📄 VowelPrompt: Hearing Speech Emotions from Text via Vowel-level Prosodic Augmentation
#语音情感识别 #大语言模型 #数据增强 #多语言 #强化学习
✅ 7.5/10 | 前25% | #语音情感识别 | #数据增强 | #大语言模型 #多语言
学术质量 7.0/7 | 选题价值 0.3/2 | 复现加成 0.2 | 置信度 高
👥 作者与机构
- 第一作者:Yancheng Wang(Arizona State University, Meta Superintelligence Labs)
- 通讯作者:未说明
- 作者列表:Yancheng Wang(Arizona State University, Meta Superintelligence Labs), Osama Hanna(Meta Superintelligence Labs), Ruiming Xie(Meta Superintelligence Labs), Xianfeng Rui(Meta Superintelligence Labs), Maohao Shen(Massachusetts Institute of Technology, Meta Superintelligence Labs), Xuedong Zhang(Meta Superintelligence Labs), Christian Fuegen(Meta Superintelligence Labs), Jilong Wu(Meta Superintelligence Labs), Debjyoti Paul(Meta Superintelligence Labs), Arthur Guo(Meta Superintelligence Labs), Zhihong Lei(Meta Superintelligence Labs), Ozlem Kalinli(Meta Superintelligence Labs), Qing He(Meta Superintelligence Labs), Yingzhen Yang(Arizona State University)
💡 毒舌点评
亮点是提出了一个新颖且可解释的语音情感识别框架,将语言学知识(元音是韵律的主要载体)与大语言模型的推理能力相结合,实验全面覆盖零样本、微调、跨域和多语言场景。短板是系统依赖外部强制对齐工具(如MFA)的准确性和可用性,这增加了实际部署的复杂度,且论文未讨论在噪声或说话人识别失败时的鲁棒性。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:使用了公开的数据集(IEMOCAP, MELD, CaFE, EmoDB, ASVP-ESD),并说明了来源。
- Demo:未提及。
- 复现材料:论文详细描述了方法流程、实验设置、数据集统计、基线方法及超参数K的选择(表A.4),并提供了大量消融实验和附录分析,为复现提供了重要参考。但未提供训练脚本、配置文件或预训练检查点。
- 论文中引用的开源项目:提到了使用Montreal Forced Aligner (MFA) 进行强制对齐,使用Praat风格算法进行特征提取,以及基于LLaMA、Qwen2等开源大模型进行实验。
- 论文中未提及开源计划。
📌 核心摘要
- 问题:传统基于文本的大语言模型(LLM)情感识别方法忽视了细粒度的韵律信息(如音高、强度、时长),而基于音频的方法虽有效但特征不透明、难以解释,且在仅文本场景下无法应用。
- 方法核心:提出VowelPrompt框架。基于语音学证据,认为元音是情感韵律的主要载体。该方法通过强制对齐提取时间对齐的元音片段,提取并归一化其音高、强度、时长等低级描述符(LLDs),将其离散化并转换为自然语言描述(如“高音高,升调,响亮,延长”),然后将这些描述与文本转录一起作为提示输入LLM。
- 创新点:1) 使用细粒度、可解释的元音级韵律描述符作为LLM的输入,而非不透明的声学嵌入或粗略的句子级描述;2) 设计了监督微调(SFT)结合基于可验证奖励的强化学习(RLVR,采用GRPO算法)的两阶段训练流程,以提升LLM的推理质量和输出结构遵循性。
- 实验结果:在五个基准数据集(IEMOCAP, MELD, CaFE, EmoDB, ASVP-ESD)上进行了广泛评估。零样本设置下,在IEMOCAP和MELD上,VowelPrompt(GPT-4o)相比纯文本基线最高提升7.80% UACC和7.11% WF1,相比句子级描述基线(SpeechCueLLM)也有稳定提升。微调与RLVR设置下,使用LLaMA-3-8B-Instruct,在IEMOCAP上达到73.46% WF1(SFT),超过基线3.14%。跨域设置下,在MELD→IEMOCAP任务中,SFT & GRPO后WF1为51.75%,比SpeechCueLLM高6.96%。多语言设置下,在法语CaFE和德语EmoDB的零样本测试中,WF1分别达到51.42%和69.85%,均为最佳。
- 实际意义:该框架为语音情感识别提供了一个高精度、可解释且轻量化的解决方案。它使文本LLM能够感知语音中的韵律线索,无需在推理时访问原始音频,有利于隐私保护和部署。生成的解释性推理过程将声学模式与情感标签显式关联,增强了模型的可信度。
- 主要局限性:系统性能依赖于上游强制对齐工具对元音边界的准确识别;论文未深入探讨在非理想语音(如噪声、多人重叠)或低资源语言(无现成对齐工具)下的表现;生成的韵律描述符是静态离散化的,可能损失动态信息。
🏗️ 模型架构
VowelPrompt是一个端到端框架,其核心思想是将声学特征转化为文本,以便与LLM集成。架构流程如下:
- 输入:一段语音波形及其文本转录(可包含对话上下文)。
- 元音级声学特征提取:
- 强制对齐与元音选择:使用音素级强制对齐工具(如Montreal Forced Aligner, MFA)获得每个音素的时间边界。根据国际音标(IPA)预定义的元音音素表(包括单元音和双元音),筛选并提取出元音片段。
- 低级描述符(LLDs)提取:对每个元音片段,计算6个可解释的特征:平均音高(F0)、音高斜率、音高变化、平均强度、强度变化、持续时间。这些特征通过Praat风格的算法提取,并进行两阶段归一化:先说话人级z归一化,再元音类型归一化,以消除个体和音素本身的差异。
- 离散化与自然语言转换:将归一化后的连续特征值通过基于分位数的分箱(K=5)离散化为有序类别(如“very low”, “low”, “moderate”, “high”, “very high”),然后确定性地映射为简洁的文本描述。
- 提示构建:将生成的元音级韵律描述符与原始文本转录(及对话上下文)按照固定模板组合成最终提示。例如,为目标语句中的每个元音附加如“the vowel /ɪ/ in ‘it’s’ has medium pitch slope, high pitch with very low variation…”的描述。
- LLM推理与适应:
- 监督微调(SFT):使用一个小规模的数据集,将上述增强提示与由高容量LLM(如GPT-4o)生成的包含推理链(
...</think>)和情感标签(<answer>...</answer>)的黄金样本作为监督信号,对LLM进行微调,使其适应此任务。 - 强化学习与可验证奖励(RLVR):在SFT基础上,使用GRPO算法进行进一步微调。奖励函数是组合式的:准确性奖励(预测是否匹配真实标签)和格式奖励(输出是否包含有效的推理和答案标签)。通过KL散度惩罚使策略保持接近SFT参考模型。
- 监督微调(SFT):使用一个小规模的数据集,将上述增强提示与由高容量LLM(如GPT-4o)生成的包含推理链(
- 输出:LLM生成一个结构化的输出,包含对给定语音文本和韵律线索的推理过程,并给出最终的情感类别预测。
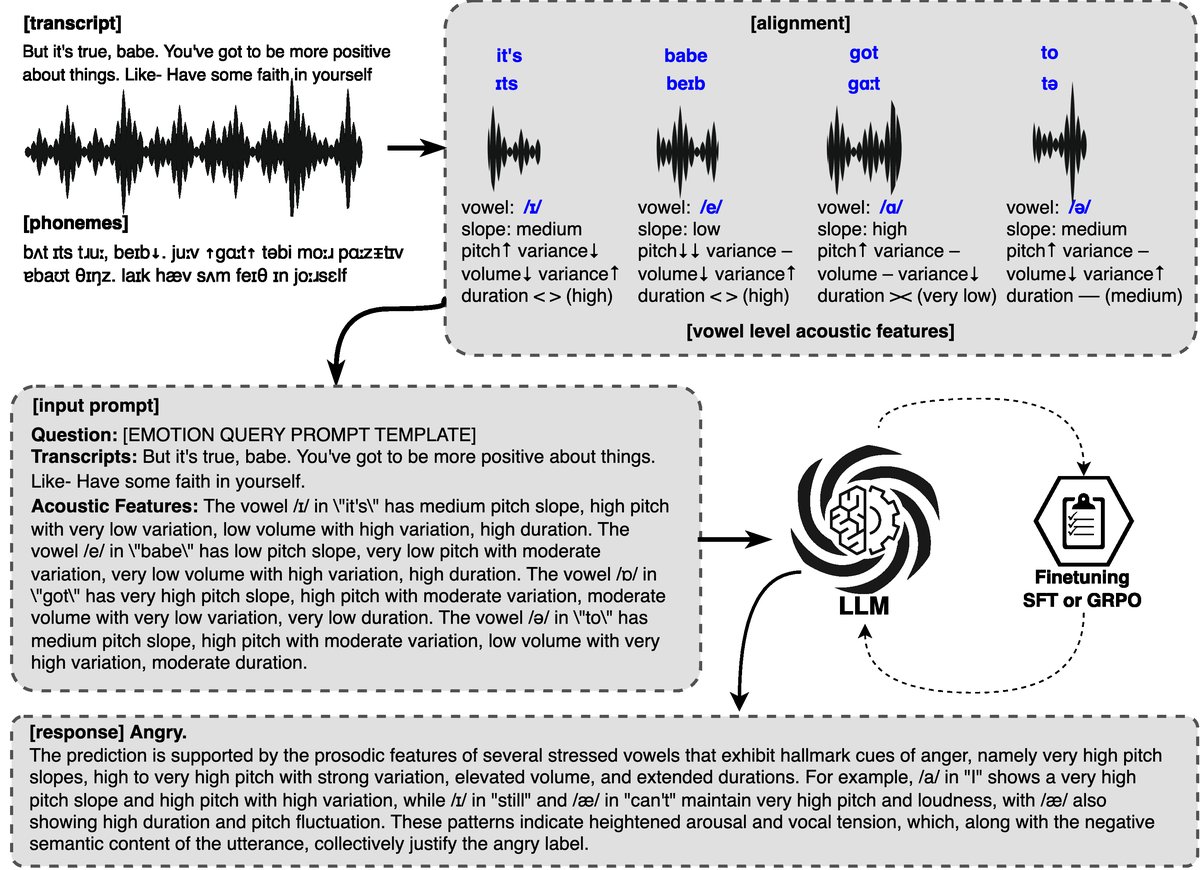 图1描述:该图展示了VowelPrompt的工作流程。上方是对话转录和针对目标话语中特定元音提取的声学特征描述。下方显示了模型的输出,包括推理过程(``标签内)和最终预测(
图1描述:该图展示了VowelPrompt的工作流程。上方是对话转录和针对目标话语中特定元音提取的声学特征描述。下方显示了模型的输出,包括推理过程(``标签内)和最终预测(<answer>标签内)。这直观地体现了如何将细粒度的元音韵律信息整合到文本中,并引导LLM进行情感推理。
💡 核心创新点
元音中心化的可解释韵律增强:
- 局限:以往基于文本提示的方法通常使用粗糙的句子级韵律描述(如“大声说,语调上升”),信息粒度粗,可能模糊关键线索;而基于音频的嵌入方法特征不透明。
- 创新:基于“元音是情感韵律主要载体”的语言学共识,系统性地从时间对齐的元音中提取细粒度、可解释的声学特征,并将其转化为自然语言。
- 收益:为LLM提供了比句子级描述更丰富、比原始音频嵌入更透明的中间表示,使预测更具可解释性。
两阶段LLM适应流水线(SFT + GRPO):
- 局限:直接将增强提示输入通用LLM效果有限;仅使用SFT可能产生不符合格式或推理不佳的输出。
- 创新:设计了一个两阶段训练方案:先用少量带推理链的黄金数据进行SFT冷启动,再用RLVR(通过GRPO实现)优化输出格式的遵循度和推理质量,同时通过KL约束防止模型偏离。
- 收益:显著提升了模型在任务准确性、输出结构稳定性和跨领域泛化方面的表现。
基于IPA的多语言扩展框架:
- 局限:现有情感识别系统多为单语言,跨语言泛化能力差。
- 创新:采用国际音标(IPA)作为跨语言的统一音素表示,使得元音特征提取流程可以语言无关地应用于英语、德语、法语等。并通过语言内归一化控制跨语言差异。
- 收益:使框架能够无缝扩展至多语言情感识别任务,实验证明其在法语、德语数据集上均有效。
🔬 细节详述
- 训练数据:
- 数据集:IEMOCAP(英语,5类,5531话语),MELD(英语,7类,13706话语),CaFE(法语,7类,936话语),EmoDB(德国,7类,535话语),ASVP-ESD(混合语言,12类,13964话语)。具体统计见论文表2。
- 预处理:对每个数据集进行音素级强制对齐,筛选元音,提取LLDs,进行说话人和元音类型归一化,离散化为自然语言。
- 数据增强:VowelPrompt本身即是一种数据/输入增强方法。SFT阶段使用了GPT-4o生成的推理链作为监督信号。论文未说明是否使用了其他数据增强技术。
- 损失函数:
- SFT阶段:标准的自回归交叉熵损失,最大化参考推理和正确标签的生成概率。
- RLVR阶段:使用GRPO优化策略,目标是最大化奖励(准确性和格式奖励)期望,同时通过KL散度约束保持与SFT参考模型的接近。论文公式(1)定义了组合奖励
R(o, y) = Racc(o, y) + Rformat(o)。
- 训练策略:
- SFT:使用一小部分训练数据(论文未说明具体比例),配对GPT-4o生成的黄金推理链进行微调。
- RLVR(GRPO):基于SFT后的模型,使用GRPO进行强化学习。对每个输入,生成一组候选输出,根据奖励计算策略梯度进行更新。添加了KL惩罚项以稳定训练。
- 实现细节:使用LoRA进行参数高效微调。训练集、验证集、测试集使用各数据集的官方划分。
- 关键超参数:
- 离散化分箱数 K=5:在零样本和SFT实验中表现最佳(见论文表A.4)。
- KL权重:在0.1到1.0之间变化,论文表A.19显示模型性能对此参数不敏感。
- 其他:论文未详细说明学习率、批大小、训练轮数等具体数值。
- 训练硬件:论文中未说明。
- 推理细节:
- 零样本/少样本:直接使用提示工程,将增强后的输入送入LLM(如GPT-4o, LLaMA-3-8B-Instruct),解码策略未说明。
- 微调模型推理:采用``和
<answer>标签约束输出结构。解码策略未具体说明。
- 正则化或稳定训练技巧:在GRPO中,使用KL散度惩罚项约束当前策略与SFT参考策略的距离,是主要的稳定训练技巧。
📊 实验结果
论文实验全面,覆盖了多种设置。关键结果如下:
表3:零样本情绪识别性能(UACC / WF1 %)
| 方法 | 输入 | LLM | IEMOCAP | MELD |
|---|---|---|---|---|
| Zero-Shot Baseline | 转录 | GPT-4o | 43.38 / 41.03 | 61.15 / 60.92 |
| SpeechCueLLM | 转录 | GPT-4o | 49.97 / 48.54 | 52.44 / 53.59 |
| VowelPrompt | 转录 | GPT-4o | 51.18 / 50.15 | 63.61 / 61.76 |
| Zero-Shot Baseline | 转录&上下文 | GPT-4o | 55.51 / 53.63 | 62.76 / 63.57 |
| SpeechCueLLM | 转录&上下文 | GPT-4o | 60.07 / 58.52 | 56.74 / 57.90 |
| VowelPrompt | 转录&上下文 | GPT-4o | 62.26 / 60.74 | 64.34 / 64.17 |
| 结论:VowelPrompt在GPT-4o和LLaMA-3-8B-Instruct上,在两种输入配置下均一致优于基线和句子级描述方法。 |
表4:微调设置下的加权F1 (%)
| 方法 | LLaMA-3-8B-Instruct | LLaMA-4-Scout-17B-16E-Instruct | ||
|---|---|---|---|---|
| SFT | SFT & GRPO | SFT | SFT & GRPO | |
| IEMOCAP / MELD | IEMOCAP / MELD | IEMOCAP / MELD | IEMOCAP / MELD | |
| Baseline | 70.32 / 67.44 | – | 70.82 / 67.90 | – |
| SpeechCueLLM | 71.74 / 67.07 | 71.55 / 67.10 | 72.02 / 68.02 | 72.18 / 67.96 |
| VowelPrompt | 73.46 / 69.61 | 73.02 / 68.98 | 73.85 / 70.12 | 74.02 / 69.79 |
| 结论:VowelPrompt在所有微调设置下均取得最佳性能,验证了细粒度韵律增强的有效性。 |
表5:跨域情绪识别(源域训练,目标域测试,WF1 %)
| 方法 | IEMOCAP → MELD | MELD → IEMOCAP | ||||
|---|---|---|---|---|---|---|
| 零样本 | SFT | SFT & GRPO | 零样本 | SFT | SFT & GRPO | |
| SALMONN | – | 40.25 | 51.48 | – | 23.65 | 40.85 |
| SpeechCueLLM | 53.85 | 42.36 | 55.16 | 42.59 | 25.10 | 44.79 |
| VowelPrompt | 54.10 | 46.26 | 60.28 | 46.26 | 28.71 | 51.75 |
| 结论:VowelPrompt在跨域设置下优势明显,特别是在结合GRPO后,表明其学习的韵律特征更具领域不变性。 |
表6与表7:多语言零样本与微调结果(WF1 %)
| 方法 | CaFE (法) | EmoDB (德) |
|---|---|---|
| Transcript Only | 45.10 | 64.86 |
| SpeechCueLLM | 49.16 | 67.32 |
| VowelPrompt | 51.42 | 69.85 |
| 方法 (ASVP-ESD, Qwen2) | SFT | SFT & GRPO |
|---|---|---|
| SpeechCueLLM | 67.85 | 68.12 |
| VowelPrompt | 70.54 | 71.36 |
| 结论:在法语、德语和混合语言数据集上,VowelPrompt均表现出色,证明了其多语言能力。 |
消融实验(论文表A.8, A.12):
- 移除任何单一声学特征(如音高、强度)都会导致性能轻微下降,说明所有特征都有贡献。
- 相比直接使用元音特征训练的MLP/XGBoost/Transformer分类器(IEMOCAP最高48.5%),VowelPrompt(73.4%)大幅提升,表明LLM整合语言知识的必要性。
- 辅音级特征效果不如元音级特征,且与元音特征结合在部分语言(德语)上有小幅提升。
⚖️ 评分理由
- 学术质量:7.0/7 - 论文在语音情感���别领域提出了一个新颖、原理清晰且可解释的框架。创新性地结合了语言学知识、细粒度声学特征和LLM的推理能力。技术路线正确,实验设计全面且深入,包括零样本、微调、跨域、多语言、消融、鲁棒性(对齐扰动、语音速率)等,并提供了充分的对比和数据,证据可信。扣分点在于:部分训练细节(如超参数、硬件)未完全公开,可能影响复现;系统依赖外部强制对齐工具,这是一个潜在的脆弱点。
- 选题价值:0.3/2 - 研究方向具有前沿性(LLM在语音情感识别中的应用),解决了现有方法可解释性差或信息粒度粗的痛点,具有明确的应用价值(智能人机交互、情感计算)。但与更广泛或多模态的情感识别相比,其应用场景相对垂直和具体。
- 开源与复现加成:0.2/1 - 论文提供了非常详尽的实验设置、数据集描述、对比方法和消融研究,复现路径清晰。然而,论文中未提供代码、模型权重或具体的超参数配置表(如学习率、批次大小),这增加了完全复现的难度。因此给予小幅加分,而非满分。