📄 Beyond Instance-Level Alignment: Dual-Level Optimal Transport for Audio-Text Retrieval
#音频检索 #最优传输 #对比学习 #跨模态 #鲁棒性
✅ 7.5/10 | 前25% | #音频检索 | #最优传输 | #对比学习 #跨模态
学术质量 6.5/7 | 选题价值 1.0/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Wenqi Guo(上海交通大学)
- 通讯作者:Shikui Tu(上海交通大学),Lei Xu(上海交通大学,广东省人工智能与数字经济实验室(深圳))
- 作者列表:Wenqi Guo(上海交通大学)、Shikui Tu(上海交通大学)、Lei Xu(上海交通大学,广东省人工智能与数字经济实验室(深圳))
💡 毒舌点评
亮点:论文从“特征通道可靠性”这一细粒度视角切入,用最优传输的语言重新定义了跨模态对齐问题,理论推导(集中界分析)为小批次下的不稳定性提供了有说服力的解释,这比单纯堆砌模块更显功力。短板:虽然实验全面,但核心创新(双层对齐+可靠性边际)的物理直觉略显复杂,且声称“特征级OT计算开销可忽略”这一论断,在真实部署场景(如视频检索、超长音频)下的泛化能力值得商榷。
🔗 开源详情
- 代码:论文中未提及代码链接。附录A提供了伪代码,但未指明完整实现代码的发布渠道。
- 模型权重:未提及。
- 数据集:使用了公开的AudioCaps、Clotho、ESC-50数据集,但论文中未提供获取链接或特殊处理说明。
- Demo:未提及。
- 复现材料:论文附录提供了极其详细的超参数设置(表6)、训练算法伪代码、理论证明、数据集统计、评估指标定义等,复现所需的信息非常充分。
- 论文中引用的开源项目:未明确列出。提到了使用预训练的编码器(如ResNet38, BERT, Beats等),但未指定具体版本或来源。
- 总体评估:论文具备高质量的复现指南,但缺少最直接的开源代码和权重链接,对快速复现构成障碍。论文中未提及明确的开源计划。
📌 核心摘要
- 问题:现有的跨模态检索方法(如对比学习、逆最优传输IOT)主要进行实例级对齐,隐含假设所有嵌入维度同等重要。在小批次训练中,这种假设会放大噪声和偏差,导致对齐信号不稳定。
- 方法核心:提出DART(双层对齐鲁棒传输)框架。它在实例级保留IOT目标以对齐样本对,同时引入特征级正则化。该正则化将每个特征维度视为一个分布,并使用非平衡Wasserstein距离(UWD) 来对齐音频和文本的特征分布。此外,设计了可靠性感知边际(RAM),基于方差、峰度和跨模态相关性动态加权特征通道,抑制噪声通道。
- 与已有方法相比新在哪里:1)超越单一的实例级对齐,增加特征级分布对齐,提供细粒度的正则化。2)RAM能自适应地识别并强调跨模态一致且稳定的语义通道。3)提供了理论分析,证明实例级损失受最大距离控制,而特征级损失受传输计划的Frobenius范数控制,后者在小批次下更鲁棒。
- 主要实验结果:在AudioCaps和Clotho两个主要基准上,DART在多个编码器设置下均达到或超越SOTA。例如,在AudioCaps(ResNet38+BERT)上,相比最强基线Luong et al. (2024),文本到音频检索R@1提升1.1个百分点,音频到文本提升4.5个百分点。在模拟小批次(k=8, 32)和噪声/半监督标签(20%,40%)的严苛条件下,DART展现出显著更强的鲁棒性。详见下表。
| 条件 | 方法 | 文本->音频 (R@1) | 音频->文本 (R@1) |
|---|---|---|---|
| 标准设置 (Batch=256, AuC) | Luong et al. (2024) | 39.10 | 49.94 |
| DART w/ RAM | 41.67 | 55.27 | |
| 小批次 (Batch=8, AuC) | Luong et al. (2024) | 20.44 | 32.91 |
| DART (LIOT+LUWD) | 24.24 | 35.21 | |
| 40%噪声标签 (Batch=32, AuC) | Luong et al. (2024) | 26.20 | 34.37 |
| DART | 29.67 | 37.09 | |
| 零样本声音事件检测 (ESC-50) | IOT (Luong et al.) | - | 79.25 (R@1) |
| DART | - | 80.75 (R@1) |
- 实际意义:该方法为在资源受限(小批次、标注稀缺)或噪声数据环境下的跨模态检索提供了更鲁棒的解决方案,具有实际部署价值。其思想可推广至其他跨模态任务(如图文检索已验证)。
- 主要局限性:特征级OT的计算复杂度随特征维度平方增长,虽在文中声称开销小,但在超高维嵌入或极大批次下可能成为瓶颈;理论分析基于一系列理想化假设,与实际情况可能有差距。
🏗️ 模型架构
DART是一个端到端的跨模态对齐框架,其核心在于联合优化两个损失:实例级损失($\mathcal{L}{IOT}$)和特征级损失($\mathcal{L}{UWD-R}$)。整体流程如下:
- 输入与编码:输入为音频-文本对。使用音频编码器 $f_\theta$ 和文本编码器 $g_\phi$ 分别提取嵌入向量。对于一个mini-batch,得到音频特征矩阵 $U_b \in \mathbb{R}^{k \times d_u}$ 和文本特征矩阵 $V_b \in \mathbb{R}^{k \times d_v}$。
- 实例级对齐($\mathcal{L}_{IOT}$):
- 计算样本间代价矩阵:$C^{Sample}{b}[i,j] = d(U{b}[i,:], V_{b}[j,:])$,其中 $d$ 为欧氏距离。
- 使用熵正则化最优传输(Sinkhorn算法)求解耦合矩阵 $\Pi_b$,使其逼近真实匹配 $\hat{\Pi}_b$(单位阵)。
- 损失为 $\mathcal{L}_{IOT} = KL(\hat{\Pi}_b | \Pi_b)$,旨在拉近匹配样本对,推远不匹配对。
- 特征级对齐($\mathcal{L}_{UWD-R}$):
- 构建特征代价矩阵:将每个特征维度视为一个分布($k$维向量)。计算特征级代价矩阵 $C^{Feature}_b \in \mathbb{R}^{d_u \times d_v}$,其元素 $C^{Feature}_b[i,j] = | U_b[:,i] - V_b[:,j] |_2^2$,衡量第 $i$ 个音频特征维度与第 $j$ 个文本特征维度在批次内的分布距离。
- 可靠性感知边际(RAM)生成:对每个特征通道 $j$,计算可靠性分数 $r_j$,公式综合了跨模态相关性(高为好)、方差不稳定性(高为坏)、峰度(高为坏),并通过Sigmoid映射到(0,1)。将分数归一化为概率分布 $u_b, v_b$,作为UWD的先验边际。
- 求解非平衡最优传输:以 $C^{Feature}b$ 为代价,以 $u_b, v_b$ 为边际(通过KL项软约束),求解传输计划 $P_b$。损失为 $\mathcal{L}{UWD-R} = \langle C^{Feature}_b, P_b \rangle$。
- 作用:RAM引导传输质量向高可靠性的语义通道倾斜,UWD本身会因噪声通道的高传输成本而自然抑制它们。
- 总损失:$\mathcal{L}{total} = \mathcal{L}{IOT} + \lambda \mathcal{L}_{UWD-R}$,其中 $\lambda$ 是平衡权重。
- RAM稳定化:使用指数移动平均(EMA)跨批次更新可靠性分数 $r_j$,避免小批次估计的波动。
关键设计动机:实例级对齐是粗粒度的,易被少数噪声维度主导。特征级对齐提供了细粒度的、维度级别的正则化,与实例级信息互补,共同提升表征质量。
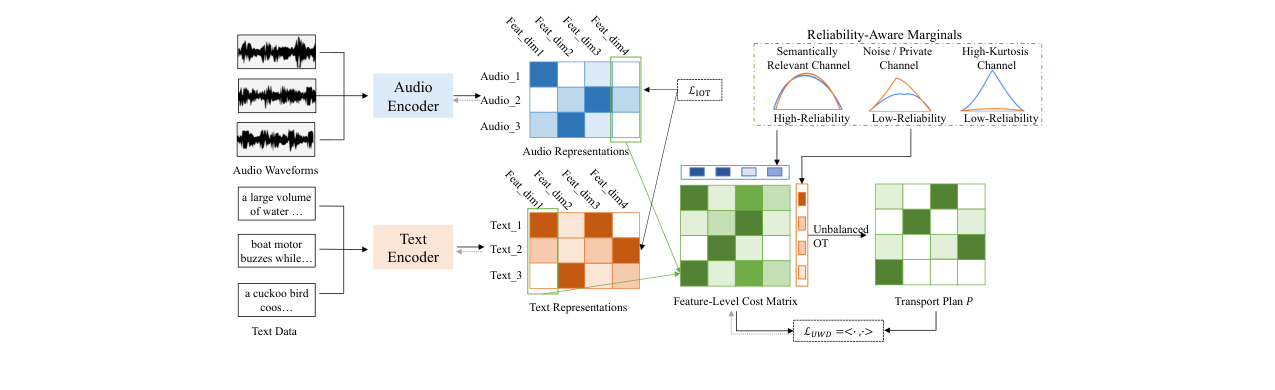
图1: DART框架概览图。展示了实例级($\mathcal{L}{IOT}$)和特征级($\mathcal{L}{UWD-R}$)双层优化路径。左侧为音频和文本表示,右侧显示通过UWD进行通道级对齐,RAM(可靠性感知边际)根据通道的可靠性(噪声/私有通道 vs. 语义相关通道)分配不同的质量。
💡 核心创新点
- 双层对齐框架(Dual-Level Alignment):首次系统性地将实例级对齐(样本级)与特征级对齐(维度级)结合用于音频文本检索。特征级对齐通过最优传输在分布层面约束通道对应关系,是对现有仅依赖实例级损失(如对比学习、三元组损失)的重要补充。
- 可靠性感知边际(Reliability-Aware Marginals, RAM):设计了一个基于统计量(相关性、方差、峰度)的通道可靠性评估机制,并将其转化为UWD的先验边际。这实现了自适应的通道加权,无需复杂的注意力网络,就能有效抑制噪声和模态特定通道。
- 理论集中界分析:从理论上证明了实例级损失($\mathcal{L}{IOT}$)的集中误差上界受最大正样本对距离 $D{max}$ 控制,解释了其在小批次下对离群点的敏感性。而特征级损失($\mathcal{L}_{UWD}$)的误差上界受传输计划的Frobenius范数 $|P^*|_F$ 控制,该范数是一个聚合量,对单个离群通道不敏感,因此提供了更紧致的界和更强的鲁棒性。
🔬 细节详述
- 训练数据:主要在AudioCaps(~50K对)和Clotho(~4K对)数据集上训练。数据为音频-文本配对,预处理细节未详细说明。
- 损失函数:总损失为实例级逆最优传输损失 $\mathcal{L}{IOT}$ 和特征级可靠性感知非平衡Wasserstein距离损失 $\mathcal{L}{UWD-R}$ 的加权和。超参数 $\lambda$ 用于平衡,实验显示在0.1-0.7范围内稳定。
- 训练策略:使用Adam或AdamW优化器,学习率在 $10^{-6}$ 到 $5\times10^{-5}$ 之间。批大小通常为256,但在鲁棒性测试中降至6-128。训练10个epoch。RAM的EMA平滑系数 $\beta=0.9$。
- 关键超参数:熵正则化参数 $\epsilon$ (用于IOT) 通常为0.03;非平衡OT中的KL正则化强度 $\tau$ 为0.05。特征维度 $d$ 因编码器而异。
- 训练硬件:论文未提及具体GPU型号和训练时长。
- 推理细节:对于检索,使用softmax归一化后的相似度得分(公式3)进行排序。
- 正则化/稳定技巧:RAM的EMA更新是核心稳定技巧。此外,UWD本身通过KL项实现了边际软约束,具有正则化效果。
📊 实验结果
论文在三个任务上进行了充分评估:音频文本检索、小批次/噪声标签鲁棒性、零样本声音事件检测,并扩展到图文检索。
表1:AudioCaps (AuC) 和 Clotho (Clo) 数据集上的检索性能(主要结果)
| 方法 | 编码器 | T->A (AuC) R@1 | A->T (AuC) R@1 | T->A (Clo) R@1 | A->T (Clo) R@1 |
|---|---|---|---|---|---|
| (Luong et al., 2024) | ResNet38+BERT | 39.10 | 49.94 | 16.65 | 22.10 |
| DART w/ RAM | ResNet38+BERT | 41.67 | 55.27 | 17.18 | 23.54 |
| (Wang et al., 2023) | CNN+BPE | 33.72 | 39.14 | 16.63 | 20.47 |
| DART w/ RAM | CNN+BPE | 33.42 | 43.30 | 20.07 | 26.79 |
| (Chen et al., 2023) | Beats+BERT | 54.2 | 66.9 | 36.7 | 25.9 |
| DART w/ RAM | Beats+BERT | 56.9 | 72.1 | 37.5 | 27.9 |
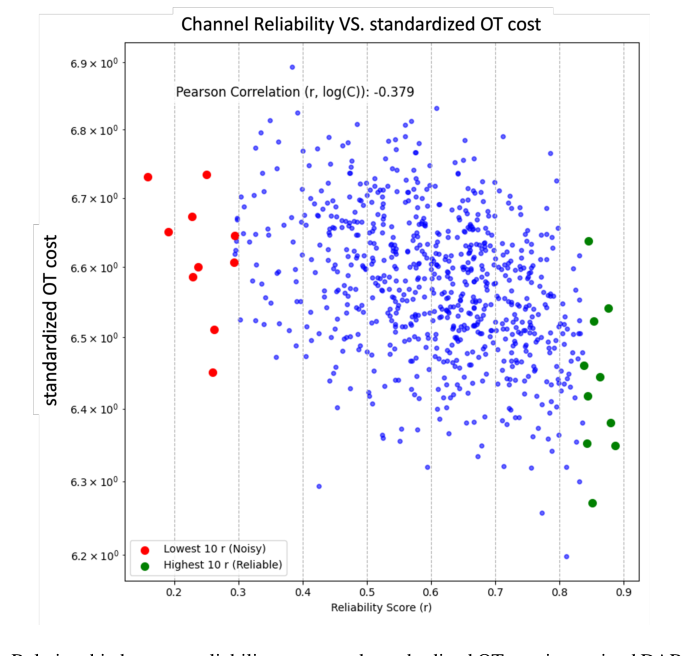
图2: 展示了在引入合成噪声后,OT成本与噪声水平σ的单调关系,为“噪声通道具有更高传输成本”的直觉提供了经验证据。 表2:不同小批次大小下的鲁棒性测试(AudioCaps)
| 批大小k | 方法 | T->A R@1 | A->T R@1 |
|---|---|---|---|
| 8 | Luong et al. (2024) | 20.44 | 32.91 |
| 8 | DART (LIOT+LUWD) | 24.24 | 35.21 |
| 32 | Luong et al. (2024) | 33.77 | 43.36 |
| 32 | DART (LIOT+LUWD) | 36.46 | 46.39 |
| 表3:零样本声音事件检测(ESC-50测试集) | |||
| 损失 | 音频->声音 R@1 | mAP | |
| :— | :— | :— | |
| Triplet loss | 71.25 | 80.09 | |
| Contrastive loss | 72.25 | 80.84 | |
| IOT (Luong et al.) | 79.25 | 87.09 | |
| DART | 80.75 | 87.78 |
消融研究与分析:
- 双层损失缺一不可:仅用$\mathcal{L}{UWD}$,R@1≈0;仅用$\mathcal{L}{IOT}$是基线;两者结合最优(表10)。
- RAM组件有效:去除RAM(用均匀边际)性能下降(表1)。单独分析RAM中各统计量(相关性、方差、峰度)表明,它们共同作用效果最佳(表5)。
- 与其他损失兼容:$\mathcal{L}_{UWD}$作为补充损失,与三元组损失、对比损失结合时均能带来提升(表11)。
- 超参数鲁棒性:在$\lambda$(0.1-0.7)、温度、不同边际分布下,性能稳定(表7,8,9)。
图6: 训练好的DART模型中,特征通道的可靠性分数$r_j$与标准化OT成本呈负相关(Pearson ρ ≈ -0.379)。低可靠性通道(红色)聚集在高成本区域,高可靠性通道(绿色)聚集在低成本区域,证实了RAM能有效识别并抑制噪声通道。
⚖️ 评分理由
- 学术质量:6.5/7:创新性体现在系统性的双层框架和RAM设计上,理论分析为方法提供了扎实的解释。实验非常充分,在多个数据集、多种编码器、多种设置(小批次、噪声)下验证了方法,消融研究完善。技术实现正确。主要扣分点在于理论假设与实际模型的差距,以及对特征级OT计算开销的讨论不够深入。
- 选题价值:1.0/2:音频-文本检索是成熟但重要的领域。论文聚焦于提升该任务在现实挑战性场景下的鲁棒性,有实际应用价值。但该方向竞争激烈,且本文更多是优化而非开创全新范式。
- 开源与复现加成:0.0/1:论文提供了非常详尽的附录,包括伪代码、超参数、实现细节,理论上复现友好度高。但当前文本中未包含任何指向代码仓库、模型权重或数据集获取方式的明确链接,因此根据规则,不能给予复现加成。若后续开源,此分可大幅提升。