📄 Bridging Piano Transcription and Rendering via Disentangled Score Content and Style
#音乐信息检索 #音乐生成 #多任务学习 #扩散模型 #解耦表示学习
🔥 8.0/10 | 前25% | #音乐信息检索 | #多任务学习 | #音乐生成 #扩散模型
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Wei Zeng (National University of Singapore, Integrative Sciences and Engineering Programme, NUS Graduate School; School of Computing)
- 通讯作者:Ye Wang (National University of Singapore, Integrative Sciences and Engineering Programme, NUS Graduate School; School of Singapore, Email: dcswangy@nus.edu.sg)
- 作者列表:Wei Zeng (National University of Singapore, Integrative Sciences and Engineering Programme, NUS Graduate School; School of Computing), Junchuan Zhao (National University of Singapore, School of Computing), Ye Wang (National University of Singapore, Integrative Sciences and Engineering Programme, NUS Graduate School; School of Computing)
💡 毒舌点评
亮点:巧妙地将演奏渲染(EPR)和乐谱转录(APT)这两个互逆任务统一到一个解耦表示学习的框架中,不仅提升了两个任务的性能,还为可控的音乐表达(风格迁移、自动推荐)开辟了新路径,理论动机清晰,工程实现完整。 短板:模型本身规模较大(188M参数),且PSR模块需要单独训练和推理,增加了部署复杂性;实验数据主要局限于古典钢琴音乐,其在更广泛音乐流派(如爵士、流行)上的泛化能力未得到验证。
🔗 开源详情
- 代码:论文中未直接提供代码仓库链接,但在结论处承诺“将在论文接收后发布代码,提供充分的说明以使用公共数据集(如ASAP和ATEPP)复现模型架构和训练流程”。
- 模型权重:未提及公开预训练模型权重。
- 数据集:使用了公共数据集ASAP和ATEPP,论文中描述了数据划分和处理流程。无配对数据(MuseScore乐谱、YouTube转录演奏)为自行收集,但部分来源公开。
- Demo:提供了一个项目主页(https://wei-zeng98.github.io/joint-apt-epr/)用于展示EPR和风格迁移的示例音频。
- 复现材料:论文附录(A-G)提供了极其详细的数据处理细节(数据过滤规则、表示方案)、模型实现细节(训练任务、损失公式、优化配置、PSR架构)、主观测试说明、补充实验(消融、多样性分析、GPT标注验证)、以及挑战与未来工作讨论。这些信息为复现提供了坚实基础。
- 引用的开源项目:MidiTok (用于MIDI令牌化), Partitura (用于音乐处理), Aria-AMT (用于音频转录)。
📌 核心摘要
- 问题:表现性钢琴演奏渲染(EPR,从乐谱生成演奏)和自动钢琴转录(APT,从演奏恢复乐谱)是音乐信息检索中的两个基础互逆任务。现有工作通常独立处理它们,且EPR系统大多依赖精细的音符级对齐数据,限制了其灵活性和可扩展性。
- 方法:本文提出了一个基于Transformer的统一序列到序列(Seq2Seq)框架,通过解耦音符级乐谱内容和全局演奏风格表示,联合建模EPR和APT。该模型可使用序列对齐的配对数据进行训练,无需音符级对齐。此外,独立引入了一个基于扩散模型的性能风格推荐(PSR)模块,能够仅从乐谱内容生成多样且风格适配的风格嵌入。
- 创新:主要创新在于:(1) 首次通过统一框架和解耦表示联合建模EPR和APT,实现任务间互监督;(2) 提出无需音符级对齐的Seq2Seq EPR公式,降低了数据门槛;(3) 设计了PSR模块,模拟了演奏家从乐谱推断风格的能力,实现了自动化且可控的渲染。
- 结果:在ASAP基准数据集上,该联合模型在APT任务上取得了与SOTA方法相当的性能(例如,在MUSTER和ScoreSimilarity多项指标上表现优异)。在EPR任务上,其性能(Ours-Target)优于仅训练EPR的模型和部分基线,生成的演奏在方差、KL散度等指标上更接近人类演奏,主观评价也获得了高分。风格解耦通过表演者/作曲家识别实验和风格迁移测试得到了验证。
- 意义:该工作为音乐AI系统提供了更统一、灵活的处理范式,推动了无对齐监督学习在音乐领域的应用。PSR模块使得非专业用户也能轻松生成具有合适风格的音乐演奏,具有潜在的教育和创作辅助价值。
- 局限性:当前评估主要在古典钢琴音乐数据集上进行,对流行、爵士等更广泛风格的泛化性有待探索。模型复杂度较高,PSR作为独立模块增加了系统的两阶段训练和推理开销。
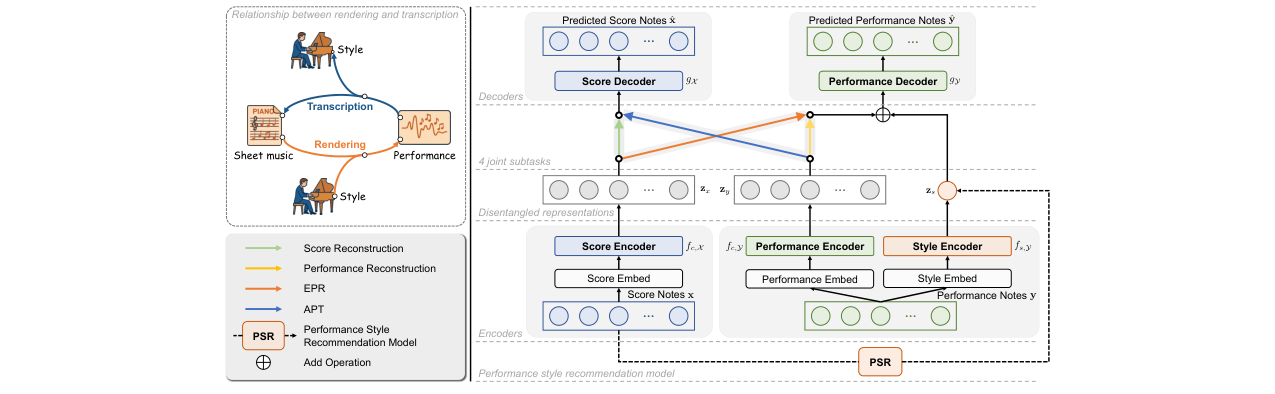
🏗️ 模型架构
论文提出的统一框架如图1所示,包含一个联合Transformer模型和一个独立的PSR模块。

联合模型架构(图1):
- 输入编码:
- 乐谱编码器 (Score Encoder):将乐谱序列
x(包含音高、时值等8个属性)编码为音符级内容表示zx。 - 演奏编码器 (Performance Encoder):将演奏MIDI序列
y(包含音高、IOI、时值、力度4个属性)编码为音符级内容表示zy。 - 风格编码器 (Style Encoder):从演奏序列
y中提取全局风格嵌入zs。它采用类似BERT的架构,在输入序列前添加一个<CLS>令牌,其最终隐藏状态作为zs。
- 乐谱编码器 (Score Encoder):将乐谱序列
- 解码与任务:
- 演奏渲染 (EPR):性能解码器
gY以zx(与zs相加)为条件,生成表现性MIDI序列ŷ。解码器输出采用结构化性能表示(Note-On, Duration, Velocity, Time-Shift)。 - 乐谱转录 (APT):乐谱解码器
gX以演奏内容表示zy为输入,生成乐谱序列x̂。
- 演奏渲染 (EPR):性能解码器
- 训练任务:联合训练包括四个子任务:
- APT:
gX(zy)预测x。 - EPR:
gY(zx ⊕ zs)预测y。 - 乐谱重建:从掩码乐谱
x̃重建x。 - 演奏重建:从掩码演奏
ỹ重建y。
- APT:
- 设计动机与交互:
- 内容-风格解耦:内容编码器
fc,X和fc,Y被训练以捕获乐谱相关的音符级信息,而风格编码器fs,Y捕获与演奏相关的全局风格信息。架构上,内容表示是序列(zx,zy),风格是单一向量(zs),实现了不同层级的表示。 - 双向监督:通过共享内容表示空间
Zc(鼓励zx和zy对齐)和利用风格信息zs,EPR和APT任务互相提供监督信号。 - 无对齐训练:模型采用Seq2Seq公式,仅需序列对齐的配对数据,避免了复杂的音符级对齐预处理。
- 内容-风格解耦:内容编码器
性能风格推荐(PSR)模块(图6):
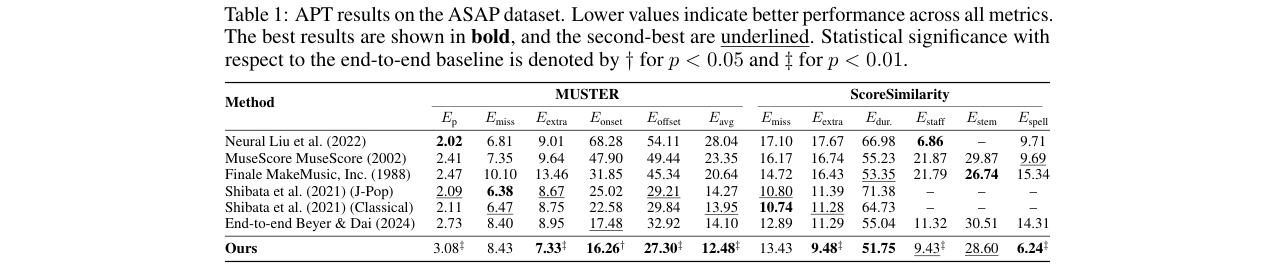
- 目的:仅从乐谱
x生成风格嵌入ẑs,用于条件化EPR解码器。 - 架构:
- 乐谱编码器
fg,X:另一个Transformer编码器,从乐谱序列提取全局内容嵌入eg(同样使用<CLS>令牌)。 - 扩散去噪网络
gs:基于DDPM(使用速度预测),以eg和带噪声的风格向量zt_s以及时间步t为输入,预测噪声或速度目标。
- 乐谱编码器
- 训练:使用预训练联合模型冻结的编码器提取真实演奏的
zs作为目标。训练扩散模型学习条件分布p(zs | eg)。 - 推理:从高斯噪声采样,结合乐谱嵌入
eg迭代去噪,生成风格向量ẑs,用于驱动EPR解码器。
💡 核心创新点
- 统一建模互逆任务:首次提出一个联合框架同时处理表现性演奏渲染(EPR)和自动钢琴转录(APT)。这打破了以往独立处理的范式,通过任务间的双向监督(共享内容表示空间)提升了学习效率和性能,并使得模型能同时理解音乐的符号层面和表现层面。
- 无音符级对齐的Seq2Seq EPR公式:将EPR建模为序列到序列转换任务,使用结构化MIDI令牌输出,摆脱了对精细音符级对齐数据的依赖。这降低了数据准备门槛,增强了模型处理复杂节奏(如装饰音)的灵活性,并使得利用大量无对齐的序列数据(如乐谱库、演奏录音转录的MIDI)成为可能。
- 基于扩散的性能风格推荐(PSR):创新性地引入了独立的PSR模块,该模块学习从乐谱内容直接生成合适的演奏风格嵌入。这模拟了人类演奏家解读乐谱并选择恰当演绎风格的过程,实现了“一键式”自动化风格感知渲染,极大地提升了用户体验和系统的实用性。
🔬 细节详述
- 训练数据:
- 配对数据:ASAP数据集(Foscarin et al., 2020),包含967首高质量钢琴曲及其乐谱-演奏对齐标注,按8:1:1划分训练/验证/测试集。
- 无配对乐谱数据:从MuseScore收集的75,913个公共领域MusicXML文件,经过规则过滤(如确保双谱表、音符数>100、小节数>10等)。
- 无配对演奏数据:从YouTube获取钢琴演奏视频,使用Aria-AMT模型转录为MIDI。
- 评估数据:ATEPP数据集(Zhang et al., 2022),用于评估风格表示的泛化性和可解释性(包含11,674个表演,标注了作曲家和演奏者信息)。
- 损失函数:总损失
Ltotal包含四部分(公式6):- 配对有监督损失:
LEPR(EPR任务的交叉熵) +LAPT(APT任务的交叉熵)。 - 无配对重建损失:
Lrec,X(掩码乐谱重建交叉熵) +Lrec,Y(掩码演奏重建交叉熵)。重建损失的权重λrec = 0.2。 - 正则化损失:
LKL,即风格嵌入的KL散度损失(公式5),鼓励zs服从标准正态先验N(0,I),促进潜在空间平滑和多样性。权重λKL = 0.1。
- PSR模块损失:
LPSR(公式12),使用均方误差(MSE)预测扩散过程中的速度目标。
- 配对有监督损失:
- 训练策略:
- 优化器:AdamW(Loshchilov & Hutter, 2019)。
- 学习率调度:余弦衰减学习率调度,带有线性预热。
- Batch Size:联合模型总batch size为36个序列(每个序列256个音符),在3张NVIDIA A5000 GPU上训练。PSR模型在单GPU上以batch size 48训练。
- 训练步数:联合模型训练40,000步,学习率峰值5e-5,预热4,000步。PSR模型使用相同调度,学习率峰值1e-4。
- 正则化:对解码器输入应用掩码(APT任务掩码率0.75,EPR任务掩码率0.2),防止模型过度依赖局部历史,鼓励学习长程依赖。
- 混合精度:使用fp16进行混合精度训练。
- 关键超参数与模型细节:
- 嵌入维度:统一为
D=512。 - Transformer层:编码器和解码器均为6层,8头注意力。
- 位置编码:旋转位置编码(RoPE)。
- 归一化与激活:预层归一化(Pre-LN),SwiGLU激活函数,前馈网络隐藏维度3072。
- 总参数量:联合模型约188.21M参数。
- 输出表示:乐谱输出采用Beyer & Dai (2024)的表示;演奏输出采用结构化令牌表示(Huang & Yang, 2020),通过MidiTok库实现。
- 嵌入维度:统一为
- 推理细节:
- APT推理:直接使用乐谱解码器
gX进行自回归解码。 - EPR推理:使用性能解码器
gY,条件为zx ⊕ ẑs(ẑs可以是提取的真实风格zs或PSR生成的ẑs)。解码策略为自回归,未提及具体的温度或beam search。 - PSR推理:迭代去噪过程,具体步数未在正文中说明。
- APT推理:直接使用乐谱解码器
📊 实验结果
APT任务结果(ASAP数据集):
| 方法 | MUSTER (Ep↓) | MUSTER (Emiss↓) | MUSTER (Eextra↓) | MUSTER (Eonset↓) | MUSTER (Eoffset↓) | MUSTER (Eavg↓) | ScoreSimilarity (Emiss↓) | ScoreSimilarity (Eextra↓) | ScoreSimilarity (Edur.↓) | ScoreSimilarity (Estaff↓) | ScoreSimilarity (Espell↓) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Neural Liu et al. (2022) | 2.02 | 6.81 | 9.01 | 68.28 | 54.11 | 28.04 | 17.10 | 17.67 | 66.98 | 6.86 | 9.71 |
| MuseScore | 2.41 | 7.35 | 9.64 | 47.90 | 49.44 | 23.35 | 16.17 | 16.74 | 55.23 | 21.87 | 9.69 |
| Finale | 2.47 | 10.10 | 13.46 | 31.85 | 45.34 | 20.64 | 14.72 | 16.43 | 53.35 | 21.79 | 15.34 |
| Shibata et al. (J-Pop) | 2.09 | 6.38 | 8.67 | 25.02 | 29.21 | 14.27 | 10.80 | 11.39 | 71.38 | - | - |
| Shibata et al. (Classical) | 2.11 | 6.47 | 8.75 | 22.58 | 29.84 | 13.95 | 10.74 | 11.28 | 64.73 | - | - |
| End-to-end Beyer & Dai (2024) | 2.73 | 8.40 | 8.95 | 17.48 | 32.92 | 14.10 | 12.89 | 11.29 | 55.04 | 11.32 | 14.31 |
| Ours | 3.08‡ | 8.43 | 7.33‡ | 16.26† | 27.30‡ | 12.48‡ | 13.43 | 9.48‡ | 51.75 | 9.43‡ | 6.24‡ |
| 注:↓表示越低越好。†表示p<0.05,‡表示p<0.01相对于End-to-end基线�� | |||||||||||
| 关键结论:本文模型在多项关键指标(如Eextra, Eonset, Eoffset, Emiss(Score), Espell)上取得了最优或次优结果,且统计显著。这证明了其学习到的内容表示能有效捕获音高、节奏和结构信息,并且无对齐的Seq2Seq公式具有竞争力。 |
EPR任务结果: 目标统计(ASAP测试集):
| 方法 | σ²(O) | σ²(D) | σ²(V) | KL(D) | MAE(D) | KL(V) | MAE(V) |
|---|---|---|---|---|---|---|---|
| Human | 0.12ᵃ | 1.72ᵃ | 241.04ᵃ | - | - | - | - |
| Score | 0.07ᵃ | 0.07ᵇ | 1.36ᵇ | 13.01ᵃ | 0.46ᵃᵇ | 13.00ᵃ | 29.14ᵃ |
| DExter | 0.20ᵇ | 4.15ᶜ | 238.86ᵃ | 1.48ᵇ | 0.88ᶜ | 2.32ᵇ | 24.27ᵇ |
| VirtuosoNet | 0.02ᶜ | 0.03ᵈ | 52.54ᶜ | 5.72ᶜᵈ | 0.48ᵃ | 4.91ᶜ | 14.40ᶜ |
| EPR-Only | 0.03ᶜ | 0.67ᵉ | 126.04ᵈ | 6.43ᶜ | 0.42ᵈ | 2.05ᵇ | 10.65ᵈ |
| Ours (Target) | 0.02ᶜ | 0.58ᶠ | 151.03ᵉ | 5.51ᵈ | 0.37ᵉ | 1.76ᵈ | 10.33ᵈ |
| Ours (PSR) | 0.02ᶜ | 0.33ᵉ | 161.51ᶠ | 6.19ᶜ | 0.44ᵇ | 2.67ᵉ | 15.24ᵉ |
| 注:同一列不同字母表示显著差异(p<0.01)。 | |||||||
| 关键结论:Ours (Target) 在多个分布度量(如KL(D), MAE(D), KL(V), MAE(V))上取得最佳,其生成的演奏在力度和时值的变化上最接近人类演奏。Ours (Target) 优于EPR-Only变体,表明联合建模和无配对数据提升了EPR性能。 |
准确率(ASAP测试集):
| 方法 | Align ↑ | Insert ↓ | Miss ↓ |
|---|---|---|---|
| Score | 93.52ᵃ | 3.57ᵃ | 2.91ᵃ |
| DExter | 91.27ᵇ | 5.11ᵇ | 3.62ᵇ |
| VirtuosoNet | 91.88ᶜ | 4.23ᵃ | 3.90ᶜ |
| Ours (Target) | 91.55ᵈ | 4.13ᵇ | 4.32ᵈ |
| Ours (PSR) | 92.27ᵃ | 3.77ᶜ | 3.96ᵃ |
| 关键结论:Ours (PSR) 在对齐率和插入率上表现最佳,显示了其无对齐Seq2Seq公式的有效性。 |
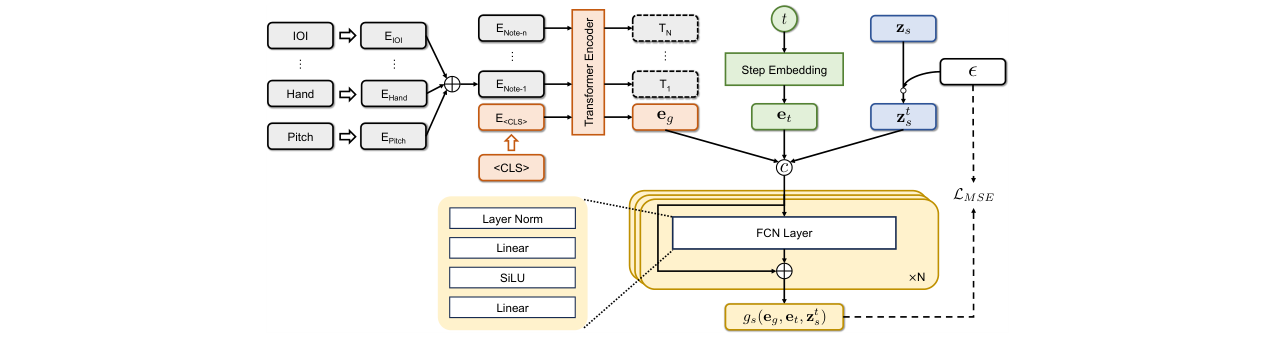
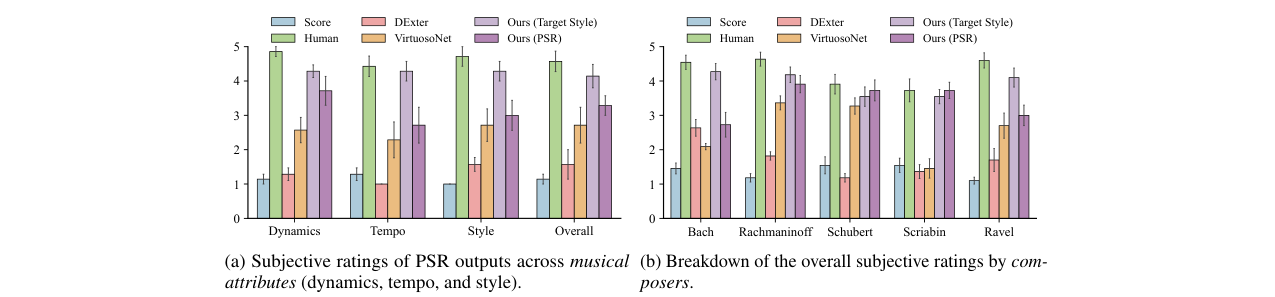
关键结论(图2):主观听觉测试表明,Ours (Target) 在动态、节奏、风格和整体拟人性所有维度上评分最高,Ours (PSR) 紧随其后且优于基线。分作曲家来看,模型在巴赫和斯克里亚宾作品上表现尤其突出。
表示解耦验证: 在ATEPP数据集上的表演者/作曲家识别准确率(%):
| 设置 | F1 | Recall | Precision | Acc. |
|---|---|---|---|---|
| Style → Perf | 25.82 | 25.67 | 27.80 | 42.07 |
| Cont → Perf | 0.74 | 2.02 | 0.46 | 9.94 |
| Style → Comp | 52.45 | 50.29 | 55.99 | 77.46 |
| Cont → Comp | 3.03 | 4.66 | 3.75 | 29.99 |
关键结论:使用风格表示zs的分类器在识别演奏者和作曲家方面远优于使用内容表示zc的分类器,这强力证明了内容与风格的成功解耦。zs编码了更多关于演奏者个性和作曲家风格的信息。 |
关键结论(图3):真实演奏的风格嵌入在二维投影中形成了清晰的作曲家和演奏者聚类,进一步直观证明了解耦的有效性。
PSR有效性评估:
关键结论(图4):PSR模型从乐谱生成的风格嵌入(右图)与从真实表演提取的风格嵌入(左图)在按音乐史时期(巴洛克、古典、浪漫、现代)的聚类结构上高度相似,表明PSR能生成具有音乐意义且风格适配的嵌入。
风格迁移评估:
关键结论(图5):风格迁移测试中,“Target”条件在风格相似性上评分最高,表明成功实现了风格转移;“Mean”(风格插值)条件在整体质量上表现稳定,表明学习到的风格空间结构良好,支持平滑插值。
⚖️ 评分理由
- 学术质量:6.0/7:
- 创新性 (2/2):将互逆音乐任务统一建模、提出无对齐Seq2Seq EPR、设计PSR模块,均为有明确动机和价值的创新点。
- 技术正确性 (2/2):模型架构设计合理,损失函数构成清晰,训练策略详细,理论推导(如扩散过程)正确。
- 实验充分性 (1.5/2):实验设计全面,涵盖了APT、EPR的客观/主观评估,表示解耦的验证(分类、可视化),以及PSR和风格迁移的评估。消融研究(无配对数据比例、KL权重)也得到了展示。
- 证据可信度 (0.5/1):大部分实验有详细的统计显著性检验(Wilcoxon检验,p值标注)。结果表格和图表清晰。但部分主观测试细节(参与者背景、具体音频)依赖附录,主文信息有限。
- 选题价值:1.5/2:
- 前沿性与影响 (1/1):解决音乐信息检索中的基础问题,推动了该领域向更统一、更智能的方向发展,符合AI for Music的当前趋势。
- 应用空间与相关性 (0.5/1):应用明确(音乐教育、自动伴奏、作曲辅助),对音乐和音频AI领域的研究者有较高价值。但对更广泛的语音/音频社区直接相关性中等。
- 开源与复现加成:0.5/1:
- 论文承诺在接收后开源代码,并提供了Demo链接(https://wei-zeng98.github.io/joint-apt-epr/)。
- 训练细节(数据处理、超参数、模型结构)在附录中描述得非常详细,复现友好度较高。
- 扣分原因:截至论文提交时代码未公开,主要的依赖开源项目(如MidiTok, Partitura)已被引用,但模型权重未提及公开。