📄 A cross-species neural foundation model for end-to-end speech decoding
#语音识别 #自监督学习 #跨模态 #端到端
✅ 7.5/10 | 前25% | #语音识别 | #自监督学习 | #跨模态 #端到端
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.3 | 置信度 高
👥 作者与机构
- 第一作者:Yizi Zhang(Columbia University), Linyang He(Columbia University)(*表示共同第一作者)
- 通讯作者:未明确说明(论文中提供了通讯邮箱,但未明确标注“Corresponding Author”)
- 作者列表:Yizi Zhang(Columbia University), Linyang He(Columbia University), Chaofei Fan(Stanford University), Tingkai Liu(Microsoft), Han Yu(Columbia University), Trung Le(University of Washington), Jingyuan Li(Amazon), Scott Linderman(Stanford University), Lea Duncker(Columbia University), Francis R Willett(Stanford University), Nima Mesgarani(Columbia University), Liam Paninski(Columbia University)
💡 毒舌点评
这篇论文堪称BCI语音解码领域的“系统集成大师”,它巧妙地将跨物种预训练、Transformer编码器和音频LLM这几个当前最时髦的模块组装成一个性能SOTA的端到端框架,展现了强大的工程整合能力和扎实的实验功底。然而,其核心创新更多在于“组合”而非“发明”,且最终端到端性能仍未超越精心调优的级联系统,这或许暗示了“神经信号直接生成文本”这条路还有很长的坡要爬。
🔗 开源详情
- 代码:论文中未提及提供开源代码仓库链接。
- 模型权重:未提及公开预训练或微调后的模型权重。
- 数据集:论文中引用的大部分预训练数据集(如Churchland et al., 2012; Willett et al., 2023/2025; Kunz et al., 2025等)均为公开数据集,可通过DANDI、DRYAD、Zenodo等平台获取。竞赛数据集(Brain-to-Text ‘24, ‘25)为公开基准。
- Demo:未提及提供在线演示。
- 复现材料:论文提供了非常详尽的复现信息,包括:
- 完整的模型架构细节(Transformer、MLP投影器)。
- 所有训练超参数范围和最终选择值。
- 损失函数的具体公式。
- 数据预处理流程。
- 基线模型(RNN)的具体配置。
- 竞赛提交的具体流程(如集成策略)。
- 论文中引用的开源项目:引用了PyTorch作为深度学习框架;引用了Ray Tune用于超参数调优;引用了OPT、Qwen系列模型作为LLM基线;引用了DeepSpeed ZeRO-3用于大模型训练优化。
📌 核心摘要
- 问题:现有侵入式语音脑机接口(BCI)多采用“神经信号→音素→句子”的级联框架,各阶段独立优化,无法全局最优,且难以处理跨任务(如想象语音)的泛化问题。
- 核心方法:本文提出名为BIT(BraIn-to-Text)的端到端框架。其核心是一个跨物种、跨任务预训练的Transformer神经编码器,该编码器在大量人类和猕猴Utah阵列记录数据上,通过自监督掩码建模进行预训练,学习通用的神经活动表征。编码器输出通过一个浅层MLP投影到文本嵌入空间,然后与一个音频大语言模型(Audio-LLM)解码器端到端连接,并通过对比学习进行模态对齐,直接生成句子。
- 创新点:a) 首次提出跨物种、跨任务的神经编码器预训练范式,以解决神经数据稀疏和非平稳问题;b) 将音频LLM引入BCI,利用其在语音任务上的先验知识提升解码性能;c) 通过对比学习显式对齐神经与文本嵌入空间,实现跨任务(尝试语音与想象语音)的泛化。
- 主要结果:在Brain-to-Text竞赛基准上:
- 级联设置(编码器+ n-gram LM):BIT达到了新的SOTA(WER 6.35%),并通过集成进一步降至5.10%(Brain-to-Text’24)和1.76%(Brain-to-Text’25)。
- 端到端设置(编码器+ Audio-LLM):BIT将之前最佳端到端方法的WER从24.69%大幅降低至10.22%(集成后),缩小了与级联系统的差距。
- 跨任务迁移:在数据量极少的想象语音任务上,预训练带来的性能提升比尝试语音更显著,且跨物种预训练比单任务有监督预训练效果更好。代表结果见下表:
| 方法 | Brain-to-Text ‘24 WER (非集成) | Brain-to-Text ‘24 WER (集成) | Brain-to-Text ‘25 WER (非集成) | Brain-to-Text ‘25 WER (集成) |
|---|---|---|---|---|
| BIT (级联) | 6.35% | 5.10% | 4.06% | 1.76% |
| BIT (端到端) | 15.67% | 10.22% | 11.06% | 7.76% |
| 之前最佳级联 (Feghhi et al., 2025) | 7.98% | 5.68% | - | - |
| 之前最佳端到端 (Feng et al., 2024) | 24.69% | - | - | - |
- 实际意义:为瘫痪患者的高精度交流提供了新的端到端技术路径,证明了基础模型思想在神经解码中的有效性,并为跨模态(神经-文本/音频)对齐研究提供了新范式。
- 主要局限性:a) 端到端推理速度(~0.95秒/句)慢于级联(~0.24秒/句),难以实时应用;b) 高度依赖大规模、高质量的预训练数据,而人类侵入式BCI数据获取成本极高;c) 跨物种(猴)数据带来的增益有限,数据价值更多体现在物种内部的多样性。
🏗️ 模型架构
BIT框架的完整架构如图1所示,其数据流与组件功能如下:
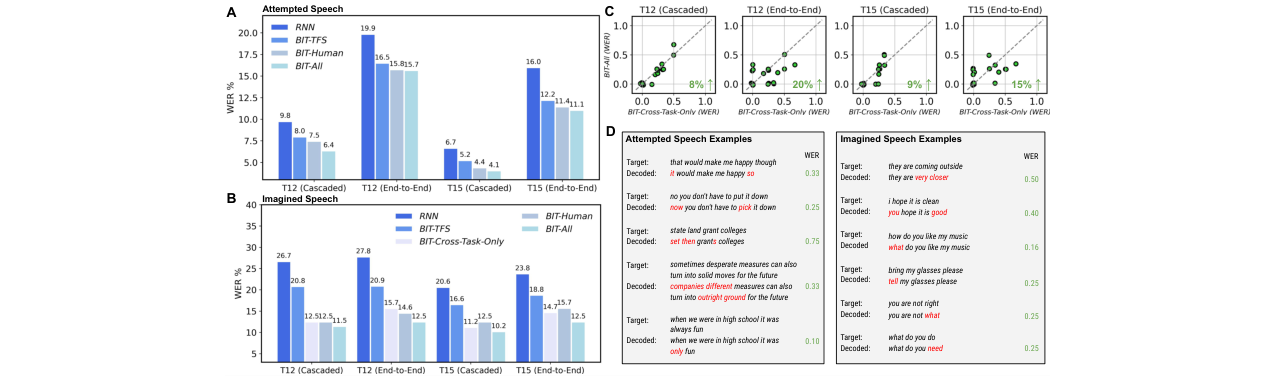
图1:BIT框架示意图。 (A)展示了整体流程:来自Utah阵列的神经活动经过预训练神经编码器,再由MLP投影器送入音频LLM解码器,生成文本。训练使用交叉熵损失和对比损失。(B)详细展示了神经编码器的预训练与微调阶段:输入神经活动经线性嵌入和分块后,进入Transformer编码器;预训练阶段使用掩码重建损失,微调阶段使用CTC损失进行音素解码。(C)展示了端到端解码器的细节:神经编码器输出经MLP投影后,被当作“神经模态”或“音频模态”输入LLM,并与文本嵌入进行对齐。
- 输入处理:原始神经活动数据(来自Utah阵列的阈值计数和尖峰波功率)被划分为20毫秒的时间窗,并进行Z-score标准化以处理电极漂移。
- 神经编码器:采用Transformer架构。首先,通过“补丁嵌入”模块将连续的多个时间步(例如5个)组合成一个“时间补丁”(token),以匹配语音的慢时间尺度。编码器使用双向注意力,其内部包含多头自注意力层和前馈网络,并采用RoPE位置编码。其关键设计是:
- 自监督预训练:采用掩码自编码器(MAE)策略,随机掩码部分时间补丁,训练模型重建原始神经信号,学习通用的神经表征。
- 有监督微调:移除掩码模块,在目标数据集上使用连接主义时序分类(CTC)损失训练其预测音素序列。这一步骤并非为了输出音素,而是将语音相关的语言学信息注入神经表征中。
- 模态投影与对齐:神经编码器的输出通过一个浅层MLP投影器映射到LLM的文本嵌入空间。同时,引入一个模态对齐器,通过对比学习将平均池化后的神经嵌入和文本嵌入拉近,实现跨模态对齐。
- LLM解码器:采用一个预训练的音频LLM(如Aero1-Audio 1.5B)。神经嵌入被插入到特定的提示词(如“decode the above neural activity…”)之后,与文本嵌入一起作为LLM的输入。LLM通过自回归方式预测下一个词,生成完整句子。训练时,使用低秩适应(LoRA)高效微调LLM的部分参数(注意力、前馈层及多模态投影器),而大部分参数保持冻结。
- 输出:直接生成连贯的英文句子。
💡 核心创新点
- 跨物种、跨任务的神经编码器自监督预训练:在大量人类和猕猴Utah阵列记录数据(包括语音任务和手臂运动任务)上,采用掩码重建的自监督目标进行预训练。此举突破了单一任务、单一受试者数据量少的瓶颈,学习到能抵抗电极漂移、跨任务可迁移的神经动力学表征。这是模型在低数据量想象语音任务上表现优异的关键。
- 端到端“神经到文本”的生成式框架:摒弃了传统的“神经→音素→文本”级联流水线,直接使用一个单一的、可微分的神经网络(神经编码器 + 音频LLM)将神经活动映射为文本句子。这允许对整个系统进行联合优化,理论上能获得更优的整体性能。
- 将音频大语言模型引入BCI解码:首次系统性地探索并证明了经过音频任务预训练的LLM(Audio-LLM)相比纯文本LLM,能更好地作为神经信号的解码器。这是因为音频LLM内嵌了对语音时序和声学特性的先验知识,使得浅层的神经-文本投影更容易对齐。
- 显式的跨模态对齐学习:引入对比损失,拉近同一句子对应的神经嵌入和文本嵌入,同时推开不匹配的嵌入对。这一机制不仅提升了端到端性能,更使得模型学到了在尝试语音和想象语音两种不同任务下语义一致的神经表征,实现了跨任务泛化。
🔬 细节详述
- 训练数据:
- 预训练数据:
98小时人类Utah阵列数据(包括语音解码和手写任务)和269小时猕猴运动任务数据。来源广泛,具体数据集列表见附录A。 - 微调数据:Brain-to-Text ‘24(T12受试者)和 ‘25(T15受试者)的尝试语音数据集,以及对应的想象语音数据集(Kunz et al., 2025)。
- 数据预处理:所有数据重采样到20毫秒时间窗,并进行跨天Z-score标准化。当提供时,将阈值计数和尖峰波功率(SBP)结合作为输入特征。
- 预训练数据:
- 损失函数:
- 预训练:均方误差(MSE)损失,用于重建被掩码的神经信号。
- 音素微调:连接主义时序分类(CTC)损失。
- 端到端解码:交叉熵损失(用于自回归生成) + 对比损失(用于神经-文本模态对齐)。总损失为两者之和。
- 训练策略:
- 优化器:AdamW。
- 学习率:预训练为 5e-4,音素微调在 5e-5 到 1e-3 之间调优,端到端解码为 5e-5。
- 批大小:预训练为64;端到端解码时,小模型(<7B)为16或8,大模型(≥7B)使用梯度累积,有效批大小为8或64。
- 训练轮数:预训练400轮,音素微调800轮,端到端解码150轮。
- 超参数调优:使用Ray Tune随机采样30组超参数(批大小、权重衰减、学习率)进行选择。
- 关键超参数:神经Transformer编码器约700万参数,含投影器和解码头后总参数约1300万。补丁大小为5个时间步。LoRA秩为8,缩放因子为32。
- 训练硬件:所有训练在单块或多块NVIDIA A100/A40/L40 GPU(40/48/80GB内存)上完成。预训练约2天,音素微调最多1天,端到端解码最多2天。
- 推理细节:解码使用核采样(nucleus sampling),参数p=0.9,温度0.7,最多生成25个新词元。未提及流式处理设置。
- 正则化技巧:在预训练中应用时间掩码作为数据增强;使用dropout(编码器0.2,注意力0.4);在LLM解码器中使用LoRA进行参数高效微调。
📊 实验结果
论文在尝试语音和想象语音两个任务上进行了全面评估,主要结果如下:
- 模型基准对比(尝试语音) 在Brain-to-Text竞赛的基准上,与各类基线进行对比。关键结果汇总于表1和表2。
表1:Brain-to-Text ‘24 竞赛结果(T12受试者,1200句测试集)
| 方法 | WER |
|---|---|
| 之前最佳端到端 (Feng et al., 2024) | 24.69% |
| BIT 端到端 | 15.67% |
| BIT 端到端 + 集成 | 10.22% |
| 基线RNN (级联) | 9.76% |
| 之前最佳级联 (Feghhi et al., 2025) | 7.98% |
| BIT 级联 | 6.35% |
| 之前最佳级联+集成 | 5.77% |
| BIT 级联 + 集成 | 5.10% |
表2:Brain-to-Text ‘25 竞赛结果(T15受试者,1450句测试集)
| 方法 | WER |
|---|---|
| BIT 端到端 | 11.06% |
| BIT 端到端 + 集成 | 7.76% |
| 基线RNN (级联) | 6.67% |
| BIT 级联 | 4.06% |
| RNN + 集成 | 3.09% |
| BIT 级联 + 集成 | 1.76% |
- 关键消融实验
- LLM解码器类型:如图3所示,音频LLM(如Aero1-Audio 1.5B)在相当模型规模下显著优于文本LLM,验证了音频预训练知识对神经解码的增益。同时,将神经嵌入视为“神经模态”略优于视为“音频模态”。
图3:LLM解码器消融实验。 (C-D)展示了不同LLM模型、模态处理方式和是否使用对比学习对验证集WER的影响。蓝色条(音频LLM)普遍低于黄色条(文本LLM),且使用对比学习(实心条)优于不使用(斜线条)。
- 预训练的收益:在想象语音任务(数据极少)上,预训练的收益远大于尝试语音。例如,BIT-All比从头训练(BIT-TFS)在T12想象语音上WER降低了约40%(见图2B)。跨物种预训练(BIT-All)优于单任务有监督预训练(BIT-Cross-Task-Only)。
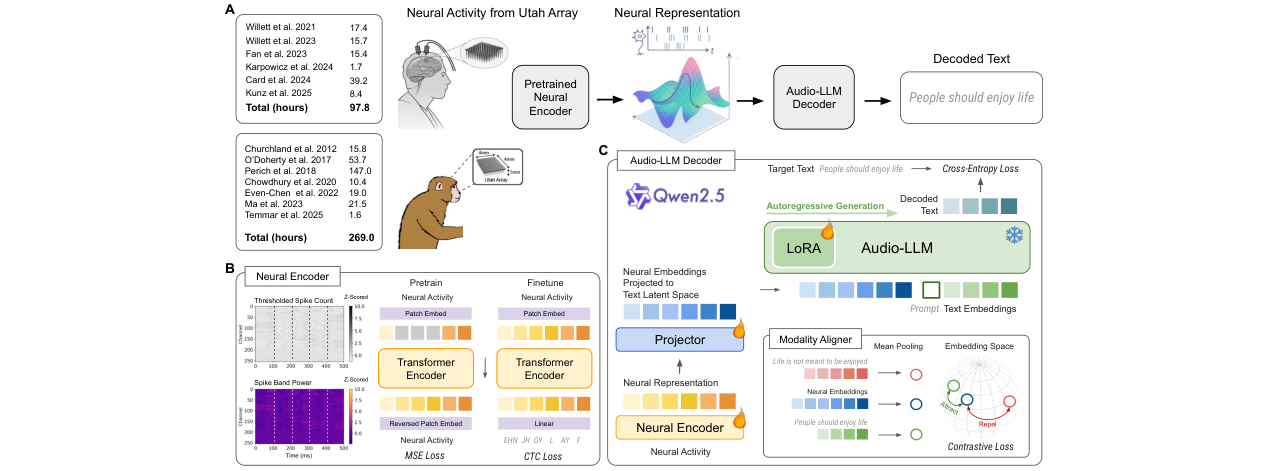
图2:BIT与基线模型在尝试和想象语音解码上的性能对比。 (A)尝试语音,预训练编码器(BIT-Human, BIT-All)在级联和端到端设置中均优于RNN和从头训练的Transformer(BIT-TFS)。(B)想象语音(50词词汇),预训练带来巨大增益,BIT-All表现最佳。
- 跨任务泛化分析
- 表征相似性分析(RSA):如图4A所示,预训练编码器的神经嵌入与音频LLM文本嵌入的相似性,高于RNN和从头训练的Transformer,表明预训练有助于学习更接近语言结构的表征。
- 嵌入对齐:如图4B-C所示,原始神经活动在PCA空间中,尝试语音与想象语音明显分离。而经过BIT处理后,两种任务的嵌入在语义空间(通过PCA可视化)中更加重合,表明模型学到了跨任务共享的语义表征。图4D的注意力权重可视化进一步证实了这一点。
图4:BIT对齐尝试与想象语音的神经嵌入以实现跨任务泛化。 (A) 神经与文本嵌入的RSA分数。(B) 原始神经活动的PCA可视化,尝试与想象任务分离。(C) BIT输出嵌入的PCA可视化,两种任务嵌入更接近。(D) 交叉注意力投影器的权重,显示神经-文本对齐模式在两种任务中相似。
⚖️ 评分理由
- 学术质量:6.0/7 - 创新性体现在系统性地将跨物种预训练、Transformer编码器和音频LLM整合到一个BCI解码框架中,并在竞赛中取得SOTA,技术路线正确且实现扎实。实验极其充分,包含多维度消融和深度分析。主要不足在于端到端性能仍未超越最佳级联系统,且预训练数据中跨物种数据的价值有限。
- 选题价值:1.5/2 - 位于BCI与AI的前沿交叉点,解决重大现实问题(帮助瘫痪患者),具有高社会价值和学术影响力。对音频/语音研究者而言,其跨模态对齐方法提供了有价值的参考。但领域非常垂直,直接相关读者面相对较窄。
- 开源与复现加成:0.3/1 - 论文详细公开了模型架构、超参数、损失函数和训练策略等几乎所有复现细节。数据集来源明确。但未提供代码或模型权重链接,且复现依赖于昂贵的侵入式BCI数据和强大算力,实际复现门槛较高。