📄 AVEX: What Matters for Animal Vocalization Encoding
#生物声学 #预训练 #自监督学习 #模型比较 #基准测试
✅ 7.0/10 | 前25% | #生物声学 | #预训练 | #自监督学习 #模型比较
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.8 | 置信度 高
👥 作者与机构
- 第一作者:Marius Miron(Earth Species Project),David Robinson(Earth Species Project)(共同贡献)
- 通讯作者:Marius Miron, David Robinson(Earth Species Project)
- 作者列表:Marius Miron(Earth Species Project),David Robinson(Earth Species Project),Milad Alizadeh(Earth Species Project),Ellen Gilsenan-McMahon(Earth Species Project),Gagan Narula(Earth Species Project),Emmanuel Chemla(Earth Species Project),Maddie Cusimano(Earth Species Project),Felix Effenberger(Earth Species Project),Masato Hagiwara(Earth Species Project),Benjamin Hoffman(Earth Species Project),Sara Keen(Earth Species Project),Diane Kim(Earth Species Project),Jane Lawton(Earth Species Project),Jen-Yu Liu(Earth Species Project),Aza Raskin(Earth Species Project),Olivier Pietquin(Earth Species Project),Matthieu Geist(Earth Species Project)。
💡 毒舌点评
亮点在于实验设计极其严谨和全面,如同为生物声学编码器领域做了一次“高考”,系统性地比较了各种技术路线,得出了可操作的“最优训练配方”。短板在于,其核心贡献是实证结论而非提出一种全新的、具有独创性的模型架构,更像是一个高质量的“工程最佳实践”指南。
🔗 开源详情
- 代码:提供代码仓库链接 https://projects.earthspecies.org/avex/ ,包含一个名为AVEX的Python库,用于模型加载、推理以及生物声学表征学习模型的训练和评估系统。
- 模型权重:明确提及并发布了多个模型检查点(checkpoint),包括本文训练的
sl-BEATS-bio,sl-BEATS-all,EffNetB0-all等(见表2)。 - 数据集:论文使用了多个公开数据集(如Xeno-canto, iNaturalist, AudioSet等),并进行了说明。未提及发布新的整合数据集。
- Demo:论文中未提及在线演示。
- 复现材料:提供了非常详尽的复现材料,包括:完整的训练超参数表(表5)、数据集划分与预处理说明、评估指标的具体计算公式(附录B.2)、以及用于生成新基准数据集的公开数据集链接(附录B.4)。
- 论文中引用的开源项目:BEATs (Microsoft), EAT (开源实现), EfficientNetB0 (torchvision), 以及用于处理BirdNet和Perch的TensorFlow-Lite。
📌 核心摘要
问题:当前生物声学编码器通常局限于特定物种(如鸟类)、单一模型架构或训练范式,且评估任务和数据集有限,难以满足广泛、泛化的实际应用需求(如物种识别、个体识别、声音库发现等)。
方法核心:本文进行了一项大规模实证研究,系统性地调查并比较了三大方面:(1)模型架构(CNN vs. Transformer)、(2)训练数据混合(生物声学数据 vs. 通用音频数据)、(3)训练范式(自监督学习、监督学习、两阶段训练)。
与已有方法相比新在哪里:首次在如此广泛的维度和规模上,对生物声学编码器的构建要素进行公平、统一的实验比较。特别创新性地引入并评估了“自监督预训练 + 监督后训练”的两阶段范式,并系统验证了在训练中混合通用音频数据对提升模型泛化能力的关键作用。
主要实验结果:
- 在涵盖物种分类、检测、个体ID、声音库发现等任务的26个数据集上,采用“在混合生物声学+通用音频数据上进行自监督预训练,再用相同混合数据进行监督后训练”的配方,取得了整体最优的性能(见下表关键结果摘录)。
- 消融研究表明:在自监督预训练阶段加入通用音频(AudioSet)能显著提升模型在各类任务上的表现(如图2a所示);监督模型在分布内任务表现强,但自监督模型在分布外任务上性能下降更小(如图2b所示);后训练能有效提升自监督骨干网络的性能(如图3所示)。
模型 BEANS分类 (Probe) BEANS检测 (R-AUC) BirdSet (Probe) 个体ID (R-AUC) 声音库 (R-AUC) sl-BEATS-all (本文最佳) 0.832 0.604 0.726 0.511 0.798 BirdNet (SOTA基线) 0.796 0.523 0.687 0.472 0.795 BEATS (SFT) 0.724 0.504 0.692 0.375 0.755 EffNetB0-bio 0.786 0.563 0.695 0.457 0.806 (注:以上为表3中关键指标摘录,Probe为分类准确率/mAP,R-AUC为检索ROC AUC,数值越大越好)
实际意义:为生物声学领域提供了一套可复现、高性能的通用编码器训练方案(AVEX)和模型,有助于加速该领域的研究(如动物通讯解码、生物多样性监测)并推动其走向实际应用。开源的代码库和模型也为后续工作提供了坚实基础。
主要局限性:研究结论受限于当前可用的公开数据和模型架构;部分消融实验(如消融鲸鱼或非鸟类数据)显示结果并非完全一致,表明数据多样性的影响可能因任务而异;研究所有模型均在16kHz采样率下评估,可能损失了部分高频信息。
🏗️ 模型架构
本文并非提出一个单一的“AVEX”新模型,而是一个研究项目,旨在通过系统实验找出构建最佳生物声学编码器的要素。因此,架构分析侧重于其实验中比较的几类主要架构:
CNN架构(以EfficientNet-B0为代表):
- 流程:输入音频 -> 转换为梅尔频谱图 -> 输入EfficientNet-B0网络 -> 提取最终层特征(时间维度平均) -> 用于下游任务(线性探测、检索、聚类)。
- 特点:轻量、高效,通常从ImageNet预训练的权重开始,在生物声学数据上进行监督微调(Post-training)。
- 动机:代表当前许多生物声学模型(如BirdNet, Perch)使用的经典视觉骨干网络路线。
Transformer架构(以BEATs, EAT为代表):
- 流程:输入音频波形 -> 通过音频标记器(如BEATs的声学标记器,EAT的频谱图掩码)转换为离散标记或直接处理频谱图 -> 输入Transformer编码器 -> 提取[CLS] token或平均特征。
- 特点:基于自监督学习(SSL)预训练,擅长捕捉长程依赖和复杂模式。BEATs基于掩码预测,EAT结合了蒸馏和重建。
- 动机:代表更先进的音频表示学习范式,有望获得更好的泛化性。
两阶段训练范式(本文提出的核心配方):
- 流程:
阶段1(自监督预训练):在(生物声学+通用音频)混合数据上,对Transformer骨干(如BEATs, EAT)进行SSL训练。 ->阶段2(监督后训练):在相同混合数据上,解冻整个模型进行监督微调(例如,预测物种标签)。 - 动机:结合SSL强大的表示学习能力和监督学习对任务的针对性优化,实现在分布内(分类)和分布外(检测)任务上均取得最佳性能。

图1展示了本研究的整体框架:评估模型、训练数据、训练范式,并提出扩展的评估数据和方法。
- 流程:
💡 核心创新点
- 首次大规模、跨维度的生物声学编码器实证研究:系统性地在数据多样性(物种、声学环境)、模型架构(CNN vs. Transformer)、训练范式(SSL, SL, 混合) 三个核心维度上展开公平比较,填补了该领域缺乏统一基准比较的空白。
- 提出并验证了“SSL预训练 + SL后训练”的最优训练配方:通过实验证明,对于生物声学编码器,在混合数据上进行自监督预训练,再进行监督后训练,能够结合两种范式的优点,实现最强的综合性能(如图2b所示)。
- 揭示了通用音频数据在提升泛化性中的关键作用:消融实验(图2a)定量证明,在自监督预训练阶段加入通用音频数据(AudioSet)能显著提升模型在各类下游任务(包括声音库发现、个体识别)上的表现,挑战了仅用生物声学数据训练的惯例。
- 扩展了生物声学编码器的评估体系:除了传统的物种分类/检测,引入了个体识别和声音库(发声类型)发现这两个重要但研究不足的任务作为新基准,并补充了检索(R-AUC)和聚类(NMI) 评估指标,更全面地探测模型表征质量。
- 开源了AVEX工具库与高性能模型:发布了包含训练、评估、推理API的完整代码库以及多个达到SOTA性能的模型检查点,降低了领域研究门槛。
🔬 细节详述
- 训练数据:
- 生物声学数据:整合了Xeno-canto (10416小时,鸟类)、iNaturalist (1539小时,多样物种)、Watkins (27小时,海洋哺乳动物)、Animal Sound Archive (78小时,多样物种)等。总生物声学数据量约12000小时。
- 通用音频数据:AudioSet (5700小时)。
- 数据增强:训练中使用了两种关键增强:1)随机噪声添加(SNR在-10dB到20dB间均匀采样,概率0.5),噪声源来自船舶、城市声音等数据集。2)样本混合(Mixup)(概率0.5),将批次内音频线性混合,标签取并集。
- 损失函数:监督训练使用二元交叉熵损失(BCE),支持多标签分类(物种预测)。自监督训练损失依据具体模型(BEATs使用掩码预测损失,EAT使用蒸馏和重建损失)。
- 训练策略:
- 优化器:AdamW。
- 学习率:峰值LR因模型而异,如BEATs后训练为1e-4,EAT后训练为8e-5。
- 调度策略:余弦学习率调度。
- Warmup:例如BEATs使用5000步warmup。
- Batch Size:通常为256。
- 训练轮数:后训练阶段通常为10轮(BEATs)或30轮(EAT)。
- 关键超参数:所有模型统一在16kHz采样率下训练和评估。EfficientNet使用B0变体。BEATs和EAT的具体配置遵循其原论文。
- 训练硬件:论文未明确说明GPU/TPU型号和训练时长,但提供了详细的超参数表(表5)。
- 推理细节:评估时,对于分类和检测任务,使用线性探测(在冻结的特征上训练线性分类器)。对于检索任务,直接使用模型输出的余弦相似度。对于聚类任务,使用K-means。也测试了基于注意力的探测头作为线性探测的替代(附录C.6)。
- 正则化技巧:使用了权重衰减(0.1)、Dropout(在探测头中)、以及前述的噪声添加和Mixup数据增强来提高鲁棒性和泛化能力。
📊 实验结果
主要基准测试结果汇总(表3)
| 模型 | BEANS分类 | BEANS检测 | BirdSet | 个体ID | 声音库 |
|---|---|---|---|---|---|
| (指标) | Probe↑ R-AUC↑ C-NMI↑ | Probe↑ R-AUC↑ | Probe↑ R-AUC↑ | Probe↑ R-AUC↑ | R-AUC↑ C-NMI↑ |
| BEATS (SFT) SSL | 0.724 0.739 0.504 | 0.339 0.692 | 0.101 0.675 | 0.375 0.602 | 0.755 0.485 |
| BEATS (pre) SSL | 0.774 0.734 0.542 | 0.381 0.722 | 0.129 0.686 | 0.380 0.637 | 0.775 0.498 |
| BirdNet SL | 0.796 0.772 0.523 | 0.392 0.523 | 0.687 N/A | N/A 0.472 | 0.708 0.545 |
| Perch SL | 0.768 0.759 0.478 | 0.368 0.478 | 0.674 0.233 | 0.530 0.656 | 0.758 0.493 |
| EffNetB0-bio SL | 0.786 0.799 0.563 | 0.365 0.563 | 0.695 0.279 | 0.457 0.683 | 0.806 0.568 |
| EffNetB0-all SL | 0.800 0.809 0.584 | 0.362 0.584 | 0.712 0.279 | 0.531 0.701 | 0.830 0.582 |
| EAT-all SSL | 0.709 0.704 0.448 | 0.315 0.448 | 0.694 0.166 | 0.348 0.611 | 0.788 0.512 |
| sl-BEATS-bio SL-SSL | 0.840 0.811 0.594 | 0.390 0.594 | 0.719 0.288 | 0.484 0.681 | 0.789 0.516 |
| sl-BEATS-all SL-SSL | 0.832 0.813 0.604 | 0.408 0.604 | 0.726 0.294 | 0.511 0.690 | 0.798 0.529 |
| sl-EAT-bio SL-SSL | 0.797 0.792 0.562 | 0.353 0.562 | 0.687 0.249 | 0.495 0.672 | 0.806 0.565 |
(注:粗体标记为对应指标最佳值。Probe为分类准确率/mAP,R-AUC为检索ROC AUC,C-NMI为聚类归一化互信息,数值越大越好。)
关键发现与证据:
- 整体SOTA:
sl-BEATS-all(在混合数据上SSL预训练+SL后训练)在大多数基准测试(BEANS分类/检测,BirdSet)上取得最佳性能,验证了本文提出的训练配方的有效性。 - 数据混合的价值:对比
EffNetB0-bio和EffNetB0-all,加入AudioSet在声音库发现(R-AUC从0.806提升至0.830)等任务上带来显著提升(如图4、5消融所示)。 - SSL的泛化优势:从图2b可见,当任务从聚焦录音(BEANS分类)转向自然声景录音(BEANS检测)时,SSL模型(如BEATS pre)的R-AUC下降幅度(约0.01)远小于SL模型(约0.09),表现出更强的分布外泛化能力。
- 后训练的增益:图3显示,对所有SSL骨干(EAT, BEATs)进行监督后训练,几乎在所有基准上都能带来性能提升,平均相对增益显著。
图2b:展示了监督(SL)和自监督(SSL)模型在BEANS分类(分布内,聚焦录音)和BEANS检测(分布外,声景录音)上的性能变化。SL模型在分布内更强,但SSL模型在分布外性能更稳定;而经过后训练的SSL模型(如NatureBEATs)结合了两者优势。
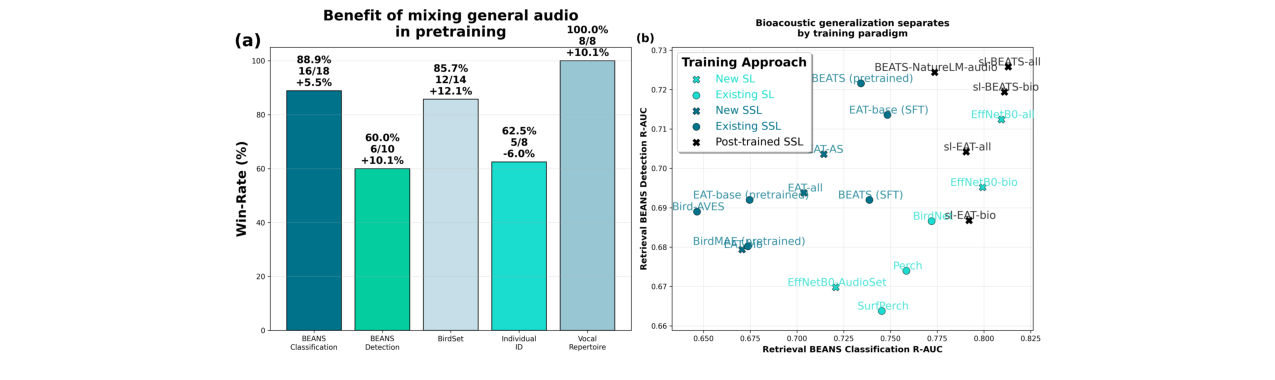
图3:后训练模型与其原始SSL骨干模型在不同基准上的性能提升胜率(Win-rate)分析,表明后训练能带来一致的改进。
图4:详细展示了不同训练数据混合方案(相比纯生物声学基线)在BEANS基准各任务和类别上的性能变化热图。可见加入通用音频(+General)在多处带来提升。
⚖️ 评分理由
- 学术质量:6.5/7:创新性体现在方法组合与系统实证上,提出了有影响力的训练范式“配方”。技术正确性高,实验设计覆盖了关键变量(架构、数据、范式),控制了比较条件(相同采样率、相似训练流程)。实验极其充分,包含26个数据集、多个任务、详尽的消融实验和分析。证据可信度强,结果可复现。扣分点在于未提出全新的、具有独创性的基础模型架构。
- 选题价值:1.5/2:前沿性明确,针对生物声学这一重要但被主流AI研究相对忽视的垂直领域,致力于构建基础编码器。潜在影响大,高性能编码器能直接赋能生态保护、生物行为研究等。实际应用空间广。对音频/语音领域读者而言,其揭示的“数据混合”和“两阶段训练”原则具有普遍参考价值。
- 开源与复现加成:+0.8:论文明确开源了AVEX代码库(提供API和训练系统)和多个模型检查点(表2)。附录详细列出了训练超参数(表5)、数据来源、评估脚本等。这极大促进了研究的可复现性和后续应用。