📄 AC-Foley: Reference-Audio-Guided Video-to-Audio Synthesis with Acoustic Transfer
#音频生成 #流匹配 #多模态模型 #零样本
🔥 8.0/10 | 前25% | #音频生成 | #流匹配 | #多模态模型 #零样本
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Pengjun Fang(香港科技大学)
- 通讯作者:未明确说明。论文列出了多位作者及其单位,通常通讯作者会在投稿系统中标注,但此处文本未明确指出。根据作者列表顺序和惯例,可能为Qifeng Chen或Harry Yang,但为避免猜测,此处标记为“未说明”。
- 作者列表:
- Pengjun Fang(香港科技大学)
- Yingqing He(香港科技大学)
- Yazhou Xing(香港科技大学)
- Qifeng Chen(香港科技大学)
- Ser-Nam Lim(中佛罗里达大学)
- Harry Yang(中佛罗里达大学)
💡 毒舌点评
AC-Foley的亮点在于用“听觉范例”替代“文字描述”来指挥AI配音,这巧妙绕过了语言在描述“微妙质感”时的无力感,并通过精心设计的两阶段训练确保了模型不是简单复读机。然而,其短板也明显:当视频或参考音本身涉及多重声源交叠或节奏极端错配时(比如用猫叫配急促打字),模型的协调能力就会捉襟见肘,暴露了其在处理复杂声景和时序冲突上的稚嫩。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。仅在伦理声明中提及未来将以Apache 2.0许可证发布模型。
- 模型权重:未提及公开预训练权重。
- 数据集:使用公开数据集(VGGSound, AudioCaps2.0, WavCaps),并说明了其许可证(见附录F)。
- Demo:未提供在线演示链接。
- 复现材料:提供了详尽的训练细节(优化器、学习率schedule、batch size、训练硬件与时间)、网络结构参数(隐藏维度、block数量),以及消融实验的设置,复现信息较为充分。
- 引用的开源项目/模型:论文依赖并提及了以下开源工作:CLIP(视觉/文本编码器)、Synchformer(同步特征提取器)、BigVGAN(声码器)、ImageBind(多模态嵌入,用于数据筛选和评估)、AdamW(优化器)。
📌 核心摘要
这篇论文(ICASSP 2026 / ICLR 2026)针对现有视频到音频(V2A)生成方法中依赖文本控制导致的语义粒度粗和描述模糊两大瓶颈,提出了AC-Foley,一种参考音频引导的视频到音频合成框架。其核心方法是直接将参考音频的声学特征作为条件信号,通过多模态Transformer和基于流匹配的生成模型,合成与视频同步且具有参考音频音色特性的声音。与已有方法相比,AC-Foley的新颖之处在于:1) 用音频直接控制,实现了细粒度音色迁移和零样本声音生成;2) 提出了包含重叠与非重叠条件的两阶段训练策略,解决了参考音频的时间适配与泛化问题。
主要实验结果如下:在VGGSound测试集上,AC-Foley在多个指标上超越了现有SOTA方法。例如,在“有音频条件”设置下,其FDPaSST达到56.00(低于MMAudio+CLAP基线的70.80),MCD达到11.37(低于基线的14.63)。消融实验证实了两阶段训练和多模态条件组合的有效性(表4,表6)。在“无音频条件”设置下,该模型性能也具有竞争力(表1)。此外,在音色迁移任务上,AC-Foley在未使用Greatest Hits数��集训练的情况下,超越了专门训练的CondFoley模型(表2)。该工作的实际意义在于为电影、游戏等领域的音效设计提供了更灵活、精确的AI辅助工具。主要局限性包括在处理多声源复杂环境和极端时间错配场景时性能下降(见论文LIMITATIONS部分)。
🏗️ 模型架构
AC-Foley是一个多模态条件生成框架,其输入为无声视频序列、参考音频片段和文本描述,输出为与视频时间对齐、并融合了参考音频声学特征的音频波形。
整体流程:
- 编码:视频、参考音频、文本分别通过各自的编码器提取特征。参考音频通过预训练的VAE编码器转换为潜变量,以保留完整声学特征(而非仅语义信息)。视频和文本通过CLIP编码,视频同步特征通过Synchformer提取。
- 多模态条件融合:将文本特征、视频特征、同步特征以及参考音频的VAE潜变量(经平均池化)与时间步嵌入结合,形成一个统一的多模态条件向量
c。 - 条件生成:使用条件流匹配(CFM)模型(基于Transformer)在潜空间进行去噪。条件向量
c通过自适应层归一化(adaLN) 调制生成过程的每一层,将控制信号注入生成网络。 - 解码:生成的潜变量通过VAE解码器恢复为梅尔频谱图,再通过预训练的声码器(BigVGAN)转换为最终波形。
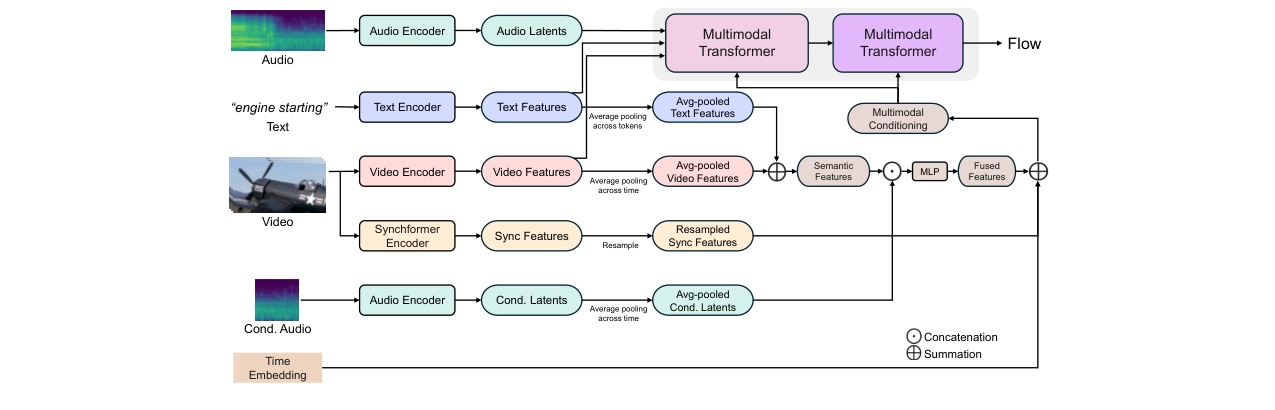
图2:AC-Foley方法概览图。展示了视频、文本、参考音频三种模态如何通过各自编码器(CLIP, Synchformer, VAE)提取特征,并在多模态Transformer中通过条件向量c融合,以指导音频潜变量的生成。
关键组件:
- 音频控制模块:这是论文的核心贡献。它使用预训练的VAE编码器处理参考音频,生成保留完整频谱/音色信息的潜变量
x1。在推理时,这个潜变量与流匹配过程中的时间步t和高斯噪声xt一起输入速度场网络。这种设计确保了控制信号是声学层面的,而非语义层面的。 - 多模态Transformer:主体是一个基于Transformer的去噪网络。输入是潜在音频表示,通过多模态条件向量
c进行调制。论文未详细说明内部block数量,但指出使用了混合的多模态和单模态block(见附录B)。 - 两阶段训练策略:这是解决“如何将参考音频适应到不同视频上下文”这一关键挑战的方法(详见下图)。
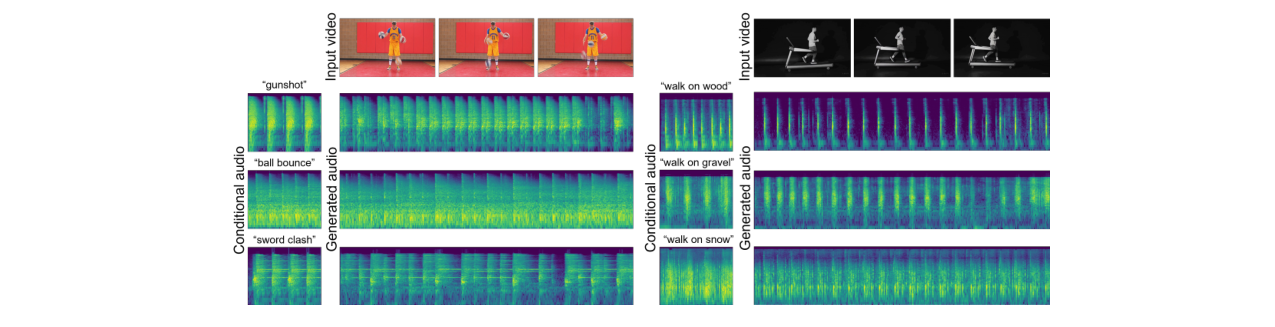
图3:两阶段训练过程示意图。(a) 第一阶段(重叠条件):从目标音频中随机采样重叠片段作为条件,学习声学特征提取。(b) 第二阶段(非重叠条件):使用同一视频中非重叠的音频片段作为条件,迫使模型利用视频的声学自相似性进行泛化,而非简单复制。
💡 核心创新点
- 参考音频直接控制,突破文本描述局限:之前V2A方法主要依赖文本提示,无法精确控制“不同狗叫的细微差异”或“金属撞击的具体质感”。AC-Foley直接以音频信号作为条件,使用户能通过提供“示例声音”来精准指定生成音频的音色、质感等声学属性,实现了细粒度声音合成和音色迁移(如图1所示)。
- “重叠-非重叠”两阶段训练策略:简单地将参考音频叠加到视频会导致时间错位和“复制粘贴”行为。该策略第一阶段使用重叠片段让模型学习声学特征的提取与对齐;第二阶段使用同一视频中非重叠的片段作为条件,利用视频内容(如连续动作)固有的声学自相似性,迫使模型学习如何将学到的声学特征转换并适应到新的时间上下文中,从而具备真正的泛化控制能力。
- 多模态条件中的声学特征保留:区别于一些使用CLAP等模型仅提取音频语义嵌入的方法,AC-Foley使用VAE编码器直接处理参考音频。这保留了音频的完整声学签名(包括音高、节奏、频谱包络等),为细粒度控制提供了可能。同时,它将这种声学特征与文本、视频、同步特征统一融合,实现了全局语义与局部声学特征的协同控制。
🔬 细节详述
- 训练数据:
- 音视频数据:VGGSound(约18万条10秒视频)。
- 音文数据:AudioCaps2.0(约9.8万条带人工标注的10秒音频)和WavCaps(约7600小时自动标注音频,提取为60万条10秒片段)。
- 微调数据:使用ImageBind得分>0.3筛选出的VGGSound高质量子集。
- 损失函数:论文采用条件流匹配(CFM)目标(公式1),即最小化预测速度场
vθ与真实向量场(x1 - x0)之间的均方误差。这是一个回归损失,用于训练生成模型。 - 训练策略:
- 两阶段训练:如上文详述。第一阶段(重叠),从10秒视频的前8秒目标音频中随机采样2秒作为条件;第二阶段(非重叠),使用该视频原始音频的最后2秒(与前8秒不重叠)作为条件。
- 微调:在第二阶段训练后,在高质量VGGSound子集上微调40k次迭代。
- 优化器:AdamW。
- 学习率:初始学习率1e-4,前1k步线性warmup,在200k步后衰减至1e-5,在240k步后衰减至1e-6。
- Batch size:320。
- 总迭代:260k。
- 训练时长与硬件:在8张NVIDIA H800 GPU上训练约26小时。使用bfloat16混合精度。
- 稳定化技术:采用事后指数移动平均(EMA)(σ_rel=0.05)。
- 关键超参数(见附录B):
- 生成音频:44.1kHz,编码为40维、43.07fps的潜变量。
- Transformer:7个多模态块 + 14个单模态块,隐藏维度896。
- 推理细节:未详细说明解码策略(如温度、步数),仅提到使用预训练的BigVGAN声码器进行波形合成。
📊 实验结果
主要对比实验(表1): 论文在VGGSound测试集上与多个SOTA方法进行了定量对比。关键结果如下:
| 方法 | FDPaSST↓ | FDPANNs↓ | FDVGG↓ | KLPaSST↓ | KLPANNs↓ | IB↑ | DeSync↓ | Onset Acc.↑ | Onset AP↑ | MCD↓ |
|---|---|---|---|---|---|---|---|---|---|---|
| 有音频条件 | ||||||||||
| Video-Foley | 613.05 | 73.17 | 17.45 | 4.16 | 4.75 | 3.6 | 1.214 | 0.2146 | 0.3409 | 17.41 |
| MMAudio + CLAP | 70.80 | 7.95 | 4.33 | 1.17 | 1.36 | 35.7 | 0.431 | 0.2511 | 0.5107 | 14.63 |
| AC-Foley (ours) | 56.00 | 4.93 | 1.08 | 0.84 | 0.95 | 37.1 | 0.465 | 0.2832 | 0.5317 | 11.37 |
| 无音频条件 | ||||||||||
| MMAudio-L-V2 | 69.25 | 8.81 | 3.98 | 1.12 | 1.34 | 37.8 | 0.392 | 0.2816 | 0.5257 | 14.11 |
| AC-Foley (w/o audio) | 64.90 | 8.59 | 3.87 | 1.17 | 1.34 | 36.6 | 0.410 | 0.2619 | 0.5095 | 14.59 |
结论:无论有无音频条件,AC-Foley在分布匹配(FD/KL)、语义一致性(IB)和频谱保真度(MCD)等关键指标上均达���或接近最优。
音色迁移实验(表2): 在Greatest Hits数据集上,AC-Foley与专门用于此任务的CondFoley对比,尽管后者在此数据集上训练,AC-Foley在所有指标(Onset Acc., Onset AP, MCD)上均占优。
消融实验(表4):
- 两阶段训练:仅用“重叠”训练,FDPaSST为80.07;切换至“非重叠”训练后,FDPaSST大幅降至60.82(↓30.1%),MCD也从12.84降至11.30,证明了非重叠条件对泛化和特征利用的关键作用。完整两阶段训练进一步优化了时序同步(DeSync)。
- 条件组件消融(表6):移除音频(w/o. audio)导致FDPaSST和MCD显著恶化;移除同步特征(w/o. sync)严重破坏时序对齐(DeSync飙升至1.240)。证明各模态条件互补且必要。
图4:定性结果展示。左图显示同一视频在不同参考音频(吉娃娃、大狗)控制下生成不同音色的狗叫;右图显示音色迁移和零样本文本控制生成。证明了模型按参考音频声学特性进行控制的能力。
人类研究(表3): 与MMAudio-L-V2相比,AC-Foley在“音质保真度”上获得83.5% 的胜率,在“时序对齐”上获得61.1% 的胜率(另有21.8%认为相当),主观评价显著领先。
⚖️ 评分理由
- 学术质量(6.5/7):论文针对V2A生成中的控制粒度瓶颈,提出了一个原理清晰、设计精巧的解决方案(参考音频控制+两阶段训练)。技术实现正确,基于成熟的流匹配和Transformer框架。实验对比充分(表1,表2),消融研究严谨(表4,表5,表6),提供了定量指标、人类研究等多角度证据,可信度高。扣分点在于模型架构本身(Transformer+CFM)创新有限,且对复杂声景的处理能力尚未验证。
- 选题价值(1.5/2):视频到音频生成是多模态生成的热点,提升生成可控性是核心需求。该工作为专业音效创作提供了新的可能性,应用前景明确(影视后期、游戏开发)。选题具有前沿性和实用价值,但任务领域相对垂直。
- 开源与复现加成(0.5/1):论文详细披露了训练配置、超参数、硬件环境,为复现提供了坚实基础。但未明确承诺开源代码、模型或演示,因此仅给予中等加成。