📄 Can Speech LLMs Think while Listening?
#语音对话系统 #语音大模型 #微调 #自回归模型 #实时处理
✅ 7.5/10 | 前25% | #语音对话系统 | #微调 | #语音大模型 #自回归模型
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Yi-Jen Shih(The University of Texas at Austin, Meta Superintelligence Labs)
- 通讯作者:Michael L. Seltzer(Meta Superintelligence Labs)
- 作者列表:Yi-Jen Shih(The University of Texas at Austin, Meta Superintelligence Labs)、Desh Raj(Meta Superintelligence Labs)、Chunyang Wu(Meta Superintelligence Labs)、Wei Zhou(Meta Superintelligence Labs)、SK Bong(Meta Superintelligence Labs)、Yashesh Gaur(Meta Superintelligence Labs)、Jay Mahadeokar(Meta Superintelligence Labs)、Ozlem Kalinli(Meta Superintelligence Labs)、Michael L. Seltzer(Meta Superintelligence Labs)
💡 毒舌点评
这篇论文最大的亮点在于将“边听边想”从一个人机交互概念落实为一套可训练、可控制的技术方案,尤其是提出的“问题完整度”指标,巧妙地将语义完备性与生成时机联系起来。然而,一个显眼的短板是,其核心指标“问题完整度”的计算严重依赖于外部LLM(如Llama-3-8B-Chat)的预测概率,这在部署时可能带来额外的计算开销和延迟,且该指标的泛化能力(是否对不同LLM稳定)并未充分验证。
🔗 开源详情
- 代码:论文中未提及公开的代码仓库链接。
- 模型权重:未提及公开Moshi微调后的模型权重。
- 数据集:
- 训练数据源:使用了公开的CoT-Collection数据集,并描述了详细的改写和TTS转换流程。
- 评测基准:作者构建并公开了SRQA(Spoken Reasoning QA)基准,包含从ARC, PIQA, SIQA, GSM8K等转化而来的语音问答数据集(详见附录A.3),但论文未明确说明该基准的公开下载地址。
- Demo:未提及在线演示。
- 复现材料:提供了非常充分的训练细节(超参数、硬件、损失函数)、评估方法(LLM-judge Prompt、VAD+Whisper流水线)以及大量定性结果示例,复现友好度高。
- 引用的开源项目:论文依赖并微调了开源的Moshi模型,并引用了Llama-3作为骨干和评估裁判、Whisper用于转录、pyannote.audio用于VAD、Llama-2/3和Gemma等作为文本基线对比。
📌 核心摘要
这篇论文旨在解决当前语音大语言模型(Speech LLMs)在复杂推理任务上表现不佳且响应延迟高的问题。作者提出通过在多流语音LLM(基于Moshi模型)的文本单声道流中进行思维链(CoT)微调来提升推理能力,并引入了“边听边想”范式以降低CoT带来的额外延迟。其核心创新在于:1) 首次系统探索了在多流架构中使用文本CoT进行微调;2) 提出一种基于KL散度的“问题完整度(QC)”指标,用于语义感知地判断何时可以开始推理;3) 利用DPO偏好优化,结合正确性和长度偏好数据,进一步优化了精度-延迟权衡。实验结果表明,CoT微调平均将语音推理任务的准确率提升2.4倍;QC指标比简单的词数偏移方法提供了更优的精度-延迟控制;最终通过DPO训练,在保持精度的同时将响应延迟降低了约70%。本文构建了首个语音推理问答基准(SRQA),并证明了文本CoT在效率上优于语音CoT。该工作推动了语音助手向更智能、响应更自然的对话代理迈进。
🏗️ 模型架构
论文基于开源的多流全双工语音LLM模型Moshi进行扩展和微调。Moshi同时处理三个时间对齐的令牌流:用户音频、系统音频和系统文本(称为“文本单声道”)。
模型架构与数据流详解:
输入与表示:
- 用户音频 (
AU):由Mimi编解码器将波形编码为离散令牌,帧率为12.5 Hz,使用8个码本(codebook),大小为2048。 - 系统音频 (
AS):同样由Mimi编码/解码。 - 系统文本 (
TS):词汇表大小为32000。 - 关键对齐:所有令牌流长度
L对齐。文本令牌通过填充令牌([PAD]和[EPAD])与音频令牌对齐,因此文本流中大部分是填充符。
- 用户音频 (
模型结构:
- 包含一个时序Transformer(Temporal Transformer)和一个深度Transformer(Depth Transformer)。
- 在每个时间步
t,时序Transformer接收AU_t和AS_t,预测下一个时间步的文本令牌TS_{t+1}。 - 该文本令牌被输入深度Transformer,用于生成下一个时间步的系统音频令牌
AS_{t+1}。 - 模型的训练目标是联合概率
p(AS_{t+1}, TS_{t+1} | AS_{≤t}, TS_{≤t}, AU_{≤t})。
CoT与流式ASR的集成(核心扩展):
- 为了在文本单声道流中集成CoT和流式ASR,作者在训练时将流式用户转录文本 (
QT)、推理文本 (RT) 和响应文本 (AT) 统一排列在文本流TS中。 - 使用特殊令牌
<start_cot>和<end_cot>来标识CoT部分。 - 引入
<switch_cot>和<switch_asr>令牌,使模型能够在生成CoT令牌和流式ASR令牌之间动态切换模式,从而实现“边听边想”。 - 训练时,流式ASR令牌
QT相对于用户音频有k个令牌(实验中为6,相当于480ms)的延迟(look-ahead),以提供足够的上下文。
- 为了在文本单声道流中集成CoT和流式ASR,作者在训练时将流式用户转录文本 (
训练Token序列安排图:

图1展示了如何在文本单声道通道上交错排列流式ASR令牌、CoT令牌和响应文本令牌,并使用特殊切换令牌进行模式切换,从而在用户语音输入的同时允许模型进行推理。
💡 核心创新点
多流语音LLM中的文本CoT微调:
- 是什么:首次在如Moshi这样的多流架构中,通过在文本单声道流插入思维链文本来微调语音LLM。
- 之前局限:此前工作要么使用语音CoT(计算成本高、令牌效率低),要么在离线场景使用,未能充分结合多流架构的并行处理能力。
- 如何起作用:将CoT以文本形式插入,与流式ASR和系统音频共享文本通道,模型需学习关联语音输入与文本推理。
- 收益:在SRQA任务上平均获得2.4倍的准确率提升,且文本CoT比语音CoT令牌效率高2倍(如表3所示)。
“问题完整度(QC)”指标实现“边听边想”:
- 是什么:提出一个基于KL散度的指标
ζ(p),用于衡量用户问题的部分转录在语义上已完整的程度,从而确定开始推理的最佳时机(信息拐点)。 - 之前局限:简单的启发式方法(如固定偏移几个词)缺乏语义感知,无法适应不同问题结构。
- 如何起作用:在训练时,根据QC指标选择的信息拐点插入
<start_cot>令牌,教模型何时开始推理。在推理时,模型需自行预测该拐点。 - 收益:相比词数偏移基线,在相同延迟条件下能获得更高的准确率(如图5所示),提供了更精确的精度-延迟权衡控制。
- 是什么:提出一个基于KL散度的指标
基于DPO的偏好优化以进一步优化:
- 是什么:利用拒绝采样生成偏好数据,对“边听边想”模型进行DPO训练,分别针对正确性和推理长度进行优化。
- 之前局限:仅通过SFT难以让模型学习动态更新推理,并可能生成过长的CoT。
- 如何起作用:生成“正确但短”与“错误或长”的回答对,通过DPO损失引导模型偏好更优的推理策略。
- 收益:实现了在保持准确率的同时,将响应延迟降低约70%(如表4所示),并将精度-延迟帕累托前沿进一步推进(如图5紫色曲线所示)。
🔬 细节详述
- 训练数据:使用CoT-Collection数据集,经过口语化改写和TTS合成,得到约69万个训练样本。问题长度限制在60词以内。
- 损失函数:
- 监督微调(SFT):使用标准的下一令牌预测的负对数似然(NLL)损失。
- 偏好调优(DPO):使用DPO损失(公式8),并结合长度归一化和NLL损失(公式9)进行稳定训练,其中
β=0.1,λ=0.1。
- 训练策略:
- SFT:在8块A100 GPU上使用全分片数据并行(FSDP)训练8000步,学习率
4e-6,批次大小128,带400步预热和退火。 - DPO:使用上述SFT模型初始化策略模型和参考模型,学习率
5e-7,批次大小16,训练1200步。
- SFT:在8块A100 GPU上使用全分片数据并行(FSDP)训练8000步,学习率
- 关键超参数:
- 模型基础:Moshi(基于Helium 7B文本骨干)。
- 音频令牌帧率:12.5 Hz(每个令牌80ms)。
- 流式ASR延迟(k):6个令牌(480ms)。
- QC阈值
θ:实验中测试了0.95, 0.85, 0.75, 0.65。
- 训练硬件:8x NVIDIA A100 GPU。
- 推理细节:
- 使用强制解码(force-decoding):在问题开始时插入k个
[PAD]令牌以适应流式ASR延迟;若模型未生成<start_cot>,则在问题结束时强制生成。 - 延迟度量:定义为用户问题结束到系统语音响应开始的时间间隔,以令牌数表示(1令牌=80ms)。
- 准确度度量:使用VAD检测响应语音,Whisper转录后,由LLaMA-3.1-405B作为评委判断答案正确性。
- 使用强制解码(force-decoding):在问题开始时插入k个
- 正则化技巧:在DPO中使用了长度归一化(Length-Normalized DPO)并加入NLL损失以稳定训练。
📊 实验结果
论文构建了语音推理问答(SRQA)基准,包含ARC-E/C、PIQA、SIQA、GSM8K和LLaMA-QS任务。
主要结果(表2):与Moshi基线及其他模型的对比
| 模型 | 预训练文本令牌数 | ARC-E | ARC-C | SIQA | PIQA | GSM8K | LLaMA-QS (事实性) |
|---|---|---|---|---|---|---|---|
| 文本LLMs | |||||||
| Helium† | 2.1T | 79.6 | 55.9 | 51.0 | 79.4 | – | – |
| LLaMA2-7b-Chat | 2T | 63.7 | 47.1 | 13.4 | 25.8 | 29.4 | 70.6 |
| Gemma-7B-Instruct | 6T | 82.5 | 66.2 | 18.3 | 45.0 | 43.1 | 69.7 |
| 语音LLMs | |||||||
| Qwen2-Audio-7B-Instruct | 2.4T | 59.1 | 42.4 | 21.9 | 24.5 | 18.1 | 64.7 |
| Kimi-Audio-7B-Instruct | 18T | 83.0 | 71.5 | 32.9 | 34.4 | 15.7 | 61.7 |
| Moshi (baseline) | 2.1T | 30.2 | 21.5 | 22.8 | 23.8 | 8.7 | 42.8 |
| Moshi + CoT (ours)♣ | 2.1T | 77.7 | 59.8 | 56.1 | 56.9 | 16.1 | 57.8 |
| w/o Streaming User ASR | 2.1T | 55.8 | 44.0 | 50.1 | 46.3 | 12.2 | 59.9 |
†为Moshi的文本骨干,结果不可直接比较。♣包含延迟为6个令牌的流式用户ASR。 关键结论:本方法将Moshi基线在推理任务上的准确率平均提升了29.1%(绝对值),在许多任务上达到2-3倍提升,并且在预训练数据量少得多的情况下,性能与更强大的商业语音LLM(如Kimi-Audio)具有竞争力。
流式ASR效果消融(图4):
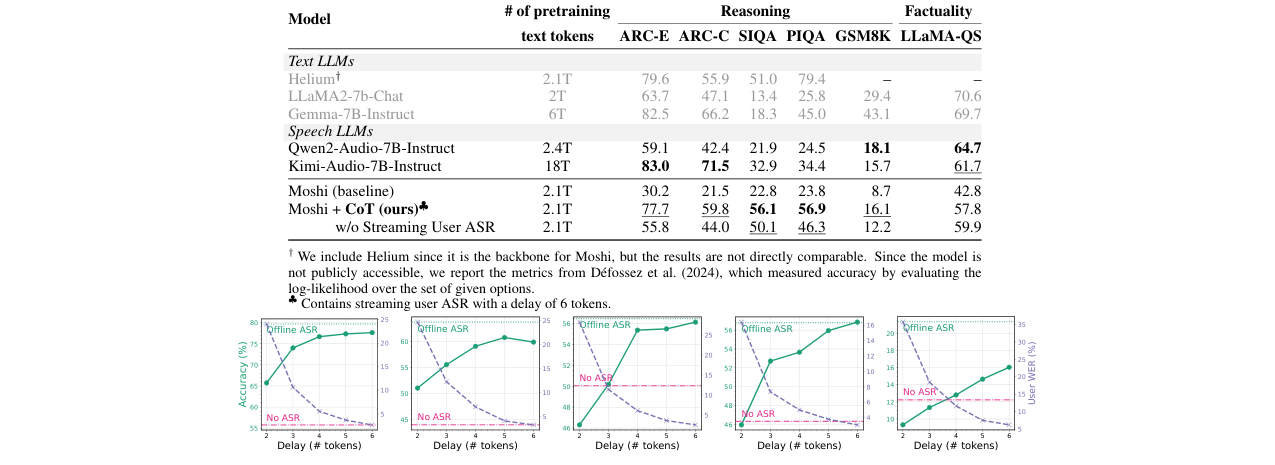
图4显示,随着流式ASR延迟(look-ahead)令牌数从2增加到6,所有SRQA任务的准确率持续提升并接近“离线ASR”上界,同时用户词错率(WER)下降。证明了流式ASR对推理至关重要。
“边听边想”方法精度-延迟权衡(图5):
图5展示了在ARC-E、ARC-C、GSM8K、SIQA、PIQA等任务上,不同方法(基线CoT、词数偏移WordShift、问题完整度QC、正确性DPO)的精度-延迟帕累托曲线。QC方法(绿线)在可比延迟下优于WordShift基线;正确性DPO(紫线)进一步提升了QC模型的精度。
DPO训练对延迟的优化效果(表4):
| Eval Set | SFT Accuracy | DPO Accuracy | SFT Latency (# tokens) | DPO Latency (# tokens) |
|---|---|---|---|---|
| LLaMA-QS | 56.2 | 56.9 | 35.6 | 20.9 |
| ARC-E | 62.8 | 65.4 | 49.2 | 12.0 |
| ARC-C | 43.2 | 46.0 | 49.9 | 13.2 |
| SIQA | 45.1 | 45.3 | 50.0 | 12.9 |
| PIQA | 40.7 | 46.0 | 46.6 | 18.2 |
| GSM8K | 13.8 | 14.7 | 76.0 | 48.6 |
关键结论:经过长度偏好DPO训练后,在所有评估集上平均延迟降低了约30个令牌(约70%),同时准确率保持稳定或略有提升。
⚖️ 评分理由
- 学术质量:6.0/7:论文创新性地将CoT引入多流语音LLM并系统解决了延迟问题,提出了有理论动机(语义完备性)的QC指标。实验设计全面,包括基线对比、多种消融研究(流式ASR、文本/语音CoT、QC vs WordShift)、以及DPO优化,结果令人信服。扣分点在于QC指标的计算依赖于一个外部且未完全公开的LLM,其稳定性和部署效率是潜在弱点。
- 选题价值:1.5/2:直接针对语音AI的核心短板(推理弱、延迟高),选题前沿且重要。提出的方案对提升语音助手的实用性和用户体验有直接影响,与音频/语音领域紧密相关。
- 开源与复现加成:0.5/1:论文提供了极其详尽的训练和评估细节(数据处理、模型配置、Prompt模板),构建了公开的评测基准(SRQA),这对复现非常友好。但主要模型权重和代码未提及开源,扣分。