📄 Unified Multi-Modal Interactive and Reactive 3D Motion Generation via Rectified Flow
#3D动作生成 #流匹配 #检索增强生成 #对比学习 #多模态模型
🔥 8.0/10 | 前25% | #音频生成 | #流匹配 | #3D动作生成 #检索增强生成
学术质量 6.5/7 | 选题价值 1.0/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Prerit Gupta†, Shourya Verma† (†表示同等贡献)
- 通讯作者:未说明
- 作者列表:Prerit Gupta(普渡大学计算机科学系)、Shourya Verma(普渡大学计算机科学系)、Ananth Grama(普渡大学计算机科学系)、Aniket Bera(普渡大学计算机科学系)
💡 毒舌点评
这篇论文最大的亮点在于其“统一”的野心——用一个框架搞定交互式和反应式两种截然不同的双人生成任务,还通过LLM分解和RAG引入了相当精细的语义引导,技术整合度很高。但短板也很明显:它本质上是一个生成框架,其成功高度依赖于底层检索库的质量和多样性,一旦遇到描述模糊或罕见的舞蹈风格,RAG模块可能从“助手”变成“累赘”,论文中也承认了这一点。
🔗 开源详情
- 代码:论文附录B承诺“Full code for this project along with the trained checkpoints for all tasks will be made open source and publicly available upon paper acceptance.”。当前未提供具体链接。
- 模型权重:如上所述,承诺将提供训练好的检查点。
- 数据集:论文中使用的三个数据集(InterHuman-AS, DD100, MDD)是现有公开或半公开数据集,论文未提及将发布新数据集。MDD是作者团队之前发布。
- Demo:论文未提及在线演示。
- 复现材料:论文提供了非常详细的实现细节(附录D)、模型参数(附录D.5)、损失函数公式(第3.5节)、训练配置(第4节实现细节)以及大量的消融实验结果(附录E、F),为复现提供了充分指导。
- 引用的开源项目/模型:CLIP (Radford et al., 2021), Jukebox (Dhariwal et al., 2020), SMPL (Loper et al., 2015)。
- 总结:论文对未来开源有明确计划和承诺,并提供了丰富的复现信息,但当前代码和权重尚未公开。
📌 核心摘要
- 问题:生成由文本、音乐等多种模态条件驱动的协调、逼真的双人3D动作是一个难题。现有方法要么只处理交互式,要么只处理反应式任务,且通常只支持单一模态,缺乏统一框架。
- 方法:论文提出了DualFlow,一个基于Rectified Flow的统一框架。其核心是设计了级联的“DualFlow块”,通过掩码机制灵活切换以处理交互式(双分支对称)和反应式(演员分支掩码)任务。引入了为双人动作设计的RAG模块,使用LLM将文本分解为空间关系、身体动作和节奏三个维度进行检索。
- 创新点:(1) 首个统一交互与反应双人生成的单一框架;(2) 针对双人动作的LLM分解RAG模块;(3) 结合了对比学习的Rectified Flow目标和同步损失。
- 实验结果:在MDD、InterHuman-AS和DD100数据集上的广泛评估表明,DualFlow在多数指标上达到SOTA。例如,在MDD数据集的交互任务中,DualFlow(Both)的FID为0.415(优于InterGen(Both)的0.426),R-Precision@3为0.513(优于InterGen(Both)的0.302)。推理速度方面,仅需20步即可完成,比需要50步的50-DDIM基线快约2.5倍。
- 意义:为VR/AR伴侣、社交机器人和游戏AI等需要生成协调多人行为的应用提供了一个更通用、更高效的基础框架。
- 局限性:性能依赖于检索库质量;在反应式设置中可能出现轻微的身体穿透;长序列生成可能有时序漂移。
🏗️ 模型架构
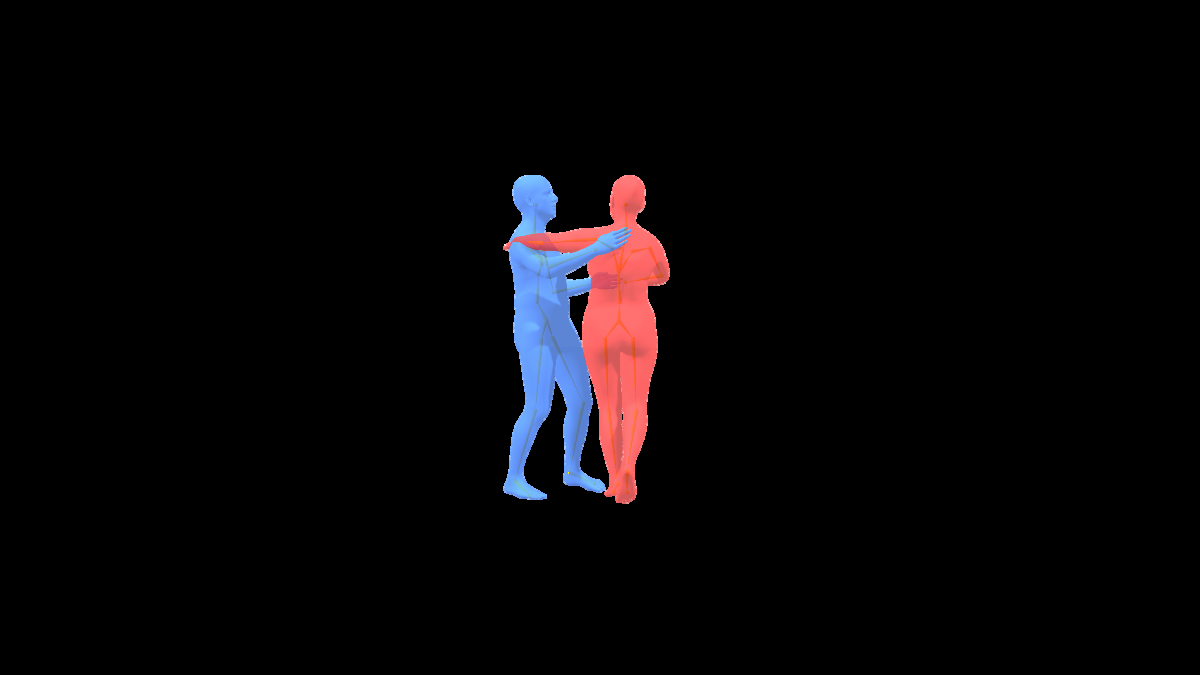 图1展示了DualFlow如何统一处理交互式和反应式生成,并利用文本(经LLM分解)、音乐和检索样本作为条件输入。
图1展示了DualFlow如何统一处理交互式和反应式生成,并利用文本(经LLM分解)、音乐和检索样本作为条件输入。
 图2是DualFlow的具体架构,分为(a)整体流程和(b)单个DualFlow块内部结构。
图2是DualFlow的具体架构,分为(a)整体流程和(b)单个DualFlow块内部结构。
整体输入输出流程:
- 输入:文本描述、音乐片段。在交互模式下,输入还有来自双人(A和B)的含噪动作序列;在反应模式下,只输入反应者(B)的含噪动作,而行动者(A)的真实动作用于条件化。
- 处理:文本通过CLIP-L/14和Transformer编码器得到文本潜在表示
z_d;音乐通过Jukebox编码器和Transformer编码器得到音乐潜在表示z_m。文本描述同时被LLM分解为空间、身体、节奏三个子描述,每个子描述与音乐特征共同用于检索库中检索相关的动作样本,经过编码后聚合为检索潜在表示z_R。这些条件信号{z_d, z_m, z_R}将共同指导生成。 - 输出:经过N个级联的DualFlow块处理后,输出去噪后的动作序列。在交互模式下输出双人动作;在反应模式下仅输出反应者的动作。
主要组件:
- 条件编码器:负责将不同模态的输入(文本、音乐、检索动作)编码到统一的潜在空间。
- DualFlow块:核心生成模块。每个块包含:
- 多尺度时间卷积:并行使用不同核大小(7, 11, 21)的1D卷积捕获不同时间分辨率的动作模式,通过可学习门控权重融合。
- 自注意力层:建模动作序列内部的时间依赖关系。
- 音乐交叉注意力层:使动作潜在表示与音乐潜在表示
z_m对齐,实现音动作同步。 - 动作交叉注意力层(交互模式)/因果交叉注意力层(反应模式):这是实现任务统一的关键。在交互模式下,两个分支通过此层相互交换信息,实现协调。在反应模式下,演员分支被掩码,反应者分支通过一个带有“前瞻(Look-Ahead)”参数L的因果注意力层,仅能关注演员动作的过去和有限未来(L帧),以实现预测性反应。
- 检索交叉注意力层:引入检索到的示例动作信息
z_R,为生成提供细粒度的语义引导。 - 前馈网络(FFN)和残差连接:标准Transformer组件,用于稳定训练和增加非线性。
关键设计选择与动机:
- 掩码机制切换任务:这是“统一”的核心。无需重新训练或切换模型,只需在输入端掩码行动者动作,并将块内的注意力层从“动作交叉注意力”切换为“因果交叉注意力”,即可从交互生成变为反应生成。
- 因果注意力与前瞻:在反应生成中,模型需要根据行动者未来的运动趋势来反应。纯因果模型无法做到。前瞻参数L允许反应者看到行动者未来L帧的信息,这在物理上是合理的(例如,舞伴在做出动作前会传递意图),同时保证了生成时的因果性。
- 多尺度卷积:人类动作在不同时间尺度上具有不同特征(如瞬时步伐、连贯手势),多尺度卷积能更全面地捕捉这些模式。
💡 核心创新点
- 统一的双人生成框架:首次将交互式(协调)和反应式(单向响应)双人动作生成整合到一个模型中。通过精巧的掩码和注意力切换机制,实现了无需重训练的任务切换,简化了多任务学习流程。
- 面向双人的检索增强生成(RAG):突破现有单人RAG的局限。创新性地利用LLM将自由文本分解为三个与拉班动作分析对齐的维度(空间、身体、节奏),并分别建立检索库。这提升了检索的精确性和对生成的引导效果,使动作在语义层面更忠实。
- 对比Rectified Flow与同步损失:将Rectified Flow引入双人生成领域,利用其直线采样路径提升了生成速度和质量。进一步引入对比三元组损失,在速度空间中对齐语义相似的动作,增强了条件对齐和动作表示的判别性。专门为双人协调设计的同步损失
L_sync,通过解剖学加权和距离加权,显式地约束了关键关节对的空间关系,提升了动作的协调性与物理合理性。
🔬 细节详述
- 训练数据:
- InterHuman-AS:超过50K个交互片段,11种动作类型(握手、拥抱等),包含SMPL-X格式的配对序列。
- DD100:100个双人舞蹈套路(萨尔萨、嘻哈、华尔兹等),包含高精度动捕数据和配对音乐。
- MDD:大规模多模态双人舞蹈数据集,10.3小时动捕数据,10K+文本标注。
- 损失函数:
L_flow:Rectified Flow的核心损失,最小化预测速度与目标速度的平方误差。L_triplet:对比三元组损失,拉近语义相似动作的速度表示,推远不相似的。边际m=0.2,权重λ_triplet=0.1。L_geo:几何损失,包含脚部接触损失L_foot、关节速度损失L_vel(权重30)、骨骼长度损失L_BL(权重10)。L_inter:交互损失,包含关节距离图损失L_DM(权重3)、相对方向损失L_RO(权重0.01)和同步损失L_sync(权重5)。L_sync对预测和真实关节间距离进行加权L2损失,权重w_d随真实距离指数衰减,w_j根据关节组(手、上半身、下半身等)分配不同重要性。
- 训练策略:Adam优化器,学习率2e-4,权重衰减2e-5,1000步warm-up,批量大小32,训练5000个epoch。使用余弦β调度器。
- 关键超参数:
- 模型:20个级联DualFlow块,8个注意力头,隐藏维度512,FFN维度1024,Dropout率0.1。
- 输入:动作维度262(基于SMPL 22关节),文本CLIP嵌入768维,音乐Jukebox特征4800维。
- 反应设置前瞻参数:L=10帧。
- 分类器自由引导:双模态随机丢弃10%,单模态随机丢弃20%。
- 训练硬件:未说明。
- 推理细节:使用Rectified Flow的确定性ODE求解器,共20步。对于10秒、30FPS的序列,在RTX 5090 GPU上平均推理时间为1.24秒。
- 正则化技巧:使用Flash Attention加速计算;在训练中通过掩码实现分类器自由引导。
📊 实验结果
主要对比实验结果
表1:MDD数据集双模态(文本+音乐)条件下的双人与反应任务结果
| 方法 | 任务 | R-Precision@1 | R-Precision@2 | R-Precision@3 | FID↓ | MMDist↓ | Diversity | MModal | BED↑ | BAS↑ |
|---|---|---|---|---|---|---|---|---|---|---|
| Ground Truth | - | 0.231 | 0.398 | 0.522 | 0.065 | 0.077 | 1.387 | - | 0.327 | 0.170 |
| InterGen(Both) | Duet | 0.105 | 0.206 | 0.302 | 0.426 | 1.532 | 1.380 | 1.352 | 0.385 | 0.185 |
| DualFlow(Both) | Duet | 0.185 | 0.373 | 0.513 | 0.415 | 0.513 | 1.392 | 1.467 | 0.286 | 0.179 |
| DuoLando(Both) | Reactive | 0.078 | 0.156 | 0.219 | 0.698 | 2.113 | 1.371 | - | 0.395 | 0.224 |
| DualFlow(Both) | Reactive | 0.189 | 0.341 | 0.471 | 0.686 | 1.056 | 1.203 | 1.473 | 0.215 | 0.226 |
结论:在MDD数据集上,DualFlow在交互任务的语义对齐(R-Precision, MMDist)和反应任务的分布质量(FID)、语义对齐及多模态多样性上均显著优于最强基线。
表2:InterHuman-AS数据集纯文本条件下的交互与反应任务结果
| 方法 | 任务 | R-Precision@1 | R-Precision@3 | FID↓ | MMDist↓ | Diversity | MModal |
|---|---|---|---|---|---|---|---|
| Ground Truth | - | 0.452 | 0.701 | 0.273 | 3.755 | 7.948 | - |
| InterGen | Duet | 0.371 | 0.624 | 5.918 | 5.108 | 7.387 | 2.141 |
| DualFlow | Duet | 0.437 | 0.681 | 6.296 | 4.394 | 7.116 | 2.729 |
| ReGenNet(UC) | Reactive | - | 0.407 | 2.265 | 6.860 | 5.214 | 2.391 |
| DualFlow(UC) | Reactive | 0.381 | 0.572 | 2.581 | 6.314 | 5.449 | 2.502 |
结论:在纯文本条件下,DualFlow在语义检索精度上全面领先,展现出更强的文本-动作对齐能力。
表3:DD100数据集纯文本条件下的反应任务结果
| 方法 | FIDk↓ | FIDg↓ | Divk↑ | Divg↑ | FIDcd↓ | Divcd↑ | BED↑ | BAS↑ |
|---|---|---|---|---|---|---|---|---|
| Ground Truth | 6.56 | 6.37 | 11.31 | 7.61 | 3.41 | 12.35 | 0.5308 | 0.1839 |
| Duolando | 25.30 | 33.52 | 10.92 | 7.97 | 9.97 | 14.02 | 0.2858 | 0.2046 |
| DualFlow | 19.22 | 28.85 | 11.01 | 7.35 | 5.57 | 19.52 | 0.2767 | 0.2113 |
结论:在专业舞蹈反应任务上,DualFlow在动作质量(FID系列指标)和节奏对齐(BAS)上优于现有方法。
关键消融实验(MDD数据集)
- 表4显示,移除任何关键组件(RAG、对比损失、同步损失、高级音乐特征)均会导致性能下降,验证了各模块的有效性。
- 表7(RAG消融)揭示了有趣现象:在交互任务中,检索样本数k=5是最佳平衡点;而在反应任务中,k=3更优,且移除音乐检索反而提升部分指标,表明在紧密同步中动作线索比音乐线索更重要。
- 图4显示了FID随推理步数的变化曲线,清晰表明DualFlow仅需20步就能达到比InterGen 50步更好的FID值,效率优势明显。
 图3展示了用户研究结果,在语义对齐、音乐同步和总体质量三个维度上,DualFlow均获得了超过50%的偏好率,优于基线方法。
图3展示了用户研究结果,在语义对齐、音乐同步和总体质量三个维度上,DualFlow均获得了超过50%的偏好率,优于基线方法。
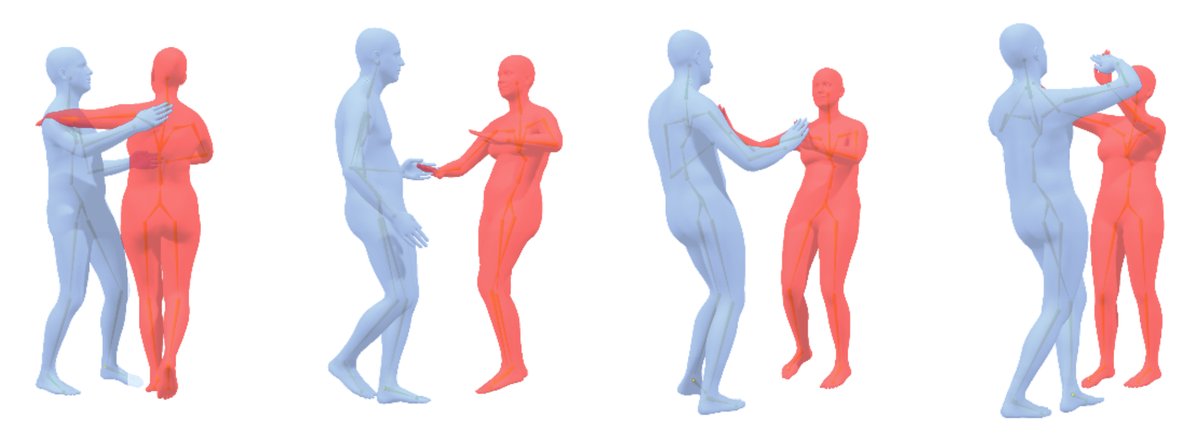 图4直观对比了DualFlow与InterGen在不同推理步数下的FID表现,证实了Rectified Flow在采样效率上的优势。
图4直观对比了DualFlow与InterGen在不同推理步数下的FID表现,证实了Rectified Flow在采样效率上的优势。
 图5通过可视化对比,展示了DualFlow生成的动作在协调性、平滑度和文本对齐上优于InterGen和DuoLando。
图5通过可视化对比,展示了DualFlow生成的动作在协调性、平滑度和文本对齐上优于InterGen和DuoLando。
⚖️ 评分理由
- 学术质量:6.5/7:创新性突出(统一框架、双人RAG),技术方案正确且完整(Rectified Flow应用、精心设计的损失函数),实验设计全面(三个数据集、多指标、消融、用户研究),证据链完整,结果具有说服力。扣分点在于部分超参数(如损失权重)的选择依赖经验值,且理论分析可进一步深化。
- 选题价值:1.0/2:前沿性高,属于生成模型在复杂交互场景的深入应用,对动画、游戏、机器人等领域有推动作用。但选题本身与“音频/语音”读者的核心关注点距离较远,属于间接相关的扩展领域。
- 开源与复现加成:0.5/1:论文明确承诺开源代码和模型,并提供了极其详尽的实现细节、架构描述和消融实验设置,极大地便利了复现。当前扣分主要因代码实际尚未公开。