📄 AVoCaDO: An Audiovisual Video Captioner Driven by Temporal Orchestration
#多模态模型 #强化学习 #视频描述生成 #音频视觉对齐 #监督微调
🔥 8.5/10 | 前25% | #视频描述生成 | #强化学习 | #多模态模型 #音频视觉对齐
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Xinlong Chen(快手技术 Kling 团队,中国科学院自动化研究所 NLPR,中国科学院大学)
- 通讯作者:Qiang Liu(中国科学院自动化研究所 NLPR,中国科学院大学)
- 作者列表:Xinlong Chen(快手技术 Kling 团队,中国科学院自动化研究所 NLPR,中国科学院大学)、Yue Ding(中国科学院自动化研究所 NLPR,中国科学院大学)、Weihong Lin(快手技术 Kling 团队)、Jingyun Hua(快手技术 Kling 团队)、Linli Yao(北京大学)、Yang Shi(北京大学)、Bozhou Li(北京大学)、Qiang Liu(中国科学院自动化研究所 NLPR,中国科学院大学)、Yuanxing Zhang(快手技术 Kling 团队)、Pengfei Wan(快手技术 Kling 团队)、Liang Wang(中国科学院自动化研究所 NLPR,中国科学院大学)
💡 毒舌点评
亮点: 论文没有满足于简单的多模态拼接,而是通过精心设计的 checklist 和 dialogue 奖励函数,将“音视频事件在时间轴上对齐”这一核心需求显式地融入了强化学习目标,这种针对具体问题定制 RL 奖励的思路比通用 GRPO 应用更有价值。 短板: 整个流程高度依赖强大的教师模型(如 Gemini-2.5-Pro)来构建 SFT 数据和评估奖励,这使得方法的泛用性和在资源受限场景下的可行性存疑,且可能隐含了将教师模型偏见传递给学生模型的风险。
🔗 开源详情
- 代码: 论文明确表示“AVoCaDO will be open-sourced”,并提供了项目主页链接 (
https://avocado-captioner.github.io/)。论文中未直接提供代码仓库链接,但项目主页很可能包含后续链接。 - 模型权重: 论文声明模型将开源,但未提供具体的权重下载链接或平台。
- 数据集: 论文详细描述了数据集的构建方法、来源和规模(107K),但未提及是否公开发布原始数据集或经过处理的描述数据集。获取构建数据集所需的原始视频相对容易(来自公开数据集),但重新生成所有描述需要访问Gemini API。
- Demo: 论文未提及是否提供在线演示。
- 复现材料: 论文提供了丰富的复现细节:包括所有训练超参数(学习率、batch size等)、硬件配置、以及用于数据构建、关键点分解、奖励计算的所有Prompt(见附录图10-17)。这些信息对复现工作至关重要。
- 论文中引用的开源项目: 依赖的开源项目主要是基础模型
Qwen2.5-Omni-7B,以及用于评估的基准测试集(如Daily-Omni,WorldSense)。构建数据时使用了TikTok-10M,Shot2Story,FineVideo等公开数据集。
📌 核心摘要
- 解决的问题: 现有视频描述生成方法大多以视觉为中心,忽略了音频信息,或者无法生成视觉和音频事件在时间上精确对齐的描述,这限制了模型对视频内容的全面理解。
- 方法核心: 提出了 AVoCaDO,一个由音视频时序协调驱动的描述生成模型。其核心是一个两阶段后训练流水线:第一阶段(SFT)在精心构建的 10.7 万条高质量、时序对齐的音视频描述数据集上进行监督微调;第二阶段(GRPO)利用三个专门设计的奖励函数(清单奖励、对话奖励、长度正则化奖励)进行强化学习,以进一步优化时序连贯性和描述准确性。
- 创新点: 相比已有方法,主要新在:1) 构建了大规模、高质量的音视频对齐描述数据集;2) 提出了针对音视频描述任务特性的组合式奖励函数设计,同时关注内容完整性、对话准确性和生成稳定性;3) 证明了在通用多模态模型上通过特定后训练即可显著提升音视频描述能力。
- 主要实验结果: 在四个音视频描述基准测试上,AVoCaDO (7B) 显著超越了所有现有开源模型,并在 UGC-VideoCap 上超越了商业模型 Gemini-2.5-Pro。关键结果如下表所示。
| 模型 | 视频-SALMONN-2测试集 (Total ↓) | UGC-VideoCap (Avg. ↑) | Daily-Omni (Avg. ↑) | WorldSense (Avg. ↑) |
|---|---|---|---|---|
| AVoCaDO (Ours) | 37.3 | 73.2 | 50.1 | 25.7 |
| video-SALMONN-2* | 38.8 | 67.2 | 29.9 | 18.2 |
| Qwen2.5-Omni | 57.1 | 57.7 | 13.4 | 8.6 |
| Gemini-2.5-Pro | 31.3 | 72.6 | 60.2 | 33.8 |
- 实际意义: 提升了视频描述模型对包含对话、音乐、环境音等复杂音视频内容的理解和描述能力,为视频理解、检索和生成等下游任务提供了更高质量的文本表示,推动了多模态大模型向更全面的视听感知发展。
- 主要局限性: 模型性能高度依赖于大规模、高质量的监督数据构建(使用了强大的教师模型),这可能限制其在不同文化或低资源语言场景下的快速迁移。此外,奖励函数的设计虽然针对性强,但也引入了额外的计算开销和复杂度。
🏗️ 模型架构
AVoCaDO 的核心是在现有的音频视觉大语言模型 Qwen2.5-Omni-7B 基础上,通过一个精心设计的两阶段后训练流水线进行增强,使其专注于生成高质量的音视频描述。

图2:高音质、时序对齐的音视频视频描述构建流程。此图清晰地展示了用于生成SFT训练数据的两阶段策略:首先使用Gemini分别生成视频帧描述和音频描述,然后将两者融合为时序连贯的多模态描述,最后通过质量检查器进行过滤。
整体输入输出:
- 输入: 一个视频文件(包含视觉帧和音频轨道)。
- 输出: 一段自然语言描述,该描述需要同时、准确地反映视频中的视觉内容、音频内容(包括对话、音乐、音效)以及二者之间的时序关系。
核心组件与流程: AVoCaDO 的模型架构本身继承自 Qwen2.5-Omni,其核心创新在于后训练方法,而非底层架构设计。其增强过程主要分为两个连续阶段:
AVoCaDO SFT(监督微调)阶段:
- 目标: 使模型具备生成时序对齐的音视频描述的基本能力。
- 数据驱动: 使用一个新构建的、包含 10.7 万对高质量音视频描述的数据集。数据构建流程如图2所示,采用了两阶段生成策略以确保质量:先分离生成视觉描述和音频描述,再融合为时序对齐的联合描述,最后通过质量过滤。
- 训练: 在此数据集上对基础模型进行全量微调。
AVoCaDO GRPO(群组相对策略优化)阶段:
- 目标: 在 SFT 基础上,进一步优化描述的细节质量,特别是音视频事件的时序对齐、对话准确性,并抑制生成过程中的重复退化。
- 核心机制: 采用 GRPO 算法(一种强化学习方法),关键创新在于设计了三个互补的奖励函数(如图3所示),共同引导模型优化。
- 奖励函数设计:
- 清单奖励 ($R_C$): 基于关键点覆盖率。将真实描述分解为涵盖五个维度(跨模态叙事逻辑、动态动作、听觉元素、时空摄影、静态实体)的关键点清单,奖励模型生成的描述覆盖这些关键点的程度。
- 对话奖励 ($R_D$): 基于对话内容的准确性和说话人识别的精确度,通过计算生成对话与真实对话的F1分数来衡量。
- 长度正则化奖励 ($R_L$): 鼓励完整但不过长的描述,惩罚重复崩溃(repetition collapse)和极端长度。
- 训练: 在 SFT 模型基础上,使用上述奖励函数在 2K 样本子集上进行 GRPO 训练。
数据流交互: 输入视频经过 Qwen2.5-Omni 的视觉和音频编码器提取特征,然后送入 LLM 骨干。在 SFT 阶段,LLM 学习根据这些特征生成对齐描述。在 GRPO 阶段,LLM 被采样生成多个候选描述,每个描述根据上述三个奖励函数计算奖励值,然后通过 GRPO 算法更新模型参数,使其更倾向于生成获得高奖励的描述。
💡 核心创新点
- 针对音视频描述任务定制的组合式强化学习奖励函数: 这是论文最核心的创新。不同于通用 RL 应用,作者针对“时序对齐”、“对话准确”、“避免重复”这三个音视频描述的关键挑战,分别设计了清单、对话、长度三个奖励,并证明它们的协同作用能显著提升模型性能(表4消融实验)。这为如何将 RL 有效应用于特定感知与生成任务提供了范例。
- 大规模、高质量的音视频时序对齐描述数据集构建: 论文不仅使用了现有视频数据,更重要的是提出了一套可靠的数据构建流程(图2):分离生成再融合,最后进行严格的质量筛选。这解决了音视频联合标注数据稀缺的问题,为监督微调提供了坚实基础。
- 两阶段后训练流水线的有效性验证: 论文清晰地展示了“监督微调打基础,强化学习提细节”的流水线价值。消融实验表明,仅 SFT 能带来大幅提升,而 GRPO 在此基础上进一步精细化优化,且三个奖励函数缺一不可。这种清晰、可复现的训练策略具有重要参考意义。
🔬 细节详述
- 训练数据: 数据集规模 107K,来源多样:TikTok-10M (24K), ShortVideo (18K), Shot2Story (20K), FineVideo (29K), YouTube-Commons (11K), CinePile (5K)。构建过程强调包含丰富的听觉元素(对话、音乐、音效)。
- 损失函数: SFT 阶段为标准的语言模型交叉熵损失。GRPO 阶段使用 GRPO 目标函数(公式2),其核心是最大化基于奖励计算出的优势函数,并包含 KL 散度正则化项($\beta=0.04$)防止策略偏离过远。
- 训练策略:
- SFT: 2 个 epoch,batch size 128,学习率 $2 \times 10^{-5}$。
- GRPO: 1 个 epoch,batch size 64,学习率 $1 \times 10^{-5}$,每个查询采样 8 个响应(G=8),温度 1.0。
- 关键超参数: 基础模型为 Qwen2.5-Omni-7B。视频采样率 2fps,每帧最大分辨率 512x28x28。受模型 32K 上下文限制,视频 token 数上限 25600。奖励函数阈值:$\gamma=0.6$ (对话相似度),$\tau_1=2048$, $\tau_2=4096$ (长度奖励)。
- 训练硬件: 16 张 NVIDIA H200 GPU。评估使用 NVIDIA H20 GPU。
- 推理细节: 论文未明确说明推理时的具体解码策略(如 beam search 参数),但根据描述生成任务特性,通常采用采样或 beam search。
- 正则化技巧: GRPO 中的 KL 散度正则化;长度奖励 $R_L$ 本身也是防止退化和过长的一种正则化。
📊 实验结果
论文在多个基准测试上进行了全面评估,包括直接评估描述质量、基于描述的问答评估以及在纯视觉设置下的评估。
主要实验结果对比(音视频描述生成):
| 模型 | 大小 | 模态 | video-SALMONN-2测试集 (Total ↓) | UGC-VideoCap (Avg. ↑) | Daily-Omni (Avg. ↑) | WorldSense (Avg. ↑) |
|---|---|---|---|---|---|---|
| AVoCaDO (Ours) | 7B | A+V | 37.3 | 73.2 | 50.1 | 25.7 |
| video-SALMONN-2* | 7B | A+V | 38.8 | 67.2 | 29.9 | 18.2 |
| UGC-VideoCaptioner* | 3B | A+V | 48.6 | 59.1 | 17.0 | 11.2 |
| Qwen2.5-Omni | 7B | A+V | 57.1 | 57.7 | 13.4 | 8.6 |
| Gemini-2.5-Pro | - | A+V | 31.3 | 72.6 | 60.2 | 33.8 |
注:标的为同期工作。video-SALMONN-2测试集使用GPT-4.1作为裁判。数据来自论文表1和表2。AVoCaDO在开源模型中取得最佳,在UGC-VideoCap上超越Gemini-2.5-Pro。在QA评估任务(Daily-Omni, WorldSense)上优势显著。
消融实验结果:
| 模型/设置 | 奖励 ($R_C$, $R_D$, $R_L$) | video-SALMONN-2测试集 (Total ↓) | Daily-Omni by caption (Avg. ↑) |
|---|---|---|---|
| Qwen2.5-Omni | – | 57.1 | 13.4 |
| AVoCaDO-SFT | – | 41.4 | 48.1 |
| AVoCaDO-GRPO | ✓ | 41.3 | 49.5 |
| AVoCaDO-GRPO | ✓, ✓ | 37.3 | 49.5 |
| AVoCaDO-GRPO | ✓, ✓, ✓ | 37.3 | 50.1 |
注:数据来自论文表4。此表清晰地展示了每个奖励函数的贡献:$R_D$提升对话质量,$R_C$降低错误率,$R_L$抑制重复崩溃(RepCol从7.1%降至0.4%)。
在纯视觉设置下的竞争性表现: 在 VDC Detailed 和 DREAM-1K 这两个评估纯视觉描述的基准上,AVoCaDO 也表现出色(表3),在 VDC Detailed 子集上准确率(Acc)达到 47.4%,DREAM-1K 上 F1 分数达到 35.9%,优于 Qwen2.5-Omni 等模型。
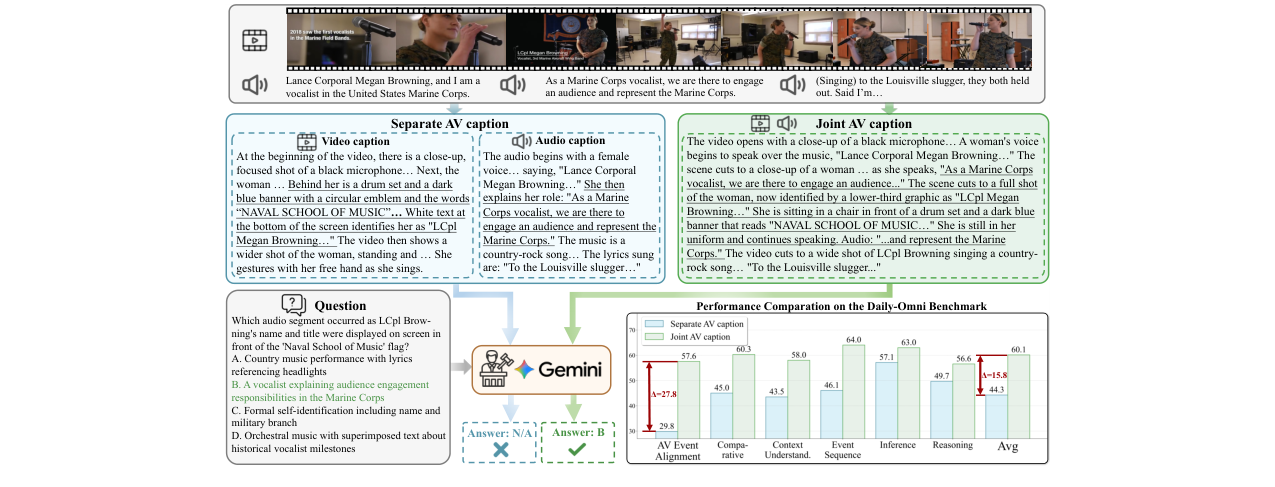
图7:AVoCaDO-GRPO阶段训练过程中三个奖励函数的演变曲线。该图显示,清单奖励和对话奖励稳步上升并趋于收敛,长度奖励偶尔的急剧下降表明模型在处理难样本时的不稳定,但整体最小值在提升,表明生成稳定性在改善。
⚖️ 评分理由
- 学术质量(6.5/7): 创新点明确且有效(定制奖励函数),方法设计有扎实的动机和清晰的逻辑。实验全面,提供了直接评估和间接(QA)评估,消融实验充分验证了各组件的贡献。结果可信,超越了同期工作和部分商业模型。扣分点在于方法对大型教师模型和精心构建数据的依赖性较强,通用性有待更广泛验证。
- 选题价值(1.5/2): 音视频时序对齐描述是多模态理解的核心挑战之一,研究前沿且有明确的应用价值(视频理解、生成)。论文针对这一具体问题提出了系统解决方案,对领域发展有推动作用。
- 开源与复现加成(0.5/1): 论文承诺开源模型和代码,提供了详细的实验设置、超参数和数据构建Prompt(附录),复现指引清晰。但数据集构建依赖闭源模型Gemini,部分代码未提及,因此未给满分。