📄 Aurelius: Relation Aware Text-to-Audio Generation At Scale
#音频生成 #流匹配 #基准测试 #数据集
🔥 8.0/10 | 前25% | #音频生成 | #流匹配 | #基准测试 #数据集
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 1.0 | 置信度 高
👥 作者与机构
- 第一作者:Yuhang He (Microsoft Research)
- 通讯作者:Yuhang He (Microsoft Research)
- 作者列表:Yuhang He (Microsoft Research), He Liang (University of Oxford, Department of Computer Science), Yash Jain (Microsoft Research), Andrew Markham (Microsoft Research), Vibhav Vineet (Microsoft Research)
💡 毒舌点评
亮点:本文核心贡献在于为“关系感知文本到音频生成”这一被忽视的子任务,系统性地构建了两个大规模、高质量的专用数据集(AudioEventSet 和 AudioRelSet)和一套完整的评测基准,精准填补了领域空白。短板:论文的“方法”部分更多是基于现有基线模型(如TangoFlux)进行评测和简单的微调实验,缺乏一个针对关系感知生成提出全新、完整架构的深度技术方案,创新性更偏向数据与评测而非模型本身。
🔗 开源详情
- 代码:论文提供了代码仓库链接:https://github.com/yuhanghe01/Aurelius
- 模型权重:论文中未提及是否公开其自身提出的模型权重,但评测了多个公开的基线模型(如TangoFlux, AudioGen)。
- 数据集:AudioEventSet和AudioRelSet的构建方法已详细描述,但论文中未明确说明数据集是否公开以及如何获取。项目主页链接为:https://yuhanghe01.github.io/Aurelius-Proj/
- Demo:论文中未提及在线演示。
- 复现材料:论文提供了详细的基线模型推理设置(附录表III)、代理工作流的具体实现(附录.3)、以及数据集构建的完整描述(3.1-3.3节),为复现提供了必要信息。
- 论文中引用的开源项目:TangoFlux, AudioGen, PANNs (用于音频事件检测和声学效果分类), Qwen-family LLMs (用于代理工作流)。
📌 核心摘要
- 要解决什么问题:现有文本到音频生成模型在处理包含多个音频事件及其复杂空间、时间、逻辑关系的描述时能力严重不足,其关系建模能力未得到充分研究和评估。
- 方法核心是什么:提出Aurelius框架,其核心是构建两个大规模、高质量的专用语料库:包含110种独特音频事件的AudioEventSet和包含100种关系的AudioRelSet。二者通过“关系-文本模板化”与“事件实例化”策略组合,可生成海量多样化的
<文本,音频>训练/测试对。 - 与已有方法相比新在哪里:首次为关系感知TTA任务提供了大规模、系统化的基准。新在:1) 专用数据集的规模与质量远超以往小规模探索(如RiTTA的11种关系);2) 提出关系“元数”概念和可扩展的配对生成策略;3) 对现有SOTA模型进行了全面、深入的基准测试与分析。
- 主要实验结果如何:基准测试显示,现有最强模型(如TangoFlux, AudioGen)在核心关系感知指标mAMSR上得分极低,最高仅为2.22%(表2)。将TangoFlux在数据集上微调后,其mAMSR从零样本的1.77%显著提升至5.58%(表3),证明了基准的有效性。但所有模型在复杂嵌套关系和高“元数”关系上仍表现不佳(图6、图7)。
- 实际意义是什么:为关系感知TTA研究建立了可量化、可扩展的公共测试平台,揭示了当前技术的根本短板,指明了未来需重点攻克关系建模能力,而非仅提升音频保真度。
- 主要局限性是什么:1) 核心贡献集中于数据与评测,未提出全新的生成模型架构;2) 关系复杂度(最高五元)和规模(100种)仍可能无法覆盖真实世界所有潜在关系;3) 自动化评测依赖音频事件检测和声学效果分类器,其准确性可能影响最终得分。
🏗️ 模型架构
论文并未提出一个全新的端到端生成模型,而是提出了一个基准框架(Aurelius Framework),其核心在于数据构建与评测流程。框架主要包含以下组件:
- AudioEventSet 语料库:一个树形结构的音频事件本体,包含7个大类、23个子类、110个细粒度事件类别。每个事件对应约75个高质量、干净、独特的音频片段(图2左)。
- AudioRelSet 语料库:一个树形结构的音频关系本体,包含6个大类(时间性、空间性、计数、感知性、组合性、嵌套组合)、100种关系。关键创新是定义了关系的“元数”(arity),表示该关系所需音频事件的数量(图2中、图3)。
- 文本-音频对生成策略:流程如图4所示。为每个关系准备5个文本描述模板,通过“头-修饰语”结构描述音频事件。将模板中的占位符替换为AudioEventSet中的具体事件名称(并使用同义词增强多样性),生成文本提示。同时,根据关系规则和音频事件片段,合成相应的音频。该策略可近乎无限地生成多样化数据。
- 评测协议(MSR):一个分阶段的关系感知评估方法。首先从生成的音频中提取音频事件和关系,然后与目标对比,计算存在性(mAPre)、关系正确性(mARel)和简洁性(mAPar)分数,并综合为mAMSR。
架构图引用:
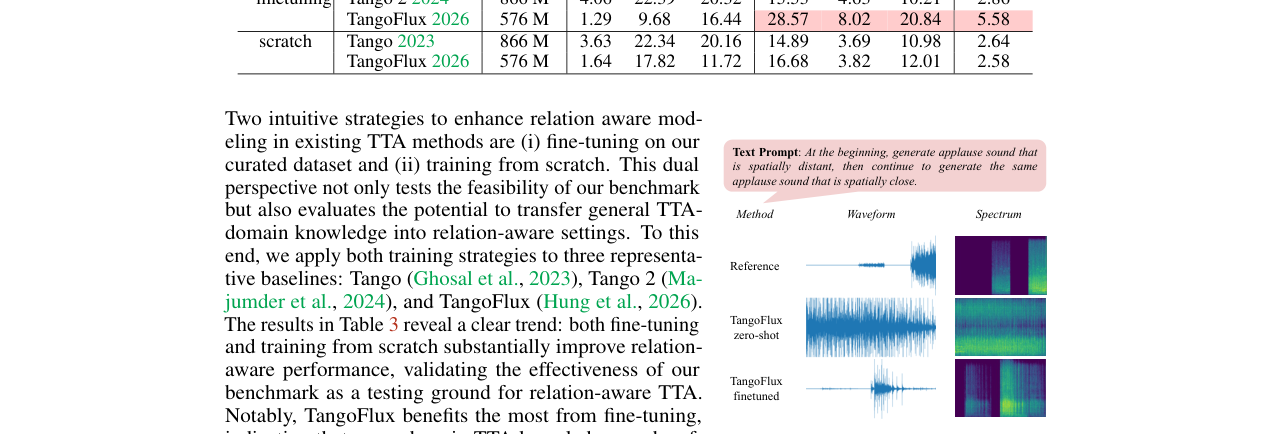
图2展示了AudioEventSet(左)和AudioRelSet(中)的树状层级结构,以及关系“元数”(arity)的概念示意图(右),该概念用于连接关系与音频事件以生成音频。
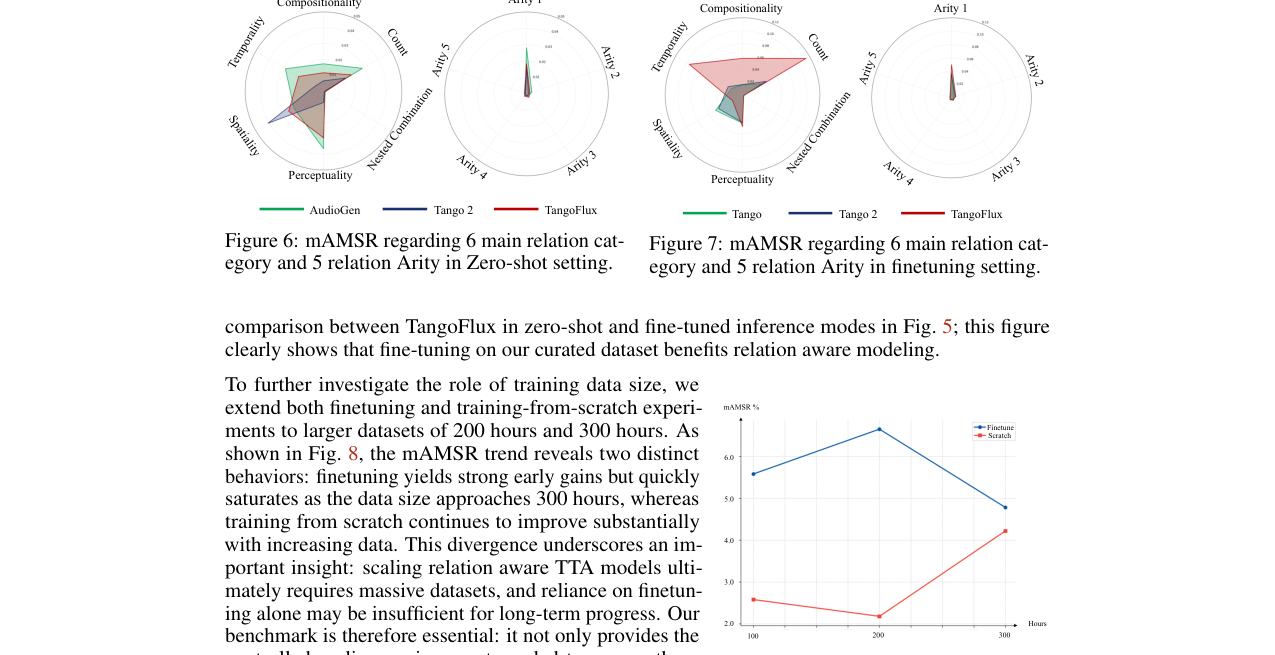
图4详细说明了文本-音频对生成过程:从AudioRelSet中选取关系(如蕴含、亲近性),从AudioEventSet中选取事件(如奶牛哞叫),通过文本模板(5种)和事件实例化生成文本提示,同时合成符合关系的音频。
💡 核心创新点
- 构建大规模专用数据集:首次为“关系感知”TTA任务构建了AudioEventSet(110个事件)和AudioRelSet(100个关系)两个高质量、结构化的语料库,解决了此前研究依赖小规模、嘈杂数据集的根本限制。
- 提出可扩展的配对生成策略:通过解耦音频事件和关系,并引入关系“元数”和文本模板化,设计了一种可自动生成海量、多样化训练/评测
<文本,音频>对的策略,支持研究的规模化。 - 建立系统化基准与评测体系:对9个主流TTA模型进行全面的零样本基准测试,并设计了针对关系感知的多阶段关系感知(MSR)评估协议,量化揭示了现有模型在关系建模上的巨大缺陷。
- 深入分析与实证研究:通过微调与从头训练对比实验(表3)、数据规模缩放实验(图8)、以及不同关系类别和元数下的细粒度性能分析(图6、图7),系统性地探索了提升关系感知能力的路径和瓶颈。
🔬 细节详述
- 训练数据:
- 数据集:本文自建的AudioEventSet和AudioRelSet。
- 来源:AudioEventSet音频来自freesound.org和FSD50K,经人工筛选确保高质量、独特性。
- 规模:训练集通过配对生成策略创建36,000对(每关系360对,约100小时);测试集10,000对(每关系100对,约28小时)。音频为10秒,16kHz采样率。
- 数据增强:在文本模板实例化时,为音频事件名称维护了同义词列表进行随机替换。
- 损失函数:论文中未详细说明,应沿用各基线模型(如TangoFlux)自身的损失函数。
- 训练策略:
- 方法:主要对比两种策略:1) 在预训练TTA模型基础上进行微调;2) 从头开始训练。
- 细节:具体的学习率、优化器、batch size等超参数未在正文中说明,可能在附录或依赖基线设置。
- 关键超参数:主要指基线模型的参数量,如TangoFlux为576M,AudioGen为1.5B等(表2)。
- 训练硬件:论文中未提及具体的GPU型号、数量和训练时长。
- 推理细节:
- 基线模型:使用发布的检查点,具体配置见附录表III(如TangoFlux: num_steps=50, guidance=3)。
- 代理工作流:使用Qwen2/2.5系列LLM作为规划器,将文本分解为子提示,然后用TangoFlux独立生成各段音频,最后按时间线拼接。
- 正则化或稳定训练技巧:未说明。
📊 实验结果
主要基准测试结果(零样本)
| 模型 | 参数量 | FAD ↓ | KL ↓ | FD ↓ | mAPre ↑ | mARel ↑ | mAPar ↑ | mAMSR (%) ↑ |
|---|---|---|---|---|---|---|---|---|
| AudioLDM (s-full) | 185 M | 4.02 | 21.23 | 22.36 | 3.47 | 0.91 | 2.95 | 0.73 |
| AudioLDM (l-full) | 739 M | 4.13 | 22.05 | 23.03 | 3.10 | 0.79 | 2.63 | 0.63 |
| AudioLDM 2 (l-full) | 844 M | 4.54 | 22.90 | 30.53 | 0.35 | 0.04 | 0.31 | 0.03 |
| MakeAnAudio | 452 M | 5.10 | 50.97 | 30.49 | 4.75 | 0.88 | 4.05 | 0.73 |
| AudioGen | 1.5 B | 7.97 | 25.19 | 32.29 | 11.3 | 2.84 | 9.13 | 2.22 |
| LAFMA | 272 M | 25.85 | 269.54 | 65.27 | 0.96 | 0.15 | 0.45 | 0.07 |
| Auffusion | 1.1 B | 4.13 | 42.59 | 31.17 | 6.71 | 1.41 | 4.07 | 0.79 |
| Tango | 866 M | 7.47 | 64.10 | 28.28 | 4.46 | 0.98 | 3.67 | 0.79 |
| Tango 2 | 866 M | 9.59 | 65.24 | 35.50 | 9.68 | 2.48 | 5.49 | 1.29 |
| TangoFlux | 576 M | 6.01 | 26.73 | 30.00 | 12.38 | 3.34 | 7.28 | 1.77 |
| Agent (Qwen2 7B+TangoFlux) | - | 9.98 | 142.87 | 39.20 | 3.53 | 0.77 | 2.25 | 0.04 |
| Agent (Qwen2.5 32B+TangoFlux) | - | 9.70 | 140.56 | 38.65 | 3.79 | 0.96 | 2.41 | 0.60 |
表2:在Aurelius基准上的定量评测结果。mAPre、mARel、mAPar值已乘以10^-2,mAMSR为百分比。所有模型在关系感知指标上表现都很差,最好的AudioGen的mAMSR仅为2.22%。
微调与从头训练对比实验
| 训练策略 | 模型 | 参数量 | FAD ↓ | KL ↓ | FD ↓ | mAPre ↑ | mARel ↑ | mAPar ↑ | mAMSR (%) ↑ |
|---|---|---|---|---|---|---|---|---|---|
| 微调 | Tango | 866 M | 3.88 | 33.26 | 21.30 | 14.58 | 4.18 | 10.16 | 2.73 |
| Tango 2 | 866 M | 4.06 | 22.39 | 20.32 | 15.53 | 4.63 | 10.21 | 2.86 | |
| TangoFlux | 576 M | 1.29 | 9.68 | 16.44 | 28.57 | 8.02 | 20.84 | 5.58 | |
| 从头训练 | Tango | 866 M | 3.63 | 22.34 | 20.16 | 14.89 | 3.69 | 10.98 | 2.64 |
| TangoFlux | 576 M | 1.64 | 17.82 | 11.72 | 16.68 | 3.82 | 12.01 | 2.58 |
表3:在测试集上微调与从头训练的结果对比。TangoFlux微调后性能提升最显著,mAMSR从1.77%升至5.58%。
不同设置下的模型性能分析图

图6:在零样本设置下,AudioGen在时间性、计数和感知性关系上表现相对较好,但所有模型在组合性关系和高元数关系上均表现不佳。
图7:微调后,TangoFlux在大多数关系类别上成为最佳模型,但其在嵌套组合和高元数关系上的性能仍显不足。
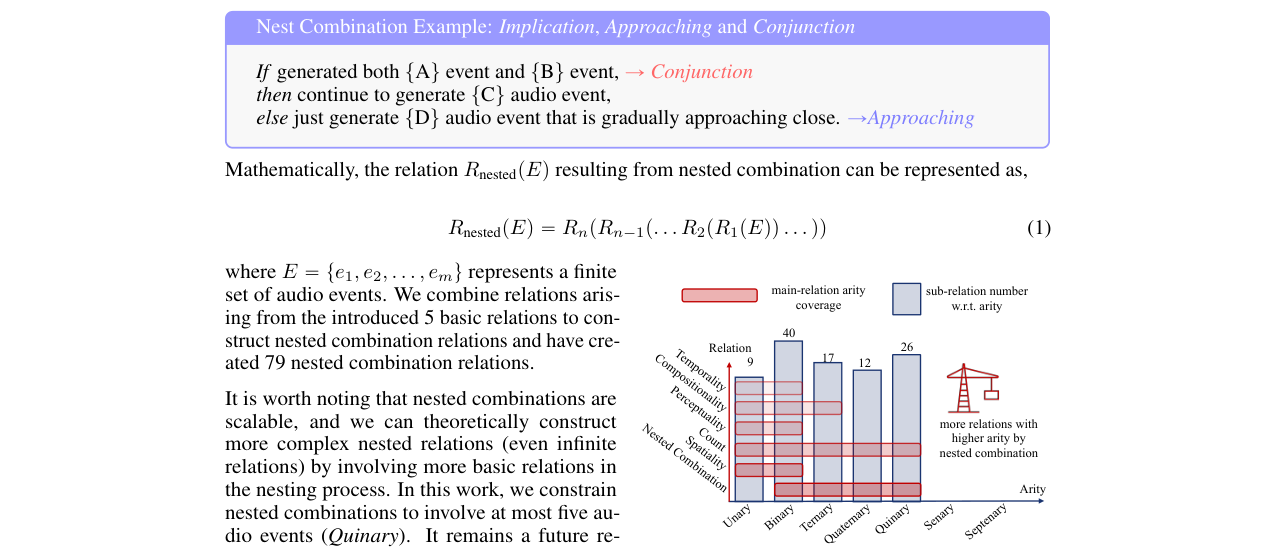
图8:微调策略在数据量增加到300小时时性能趋于饱和,而从头训练策略的性能随数据量增加持续提升。
单事件与多事件生成准确率对比(以TangoFlux为例)
| 描述 | 准确率 |
|---|---|
| 事件(单事件,无关系) | 75% |
| 事件(多事件,关系感知) | 12% |
| 关系(多事件,关系感知) | 3% |
表4:清晰地展示了当前SOTA模型TangoFlux在单事件生成上表现尚可,但在多事件关系感知生成上性能断崖式下跌。
⚖️ 评分理由
- 学术质量:5.5/7:论文在数据集构建、评测体系设计和系统性实验分析方面工作扎实、完整,技术细节清晰。但核心创新偏重于“基准”和“资源”建设,而非提出新的生成模型架构,在模型算法层面的突破性有限。
- 选题价值:1.5/2:关系感知是音频生成走向复杂场景理解和创作的必经之路,该选题具有明确的前沿性和实际应用潜力(如影视声音设计、游戏音效、辅助技术)。任务相对垂直,但本文奠定的基准对相关领域研究者价值很高。
- 开源与复现加成:1.0/1:论文明确提供了代码仓库和项目主页链接,详细介绍了数据集构建方法和评测协议,提供了基线模型的配置,使得复现其基准测试和分析工作具有较高可行性。