📄 Better Together: Leveraging Unpaired Multimodal Data for Stronger Unimodal Models
#多模态模型 #音频分类 #自监督学习 #迁移学习 #少样本学习
✅ 7.0/10 | 前25% | #音频分类 | #自监督学习 #迁移学习 | #多模态模型 #自监督学习
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0 | 置信度 高
👥 作者与机构
- 第一作者:Sharut Gupta (MIT CSAIL)
- 通讯作者:未说明(论文中未明确标注通讯作者)
- 作者列表:Sharut Gupta (MIT CSAIL), Shobhita Sundaram (MIT CSAIL), Chenyu Wang (MIT CSAIL), Stefanie Jegelka (TU Munich, MIT CSAIL), Phillip Isola (MIT CSAIL)
💡 毒舌点评
亮点在于其理论部分严谨地证明了无配对多模态数据在信息论层面的价值,为“跨模态知识蒸馏无需配对”提供了坚实论据,实验也相当全面。短板是UML的框架(共享权重,交替训练)相对直观,并非一个复杂的“新模型”,且其实验验证主要围绕视觉分类,对理论承诺的“适用于音频”只做了初步展示,深度稍显不足。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。仅提供了项目主页(https://unpaired-multimodal.github.io/)。
- 模型权重:未提及公开预训练或训练好的模型权重。
- 数据集:实验中使用的数据集均为公开基准(MultiBench, ImageNet-ESC, 以及各种标准图像分类数据集)。
- Demo:未提供在线演示。
- 复现材料:提供了非常详细的复现材料。附录B包含了完整的实验细节,如硬件环境(V100 GPU)、数据集描述与预处理、训练协议(优化器、学习率范围、轮数等)、以及超参数搜索网格(Table 5)。这为研究者复现实验提供了充分的信息。
- 论文中引用的开源项目:论文依赖了多个开源模型和库,包括:
- 视觉编码器:ViT (Dosovitskiy et al., 2020), DINOv2, CLIP。
- 文本编码器:OpenLLaMA, BERT (Devlin et al., 2019), RoBERTa, GPT-2。
- 音频编码器:AudioCLIP (Guzhov et al., 2021)。
- 框架:PyTorch。
- 优化器:AdamW (Loshchilov & Hutter, 2017)。
- 数据集:MultiBench (Liang et al., 2021), ImageNet-ESC (Lin et al., 2023) 等。
📌 核心摘要
本文旨在解决多模态学习中对昂贵且有限的配对数据(如图像-文本对)的依赖问题。其核心方法是提出无配对多模态学习器(UML),这是一个模态无关的训练范式,让单一模型在不同模态的输入(如图像和文本)之间交替训练并共享权重。这一设计基于不同模态是对同一底层现实的不同投影的假设,使得模型无需显式的对齐关系就能从跨模态结构中受益。与已有方法相比,UML的新颖之处在于它完全摒弃了对模态间配对关系的要求,甚至摒弃了用于推断对齐的中间目标。理论上,论文在线性数据生成假设下证明了,加入无配对的辅助模态数据可以严格增加关于共享潜在变量的Fisher信息,从而得到更准确的表示。实验上,论文展示了UML在多个图像和音频分类基准上,无论是自监督还是监督、少样本还是全数据设置下,都能稳定提升仅基于目标模态的基线模型性能。例如,在MUSTARD数据集上,图像表示的分类准确率从59.66%提升至63.28%(Table 1)。实际意义在于,该方法能够轻松利用互联网上大量存在的、无需配对的多模态数据来提升特定模态模型的性能,具有广泛的应用潜力。其主要局限性在于,目前的实验主要集中在分类任务,对生成等其他任务的有效性有待验证,且论文未深入探究无配对设置下可能出现的梯度干扰、模态崩溃等优化挑战。
🏗️ 模型架构
UML的核心是一个模态无关的共享权重网络。其整体流程如下:
- 输入:接收来自不同模态(如图像、文本、音频)的独立样本。每个模态有其特定的输入格式。
- 模态特定编码器:每种模态使用一个初始的编码器(可以是预训练的,如DINOv2用于图像,OpenLLaMA用于文本)将原始输入转换为特征向量(嵌入)。例如,图像被转换为patch嵌入,文本被转换为token嵌入。
- 共享网络 (h):所有模态的特征向量被投影到一个共享的嵌入空间后,都通过同一个共享的神经网络(如Transformer)。这是UML的核心,使得来自不同模态的梯度能够更新同一组参数,从而累积跨模态的知识。
- 模态特定解码头/分类头:
- 自监督设置(图4a):每个模态有自己独立的解码器(
g_X,g_Y),其目标是根据共享网络h的输出重构或预测该模态的原始输入(如下一个token/patch)。不同模态的损失函数独立计算并求和。 - 监督设置(图4b):共享网络
h的输出被送入一个共享��分类器头,用于预测该样本所属的类别标签。不同模态的损失函数同样独立计算并求和。
- 自监督设置(图4a):每个模态有自己独立的解码器(
- 训练:模型交替(或混合批次)处理来自不同模态的数据,损失函数是各模态损失之和。梯度同时更新共享网络
h和各模态特定的编码器/解码头(或分类头)。 - 推理:在推理时,只使用目标模态的路径(例如,只使用图像编码器
f_X和共享网络h),丢弃辅助模态的路径。h的输出作为增强后的目标模态表示,用于下游任务(如在上面训练一个线性探测器)。
关键设计选择的动机是:假设不同模态共享一个底层的现实表示,通过共享权重强制模型学习对所有模态都有用的通用特征,从而实现无需配对的跨模态知识迁移。
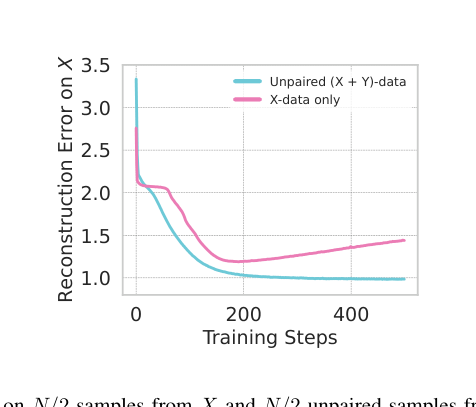
(图1:展示了未配对多模态表示学习的概念,即文本即使不与图像直接配对,也能提供互补信息。UML通过跨模态共享权重来提取协同效应。)
(图4:详细展示了UML在自监督(a)和监督(b)设置下的具体架构。左图显示不同模态的输入被token化并嵌入;右图展示了两种设置下数据流经共享网络和模态特定模块的过程。)
💡 核心创新点
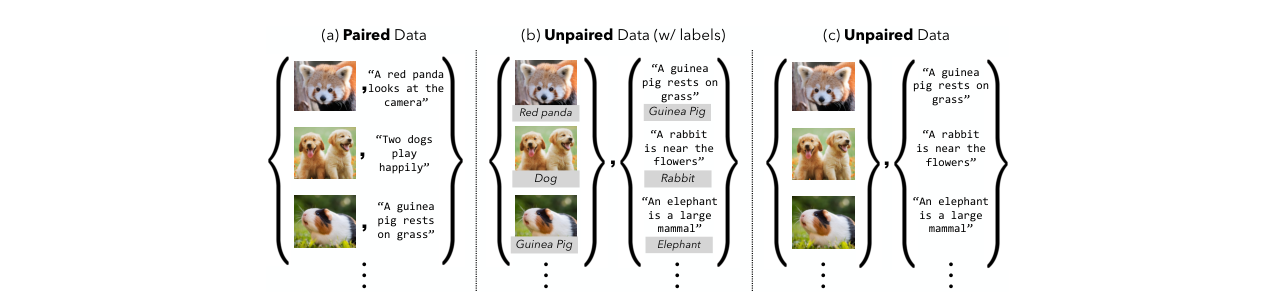
- 利用无配对多模态数据提升单模态模型:明确了研究问题——在没有一一对应关系(配对)的情况下,仅使用目标模态和辅助模态的边际分布数据,是否以及如何提升目标模态模型的性能。这是对传统“必须配对”范式的直接挑战。
- 理论证明无配对数据的信息增益:在线性模型假设下,严格证明了引入无配对的辅助模态数据可以严格增加关于共享潜在变量的Fisher信息,从而降低估计方差(定理1,2)。甚至指出在特定方向,一个辅助模态样本的“价值”可能超过一个目标模态样本(定理3)。
- 简单有效的UML框架:提出了一个极其简洁的实现方式——跨模态权重共享与交替训练。无需复杂的对齐损失、翻译模块或聚类步骤,仅通过让梯度在共享参数上累积,就实现了理论预测的信息增益。这证明了机制的有效性和框架的通用性。
- 量化模态间的“汇率”:创新性地提出了“边际替代率”概念,通过实验(图8,9)量化了图像与文本数据之间的性能转换比率,回答了“一张图像值多少个词”的问题,为数据收集和资源分配提供了直观指导。
🔬 细节详述
- 训练数据:
- 自监督实验:使用MultiBench数据集(包含医疗、情感计算、多媒体等领域的图像-文本或多模态数据集)和标准视觉-文本分类基准(Oxford Pets, UCF101, DTD)。文本和图像特征使用预训练的DINOv2和OpenLLaMA提取。
- 监督实验:使用9个标准视觉分类基准(如Stanford Cars, SUN397, Caltech101等)。图像使用ViT-S/14 DINOv2编码,文本使用OpenLLaMA-3B编码器生成模板化类别描述(如“a photo of a {}”)。
- 音频实验:使用ImageNet-ESC基准(ImageNet-ESC-19和-27),结合图像、文本和音频(ESC-50环境声)模态。音频编码使用AudioCLIP。
- 数据增强:论文未说明使用了特定的数据增强策略(如裁剪、翻转),但依赖于预训练编码器的鲁棒性。
- 损失函数:
- 自监督 (LUML-SSL):各模态损失之和。对于连续目标(如图像重建)使用均方误差(MSE);对于离散token(如文本)使用交叉熵损失。
- 监督 (LUML-Sup):各模态分类交叉熵损失之和。
- 训练策略:
- 优化器:AdamW。
- 学习率:通过网格搜索在
{0.001, 1e-4}中选择。 - 批大小:
{8, 32}。 - 轮数/步数:自监督模型训练100个epoch;监督线性探测模型最多训练12800次迭代,并设有早停机制。
- 调度策略:使用余弦学习率调度器,带有线性warmup。
- 其他:实验使用单卡NVIDIA Tesla V100 GPU (32GB) 进行。
- 关键超参数:
- 共享网络
h:在MultiBench上为5层5头Transformer;在视觉-文本基准上为4层4头Transformer。 - 嵌入维度:通过模态特定的线性层投影到共享维度(如10, 40, 150, 256, 300等)。
- 训练启动策略:可能存在一个“课程”参数
step,控制先用单模态训练多少epoch再切换到联合训练。
- 共享网络
- 推理细节:在推理时,仅使用目标模态路径。共享网络
h的输出(如CLS token或均值池化后的嵌入)被用作特征,用于下游线性探测或微调。未说明使用特殊的解码策略(如beam search)。 - 正则化或稳定训练技巧:论文提及对所有方法都进行了严格的超参数调优。使用了dropout(概率0.1)和权重衰减(如0.01)。未专门提及针对无配对训练的特殊稳定技巧。
📊 实验结果
主要结果表格:
Table 1: 自监督设置下的性能对比(线性探测准确率,%)
| 数据集 (MultiBench / 标准视觉-文本) | 方法 | MUSTARD | MIMIC | MOSEI | MOSI | UR-FUNNY | Oxford Pets | UCF101 | DTD | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|
| 无配对基线 | 59.66 | 55.16 | 70.62 | 56.17 | 56.99 | 85.04 | 79.86 | 78.13 | - | |
| UML (本方法) | 63.28 ↑ | 57.10 ↑ | 71.98 ↑ | 58.16 ↑ | 57.34 ↑ | 86.32 ↑ | 80.98 ↑ | 78.49 ↑ | - |
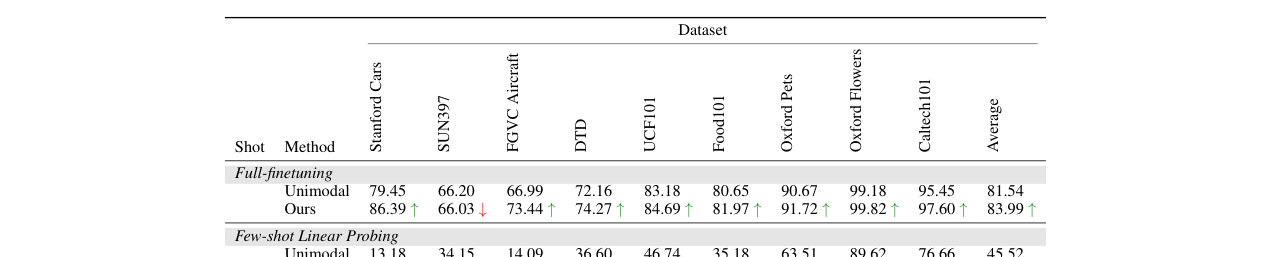
Table 2: 监督设置下的性能对比(使用DINOv2和OpenLLaMA)
全量微调(Full-finetuning)
数据集 方法 Stanford Cars SUN397 FGVC Aircraft DTD UCF101 Food101 Oxford Pets Oxford Flowers Caltech101 平均 无配对基线 79.45 66.20 66.99 72.16 83.18 80.65 90.67 99.18 95.45 81.54 UML (本方法) 86.39 ↑ 66.03 ↓ 73.44 ↑ 74.27 ↑ 84.69 ↑ 81.97 ↑ 91.72 ↑ 99.82 ↑ 97.60 ↑ 83.99 ↑ 少样本线性探测(1-shot)
数据集 方法 Stanford Cars SUN397 FGVC Aircraft DTD UCF101 Food101 Oxford Pets Oxford Flowers Caltech101 平均 无配对基线 13.18 34.15 14.09 36.60 46.74 35.18 63.51 89.62 76.66 45.52 UML (本方法) 16.49 ↑ 41.79 ↑ 15.63 ↑ 42.04 ↑ 52.33 ↑ 42.27 ↑ 73.59 ↑ 93.64 ↑ 84.52 ↑ 51.36 ↑ 少样本线性探测(4-shot)
数据集 方法 Stanford Cars SUN397 FGVC Aircraft DTD UCF101 Food101 Oxford Pets Oxford Flowers Caltech101 平均 无配对基线 38.76 57.51 32.10 59.69 67.75 60.79 83.89 98.59 93.48 65.84 UML (本方法) 43.17 ↑ 60.89 ↑ 33.86 ↑ 62.43 ↑ 71.13 ↑ 63.88 ↑ 87.36 ↑ 99.17 ↑ 94.96 ↑ 68.53 ↑
关键结论:
- 一致性提升:UML在所有测试的基准、所有设置(自监督/监督、少样本/全量)下,均一致地超过了仅使用图像的无配对基线模型。在细粒度任务(如Stanford Cars)和少样本场景下提升尤为明显。
- 模态越多,效果越好:扩展到音频-视觉-文本三模态时(图6),性能随辅助模态增加而单调提升。
- 鲁棒性增强:在ImageNet分布偏移测试集(V2, Sketch, A, R)上,UML训练的模型比无配对基线更鲁棒(图5)。
- 迁移学习有效:用预训练的语言模型(BERT)权重初始化视觉模型(ViT),能显著提升性能(图7),表明语义知识可跨模态迁移。
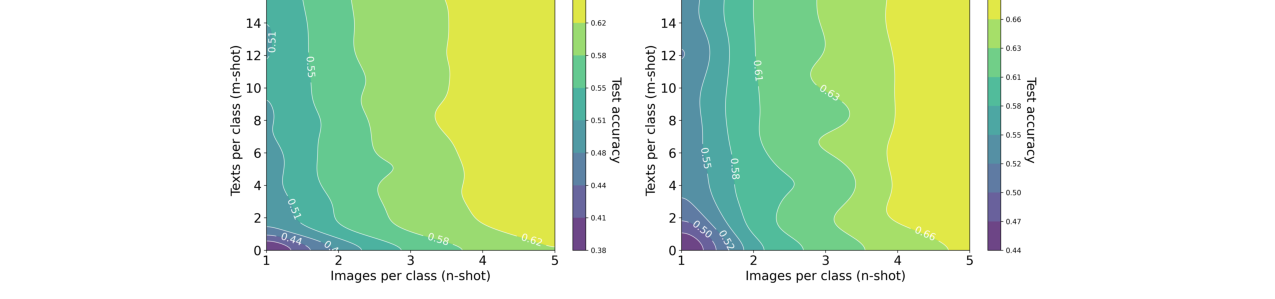
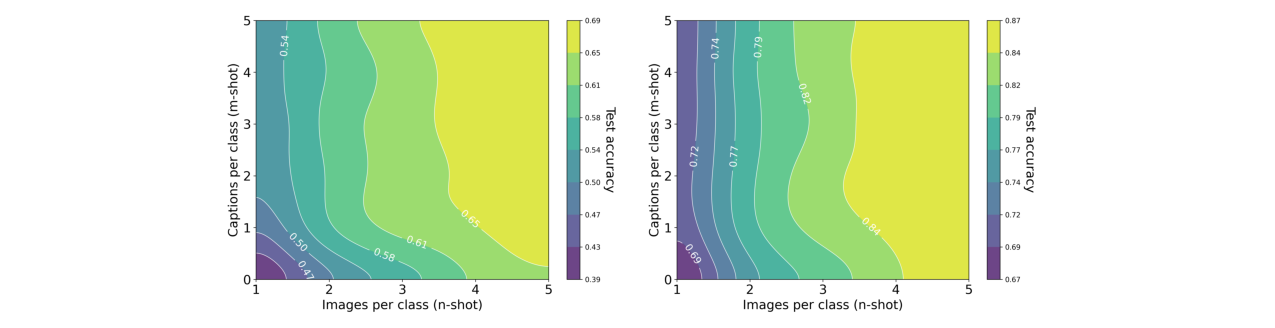
- 模态转换比率:在Oxford Pets上,使用对齐的CLIP编码器时,1张图像约等于228个词;使用未对齐的DINOv2+OpenLLaMA时,1张图像约等于1034个词(图8,9)。
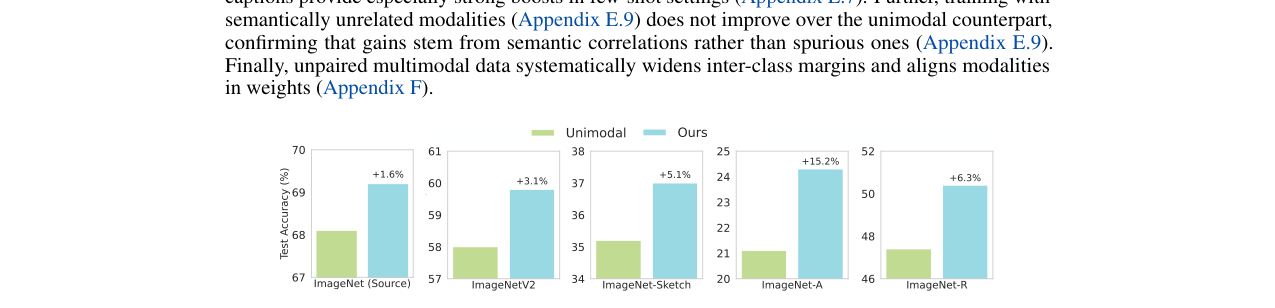
(图5:展示了UML方法在四个ImageNet分布偏移测试集上,相比无配对基线具有更高的测试准确率,表明其学习到了更鲁棒的特征。)
(图6:展示了在ImageNet-ESC音频分类任务上,使用UML结合无配对的图像和文本数据,能够显著提升仅基于音频的分类性能。)
(图7:展示了用BERT预训练权重初始化ViT的图像分类器,无论主干是否冻结,性能都优于从头训练的模型。)
(图8:显示了使用CLIP编码器时,在Oxford Pets数据集上达到相同性能所需的图像和文本样本数量关系,计算得出1张图像约等于228个词。)

(图9:显示了使用未对齐的DINOv2和OpenLLaMA编码器时,1张图像约等于1034个词,效率低于CLIP。)
⚖️ 评分理由
- 学术质量:5.5/7:论文的创新性体现在提出并系统研究了“利用无配对多模态数据提升单模态模型”这一问题,提出了简洁的UML框架,并提供了坚实的理论分析。技术正确性高,实验设计严谨、全面,覆盖了多种设置、基准和模态,结果具有很强的说服力。主要扣分点在于其框架本身(共享权重交替训练)并非一个极其复杂的架构创新,且理论分析基于线性假设,与深度网络的实际情况存在差距。
- 选题价值:1.5/2:选题非常前沿且具有实际意义,直接针对多模态学习中数据对齐的瓶颈问题。对于拥有海量无配对数据的领域(如多语言文本、网络图文、科学数据、音频文本),该研究提供了新的思路和方法,潜在影响广泛。对于音频/语音读者,论文中展示的音频分类提升和模态转换比率具有直接参考价值。
- 开源与复现加成:0/1:论文提供了详细的项目主页,附录中包含了几乎完整的实验复现细节(数据集、超参数、训练协议)。但核心的UML实现代码未开源,这使得读者无法直接复现或快速验证,也阻碍了方法在更广泛场景下的应用和改进。