📄 Can Vision-Language Models Answer Face to Face Questions in the Real-World?
#音频问答 #基准测试 #多模态模型 #音视频
🔥 8.0/10 | 前25% | #音频问答 | #基准测试 | #多模态模型 #音视频
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Reza Pourreza(Qualcomm AI Research)
- 通讯作者:未明确说明
- 作者列表:Reza Pourreza(Qualcomm AI Research), Rishit Dagli(University of Toronto / Qualcomm AI Research), Apratim Bhattacharyya(Qualcomm AI Research), Sunny Panchal(Qualcomm AI Research), Guillaume Berger(Qualcomm AI Research), Roland Memisevic(Qualcomm AI Research)
💡 毒舌点评
论文的亮点在于精准地抓住了当前多模态大模型从“离线理解”走向“实时交互”的关键瓶颈,并构建了一个极具针对性的真实世界问答基准,为社区指明了明确的改进方向。然而,其短板在于数据集规模相对有限(2900条),且核心评估指标依赖LLM judge,可能引入新的评估偏差,而提出的“流式基线”方法相对简单,更多是概念验证而非技术突破。
📌 核心摘要
本文旨在评估当前的视觉语言大模型在真实世界实时、面对面问答场景下的能力。论文指出,现有模型和基准大多关注离线视频理解,缺乏对实时交互中“情境感知”和“回答时机判断”能力的评估。为此,作者构建了一个新的数据集与基准——Qualcomm Interactive Video Dataset (QIVD)。该数据集包含2900个由用户通过手机或电脑录制的视频,视频中用户会基于看到的场景提出一个开放性问题,并提供了问题文本转录、答案以及最关键的“最佳回答时间戳”。通过与多个最先进(SOTA)模型(包括GPT-4o、Gemini、Qwen系列、VideoLLaMA系列等)的对比实验,论文发现现有模型在该任务上与人类表现存在巨大差距。例如,在离线设置(使用真值问题和时间戳)下,最强的GPT-4o模型正确率仅为58.76%,而人类基线达到87.33%。实验揭示了模型的三大主要失败模式:难以实时整合视听信息消歧、无法判断合适的回答时机、缺乏情境常识。论文进一步证明,通过在QIVD上对多模态模型(如VideoLLaMA2.1)进行微调,可以显著提升其在动作计数、音频视觉任务等类别上的性能。该工作的主要贡献是提出了一个全新的、用于评估实时交互式视觉推理的基准数据集,并系统地分析了当前模型的局限性。其局限性在于数据集规模相对较小,且评估高度依赖LLM judge。
🏗️ 模型架构
本文的核心贡献并非提出一个新的端到端实时交互模型,而是定义问题、构建数据集并评估现有模型。因此,其“架构”主要体现在评估框架和一个简单的基线方法上。
整体评估框架: 论文评估了多种闭源(GPT-4o, Gemini-2.5-Flash)和开源(VideoLLaMA系列, Qwen系列等)的大语言多模态模型(LMM)。对于非流式模型,评估框架为:输入一个经过裁剪的视频(裁剪点基于“最佳回答时间戳”)和对应的问题文本,让模型生成答案,然后使用LLM judge(Qwen3-8B)判断答案的正确性。
流式基线方法(Baseline Streaming Approach): 这是一个为应对实时处理而提出的简单流水线,其核心思想是将“听到问题”和“回答问题”解耦。
- 输入: 包含用户语音的连续视频流。
- 组件1:流式ASR系统。 使用Whisper-Streaming实时转录音频,其作用不仅是转录问题文本,更重要的是检测问题的结束时刻(
when-to-answer)。论文指出,问题结束时刻不一定等于可以回答的时刻,因此这是一个妥协方案。 - 组件2:视频LMM骨干网络。 在检测到问题结束的时刻,将截至该时刻的视频帧、音频特征以及转录出的问题文本一起输入给选定的视觉语言模型(如VideoLLaMA),由该模型生成最终答案。
- 数据流: 音视频流 -> 流式ASR(转录+检测结束点) -> 在该时间点截取多模态输入 -> LMM -> 答案。
该方法将复杂的实时交互拆分为两个当前技术相对成熟的模块,但其性能受限于ASR的转录精度和
when-to-answer检测精度。
- 流式Qwen2.5-Omni模型(Stream-Qwen-Omni): 这是一个为更精确地解决“何时回答”问题而微调的模型。
- 架构改造: 基于Qwen2.5-Omni模型,将其输入改为1秒粒度的音视频数据块。
- 训练目标: 模型在“聆听和观察”阶段生成特殊占位符token,在达到训练数据中提供的“最佳回答时间戳”时,开始生成答案。
- 训练方式: 仅微调视觉适配器、音频适配器和嵌入层,冻结其他大部分权重。 这种方法试图让模型自身学会判断回答时机,而非依赖外部ASR系统,其时间戳预测误差(MAE 0.52秒)显著优于Whisper-Streaming(MAE 0.83秒)。
图D.1:Stream-Qwen-Omni与离线Qwen-Omni的结构对比示意图。左侧为离线模型,一次性处理所有数据;右侧为流式模型,以1秒为单位分块处理,并在合适的时机生成答案。
💡 核心创新点
- 提出首个面向实时、面对面问答的基准数据集QIVD: 这是最核心的创新。不同于以往处理预先录制好视频的QA数据集,QIVD的视频是用户同时录制动作并提问的,真实模拟了“边发生边提问”的场景,并创新性地标注了“最佳回答时间戳”,将“何时回答”这一关键但被忽视的能力纳入评估。
- 系统性地诊断当前多模态大模型的实时交互能力缺陷: 论文通过全面的实验,明确指出了现有模型在整合实时视听信息、判断回答时机以及应用情境常识方面的三大短板,为后续研究提供了清晰的路线图。
- 证明了在特定交互数据上微调的有效性: 通过对VideoLLaMA2.1在QIVD上进行微调,证明了即使在小数据集上训练,也能显著提升模型在动作理解、音视频整合等关键实时交互任务上的性能,验证了数据驱动方法的潜力。
- 设计了流式处理基线并探索了端到端时机检测: 提出了流式ASR+LMM的流水线基线,并进一步微调Qwen2.5-Omni使其具备端到端的“当答时机”检测能力,为构建实用的实时交互系统提供了初步的技术路径。
🔬 细节详述
- ��练数据:
- 数据集:QIVD,包含2900个视频-问题-答案三元组。
- 来源:众包收集,参与者使用手机/电脑录制自己做动作并提问的视频。
- 规模:2900个样本,平均视频时长约5.1秒。
- 预处理:经过严格的人工质量检查,排除不合格内容。进行了语义分类(13类)和答案归一化(生成短答案)。
- 数据增强:未说明。
- 损失函数: 未明确说明微调时使用的确切损失函数(可能为标准交叉熵损失)。
- 训练策略:
- 对于VideoLLaMA2.1-7B-AV的微调:采用5折交叉验证。冻结视觉编码器(SigLIP),训练音频塔(BEATs)、多模态投影器(A)和LLM骨干(Qwen2-7B)。学习率
2e-5,使用余弦退火调度,3% warm-up,训练2个epoch,批大小8(通过梯度累积),使用DeepSpeed ZeRO-2。 - 对于Stream-Qwen-Omni的微调:冻结大部分权重,仅训练视觉/音频适配器和嵌入层。批大小1,梯度累积1,训练1个epoch。
- 对于VideoLLaMA2.1-7B-AV的微调:采用5折交叉验证。冻结视觉编码器(SigLIP),训练音频塔(BEATs)、多模态投影器(A)和LLM骨干(Qwen2-7B)。学习率
- 关键超参数:
- 模型规模:评估的模型从7B到72B参数不等。
- 微调框架:使用PyTorch和DeepSpeed。
- 训练硬件: 所有实验在单块A100-80GB GPU上运行。
- 推理细节:
- 对于流式基线,使用Whisper-Streaming进行实时转录,块大小0.25秒。
- 对于标准LMM评估,视频被预处理为4帧均匀采样,分辨率减半(针对GPT-4o)。
- Stream-Qwen-Omni以1秒为单位分块输入音视频数据。
- 正则化或稳定训练技巧: 未特别说明。
📊 实验结果
论文的实验分为几个部分,揭示了不同设置下的模型性能。
流式ASR性能(表4):
模型 METEOR ↑ BLEU ↑ ROUGE-L ↑ ∆t ↓ (MAE) Whisper 90.01 80.95 90.32 - Whisper-Streaming 92.34 74.57 91.82 0.83秒 Stream-Qwen-Omni - - - 0.52秒 Stream-Qwen-Omni在“何时回答”的时间戳预测上显著优于Whisper-Streaming。 主要模型评估结果(表5 - 部分关键数据): 论文的核心评估比较了不同模型在两种设置下的表现:“ASR问题与时间戳”(模拟真实流式)和“人类问题与时间戳”(理想离线)。
| 模型 | 正确率 (人类问题) ↑ | METEOR (人类问题) ↑ |
|---|---|---|
| 人类基线 | 87.33 | 53.21 |
| GPT-4o | 58.76 | 51.18 |
| Gemini-2.5-Flash | 58.07 | 43.07 |
| Qwen3-VL-8B | 60.07 | 36.72 |
| VideoLLaMA2-72B | 50.83 | 51.13 |
| VideoLLaMA2.1-7B-FT (AV) | (图2数据) | - |
关键发现:
- 巨大性能差距: 最强的模型(GPT-4o)与人类基线在正确率上相差近30个百分点。
- 静态 vs. 时序任务鸿沟(图3, 表C.3): 所有模型在静态对象任务上表现尚可,但在需要时序推理的任务(如动作计数)上性能断崖式下跌,而人类表现稳定。
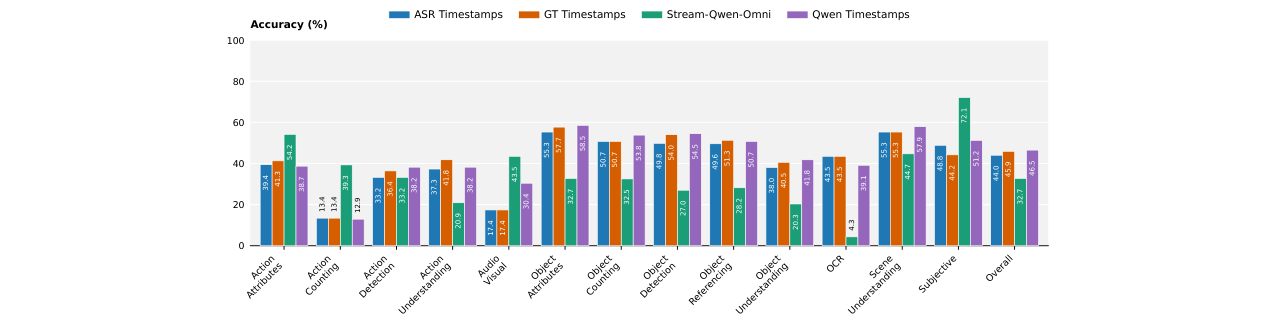
图3:模型在静态任务与时序任务上的正确率对比。人类在两类任务上表现接近,而所有模型在时序任务上性能显著下降。
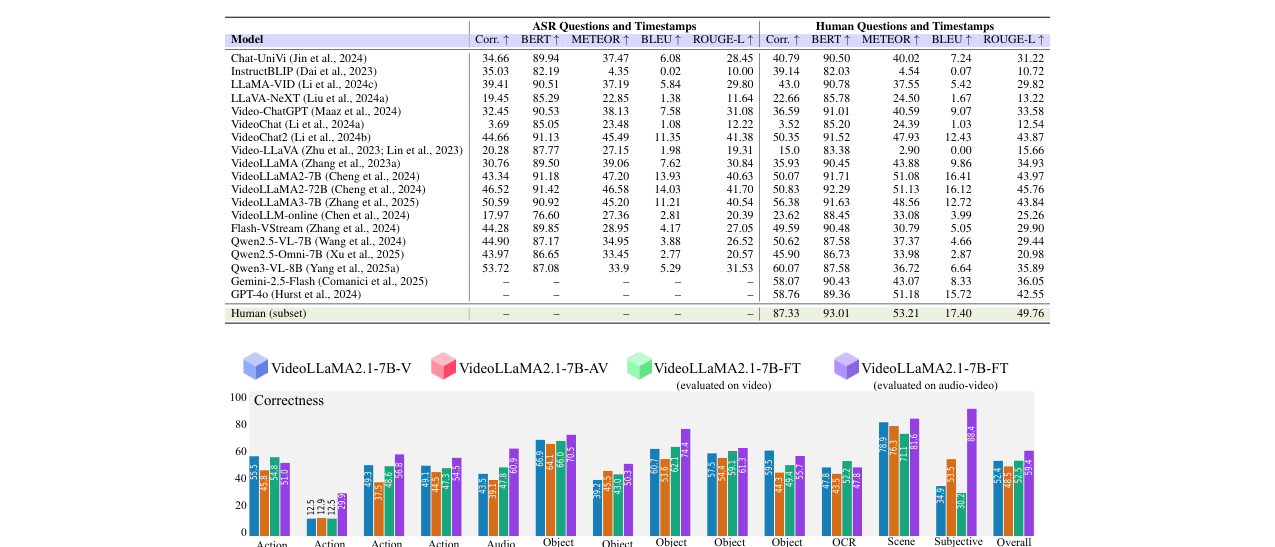
微调效果(图2): 对VideoLLaMA2.1-7B-AV在QIVD上进行微调后,其性能在多个类别上得到提升,尤其在主观题(+23.26%)、音频视觉任务(+17.39%)和动作计数(+16.96%)上提升明显。这证明了针对性数据训练的价值。
音频模态影响(图2): 有趣的是,在微调前,直接向VideoLLaMA2.1-7B加入音频信息反而降低了整体性能。但微调后,音视频融合模型在几乎所有类别上都优于仅视觉模型,尤其是在主观题(+37.61%)和对象检测(+9.48%)上。这表明现有模型的音视频融合能力需要专门训练才能有效发挥。
回答时机的重要性(图3): 使用Qwen2.5-Omni模型的实验表明,使用真值时间戳(GT Timestamps)的性能(正确率45.9%)远高于使用其自身预测的流式时间戳(Qwen Timestamps, 正确率39.3%),而后者又高于使用ASR时间戳(ASR Timestamps, 正确率43.5% - 此处数据与描述略有出入,但趋势一致)。这证实了精准判断“何时回答”对性能至关重要。
⚖️ 评分理由
- 学术质量:6.0/7 - 论文提出了一个定义清晰、极具现实意义的新问题和评估基准。实验设计全面,覆盖了多种SOTA模型,分析深入(如静态/时序任务对比、音频影响、时机影响),数据翔实,结论可信。创新性主要体现在问题定义和数据集构建上,而非提出全新的模型架构或算法。
- 选题价值:1.5/2 - 实时多模态交互是AI助手和机器人的核心能力,具有极高的前沿性和应用潜力。该工作精准地揭示了当前技术的关键瓶颈,对推动该领域发展有直接指导意义。相关性高,但应用范围目前可能偏向交互系统研究。
- 开源与复现加成:0.5/1 - 论文详细说明了数据收集方法、标注流程、评估指标和实验设置,提供了很强的可复现指导。明确提供了QIVD数据集的链接(qualcomm.com/…),但论文中未提及开源具体代码(如流式基线或微调脚本)。部分超参数和细节在附录中给出。