📄 VibeVoice: Expressive Podcast Generation with Next-Token Diffusion
#语音合成 #语音大模型 #扩散模型 #多说话人
🔥 8.5/10 | 前25% | #语音合成 | #扩散模型 | #语音大模型 #多说话人
学术质量 5.5/7 | 选题价值 2.0/2 | 复现加成 0.8 | 置信度 高
👥 作者与机构
- 第一作者:Zhiliang Peng(Microsoft Research)
- 通讯作者:Furu Wei(Microsoft Research)
- 作者列表:Zhiliang Peng(Microsoft Research)、Jianwei Yu(Microsoft Research)、Wenhui Wang(Microsoft Research)、Yaoyao Chang(Microsoft Research)、Yutao Sun(Microsoft Research)、Li Dong(Microsoft Research)、Yi Zhu(Microsoft Research)、Weijiang Xu(Microsoft Research)、Hangbo Bao(Microsoft Research)、Zehua Wang(Microsoft Research)、Shaohan Huang(Microsoft Research)、Yan Xia(Microsoft Research)、Furu Wei(Microsoft Research)
💡 毒舌点评
这篇论文通过超低帧率的连续语音分词器和下一个token扩散框架,为“像人一样聊一小时”这个语音生成领域的终极难题提供了一个工程上非常扎实且效果显著的方案,尤其在长篇、多人对话生成上取得了SOTA。但论文的“多说话人”实验部分,对于超过4人或存在激烈抢话、声音重叠等极端复杂对话场景的鲁棒性验证略显不足,现实世界的播客可能比测试集更“混乱”。
🔗 开源详情
- 代码:提供代码仓库链接
https://github.com/microsoft/VibeVoice。 - 模型权重:提及检查点可用(checkpoint are available),但未明确是否全部公开。代码仓库链接暗示可能包含预训练权重。
- 数据集:创建了VIBEVOICE-Eval评测集(108个样本,约28.9小时),并说明了构建方法。论文未提及是否公开该评测集。
- Demo:论文中未提及在线演示链接。
- 复现材料:提供了详细的训练超参数(表9)、分词器和模型架构细节、数据处理流程描述(附录A)、以及使用的主要开源工具列表(表4)。复现信息非常充分。
- 引用的开源项目:Silero VAD, Whisper-large-v3-turbo, Nemo ASR, WeSpeaker (vblinkp模型), 以及用于评估的WER和SIM-O工具包。
📌 核心摘要
本文旨在解决传统文本转语音(TTS)系统在生成长篇幅、多说话人、自然对话式音频(如播客)时面临的可扩展性、说话人一致性以及自然轮替等挑战。核心方法VibeVoice提出了一个新颖的框架,其技术核心在于两个方面:1)设计了工作在7.5Hz超低帧率下的连续声学与语义分词器,以高效且高保真地压缩和表示语音;2)采用了基于下一个token扩散的端到端大语言模型(LLM)架构,结合混合语音表示(声学+语义)进行生成。与已有方法相比,该框架新在能以零样本方式端到端生成长达90分钟、多达4个说话人的对话,显著超越了以往模型在生成时长和说话人数量上的限制,并能自然地生成呼吸、咂嘴等副语言特征。主要实验结果显示,VibeVoice-7B在主观评测(真实感、丰富度、偏好度均最高)和客观评测(WER-W 1.29, SIM-O 0.692)上均优于包括Google Gemini 2.5 Pro TTS和ElevenLabs v3 alpha在内的多个强基线模型。其实际意义在于为自动化、高质量的播客内容创作提供了可行的技术路径。主要局限性可能在于对更极端、更混乱的对话场景(如多人同时发言)的处理能力未被验证,且模型规模较大(7B参数)。
🏗️ 模型架构
VibeVoice是一个端到端的、基于大语言模型(LLM)和扩散模型的语音生成系统,旨在从文本脚本和声音提示生成长篇多说话人对话。其整体流程如图1所示。
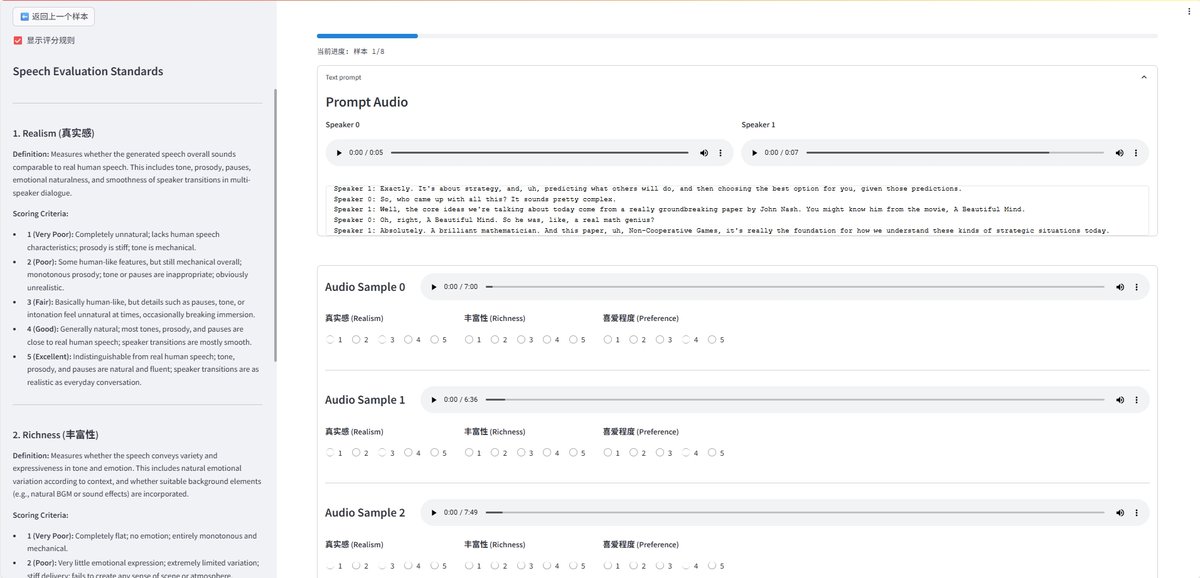 图1:VibeVoice可扩展且富有表现力的播客生成流程。用户提供声音提示和文本脚本作为初始输入。VibeVoice处理混合上下文特征,其隐状态条件化一个用于预测声学VAE特征的token级扩散头(D),随后由声学解码器(A)恢复波形。
图1:VibeVoice可扩展且富有表现力的播客生成流程。用户提供声音提示和文本脚本作为初始输入。VibeVoice处理混合上下文特征,其隐状态条件化一个用于预测声学VAE特征的token级扩散头(D),随后由声学解码器(A)恢复波形。
核心组件及数据流:
- 连续语音分词器(Continuous Speech Tokenizers):作为输入特征提取器,它们是整个系统高效处理长序列的基础。
- 声学分词器(Acoustic Tokenizer):基于σ-VAE架构,负责将原始音频压缩为连续的声学隐向量(latent vector)。它以7.5Hz的超低帧率工作,这意味着每秒音频仅生成7.5个token,极大提升了长序列处理的效率。其结构为编码器-解码器对称设计,编码器使用7级改进的Transformer块(采用1D深度可分离因果卷积代替自注意力)实现3200倍下采样。训练目标是重建音频波形(如图2上半部分)。
- 语义分词器(Semantic Tokenizer):架构与声学分词器的编码器镜像,但去除了VAE组件。其训练目标是自动语音识别(ASR),通过Transformer解码层预测文本转录,从而提取与语言内容对齐的确定性语义特征(如图2下半部分)。训练后,解码器被丢弃。
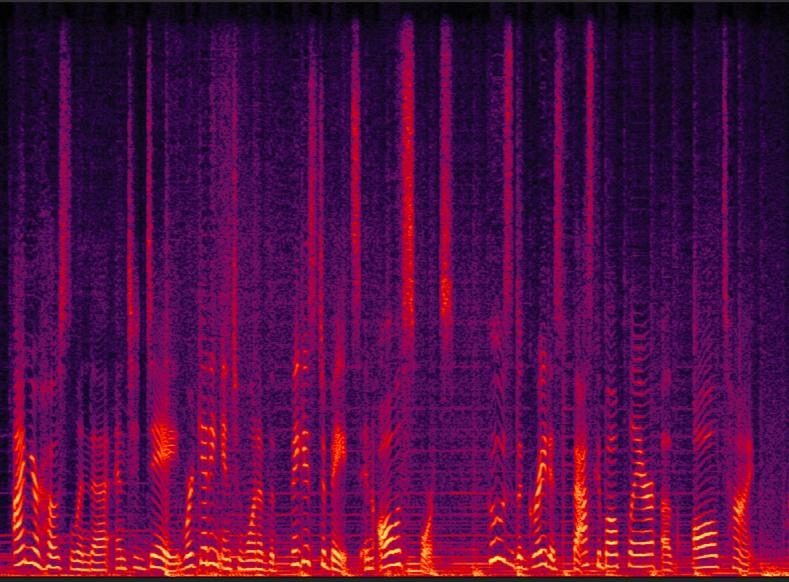 图2:声学分词器(上)通过σ-VAE重建波形,语义分词器(下)使用ASR作为代理任务。
图2:声学分词器(上)通过σ-VAE重建波形,语义分词器(下)使用ASR作为代理任务。
输入表示(Input Representation):对于每个说话人$k$,其声音提示$v_k$被声学分词器编码为序列$Z_{a,k}$。文本脚本$W_k$被嵌入为序列$E_k$。最终的输入序列$X$由说话人标识符、声学提示特征、文本脚本嵌入交错拼接而成,并以一个起始语音token
<S>结束。语音生成(Speech Generation):在每个生成步骤$i$,LLM基于当前的混合语音表示$z_{p,i}$(由上一时刻的声学特征$z_{a,i}$和语义特征$SemanticEnc(y_i)$加权融合而成,如公式3所示)预测下一个声学VAE特征$z_{a,i+1}$。公式1和2描述了该自回归过程。这种使用历史混合表示的自回归方式使其天然支持流式生成。
基于扩散的声学VAE生成(Diffusion-based Acoustic Latent VAE Generation):这是生成高质量声学token的关键模块。
- 训练:一个轻量级的扩散头(Diffusion Head)被训练来预测被噪声污染的声学VAE特征$z_{a,i}(t)$中注入的噪声$\epsilon$,其条件是来自LLM的当前隐状态$h_i$。训练目标是最小化噪声预测的L2损失(公式5)。
- 推理:采用无分类器引导(Classifier-Free Guidance, CFG)进行迭代去噪。从随机噪声开始,经过T步(如10步)去噪,得到干净的声学特征。最终生成的语音是各个步骤生成波形片段的拼接。公式6展示了使用CFG的噪声估计过程。
关键设计选择:解耦的声学与语义分词器确保了音频保真度和语义内容的准确传递;混合表示稳定了长语音的生成过程;下一个token扩散框架结合了LLM的序列建模能力和扩散模型的高保真生成能力。
💡 核心创新点
超低帧率连续语音分词器:
- 是什么:声学和语义分词器均工作在7.5Hz的超低帧率。
- 之前局限:现有分词器帧率较高(如50-75 Hz),处理长序列时计算负担重。
- 如何起作用:通过激进的压缩(3200倍下采样)将音频表示为极少的连续token序列,同时借助σ-VAE和专门的ASR训练目标保持高重建保真度和语义内容。
- 收益:极大提升了处理90分钟长音频序列的可行性(计算效率),并在重建质量上(PESQ, UTMOS)达到或超过帧率高得多的模型(如WavTokenizer, X-codec2)。
端到端的多说话人长篇对话生成框架:
- 是什么:一个集成了LLM和扩散头的统一模型,可直接从文本和声音提示生成长达90分钟、最多4个说话人的连贯对话。
- 之前局限:先前系统要么只能生成短句再拼接(导致不自然),要么在说话人数量(通常≤2)和时长(通常<10分钟)上受限,且生成不稳定(如MoonCast在长音频/多人时易崩溃)。
- 如何起作用:利用LLM强大的上下文建模能力处理长对话流,通过混合语音表示和扩散头生成高保真音频,并利用声音提示实现零样本说话人克隆。
- 收益:在VIBEVOICE-Eval数据集上,在长音频(12-30分钟)和多说话人(3-4人)设置下,VibeVoice展示了卓越的稳定性和一致性(WER-W 1.24, SIM-O 0.75),显著优于MoonCast等基线。
用于真实对话建模的数据处理流程:
- 是什么:一个自动标注流水线,能为大规模原始播客数据生成伪转录和说话人轮次标签。
- 之前局限:缺乏适用于长篇多说话人音频的标注数据。
- 如何起作用:流程包括语音活动检测分段、Whisper转录与基于标点的重分割、基于说话人嵌入和聚类的语音分离,以及质量过滤。
- 收益:为训练提供了包含真实语调、轮次和副语言特征的丰富数据,使模型能学习到自然的对话动态。
🔬 细节详述
- 训练数据:来自内部收集的大规模播客音频数据,通过上述数据处理流程进行伪标注。训练数据总量约为800亿个token。未提及具体音频文件数量或小时数。
- 损失函数:
- 声学分词器:采用DAC方法的判别器和损失设计进行重建损失和对抗损失训练。
- 语义分词器:使用交叉熵损失进行ASR任务训练。
- VibeVoice主模型:
- 扩散头:使用L2损失最小化噪声预测误差(公式5)。
- LLM部分:论文未明确说明其训练损失,推测为预测下一个token的标准自回归损失,可能还包括判断语音结束的token预测。
- 训练策略:
- 课程学习:对LLM输入序列长度采用渐进式增长策略,从4,096 tokens逐步增加到65,536 tokens(1.5B模型),共110k步。7B模型因资源限制跳过了最后阶段。
- 优化器与调度:使用Adam优化器(β1=0.9, β2=0.95)。采用余弦学习率调度,峰值学习率为1e-4,预热步数为500。梯度范数裁剪为2。
- 冻结组件:训练VibeVoice主体时,预先训练好的声学和语义分词器参数被冻结。
- 关键超参数:
- 模型大小:评估了1.5B和7B参数版本的Qwen2.5 LLM。
- 扩散头:4层,约123M参数(1.5B版本)。使用余弦噪声调度,训练步数为1000。
- 分词器:声学分词器编码器/解码器各约340M参数,VAE维度64,Cσ=0.5。语义分词器架构相同。
- 推理:CFG引导比例w=1.3,扩散去噪步数T=10。
- 训练硬件:1.5B模型在64块AMD Instinct MI300X GPU上训练约170小时,使用了nnscaler训练引擎。
- 推理细节:采用DPM-Solver++作为高效采样器。每个说话人使用独立的声学提示。生成的语音是逐片段拼接的流式输出。
- 正则化/稳定技巧:使用σ-VAE(预定义方差)而非标准VAE,以缓解自回归建模中的方差崩溃问题。
📊 实验结果
- 主要生成任务对比(VIBEVOICE-Eval数据集)
- 短音频(0-12分钟)子集:
- VibeVoice-7B(序列长度32K)在所有说话人设置下(1-4人)均取得了最低的WER-W(整体0.66)和最高的SIM-O(整体0.75)。
- MoonCast在3人以上设置频繁崩溃,无法完成测试。
- 长音频(12-30分钟)子集:
- VibeVoice-7B(32K)表现最佳,整体WER-W为1.24,SIM-O为0.75。
- CosyVoice2(拼接方法)的WER较高(整体4.95),且SIM-O较低(整体0.74)。
| 模型 | 序列长度 | 1人 WER-W↓ | 1人 SIM-O↑ | 2人 WER-W↓ | 2人 SIM-O↑ | 3人 WER-W↓ | 3人 SIM-O↑ | 4人 WER-W↓ | 4人 SIM-O↑ | 整体 WER-W↓ | 整体 SIM-O↑ |
|---|---|---|---|---|---|---|---|---|---|---|---|
| VIBEVOICE-Eval Short (0~12 min) | |||||||||||
| Cosyvoice2 - Concat | - | 3.14 | 0.79 | 3.5 | 0.73 | 5.33 | 0.69 | 5.83 | 0.70 | 4.27 | 0.73 |
| MoonCast | 40K | 7.2 | 0.61 | 7.9 | 0.63 | 17.2‡ | ‡ | 11.5‡ | 0.48‡ | 10.4‡ | 0.55‡ |
| VIBEVOICE-1.5B | 64K | 0.63 | 0.63 | 1.92 | 0.59 | 1.48 | 0.58 | 1.34 | 0.58 | 1.22 | 0.60 |
| VIBEVOICE-7B | 32K | 0.47 | 0.76 | 0.53 | 0.75 | 0.68 | 0.75 | 1.02 | 0.72 | 0.66 | 0.75 |
| VIBEVOICE-Eval Long (12~30 min) | |||||||||||
| Cosyvoice2 - Concat | - | 5.76 | 0.80 | 4.94 | 0.75 | 4.34 | 0.71 | 4.77 | 0.70 | 4.95 | 0.74 |
| VIBEVOICE-1.5B | 64K | 1.80 | 0.63 | 1.59 | 0.62 | 0.97 | 0.60 | 1.80 | 0.56 | 1.55 | 0.59 |
| VIBEVOICE-7B | 32K | 1.08 | 0.79 | 1.55 | 0.77 | 0.84 | 0.73 | 1.51 | 0.71 | 1.24 | 0.75 |
- 主观评测结果 VibeVoice-7B在平均分(3.76)上超越了所有基线,包括Gemini 2.5 Pro (3.66) 和 ElevenLabs v3 alpha (3.40)。在真实感、丰富度和偏好度三个维度均获得最高分。
| 模型 | 真实感 | 丰富度 | 偏好度 | 平均 | WER-W↓ | WER-N↓ | SIM-O↑ |
|---|---|---|---|---|---|---|---|
| Elevenlabs v3 alpha | 3.34 ±1.11 | 3.48 ±1.05 | 3.38 ±1.12 | 3.40 ±1.09 | 2.39 | 2.47 | 0.623 |
| Gemini 2.5 pro preview tts | 3.55 ±1.20 | 3.78 ±1.11 | 3.65 ±1.15 | 3.66 ±1.16 | 1.73 | 2.43 | - |
| VIBEVOICE-1.5B | 3.59 ±0.95 | 3.59 ±1.01 | 3.44 ±0.92 | 3.54 ±0.96 | 1.11 | 1.82 | 0.548 |
| VIBEVOICE-7B | 3.71 ±0.98 | 3.81 ±0.87 | 3.75 ±0.94 | 3.76 ±0.93 | 1.29 | 1.95 | 0.692 |
- 消融实验
- 分词器配置:仅使用声学分词器(Acoustic-only)时,说话人相似度高(SIM-O: 0.68)但内容清晰度差(WER: 6.22)。提出的混合表示(Hybrid)在WER(1.84)和SIM-O(0.64)间取得了最佳平衡。
- 模型规模:从1.5B扩展到7B,整体WER从2.11降至0.66,SIM-O从0.59升至0.75,主观偏好分从3.54升至3.76,性能全面提升。
- CFG与扩散步数:WER在10步去噪和1.25的CFG比例下最优(图3a)。SIM-O在5步时已接近峰值,步数增加略有下降(图3b),表明过多的“去噪”可能会抹去对说话人识别有益的环境特征。
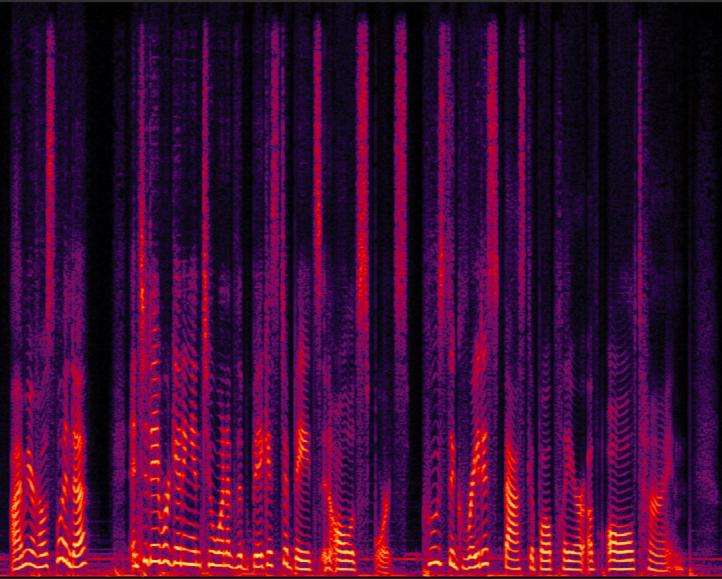 图3:CFG和DDPM步数对WER和SIM-O的影响热图。(a) WER在10步、CFG 1.25时最优;(b) SIM-O在5步时已较高,步数增加略有下降。
图3:CFG和DDPM步数对WER和SIM-O的影响热图。(a) WER在10步、CFG 1.25时最优;(b) SIM-O在5步时已较高,步数增加略有下降。
- 重建质量对比 在LibriTTS数据集上,VibeVoice的声学分词器(7.5Hz)在PESQ和UTMOS上取得了最佳或接近最佳的成绩,证明了其在极低帧率下仍能保持高保真重建。
| 模型 | 帧率 | PESQ (test-clean) | UTMOS (test-clean) |
|---|---|---|---|
| DAC (4 quantizers, 400 token rate) | 100 | 2.738 | 3.433 |
| WavTokenizer (75 token rate) | 75 | 2.373 | 4.049 |
| Ours (Acoustic) | 7.5 | 3.068 | 4.181 |
⚖️ 评分理由
- 学术质量:5.5/7:本文提出了一个针对长篇多说话人语音生成的完整且创新的解决方案,其超低帧率分词器和下一个token扩散架构在技术上具有新颖性和合理性。实验全面,与众多强基线对比,结果令人信服。扣分点在于对更极端对话场景(如严重声音重叠、多人抢话)的验证缺失,以及模型规模带来的计算成本可能限制其广泛应用。
- 选题价值:2.0/2:播客生成是当前语音技术的热点和前沿方向,具有明确的商业和应用需求。本文的工作在该方向上取得了显著进展,解决了关键的技术瓶颈,对学术界和工业界均有较高价值。
- 开源与复现加成:0.8/1:论文明确提供了代码仓库和模型检查点链接,详细披露了训练超参数、硬件配置、课程学习策略等关键复现细节,并公开了评测数据集。这种开放程度为社区复现和后续研究提供了极大便利。