📄 AUHead: Realistic Emotional Talking Head Generation via Action Units Control
#生成模型 #扩散模型 #动作单元 #大语言模型
✅ 7.5/10 | 前25% | #生成模型 | #扩散模型 | #动作单元 #大语言模型
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Jiayi Lyu (中国科学院大学)
- 通讯作者:Jian Xue (中国科学院大学)
- 作者列表:
- Jiayi Lyu (中国科学院大学)
- Leigang Qu (National University of Singapore)
- Wenjing Zhang (中国科学院大学)
- Hanyu Jiang (中国科学院大学)
- Kai Liu (Zhejiang University)
- Zhenglin Zhou (Zhejiang University)
- Xiaobo Xia (National University of Singapore)
- Jian Xue (中国科学院大学)
- Tat-Seng Chua (National University of Singapore)
💡 毒舌点评
亮点在于首次尝试将大型音频语言模型(ALM)作为“情感理解-表情生成”的推理引擎,将模糊的语音情感线索解耦为结构化、可解释的动作单元(AU)序列,这一思路为跨模态生成任务提供了新颖的中间表示范式。短板则是第一阶段的AU预测精度完全依赖ALM的“想象”能力,其生成的AU序列可能并不完全忠于原始音频的真实口型运动,导致第二阶段生成时唇音同步性可能妥协,消融实验也表明其Sync得分略有下降。
🔗 开源详情
- 代码:提供了代码仓库链接:https://github.com/laura990501/AUHead_ICLR。
- 模型权重:论文中未明确说明是否公开训练好的模型权重检查点。
- 数据集:实验使用公开数据集MEAD和CREMA,论文中未说明如何获取或预处理脚本。
- Demo:论文中未提供在线演示链接。
- 复现材料:论文正文和附录(Appendix)详细描述了模型架构、训练目标(损失函数)、实现细节(学习率、硬件、GPU小时数)、评估设置,并提供了关键的超参数(如λ, γ, n, 引导尺度s)。附录还包含了使用的AU定义列表、数据验证工具说明、Prompt模板示例,以及额外的定性结果和视频链接。复现信息较为充分。
- 论文中引用的开源项目:
- Qwen-Audio-Chat:作为第一阶段的核心ALM。
- Hallo V1 和 MEMO:作为第二阶段的基础扩散模型。
- LoRA:用于第一阶段的微调。
- SyncNet:用于评估音唇同步。
- EAT:用于情感分类评估模型。
📌 核心摘要
- 要解决什么问题:现有的音频驱动说话头像生成方法缺乏对细微、丰富情感表达的精细控制,往往生成中性或表情单一的视频。
- 方法核心是什么:提出一个两阶段框架AUHead。第一阶段,利用大型音频语言模型(ALM,如Qwen-Audio-Chat)通过“情感先于动作单元”的思维链(CoT)机制,从音频中生成细粒度的动作单元(AU)序列。第二阶段,将AU序列映射为2D面部表示(如关键点或网格渲染),并设计一个AU驱动的可控扩散模型,通过上下文感知的AU嵌入和跨注意力机制,合成情感丰富且身份一致的说话头像视频。
- 与已有方法相比新在哪里:首次探索利用ALM作为中间桥梁,将音频理解为可解释的AU序列来控制视频生成。与直接使用情感标签或潜在码的方法相比,AU序列提供了更细粒度、结构化的空间和时间控制信号。
- 主要实验结果如何:
- 在MEAD和CREMA数据集上,与多个基线(如HalloV1, MEMO, AniPortrait等)对比,在视觉质量(PSNR, SSIM, FID)、表情真实度(Emotion ACC)和面部结构保真度(M/F-LMD)上均取得竞争力甚至领先的性能。
- 关键消融实验显示:采用“先情感后AU”的CoT策略比直接预测AU的精度更高(AU精度0.58 vs 0.50);使用2D AU表示(LMK/RoM)比1D AU序列显著提升了生成质量(例如MEAD上FID从11.11降至10.87)。
- 用户研究显示,在情感表达、视频质量和音唇同步方面,AUHead(64.63%, 63.63%, 71.00%)均显著优于强基线HalloV2。
- 实际意义是什么:为虚拟形象、影视制作和交互式系统提供了一种更可控、更具表现力的情感说话头像生成方案,增强了AI生成内容的真实感和情感交互能力。
- 主要局限性是什么:1) AU预测的准确性依赖于ALM的理解与生成能力,可能无法完美还原真实面部运动;2) 将1D AU序列上采样并映射为2D表示可能引入信息损失或模糊;3) 当前实验主要在受控数据集上进行,对复杂场景(如大角度头部运动、复杂背景)的泛化能力有待验证。
🏗️ 模型架构
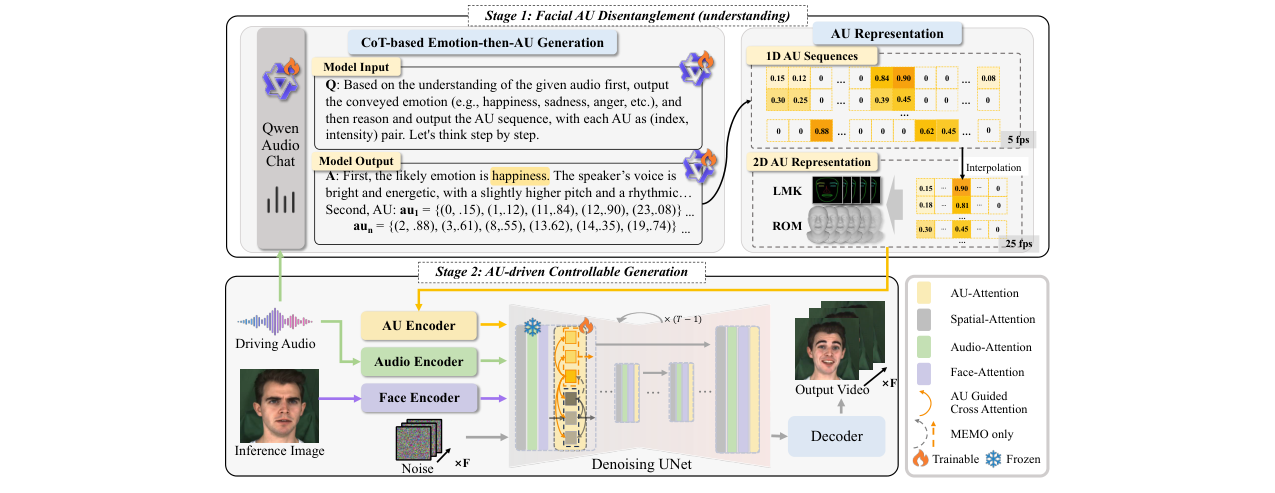
本论文提出了一个两阶段框架AUHead,旨在实现可控的、情感丰富的话者头部视频生成。其整体架构如图2所示。

(图2:AUHead框架总览。Stage 1利用ALM从音频生成AU序列;Stage 2利用AU驱动的扩散模型合成视频。)
第一阶段:面部AU解耦(理解)
- 输入:16kHz音频波形。
- 核心组件:微调后的音频语言模型(ALM),具体为Qwen-Audio-Chat。
- 关键技术:
- 空间-时间AU分词:将高维、稠密的AU向量(24维)转换为离散的(索引,强度)对集合,实现稀疏化表示(平均降低80.95%序列长度)。同时,在时间上以5 fps(而非原始的25 fps)进行降采样,以平衡序列长度与动态信息保留。
- 基于CoT的“情感先于AU”生成:模型首先预测音频表达的情感类别(如快乐、悲伤),然后以此为上下文,自回归生成对应的AU序列。这种粗到细的策略利用了情感与AU模式的相关性,提升了AU预测的准确性。
- 输出:一个与音频对齐的AU序列,表示为
AU_{1:T'},其中每个au_t是24维向量。
第二阶段:AU驱动的可控生成
- 输入:参考肖像图像、驱动音频、第一阶段生成的AU序列。
- 核心组件:基于潜在扩散模型(LDM)的去噪UNet,集成了AU适配器。
- 关键技术:
- AU表示:将低帧率的AU序列通过线性插值上采样至目标帧率(25 fps),并映射为2D结构表示,论文探索了关键点地标(LMK)和网格渲染(RoM)两种形式,以增强空间保真度。
- 上下文感知AU嵌入:对每个目标帧
t,取其前后共n=2帧(窗口大小5)的AU表示进行拼接,并通过一个轻量级时序卷积网络编码,得到能捕捉局部表情动态的嵌入c_t。 - AU-视觉交互:在预训练扩散模型的UNet中插入由多个跨注意力层组成的AU适配器。在每个去噪步骤和空间分辨率上,视觉潜在变量
z_t(Query)通过交叉注意力关注AU嵌入c_{AU}(Key/Value),从而实现AU条件对生成过程的精细化控制。
- 推理时控制:引入了一种解耦引导策略,允许独立调节AU引导强度(
s_{AU})和其他条件(如音频、运动先验)的引导强度(s_{H}),以平衡情感表达控制与整体视频质量。
(图7:定性结果展示。展示了AUHead在不同视觉风格(素描、油画、真实人脸)下生成10秒长视频的时序一致性与泛化能力。)
💡 核心创新点
- 首次利用ALM生成AU序列:开创性地将大型音频语言模型用于从音频预测面部动作单元序列,将ALM的情感理解能力显式地转化为可解释的面部运动控制信号,建立了音频理解与视觉生成之间新的桥梁。
- “情感先于AU”的思维链策略:借鉴CoT思想,设计粗到细的生成流程(先预测情感类别,再生成AU序列),有效利用了情感与AU之间的语义关联,提升了从音频中提取精细表情线索的准确性。
- AU到2D面部表示的映射与交互:超越简单的1D AU条件注入,将AU序列映射为结构化的2D面部表示(地标/网格),并通过专门设计的上下文感知嵌入和跨注意力机制与视觉特征交互,增强了生成的可控性和空间保真度。
- 推理时的解耦引导策略:提出针对AU条件的引导方法,允许在推理时灵活、独立地调节AU表达强度与其他条件的影响,实现了“AU控制强度-生成质量”之间的灵活权衡。
🔬 细节详述
- 训练数据:
- 数据集:MEAD(10,000个片段,8种情感)和 CREMA(7,442个片段,6种情感)。
- 预处理:统一重采样至25fps,512×512像素;音频重采样至16kHz。使用窗口大小和步长均为640采样点的梅尔频谱图评估同步性。
- 数据增强:未说明。
- 损失函数:
- Stage 1:语言建模交叉熵损失,用于监督AU序列的生成。
- Stage 2:标准的潜在扩散模型损失函数(公式1):
L = E_{I,c,t,ε} [ ||ε - ε_θ(z_t, t, c)||_2^2 ],其中条件c包含音频、参考图像和AU嵌入。
- 训练策略:
- Stage 1:对Qwen-Audio-Chat进行LoRA微调,学习率
1×10^{-4}。 - Stage 2:冻结预训练的扩散模型(Hallo V1或MEMO)主体,仅训练插入的AU适配器。Hallo V1基座学习率
5×10^{-6},MEMO基座学习率1×10^{-5}。 - 为支持无条件建模,训练时每个条件以一定概率随机置零。
- Stage 1:对Qwen-Audio-Chat进行LoRA微调,学习率
- 关键超参数:
- AU稀疏系数
λ = 0(允许输出0值)。 - AU时间降采样因子
γ = 0.2(即5 fps)。 - 上下文感知嵌入窗口大小
n = 2(即前后各2帧)。 - 推理时默认AU引导尺度
s_{AU}= 3.5(根据图3消融实验选定的最佳权衡点)。
- AU稀疏系数
- 训练硬件:
- Stage 1:4× NVIDIA A100 GPU,约24 GPU小时。
- Stage 2:4× NVIDIA A100 GPU,12 GPU小时。
- 推理细节:在单张NVIDIA A100 GPU上完成Stage 1的AU预测和Stage 2的视频生成。解码器
D解码生成的潜在变量得到最终帧图像。 - 正则化/稳定训练技巧:AU适配器中的跨注意力层使用零初始化,以确保训练初期不影响预训练模型的输出。
📊 实验结果
主要对比实验(与SOTA方法): 论文在MEAD和CREMA数据集上与多个前沿方法进行了定量比较,结果如表3所示。AUHead(基于MEMO)在关键指标上表现优异。
| 数据集 | 方法 | Sync (↑) | PSNR (↑) | SSIM (↑) | FID (↓) | M/F-LMD (↓) |
|---|---|---|---|---|---|---|
| MEAD | MEMO* (基线) | 6.9885 | 23.1910 | 0.7345 | 11.1237 | 2.0684/2.2473 |
| AUHead (MEMO) | 6.6311 | 23.3466 | 0.7395 | 10.9671 | 1.8608/2.1604 | |
| HalloV2 | 6.3832 | 21.4575 | 0.6779 | 15.6245 | 2.3489/2.5880 | |
| CREMA | MEMO* (基线) | 6.0922 | 24.2808 | 0.7410 | 8.3881 | 1.9678/2.4296 |
| AUHead (MEMO) | 6.2050 | 24.2912 | 0.7413 | 8.2361 | 1.9313/2.4025 | |
| Sonic | 6.8620 | 23.0787 | 0.7341 | 9.9440 | 1.9454/2.3638 |
关键发现:与基线MEMO相比,AUHead在PSNR、SSIM(视觉质量)和FID(感知真实度)上均有提升,M-LMD和F-LMD(唇/脸结构保真度)也更低,表明AU引导增强了表情细节和面部结构的准确性。尽管在MEAD上Sync分数略有下降,但用户研究(表4)显示,在主观感知上AUHead的音唇同步更受青睐(71.00% vs 13.75%)。
消融实验:
- Stage 1 CoT策略有效性(表1):“先情感后AU”策略的AU预测精度(F1=0.69)和情感准确率(67.01%)显著优于其他组合。
- Stage 2 AU表示形式(表2):使用2D表示(LMK或RoM)比1D AU序列在几乎所有指标上都有提升,尤其是在FID和LMD上。

(图3:AU引导尺度消融实验。展示了FID、情感准确率(ACCemo)和MAE随AU CFG scale的变化趋势,星号标记了最佳平衡点。)
定性比较:图4和图11展示了与AniPortrait, Echomimic, HalloV1, MEMO等方法的定性对比。AUHead生成的结果在表情生动性(如眉毛运动、眼神)和纹理清晰度上具有优势,减少了模糊和形变伪影。

(图4:在MEAD和CREMA数据集上与SOTA方法的定性比较,标注了基线方法常见问题(牙齿异常、模糊、表情平淡)。)
⚖️ 评分理由
- 学术质量:6.0/7 - 创新性强,提出了新颖的“ALM->AU序列->扩散模型”的两阶段框架,技术细节完整(分词、CoT、2D表示、跨注意力、引导策略)。实验设计合理,在标准基准上进行了充分的定量和定性比较,并提供了深入的消融研究。证据可信,结果分析严谨。主要扣分点在于第一阶段的AU生成本质上依赖于预训练ALM的“幻觉”,其准确性边界和泛化能力存疑;此外,AU到2D表示的映射可能并非最优,且未与其他中间表示(如3DMM参数)进行对比。
- 选题价值:1.5/2 - 选题聚焦于情感可控的说话头像生成,这是当前数字人、虚拟形象领域的核心痛点之一,具有明确的应用前景和学术前沿性。采用AU作为控制信号比情绪标签更细粒度、更可解释,与音频/语音读者的关联度中等(更偏向视觉生成与多模态交叉领域)。
- 开源与复现加成:0.5/1 - 论文提供了代码仓库链接(https://github.com/laura990501/AUHead_ICLR),并声明提供了实现。附录和正文详细说明了模型架构、训练细节、超参数和评估设置。这为复现提供了良好基础。未给满分是因为未提及模型权重是否公开,且数据集(MEAD, CREMA)为公开数据集,但论文未说明其具体使用协议或预处理脚本。