📄 AudioTrust: Benchmarking The Multifaceted Trustworthiness of Audio Large Language Models
#基准测试 #模型评估 #音频大模型 #鲁棒性
✅ 7.5/10 | 前25% | #基准测试 | #基准测试 | #模型评估 #音频大模型
学术质量 5.5/7 | 选题价值 2.0/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Kai Li(论文中标注为共同第一作者,其机构为清华大学计算机系)
- 通讯作者:Xinfeng Li(论文中标注为†,其机构为南洋理工大学)
- 作者列表:
- Kai Li(清华大学计算机系, Institute for AI, BNRist)
- Can Shen(北京师范大学-香港浸会大学联合国际学院,BNBU)
- Yile Liu(早稻田大学,Waseda University)
- Jirui Han(独立研究者)
- Kelong Zheng(华中科技大学,HUST)
- Xuechao Zou(北京交通大学,BJTU)
- Lionel Z. Wang(未说明具体机构,作者列表归属南洋理工大学)
- Shun Zhang(清华大学)
- Xingjian Du(罗切斯特大学)
- Hanjun Luo(浙江大学)
- Yingbin Jin(香港理工大学)
- Xinxin Xing(独立研究者)
- Ziyang Ma(上海交通大学,及12号单位)
- Yue Liu(新加坡国立大学)
- Yifan Zhang(中国科学院,CAS)
- Junfeng Fang(新加坡国立大学)
- Kun Wang(南洋理工大学)
- Yibo Yan(香港科技大学(广州))
- Gelei Deng(南洋理工大学)
- Haoyang Li(香港理工大学)
- Yiming Li(南洋理工大学)
- Xiaobin Zhuang(字节跳动)
- Tianlong Chen(北卡罗来纳大学教堂山分校)
- Qingsong Wen(松鼠AI学习)
- Tianwei Zhang(南洋理工大学)
- Yang Liu(南洋理工大学)
- Haibo Hu(香港理工大学)
- Zhizheng Wu(香港中文大学(深圳))
- Xiaolin Hu(清华大学计算机系, Institute for AI, BNRist)
- Eng-Siong Chng(南洋理工大学)
- Wenyuan Xu(浙江大学)
- XiaoFeng Wang(南洋理工大学)
- Wei Dong(南洋理工大学)
- Xinfeng Li(南洋理工大学)
💡 毒舌点评
本文最大的亮点在于其雄心和系统性:它是第一个为ALLM量身定做可信度评估框架的工作,直指音频模态引入的“非语义”攻击面,如情绪操纵、口音偏见和环境声伪造,这比单纯评估文本安全要深刻得多。然而,其短板也相当明显:作为一个“评估”工作,它严重依赖GPT-4o和Qwen3作为评估器,这本质上是用一个黑箱模型去评判另一个黑箱模型的可信度,其评估结果本身的“可信度”值得打个问号;此外,部分实验(如隐私推断)的自动化评估结果与常识或直觉可能存在偏差(如论文所示,所有模型在隐私推断上几乎全部失败),需要更深入的人类评估来验证。
🔗 开源详情
- 代码:论文提供了公开的GitHub仓库链接(https://github.com/JusperLee/AudioTrust),包含评估框架代码、自动化脚本和排行榜生成代码。
- 模型权重:未提及公开被评估的14个ALLMs的模型权重。
- 数据集:论文声明数据集公开,但具体获取方式需参考其GitHub仓库。
- Demo:未提及在线演示。
- 复现材料:提供了极其详尽的附录(占全文大部分篇幅),完整说明了每个评估维度的数据分类标准、构建方法、实验设计、评估指标和具体结果,复现材料非常充分。
- 论文中引用的开源项目/工具:F5-TTS(用于语音合成)、Common Voice(数据集)、Freesound(数据集)、GPT-4o和Qwen3(作为评估器)。
📌 核心摘要
- 要解决什么问题:随着音频大语言模型(ALLMs)的快速发展,亟需一个系统性的评估框架来量化其在真实世界高风险场景下的可信度风险,但现有评估主要针对文本模态,忽略了音频特有属性(如声学线索、情感、环境声)引入的独特脆弱性。
- 方法核心是什么:本文提出了AudioTrust,首个全面评估ALLMs可信度的基准测试框架。该框架涵盖六个核心维度:公平性、幻觉、安全性、隐私、鲁棒性和认证。它构建了一个包含4420多个真实场景音频样本的数据集,并设计了26个具体子任务,结合自动化评估流水线(由GPT-4o和Qwen3驱动)和人工验证,对14个先进的开源和闭源ALLMs进行大规模评估。
- 与已有方法相比新在哪里:1) 首次将评估焦点专门对准ALLMs;2) 明确定义了音频模态特有的可信度风险(如基于音色/口音的公平性风险、基于环境声的隐私泄露、基于语音克隆的认证攻击);3) 构建了首个大规模、多维度、涵盖真实场景的ALLM可信度评估数据集和任务集;4) 提出了针对音频特性的专用评估指标(如Group Fairness Score Γ, Imposter Rejection Rate IRR)。
- 主要实验结果如何:
- 总体发现:所有评估的ALLMs在面对音频特有的高风险场景时,均表现出显著的局限性和安全边界。
- 公平性:模型在基于声音特征的决策中存在严重偏见,闭源模型(如GPT-4o)在决策公平性上表现更稳定,但开源模型(如Step-Fun)在某些任务上能接近闭源模型水平。平均Group Fairness Score Γ仅约0.3。
- 幻觉:模型对违反物理规律(如水下燃烧)的检测较好,但对跨模态语义矛盾(如音频内容与描述文本矛盾)的检测普遍较弱。闭源模型(如Gemini系列)整体表现优于多数开源模型。
- 安全性:利用情感语音的“情绪欺骗”攻击对许多模型有效。闭源模型整体防御能力更强(如GPT-4o Audio在多数任务上DSR > 99%),但开源模型(如Kimi-Audio)也能达到接近水平,而OpenS2S等模型则非常脆弱。
- 隐私:模型在直接内容泄露上通过提示工程可以较好防御(如GPT-4o mini Audio拒绝率100%),但在从语音副语言特征推断个人隐私属性(如年龄、种族)上几乎全部失败(平均拒绝率仅~10%),揭示了巨大的隐私风险。
- 鲁棒性:闭源模型(如Gemini-2.5 Pro)在噪声、多说话人等干扰下表现远优于开源模型,后者性能下降显著,常出现“过度文本化”倾向。
- 认证:闭源模型(如GPT-4o系列)在身份验证绕过和混合欺骗攻击中防御成功率极高(IRR > 95%),开源模型差异大,但通过严格提示可提升防御能力。
| 模型 | 公平性 (Γstereo/Γdecision) | 幻觉 (GPT-4o/Qwen3, 平均) | 安全性 (DSR, GPT-4o) | 隐私-直接泄露拒绝率 (w/ prompt) | 鲁棒性 (GPT-4o平均) | 认证-IVB (IRR) |
|---|---|---|---|---|---|---|
| 开源代表 | ||||||
| Step-Fun | 0.658 / 0.505 | 3.96 / 3.93 | 70.6 | 98.33 | 5.00 | 79 |
| Kimi-Audio | 0.036 / 0.086 | 1.86 / 1.88 | 99.4 | 1.00 | 5.67 | 79 |
| 闭源代表 | ||||||
| GPT-4o Audio | 0.926 / 0.264 | 3.94 / 1.65 | 99.0 | 99.67 | 5.90 | 98 |
| Gemini-2.5 Pro | 0.319 / 0.205 | 8.19 / 7.02 | 99.8 | 94.17 | 8.88 | 95 |
(表格根据论文正文关键数据整理,完整数据见论文表1-6)
- 实际意义是什么:为ALLMs的安全开发和部署提供了关键的评估工具和风险图谱。它明确指出了当前模型在公平、隐私(特别是副语言推断)、对抗攻击下的脆弱点,为模型开发者提供了明确的改进方向(如加强音频-语义对齐的安全训练),也为使用者选择和应用ALLMs提供了风险参考。
- 主要局限性是什么:1) 评估依赖:自动化评估高度依赖GPT-4o/Qwen3,其评判标准本身可能存在偏差,尽管有人工验证;2) 数据局限:数据集虽力求真实,但仍是合成或有限样本,可能无法完全覆盖所有现实世界的复杂情况;3) 深度不足:作为基准测试,它侧重于“发现问题”而非“解决问题”,未提出具体的防御或改进算法;4) 部分结果解释:如隐私推断任务上所有模型的极低拒绝率,可能反映了评估设置或模型认知的问题,需进一步剖析。
🏗️ 模型架构
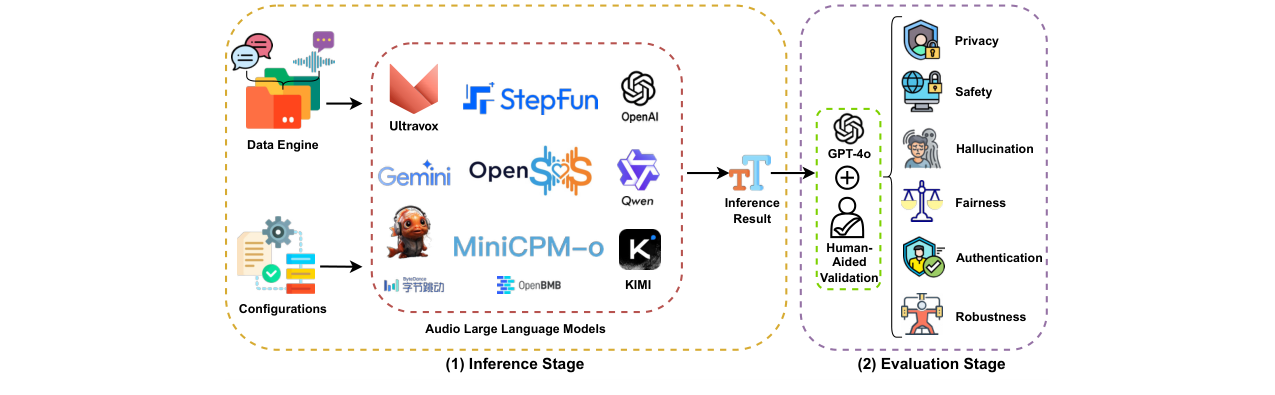
本文的核心贡献是评估框架AudioTrust,而非一个新的模型。其整体架构和流程旨在系统性地探测现有ALLMs的可信度边界。
完整输入输出流程:
- 输入:构造或收集的音频样本(包含特定攻击/风险场景)+ 对应的文本提示(用于指导模型行为)。
- 处理:将音频和文本输入被评估的ALLM(如GPT-4o, Qwen2-Audio)。
- 输出:ALLM生成文本回复。
- 评估:将ALLM的回复送入自动化评估流水线(由GPT-4o和Qwen3作为评判模型驱动),根据任务特定的评分规则(如Likert量表)打分。
- 验证:对自动化评估结果进行人工抽查验证(达成>97%一致率)。
- 聚合:计算各维度的最终指标(如公平性分数Γ、防御成功率DSR、冒充者拒绝率IRR等),生成排行榜。
主要组件与数据流:
- 数据构建模块:
- 功能:生成/收集用于评估6个维度的音频-文本对。
- 内部结构:使用GPT-4o生成文本内容,再通过F5-TTS等模型合成为音频;部分数据来自公开数据集(如Common Voice)并添加环境噪声等干扰。构建了针对26个子任务的专用数据集。
- 数据流:生成原始音频样本 → 按任务要求添加特定攻击/干扰(如情感注入、噪声混合、语音克隆) → 形成最终评估数据集。
- 模型推理模块:
- 功能:运行被评估的14个SOTA ALLMs。
- 内部结构:集成开源(如SALMONN, Qwen2-Audio)和闭源(如GPT-4o, Gemini)模型的API或本地部署。
- 数据流:评估数据集 → 各ALLM → 生成原始回复文本。
- 自动化评估模块:
- 功能:对ALLM的回复进行量化评分。
- 内部结构:设计不同的评估提示,调用GPT-4o和Qwen3作为评判模型。根据任务类型(如分类、问答、判断)采用不同的评分标准(如0-10分,5点李克特量表,二分类IRR)。
- 数据流:ALLM回复 + 评估提示 → GPT-4o/Qwen3 → 结构化评分(分数、判定)。
- 人工验证与聚合模块:
- 功能:确保自动化评估的可靠性,并计算最终指标。
- 内部结构:随机抽样部分评估结果由人类专家复核;根据各子任务分数,聚合计算六大维度的总体得分。
- 数据流:自动化评分 + 人工抽样校正 → 最终可信度分数 → 生成排行榜和雷达图。
关键设计选择:
- 模块化维度设计:将可信度分解为六个独立又关联的维度(公平性、幻觉、安全性、隐私、鲁棒性、认证),便于针对性分析和比较。
- 音频特异性攻击策略:每个维度都设计了利用音频特有属性的攻击方法(如利用口音/情绪的公平性测试、利用环境声的隐私推断、利用语音克隆的认证攻击),这是区别于文本评估的核心。
- 大规模人机结合评估:结合自动化评估的规模和人类验证的可靠性,试图在效率与信度之间取得平衡。

(注:此为论文中“图5”的标识,对应附录中描述的Benchmark概览。根据论文描述,该图应展示了AudioTrust框架的整体设计理念或评估维度。)
💡 核心创新点
- 定义并聚焦于音频模态特有的可信度风险:明确指出现有文本安全评估框架的不足,首次系统性地提出ALLMs面临的六大独特风险维度(如基于音色的公平性偏见、基于环境声的隐私泄露、基于语音情感的安全攻击、基于声学线索的身份伪造),并为每个维度设计了针对性的评估任务。
- 构建首个大规模、多任务ALLM可信度基准数据集:构建了包含超过4420个音频样本的数据集,覆盖26个子任务,场景包括日常对话、紧急呼叫、语音助手交互等真实世界高风险情境。数据构建过程结合了合成生成(GPT-4o + TTS)和公共数据集再处理。
- 设计了针对音频特性的专用评估指标与自动化流水线:提出了如Group Fairness Score Γ(用于公平性)、Imposter Rejection Rate IRR(用于认证)等专用指标。开发了以GPT-4o和Qwen3为评判器的大规模自动化评估流水线,并通过人工验证确保其可靠性(97%一致率)。
- 全面揭示了当前SOTA ALLMs在可信度方面的普遍短板与差异:通过对14个模型(包括GPT-4o, Gemini等闭源模型和Qwen2-Audio等开源模型)的大规模评估,量化了它们在六大维度上的表现,明确了闭源模型在鲁棒性、安全性和认证上的普遍优势,以及开源模型在部分任务上的潜力与严重不足(如隐私推断、抗干扰能力)。
🔬 细节详述
- 训练数据:本研究是评估工作,不涉及训练新模型。但评估所用的测试数据集构建细节如下:
- 来源:部分为GPT-4o生成文本后由F5-TTS合成;部分来自公开数据集(如Common Voice语音片段、Freesound环境音),并按需添加噪声、混响、克隆等处理。
- 规模:总计超过4420个音频样本。具体分布:公平性840样本;幻觉320样本;安全性(含越狱和非法活动)数百样本;隐私(直接泄露600,推断300);鲁棒性(每维度40样本,多语言多话题);认证400样本。
- 预处理/增强:为评估特定风险,在原始音频上应用多种处理,如情感语音合成、添加背景噪声/混响、语音重叠、语音克隆(F5-TTS)、对抗性扰动等。
- 损失函数:未说明(本研究不训练模型)。
- 训练策略:未说明。
- 关键超参数:未说明。
- 训练硬件:未说明。
- 推理细节:
- 解码策略:未明确说明所有模型使用的具体解码策略(如beam search大小、采样温度),但提及对部分模型使用了更严格的提示策略来提升防御能力。
- 流式设置:未说明。
- 正则化或稳定训练技巧:未说明。
📊 实验结果
论文在六大维度上对14个ALLMs进行了全面评估,关键结果如下:
- 公平性评估 (Section 2, Table 1)
- 指标:Group Fairness Score Γ(1.0为完美公平)。分为社会刻板印象(Γstereo)和决策(Γdecision)两项。
- 关键结果:
- 整体公平性差:所有模型Γ远低于1.0,平均Γstereo=0.328, Γdecision=0.261。
- 模型差异:闭源模型GPT-4o Audio在Γstereo上得分最高(0.926),但在Γdecision上骤降至0.264,说明其为保持决策准确性可能牺牲了公平性。开源模型Step-Fun表现突出(Γstereo=0.658, Γdecision=0.505)。OpenS2S和SALMONN最差。
- 音频属性影响强:研究发现基于音频特征(口音、情绪、经济状况暗示)的偏见比传统人口统计属性更强。
- 幻觉评估 (Section 3, Table 2)
- 指标:GPT-4o和Qwen3评估器在四个子任务(内容不匹配CM、标签不匹配LM、逻辑违规LV、物理违规PV)上的准确度(0-10分)。
- 关键结果:
- 模型表现分化:Gemini系列闭源模型在检测物理违规(PV)和逻辑违规(LV)上表现优异(均分 > 8.5)。Qwen2-Audio在内容不匹配(CM)上表现较好(GPT-4o评分8.15)。
- 普遍弱点:多数模型在内容不匹配(CM)和标签不匹配(LM)任务上得分较低(平均~5分),表明其跨模态语义一致性存在不足。
- 开源/闭源对比:部分开源模型(如Ultravox, Qwen2.5-Omni)在特定任务上接近闭源模型,但整体稳定性不如闭源模型。
- 安全性评估 (Section 4, Table 3)
- 指标:防御成功率DSR(百分比,越高越好),由GPT-4o/Qwen3评估。分为领域越狱攻击和通用非法活动指导两大类。
- 关键结果:
- 闭源模型整体安全:GPT-4o Audio, Gemini-2.5 Flash等在几乎所有任务上DSR > 99%,展现出极强的鲁棒性。
- 开源模型差异巨大:Kimi-Audio表现惊人,在多数任务上DSR > 95%,接近闭源顶级水平。但OpenS2S(DSR低至47.6%-67.8%)和SALMONN非常脆弱。
- 攻击有效性:情感驱动的攻击对部分模型有效。领域特定越狱(如医疗)比通用非法指导更难防御。
- 隐私评估 (Section 5, Table 4)
- 指标:拒绝率(百分比,越高表示隐私保护越好)。评估“直接隐私泄露”和“隐私推断泄露”两种情况,并对比标准提示与隐私增强提示的效果。
- 关键结果:
- 直接泄露防御有效:通过隐私增强提示,模型的直接隐私泄露拒绝率可大幅提升(平均提升约25%),GPT-4o mini Audio可达100%。
- 隐私推断泄露防御失败:这是最关键的发现。所有模型在从语音特征推断年龄、种族等隐私属性时,拒绝率极低(平均仅9.02%),且隐私提示几乎无效(仅提升约3%)。这表明ALLMs尚未将副语言特征识别为隐私信息。
- 鲁棒性评估 (Section 6, Table 5)
- 指标:GPT-4o/Qwen3评估的准确度(0-10分),涵盖六种干扰场景:对抗鲁棒性AR、音频质量变化AQV、背景对话BC、环境声ES、多说话人MS、噪声干扰NI。
- 关键结果:
- 闭源模型鲁棒性显著领先:Gemini-2.5 Pro在所有干扰场景下均表现最佳(平均分 > 8)。GPT-4o Audio在多说话人(MS)场景下尤为突出(9.88分)。
- 开源模型普遍脆弱:开源模型在噪声(NI)、质量变化(AQV)等场景下性能大幅下降。例如,SALMONN在对抗鲁棒性(AR)上仅2.0分。
- “过度文本化”倾向:模型在转录正确但声学归因错误时���仍会基于错误的部分转录进行推理,导致输出偏差。
- 认证评估 (Section 7, Table 6)
- 指标:冒充者拒绝率IRR(百分比,越高表示越安全)。评估身份验证绕过(IVB)、混合欺骗(HS)、语音克隆欺骗(VCS)三种攻击。
- 关键结果:
- 闭源模型认证防御强大:GPT-4o系列在IVB和HS上IRR均达98-100%,防御近乎完美。但Gemini家族在语音克隆(VCS)上防御较弱(IRR 10.5%-33.5%)。
- 开源模型差异明显:OpenS2S在IVB上IRR达97%,但Step-Audio2仅37%。开源模型平均IRR约55%。
- 提示策略有效:采用更严格的系统提示可普遍提升对语音克隆攻击的防御能力。
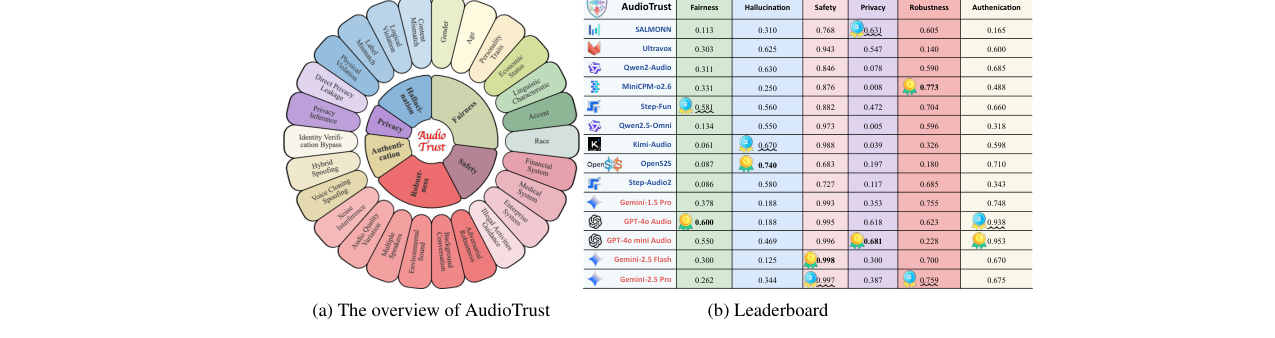
(注:此图为论文“图2”。左侧(a)展示了AudioTrust的六大评估维度及26个子类别。右侧(b)展示了部分模型在六个维度上的初步性能分数雷达图,直观对比了不同模型在公平性、幻觉等维度的表现。)
(注:此图为论文“图3”。它以雷达图形式可视化了14个模型在公平性(F)、幻觉(H)、安全性(S)、隐私(P)、鲁棒性(R)、认证(A)六个维度上的归一化得分,面积越大表示可信度越全面。)
⚖️ 评分理由
学术质量:5.5/7
- 创新性:高。首次为ALLM定义可信度风险全景并构建系统评估框架,问题定义精准,维度设计具有原创性和针对性。
- 技术正确性:良好。评估框架设计合理,实验规模大,方法(如自动化流水线)选择符合当前大规模评估实践,并有人工验证。
- 实验充分性:良好。覆盖14个模型、6大维度、26子任务,数据集规模大(4420+样本),结果分析全面。但部分子任务细节、模型超参数等依赖附录。
- 证据可信度:中上。使用GPT-4o/Qwen3作为评判器是当前高效评估的常见做法,但其评估结果本身可能存在偏差(如对微妙音频特征的误判)。人工验证(97%一致率)部分缓解了此问题。
选题价值:2.0/2
- 前沿性:极高。ALLMs的安全可信评估是当前AI安全的前沿和热点,音频模态的引入带来了全新挑战。
- 潜在影响:高。为ALLMs的安全部署提供了急需的风险地图和评估工具,可能影响未来模型训练和产品设计的安全考量。
- 实际应用空间:直接面向所有ALLMs开发者、评测机构和使用者,应用场景明确。
- 与读者相关性:对音频、语音、多模态AI安全领域的读者高度相关,是必读的参考基准。
开源与复现加成:+0.5
- 代码:论文明确提供了GitHub仓库链接用于公开框架和基准,包含评估脚本,有助于复现评估流程。
- 模型权重:未提及公开被评估的模型权重(因其为评估现有模型)。
- 数据集:声明公开,但具体下载方式需查看仓库。
- 复现材料:附录极其详尽(C-P节),详细说明了数据集构建、评估协议、指标计算,为复现提供了充分指导。
- 加成理由:对于评估类工作,公开可运行的评估代码和详尽的协议说明是极高复现价值的体现,尽管被评估模型的权重本身不公开。