📄 Automatic Stage Lighting Control: Is it a Rule-Driven Process or Generative Task?
#音乐生成 #端到端 #预训练 #迁移学习
✅ 7.0/10 | 前25% | #音乐生成 | #端到端 | #预训练 #迁移学习
学术质量 5.5/7 | 选题价值 1.0/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Zijian Zhao(香港科技大学)
- 通讯作者:Xiaoyu Zhang(香港城市大学)
- 作者列表:Zijian Zhao(香港科技大学)、Dian Jin(香港理工大学)、Zijing Zhou(香港大学)、Xiaoyu Zhang(香港城市大学)
💡 毒舌点评
亮点:论文开创性地将自动舞台灯光控制(ASLC)从“规则映射”问题重新定义为“生成任务”,并基于BART设计了端到端的Skip-BART模型,其生成效果在人工评估中已接近专业灯光师水平,概念和方法均有新意。短板:尽管开创了新范式,但其构建的RPMC-L2数据集仅包含约700个摇滚/朋克/金属风格的现场演出片段,规模和多样性有限,这严重制约了模型在更广泛音乐类型和复杂舞台场景下的泛化能力上限。
🔗 开源详情
- 代码:是,提供完整代码仓库链接:https://github.com/RS2002/Skip-BART
- 模型权重:是,提供训练好的模型参数供下载。
- 数据集:是,提供了处理后的数据集(RPMC-L2)下载链接。
- Demo:论文中未提及在线演示。
- 复现材料:论文在附录中提供了详细的预训练配置(附录A)、实验设置(附录B)和数据集构建细节(附录C),包括所有超参数、损失函数权重和数据处理流程,复现信息非常充分。
- 引用的开源项目:论文依赖并引用了多个开源工具/模型,包括:PianoBART(用于迁移学习的骨干)、OpenL3(音频特征提取)、PyTorch(深度学习框架),以及用于生成对比歌曲的Suno。
📌 核心摘要
- 问题:现有的自动舞台灯光控制(ASLC)大多依赖将音乐分类到有限类别后映射到预设灯光模式,导致结果公式化、单调且缺乏合理性。作者认为灯光控制本质上是艺术创作过程,而非简单的规则映射。
- 方法:论文首次提出将ASLC视为一个生成任务,并提出了端到端深度学习模型 Skip-BART。该模型以BART为骨干,使用OpenL3提取音频特征,通过离散嵌入处理灯光数据(HSV色彩空间的色相H和明度V)。其核心创新是引入跳连接机制,显式对齐音乐帧与灯光帧,以增强时序对应关系。训练过程采用掩码语言模型(MLM)预训练和端到端微调,并结合了迁移学习(PianoBART)和受限随机温度控制(RSTC)采样。
- 创新:与传统分类-映射范式相比,新在:(1) 将ASLC建模为序列到序列的生成问题;(2) 设计了包含跳连接的Skip-BART架构;(3) 构建了首个专门的ASLC数据集RPMC-L2。
- 实验结果:在自建的RPMC-L2数据集上,Skip-BART在定量指标(RMSE, MAE, corr(|Δ|))上显著优于规则基线方法(见下表)。人工评估(38名参与者)显示,Skip-BART的总体评分(M=4.35)与真实灯光师(M=4.51)无显著差异(p=0.724),但显著高于规则方法(M=2.67,p<0.001)。
| 方法 | RMSE↓ (Hue) | RMSE↓ (Value) | MAE↓ (Hue) | MAE↓ (Value) | corr(|Δ|)↑ (Hue) | corr(|Δ|)↑ (Value) | | :— | :— | :— | :— | :— | :— | :— | | Rule-based | 48.67 | 93.39 | 43.43 | 86.55 | 0.50 | 0.58 | | Skip-BART | 36.13 | 60.74 | 28.72 | 51.27 | 0.88 | 2.94 |
- 实际意义:为舞台灯光自动化提供了更智能、更人性化的新思路,有望降低专业灯光设计的门槛和成本。
- 局限性:数据集规模有限且风格集中;模型目前仅支持离线单灯光生成;在音乐的长程节奏稳定性和局部波动控制上仍有不足。
🏗️ 模型架构
Skip-BART是一个基于编码器-解码器(Encoder-Decoder)的序列到序列生成模型,旨在根据输入的音乐序列生成对应的灯光(色相H,明度V)序列。
整体流程:
- 输入:一段音乐,被处理为OpenL3音频嵌入序列
e = {e1, e2, ..., en}。 - 编码器:使用预训练的BART编码器(其骨干来自PianoBART),接收音频嵌入序列
e,提取上下文特征。 - 解码器:接收来自编码器的特征,并自回归地生成灯光序列
y = {y1, y2, ..., yT}。 - 输出:每个灯光帧
yt包含色相ht和明度vt,通过两个独立的MLP头部进行分类预测。
核心组件与数据流:
输入嵌入层:
- 音频嵌入:使用预训练的OpenL3模型提取音频特征,再通过一个MLP映射到BART的嵌入维度(512维)。
- 灯光嵌入:将灯光帧
yt = [ht, vt]的色相和明度分别通过独立的嵌入层进行离散嵌入。这样设计是为了更好地处理色相(Hue)的循环特性(0°和180°相近)。两个嵌入向量被拼接后作为解码器的输入。
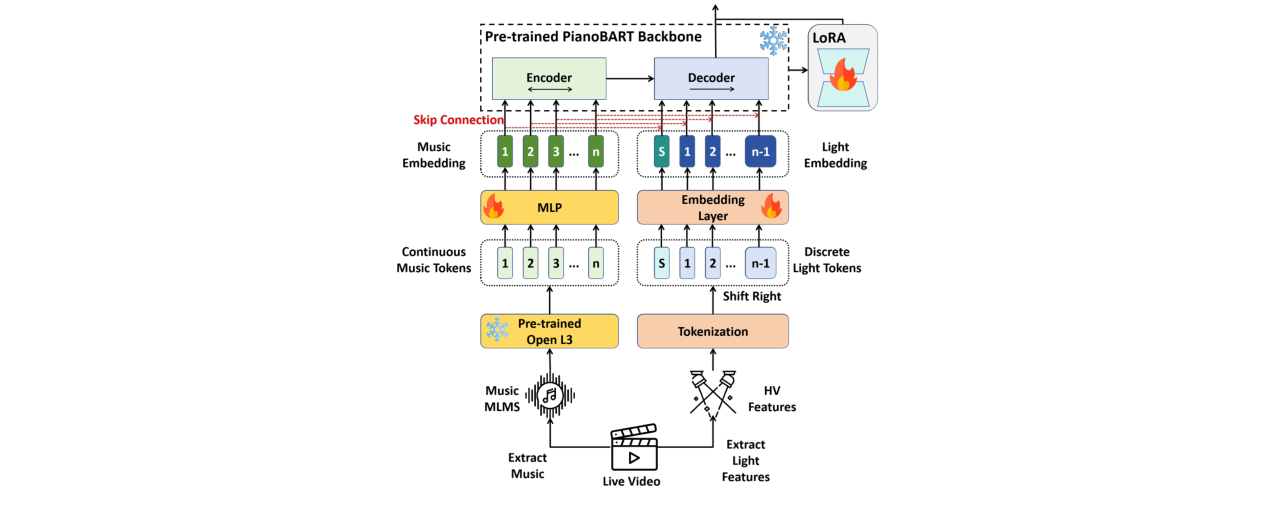
(图1:网络架构示意图。图中‘ice’代表冻结参数,‘fire’代表可训练参数。展示了从音频输入、经过OpenL3和MLP得到音频嵌入,到灯光数据处理后作为解码器输入的完整数据流。)
跳连接机制(Skip Connection): 这是本文的关键创新。为了解决模型难以学习灯光帧与音乐帧之间一一对应关系的问题,在解码器中,将灯光帧
yi的嵌入 与音乐帧xi-1的嵌入(考虑右移一位)进行拼接,再送入解码器。这显式地告诉模型每个时间步的灯光生成应重点关注哪个音乐片段,增强了时序对齐能力。骨干网络与迁移学习:
- 直接采用PianoBART的预训练权重作为BART骨干的初始化。
- 通过DARE方法融合PianoBART在多个下游任务(如旋律提取、情感分类)上的微调参数,获得更强大的初始表示。
- 在后续训练中,使用LoRA进行高效参数微调。
训练工作流:
(图3:Skip-BART的工作流程图。展示了从数据准备、MLM预训练到端到端微调,再到推理的完整过程。)
- MLM预训练:仅使用音频数据。随机遮蔽部分音频嵌入(遮蔽Token服从正常分布),训练模型恢复原始嵌入。损失函数包括重建损失、遮蔽Token恢复损失和GAN判别器损失,以提升生成序列的真实性。
- 端到端微调:使用灯光数据。任务转化为预测下一灯光Token(分类问题)。损失函数是色相和明度交叉熵损失的加权和,权重根据两者学习速度动态调整。
- RSTC推理:生成时采用带温度的随机采样,并加入受限机制,限制相邻灯光帧的色相和明度变化不超过阈值,以确保生成结果的平滑性和稳定性。
💡 核心创新点
- 范式转变:首次明确将自动舞台灯光控制(ASLC)概念化为一个生成任务,而非传统的规则驱动或分类映射过程。这为领域研究提供了全新的视角和方法论基础。
- 端到端生成模型Skip-BART:提出了一个完整的端到端深度学习框架,直接从专业灯光师的作品中学习并生成灯光序列,避免了传统方法中分类粗粒度、映射规则固化的问题。
- 跳连接机制:设计了一种新颖的跳连接结构,在解码器输入中显式融合对应时间步的灯光嵌入和音乐嵌入,强制模型学习精细的帧间对齐关系,从而更好地捕捉音乐与灯光之间的同步节奏。
- 首个ASLC数据集:构建并发布了名为RPMC-L2的第一个舞台灯光生成数据集,包含来自多种摇滚/朋克/金属风格现场演出的699个样本,并提供了从原始视频提取灯光特征的标准流程,为该领域研究提供了数据基础。
🔬 细节详述
- 训练数据:使用自建数据集RPMC-L2(Rock, Punk, Metal, and Core - Livehouse Lighting)。包含699个样本,来自2020-2024年间的35场现场演出,长度20秒至5分钟不等。数据集按8:1:1划分为训练、验证、测试集,且确保不同演出的数据不会交叉。提供了处理后的HDF5文件(约40GB)。灯光数据从视频中逐帧提取为HSV色彩空间的主色相(Mode)和明度(加权平均),并固定饱和度为255。音频以10Hz采样率分帧。
- 损失函数:
预训练损失 (
Lpre):Lpre = α1l1 + α2l2 + α3l3。其中l1是自编码器式的全序列MSE损失,l2是仅针对被遮蔽Token的MSE损失,l3是判别器判断生成序列为“真”的交叉熵损失。权重设为α1=0.8, α2=0.2, α3=0.1。 微调损失 (Lstf):Lstf = β1CE(û, h) + β2*CE(û, v),是色相和明度分类交叉熵损失的加权和。权重β根据上一轮验证集上的准确率自适应调整,以平衡两个属性的学习速度。 - 训练策略:使用AdamW优化器,学习率为0.0001,批量大小为16。预训练15小时,微调1.5小时。使用LoRA进行高效微调。
- 关键超参数:模型总参数量约240M,可训练参数19M。输入序列长度1024。网络层数8,隐藏维度2048,注意力头数8。色相词汇表大小180,明度词汇表大小256。
- 训练硬件:在Intel Xeon Gold 6133 CPU(2.50 GHz)和NVIDIA 4090/A100 GPU上进行。GPU显存占用约18GB。
- 推理细节:采用自回归生成方式。使用受限随机温度控制(RSTC)采样,温度参数
t用于控制生成的多样性。采样时,会限制相邻帧的色相距离(循环距离)和明度差值小于预设阈值dh和dv,防止输出过度跳跃。 - 正则化/稳定训练技巧:在预训练中引入GAN判别器以增强生成真实感。微调中采用自适应损失权重平衡不同属性的学习。推理阶段使用RSTC机制保证输出平滑性。
📊 实验结果
实验在自建的RPMC-L2数据集测试集上进行,并辅以人工评估和跨域评估。
定量分析结果: Skip-BART与规则基线方法及多个消融变体的对比如下表所示。Skip-BART在所有指标上均取得最佳或次佳表现,尤其在明度预测上优势明显。
| 方法 | RMSE↓ (Hue) | RMSE↓ (Value) | MAE↓ (Hue) | MAE↓ (Value) | corr(|Δ|)↑ (Hue) | corr(|Δ|)↑ (Value) | | :— | :— | :— | :— | :— | :— | :— | | Rule-based | 48.67 | 93.39 | 43.43 | 86.55 | 0.50 | 0.58 | | Skip-BART | 36.13 | 60.74 | 28.72 | 51.27 | 0.88 | 2.94 | | w/o skip connection | 36.89 | 68.33 | 29.44 | 58.34 | 1.15 | 0.30 | | w/o light embedding | 51.04 | 67.25 | 41.50 | 54.87 | 0.80 | 0.70 | | train from scratch | 36.63 | 67.49 | 28.83 | 57.22 | 0.69 | 0.53 | | pre-train w/o random [MASK] | 49.97 | 64.45 | 42.07 | 52.63 | 0.54 | 1.11 | | pre-train w/o discriminator | 50.40 | 68.09 | 41.52 | 56.54 | 0.46 | 1.13 |
人工评估结果: 38名参与者对四种方法(真值、Skip-BART、无跳连接消融、规则方法)在6个维度和总体上进行评分(1-7分)。使用重复测量ANOVA和事后配对t检验进行分析。
- 总体评分:Ground Truth (4.51±0.88) ≈ Skip-BART (4.35±0.87) > Ablation Study (4.11±0.84) » Rule-based (2.67±1.29)。
- 显著性:Skip-BART与Ground Truth无显著差异(p=0.724);Skip-BART与Rule-based差异极显著(p<0.001)。
- 细分维度:Skip-BART在情绪匹配上得分甚至略高于真值(4.69 vs 4.50),但在惊喜感上得分较低(3.83 vs 4.34)。跳连接对冲击力、氛围等指标有提升,但对节奏和流畅度影响较小。
跨域评估结果: 使用Suno生成的民间、R&B、爵士乐歌曲,由30名用户评估三种方法(无真值)。结果显示Skip-BART在所有指标和总体得分上仍显著优于规则方法(p<0.001),展现了不错的跨音乐风格泛化能力。
生成样本可视化: 论文提供了生成序列的可视化图(图5),展示了Skip-BART能较好地跟随音乐的段落转换(如红框所示),但有时会出现局部过度波动,而规则方法则倾向于产生平缓、单调的过渡。

(图5:不同方法生成灯光序列的可视化对比。上排为输入Mel频谱图,下排为Ground Truth、Skip-BART等方法生成的序列。红框标示了一个Skip-BART成功捕捉的音乐-灯光同步过渡片段。)
⚖️ 评分理由
- 学术质量:5.5/7:创新性地将ASLC定义为生成任务是清晰且有价值的贡献。Skip-BART模型设计合理,跳连接是针对问题的有效改进。实验设计完整,包含定量对比、充分的消融研究和严谨的人工评估,证据可信度高。主要不足在于实验所用数据集规模偏小且风格单一,限制了结论的普适性。
- 选题价值:1.0/2:选题在MIR领域具有新颖性,填补了特定应用空白。但舞台灯光控制是一个非常垂直、细分的应用场景,其直接影响力和市场应用空间相对有限,与主流的音频/语音任务关联度中等。
- 开源与复现加成:0.5/1:论文提供了完整的开源代码(GitHub)、预训练模型参数、处理后的数据集以及详细的复现说明(包括超参数、硬件环境),极大地降低了复现门槛,因此给予0.5的加分。