复现提供了坚实基础。
- 论文中引用的开源项目:Mimi语音分词器 (Défossez et al., 2024)、Kokoro-TTS (开源TTS模型)、SmolLM (Allal et al., 2025)、Whisper (用于评估)、BAAI/bge-large-en-v1.5 (用于聚类)、Qwen2.5 LLMs。
📌 核心摘要
这篇论文旨在解决一个核心问题:将文本大语言模型(LLM)适配到语音输入后,其在语言理解任务上的性能会显著低于其原始文本版本(即“文本-语音理解差距”)。 方法核心是提出了SALAD(Sample-efficient Alignment with Learning through Active selection and cross-modal Distillation),它包含两个阶段:1)在天然语音数据上进行跨模态知识蒸馏,让语音模型模仿其文本教师的输出分布,以减轻遗忘和失准;2)利用模型自身的失准信号,通过主动学习算法从大规模文本语料中选择最具挑战性的领域,合成少量语音数据进行针对性训练,以弥补领域差距。 与先前需要海量合成数据或专有数据集的方法相比,SALAD的创新在于结合了蒸馏目标(对齐效果好)与主动数据选择(数据效率高),两者协同作用。实验结果显示,在3B和7B参数规模的模型上,SALAD仅使用少于一个数量级的公开语音数据(约14万小时天然语音+1%的合成数据),就在6个广泛领域的知识与推理基准测试(如HellaSwag, ARC-C)上,达到了与当前最强开源模型(如Qwen2.5-Omni)相近的语音理解性能,平均差距仅为1.2%,并大幅超越了其他基线。 其实际意义在于证明了无需依赖天量数据或闭源资源,也能高效地缩小语音与文本模型的能力差距,为开发高效、可复现的语音大模型提供了新路径。 主要局限性是实验验证主要基于英语语音,且评估集中在多选题形式,对开放式生成或更复杂对话场景的验证有限。
🏗️ 模型架构
本文的模型架构遵循语音大模型的标准设计,包含三个主要组件,其数据流如下:语音波形 → 语音编码器 → 适配器 → 大语言模型 → 文本输出。
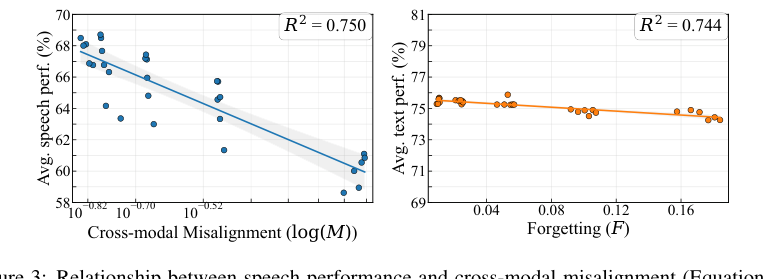
图2展示了文本语料(FineWeb-Edu)与语音数据集(LibriHeavy, Emilia)在领域分布上的巨大差异。 文本数据覆盖了广泛的领域,而现有语音数据仅集中在少数几个领域。这直观地揭示了领域失配是导致模型性能下降的关键原因之一。
- 语音编码器(Speech Encoder):采用冻结的、轻量级的因果模型Mimi语音分词器。它将输入的语音波形序列转换为一组低级的、非文本化的语音表示序列。作者选择此编码器是为了模拟一种“最坏情况”的输入对齐场景,以确保发现能推广到更先进的表示对齐方法,并直接适用于需要低延迟的流式架构。
- 适配器(Adapter):一个由122M参数的Transformer解码器层堆叠而成的模块。其功能是将编码器输出的低级语音表示转换为更高层次、更接近文本语义的表示,以便与LLM的输入空间对齐。该适配器保持因果性,适用于流式处理。
- 语言模型(Language Model):初始化自预训练的纯文本LLM(如Qwen2.5-3B/7B)。它处理由文本嵌入和适配器输出的语音表示交错组成的多模态序列,并预测下一个文本词元的概率分布。
在训练过程中,语音编码器保持冻结,适配器和语言模型被联合优化。
💡 核心创新点
- 对“文本-语音理解差距”的量化分析与归因:明确定义了遗忘(Forgetting) 和跨模态失准(Cross-modal Misalignment) 两个指标,并证明它们分别主要影响文本性能和语音性能(图3)。这一分析框架为后续方法设计提供了清晰的指导方向。
- 两阶段SALAD训练方法:
- 阶段I(蒸馏对齐):证明了在天然语音数据上,使用跨模态知识蒸馏损失(L_DIST) 替代标准的负对数似然损失(L_NLL)是更有效的。这不仅显著降低了跨模态失准,还缓解了文本能力的遗忘(图4, 表2)。
- 阶段II(主动选择扩展):创新性地引入主动学习算法。该算法利用模型自身的跨模态失准信号作为代理,从大规模文本语料中识别并采样最需要补充语音数据的领域进行合成。这种方法用极少量(仅占天然数据1%)的合成数据,针对性地填补了领域空白,实现了高效的数据增强。
- 数据效率的显著提升:通过结合蒸馏与主动选择,SALAD在远少于现有方法的训练数据下(超过一个数量级),实现了具有竞争力的性能(图1)。这挑战了“需要海量数据才能缩小差距”的固有观念。
- 流式友好架构设计:特意选择因果编码器和适配器,表明其方法适用于低延迟、流式的实时交互场景,具有实际应用价值。
🔬 细节详述
- 训练数据:
- 天然语音数据(D_speech):使用LibriHeavy(约5万小时,朗读语音)和Emilia的YODAS-EN子集(对话语音)。
- 文本语料(D_web):使用FineWeb-Edu的10B词元子集,作为领域扩展的来源。
- 合成数据:使用Kokoro-TTS模型(af-heart声音)将选定的文本合成语音。
- 数据处理:为进行交错语言建模,文本和语音段被随机交错(文本段10-30词,语音段5-15词)。语音数据使用强制对齐工具获取词级时间戳。
- 损失函数:采用加权损失
L = α L_DIST + (1-α) L_NLL。L_NLL:标准的负对数似然损失,用于下一个词元预测。L_DIST:跨模态知识蒸馏损失。它最小化语音模型给定语音上下文的输出分布与文本教师模型给定文本上下文的输出分布之间的KL散度。其中,教师模型是初始化该语音模型的原始文本LLM。- 参数α控制蒸馏强度,α=1表示纯蒸馏。
- 训练策略:
- 优化器:AdamW,权重衰减0.1。
- 学习率调度:采用预热-稳定-衰减策略。预热500步,最后20%训练步数线性衰减至零。适配器和语言模型使用不同的峰值学习率(例如SALAD-3B:适配器1e-3, LLM 5e-5)。
- 批次大小:约1M词元。
- 上下文窗口:2048词元。
- 阶段II训练:从阶段I的检查点恢复,继续训练1.9B词元,并将学习率按比例衰减。训练数据由天然语音、主动选择的合成数据和SmolLM语料等比例混合。
- 关键超参数:
- 适配器:12层Transformer解码器,隐藏维度960,MLP维度2560,15个注意力头,5个KV头。
- 主动学习:使用BAAI/bge-large-en-v1.5嵌入进行K-means聚类(K=128)。选择性参数γ=5,合成预算为天然数据的1%。
- 训练硬件:论文中未说明。
- 推理细节:评估采用少样本提示(1-5个示例),通过计算每个答案选项的归一化对数概率并选择最高者来评估准确率。
- 正则化:在训练中混入部分SmolLM语料以缓解遗忘。
📊 实验结果
论文在6个广泛领域的多选题基准测试上进行了评估:StoryCloze, MMSU, OpenBookQA (OBQA), HellaSwag, ARC-Challenge (ARC-C), PIQA。
主要性能对比(表3)
| 模型 | StoryCloze (Acc/Gap) | MMSU (Acc/Gap) | OBQA (Acc/Gap) | HellaSwag (Acc/Gap) | ARC-C (Acc/Gap) | PIQA (Acc/Gap) | 平均 (Acc/Gap) |
|---|---|---|---|---|---|---|---|
| SALAD-7B | 81.5 / 3.5 | 57.5 / 13.3 | 75.1 / 13.9 | 74.0 / 2.7 | 84.0 / 4.4 | 80.3 / 0.4 | 75.4 / 6.2 |
| Qwen2.5-Omni-7B | 80.1 / 4.9 | 61.0 / -9.8 | 85.5 / 3.5 | 68.4 / 8.3 | 87.1 / 1.3 | 78.0 / 1.9 | 76.7 / 5.0 |
| ASR + Qwen2.5-7B (级联) | 84.2 / 0.8 | 67.1 / 3.7 | 84.0 / 5.0 | 74.7 / 2.0 | 86.5 / 1.9 | 79.9 / 0.0 | 79.4 / 2.2 |
| … (其他基线略) | … | … | … | … | … | … | … |
关键结论:SALAD-7B在平均性能和差距上与最强的闭源端到端模型Qwen2.5-Omni-7B非常接近(差距仅1.2%),同时训练数据量少一个数量级(图1)。它显著超越了Qwen2-Audio、DiVA等其他开源端到端模型,并与级联管线(ASR+LLM)具有竞争力。
阶段II主动选择的效果(表4)
| 方法 | MMSU | OBQA | ARC-C | 平均提升 |
|---|---|---|---|---|
| 随机采样 | 49.5 | 71.9 | 78.9 | 基准 |
| 主动选择 (γ=5) | 52.5 | 76.7 | 79.9 | +2.4% |
| 结论:主动选择策略在科学、技术类问题(如MMSU, OBQA, ARC-C)上带来了显著提升,验证了其针对领域差距进行采样的有效性。 |
文本能力保持对比(表5) SALAD模型(3B和7B)在语音训练后,其文本输入下的性能与原始文本LLM的差距极小(甚至为负值,表示略有提升),远优于DiVA、GLM-4-Voice等其他模型。这证明了蒸馏目标能有效防止文本能力遗忘。
分析性结论(图3, 图4)
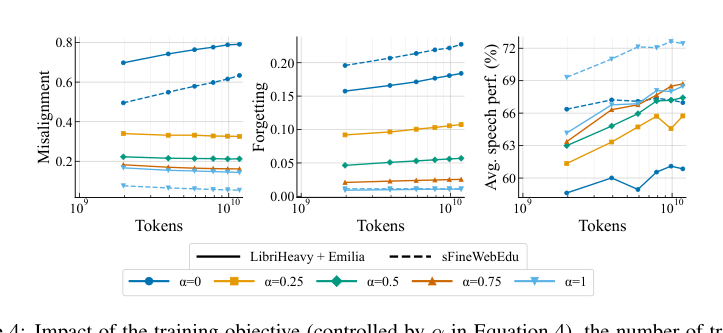
图3显示,语音性能与失准度(对数尺度)强负相关(R²=0.75),文本性能与遗忘度强负相关(R²=0.74)。表1的偏R²分析表明,失准度是语音性能下降的主要独特解释因子,遗忘度是文本性能下降的主要独特解释因子。
图4显示,在窄域数据(LibriHeavy+Emilia)上,纯NLL训练(α=0)导致失准随数据量增加而恶化;而蒸馏训练(α>0)能有效控制失准。在广域合成数据(FineWebEdu)上结合蒸馏(α=1)取得了最低的失准和最好的性能。
其他分析:
- 缩放定律(表2):失准度与训练词元数符合神经网络缩放定律,蒸馏目标(α>0)能更快地将失准度降至不可约水平附近。
- 主动选择分析(图6, 图8):存在一个最优的选择性参数γ,过小则无效,过大则过度集中而损失多样性。两阶段训练在大多数任务上优于仅第一阶段训练。
⚖️ 评分理由
- 学术质量:6.5/7:论文的分析框架清晰有力,技术方案(SALAD)设计精巧,实验设计全面,包括了消融研究、缩放分析和广泛基准测试,数据充分,论证严谨。主要创新在于将蒸馏与主动学习结合以提升效率。
- 选题价值:1.5/2:解决语音大模型理解能力不足的问题是当前的核心挑战之一,该工作对提升模型能力、降低训练成本有直接贡献,应用前景明确。
- 开源与复现加成:0.5/1:论文在附录中提供了详尽的模型架构、训练超参数、评估协议等信息,可复现性高。但主要的扣分点在于未提供代码仓库或模型权重的公开链接,这使得实际复现存在一定门槛。