📄 YuE: Scaling Open Foundation Models for Long-Form Music Generation
#音乐生成 #预训练 #歌唱语音合成 #自回归模型
✅ 7.5/10 | 前10% | #音乐生成 | #预训练 | #歌唱语音合成 #自回归模型
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 1.0 | 置信度 高
👥 作者与机构
- 第一作者:Ruibin Yuan(香港科技大学,MAP)
- 通讯作者:未说明(论文列出了多位通讯作者,按字母排序:Jiaheng Liu, Jian Yang, Wenhao Huang, Wei Xue, Xu Tan, Yike Guo)
- 作者列表:Ruibin Yuan(香港科技大学,MAP), Hanfeng Lin(香港科技大学,MAP), Shuyue Guo(MAP), Ge Zhang(MAP,密歇根大学), Jiahao Pan(香港科技大学,MAP), Yongyi Zang(独立), Haohe Liu(萨里大学,MAP), Yiming Liang(MAP), Wenye Ma(MBZUAI,MAP), Xingjian Du(罗切斯特大学,MAP), Xeron Du(MAP), Zhen Ye(香港科技大学), Tianyu Zheng(MAP), Zhengxuan Jiang(MAP), Yinghao Ma(MAP,伦敦玛丽女王大学), Minghao Liu(2077AI,MAP), Zeyue Tian(香港科技大学,MAP), Ziya Zhou(香港科技大学,MAP), Liumeng Xue(香港科技大学,MAP), Xingwei Qu(MAP), Yizhi Li(MAP,曼彻斯特大学), Shangda Wu(中央音乐学院,MAP), Tianhao Shen(MAP), Ziyang Ma(MAP,上海交通大学,南洋理工大学), Jun Zhan(复旦大学), Chunhui Wang(吉利汽车), Yatian Wang(香港科技大学), Xiaowei Chi(香港科技大学), Xinyue Zhang(香港科技大学), Zhenzhu Yang(香港科技大学), Xiangzhou Wang(MAP), Shansong Liu(美团), Lingrui Mei(美团), Peng Li(香港科技大学), Junjie Wang(清华大学), Jianwei Yu(月之暗面), Guojian Pang(MAP), Xu Li(小红书), Zihao Wang(浙江大学,卡内基梅隆大学), Xiaohuan Zhou(MAP), Lijun Yu(卡内基梅隆大学), Emmanouil Benetos(伦敦玛丽女王大学,MAP), Yong Chen(吉利汽车), Chenghua Lin(曼彻斯特大学,MAP), Xie Chen(上海交通大学), Gus Xia(MBZUAI,MAP), Zhaoxiang Zhang(中国科学院), Chao Zhang(清华大学), Wenhu Chen(滑铁卢大学,MAP), Xinyu Zhou(月之暗面), Xipeng Qiu(复旦大学), Roger Dannenberg(卡内基梅隆大学,MAP)。 (注:“MAP”指Multimodal Art Projection团队)
💡 毒舌点评
亮点:首个开源且能生成长达五分钟、歌词对齐的完整歌曲的基础模型系列,其双轨分离预测和结构化渐进条件等技术,为解决长时序、多信号音乐生成提供了坚实且可扩展的方案。短板:尽管在结构控制和音域广度上与商业模型持平甚至超越,但其主观音质评估(人声与伴奏质感)与Suno V4仍有清晰可见的差距,且论文中未提供其超大模型(7B)在完整训练集上所需的、惊人的计算资源细节。
🔗 开源详情
- 代码:提供了GitHub仓库链接:https://github.com/multimodal-art-projection/YuE
- 模型权重:在HuggingFace上提供了模型集合:https://huggingface.co/collections/m-a-p/yue
- 数据集:未提供可直接下载的数据集。论文说明了数据来源为网络挖掘的CC许可音乐和语音,并给出了混合比例和语言/风格分布,但未提供构建好的数据集或处理脚本。
- Demo:提供了在线演示网站:https://map-yue.github.io/
- 复现材料:论文详细说明了模型架构(附录C、D)、训练设置、超参数和评估协议。提供了训练数据量级(如7B模型在1.75T token上训练)、模型尺寸等关键信息,但未给出具体的硬件配置(如GPU型号和数量)和完整训练时长。
- 论文中引用的开源项目:X-Codec (音频分词器), LLaMA2 (基础架构), Vocos (上采样器), Whisper (WER评估), audioldm_eval, CLAP, CLaMP 3, RMVPE等。
📌 核心摘要
本文旨在解决长篇、高质量、歌词到完整歌曲(包含人声和伴奏)生成这一核心挑战。为此,作者提出了“YuE(乐)”——一个开源的基础模型家族。其核心方法包含三个关键技术:1)双轨分离预测(Dual-NTP),将每个时间步建模为一对独立的人声与伴奏token,解决了混合信号带来的信息干扰问题;2)结构化渐进条件(SPC),利用歌曲固有的段落结构(如主歌、副歌),通过交错安排歌词与音频token,实现了分钟级别的上下文与歌词跟随;3)重新设计的音乐上下文学习(ICL),通过延迟引入参考音频数据,实现了风格克隆、双向内容创作且避免了捷径学习。与已有方法相比,YuE是首个在开源条件下,能生成长达5分钟、具有连贯结构且歌词对齐的歌曲的模型。实验表明,在人类评估中,YuE在整体偏好和音乐性上与Tiangong和Udio等商业系统持平,并超越了Hailuo,但略逊于Suno V4。其生成的歌曲时长和人声音域范围也显著领先于多数对比系统。在自动指标上,其KL散度(0.372)和CLaMP 3分数(0.240)表现优异。该工作的实际意义在于,极大地降低了高质量AI音乐创作的门槛,推动了该领域的开源生态发展。主要局限性在于,与最强闭源系统相比,在声音的精致度和艺术性上仍有提升空间,且训练超大模型需要巨大的计算资源。
🏗️ 模型架构
YuE是一个基于自回归语言模型(LLM)的两阶段框架,旨在将歌词转化为完整的歌曲波形。

整体流程与组件:
- 音频分词器(Audio Tokenizer):使用X-Codec,将原始音频波形转换为离散的token序列。它采用语义-声学融合策略,在一个统一的codebook中同时包含语义信息和声学细节。本文主要使用其8层RVQ中的第一层(codebook-0)作为语义丰富的代表。模型还配备了一个轻量级的上采样器(基于Vocos),将16kHz的重建音频提升至44.1kHz。
- 文本分词器(Text Tokenizer):复用LLaMA分词器,对指令、风格、歌词和结构标签进行编码。
- 第一阶段语言模型(Stage-1 LM):这是生成流程的核心。基于LLaMA2架构(7B参数),它以自回归方式预测文本token和音频token(codebook-0)。其创新点在于双轨分离预测(Dual-NTP),即对每个时间帧
t,模型依次预测一对token:v_t(人声token)和a_t(伴奏token),序列形式为(v_1, a_1, v_2, a_2, ..., v_T, a_T)。概率分解为:P(v_t, a_t | v_{<t}, a_{<t}) = P(v_t | v_{<t}, a_{<t}) * P(a_t | v_{≤t}, a_{<t})。这使模型能显式解耦人声与伴奏的建模。 为了处理长上下文,Stage-1 LM采用了结构化渐进条件(SPC)。它利用自动音乐结构分析工具将歌曲分段,然后在输入序列中,将结构标签(如[verse],[chorus])和对应的歌词与生成的音频token交错排列(如图2中“Lyrics2Song”所示)。这相当于为模型提供了分段的“进度条”,使其能在长序列中保持歌词对齐。 - 第二阶段语言模型(Stage-2 LM):这是一个较小的模型(2B参数),负责残差建模。它以Stage-1生成的codebook-0 token为条件,自回归地预测剩余的codebook 1-7,从而细化音频细节,恢复高保真度。训练时,它先“看到”整个codebook-0序列,然后逐帧预测所有8个codebook的token。推理时,codebook-0被固定为Stage-1的输出,仅生成残差部分。
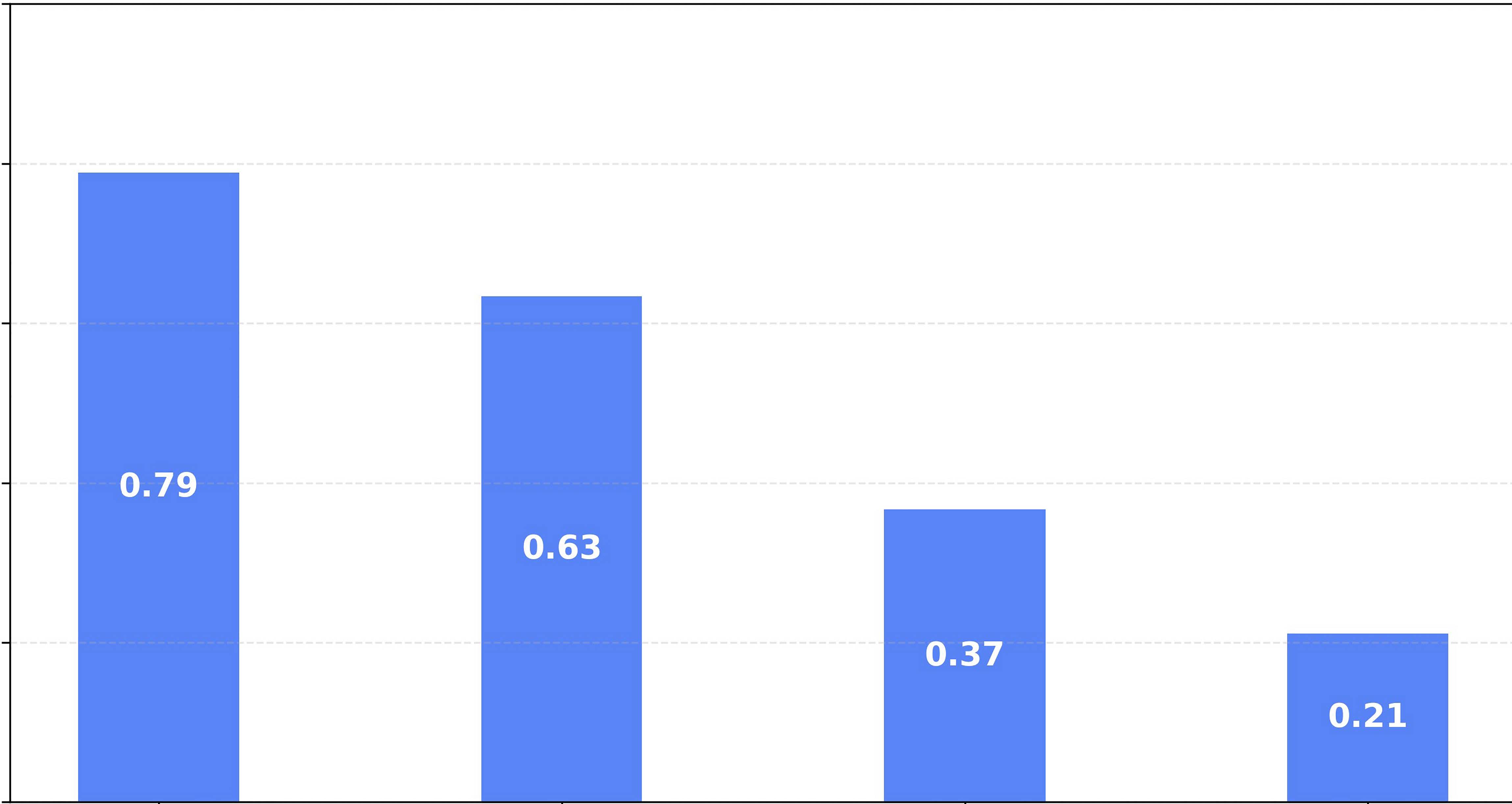 图2详细展示了Stage-1 LM的输入序列构成。蓝色为人声token,橙色为伴奏token,灰色为残差token(用于Stage-2)。虚线表示Dual-NTP的双token预测。文本与音频token按结构交错(SPC)。绿色token代表用于ICL的参考音频片段。
图2详细展示了Stage-1 LM的输入序列构成。蓝色为人声token,橙色为伴奏token,灰色为残差token(用于Stage-2)。虚线表示Dual-NTP的双token预测。文本与音频token按结构交错(SPC)。绿色token代表用于ICL的参考音频片段。
💡 核心创新点
- 双轨分离预测(Dual-NTP):针对歌词到歌曲任务中人声与伴奏混合导致的信息混乱问题,该方法在序列层面显式地将两者解耦。相比于将混合信号压缩为单个token的标准NTP方法,Dual-NTP能更好地保留人声信息(尤其在伴奏强烈的音乐如金属乐中),并实现联合建模与快速收敛(如图7所示,训练损失显著更低)。
- 结构化渐进条件(SPC):针对长上下文建模中文本条件随音频长度增长而失效的挑战,该方法巧妙利用了音乐的固有结构先验。通过将歌词和结构标签分段嵌入序列,为模型提供了清晰的“导航”,使其能在超过150秒的生成过程中维持稳定的歌词跟随能力(如图8所示,WER随时间增长控制得更好)。
- 重新设计的音乐上下文学习(ICL):针对传统语音ICL(续写式)在音乐任务中的局限(需参考文本、单向、易抄袭),新设计将随机采样的一段参考音频token直接前置到SPC数据前。关键创新在于延迟激活策略:在训练后期才引入少量ICL数据,避免了模型过早学习“复制粘贴”的捷径,从而实现了受控的风格迁移和内容创作(如改变语言或演唱风格)。
🔬 细节详述
- 训练数据:
- 规模:使用了约70k小时的语音数据和650k小时的创意共享许可音乐数据(从网络挖掘)。
- 预处理:歌词通过Google搜索程序化获取。数据通过字符串匹配过滤以排除明确版权限制内容。
- 混合比例:预训练阶段,条件:无条件 = 3:1,音乐:语音 = 10:1。退火阶段仅使用SPC和ICL数据,SPC:ICL = 2:1。
- 损失函数:标准自回归交叉熵损失。Stage-1预测token序列的下一token概率;Stage-2预测codebook-0到7的联合概率,但推理时固定codebook-0。
- 训练策略:
- Stage-1:0.5B模型在100B token上训练;2B模型在500B token上训练;7B模型在1.75T token(16K上下文)上训练,随后进行40B token的退火。
- Stage-2:使用2T token,上下文长度8K。
- 优化器:全局batch size为768。学习率从3e-4线性预热,退火阶段降至3e-5。
- 关键超参数:Stage-1 LM为7B参数(LLaMA2架构);Stage-2 LM为2B参数;音频分词器为X-Codec(8层RVQ,码本大小1024);生成歌曲最长可达5分钟。
- 训练硬件:论文未具体说明GPU型号和数量。
- 推理细节:采用采样和Classifier-Free Guidance (CFG) 以提升生成质量。在测试时,常用一段歌曲的副歌作为ICL的参考音频前缀。
📊 实验结果
主要对比实验(人类评估): 图3展示了YuE与四个闭源商业系统(Suno V4, Udio, Tiangong, Hailuo)的A/B测试结果。
- 整体偏好(左图):YuE在与Hailuo的对比中占据明显优势(64% vs 36%),与Tiangong(47% vs 53%)和Udio(47% vs 53%)基本持平,但落后于Suno V4(29% vs 71%)。
- 音乐性胜率(右图):模式类似,YuE在音乐性上与Tiangong和Udio平衡(约49%-50%),大幅领先Hailuo,但低于Suno V4(20% vs 30%)。
其他关键定量结果:
- 人声音域(图4):YuE生成歌曲的人声音域中位数约27个半音,与Suno V4接近,显著高于Hailuo和Tiangong(约20个半音),表明其生成更富表现力的歌声。
- 生成时长(图5):YuE生成的歌曲时长范围最广,中位数最高,能稳定生成超过100秒的音频,证明其在长时序建模上的优势。
- 模型自动评估(表1):
| Metric | Hailuo | SunoV4 | Tiangong | Udio | YuE |
|---|---|---|---|---|---|
| KL↓ | 0.756 | 0.620 | 0.708 | 0.503 | 0.372 |
| FAD↓ | 2.080 | 1.544 | 2.547 | 1.222 | 1.624 |
| CE↑ | 7.350 | 7.474 | 7.421 | 7.112 | 7.115 |
| CU↑ | 7.737 | 7.813 | 7.766 | 7.520 | 7.543 |
| CLAP↑ | 0.265 | 0.265 | 0.244 | 0.310 | 0.118 |
| CLaMP 3↑ | 0.106 | 0.160 | 0.114 | 0.156 | 0.240 |
YuE在分布匹配指标KL上表现最佳,在FAD上优于Hailuo和Tiangong。在语义对齐上,CLaMP 3分数最高,但CLAP分数较低。
消融实验与分析:
- Dual-NTP有效性(图7):在相同预算下,Dual-NTP的训练损失比标准NTP低约0.4,收敛更快。
- SPC有效性(图8):在150秒的生成长度上,SPC方法的字错误率(WER)显著低于Vanilla(前缀条件)、Curriculum(课程学习)和ABF(调整RoPE基频)等方法。同时,将模型从0.5B扩展到7B,WER从约70%降至约20%。
- 测试时技巧(图9b):ICL+CFG的组合在音乐性上获得最高的人类偏好胜率(0.79),远超仅使用SPC的基线(0.21)。
 图8清晰地显示了SPC方法和模型缩放在维持长时歌词跟随能力上的巨大优势。
图8清晰地显示了SPC方法和模型缩放在维持长时歌词跟随能力上的巨大优势。
⚖️ 评分理由
- 学术质量:6.0/7:论文提出了针对长音乐生成的多项关键且有效的技术创新(Dual-NTP, SPC, ICL),技术路线正确且有充分的消融实验支撑。与商业系统的广泛对比增强了结论的说服力。然而,与Suno V4等顶尖系统在主观音乐品质上的差距,以及部分自动指标(如CLAP)与人类感知的脱节,显示了技术成熟度仍有提升空间。
- 选题价值:1.5/2:生成长篇、连贯、可控制的音乐是AI创作领域的“圣杯”之一,该问题定义清晰、挑战巨大且应用前景广阔。YuE作为该方向的首个高质��开源解决方案,影响力显著。
- 开源与复现加成:1.0/1:论文提供了代码库、预训练模型、训练数据说明、详细的架构与训练超参数,并附有在线演示。开源信息极为全面,是复现和后续研究的理想基础,加成满分。