📄 Towards True Speech-to-Speech Models Without Text Guidance
#语音对话系统 #大语言模型 #端到端 #预训练 #流式处理
🔥 9.1/10 | 前10% | #语音对话系统 | #大语言模型 #端到端 | #大语言模型 #端到端
学术质量 6.5/7 | 选题价值 1.8/2 | 复现加成 0.8 | 置信度 高
👥 作者与机构
- 第一作者:Xingjian Zhao (Fudan University, MOSI.AI)
- 通讯作者:Xipeng Qiu (Fudan University, Shanghai Innovation Institute)
- 作者列表:Xingjian Zhao (Fudan University, MOSI.AI)、Zhe Xu (Fudan University, Shanghai Innovation Institute, MOSI.AI)、Luozhijie Jin (Fudan University, Shanghai Innovation Institute, MOSI.AI)、Yang Wang (Fudan University, MOSI.AI)、Hanfu Chen (Fudan University, MOSI.AI)、Yaozhou Jiang (Fudan University, MOSI.AI)、Ke Chen (Fudan University, Shanghai Innovation Institute, MOSI.AI)、Ruixiao Li (Fudan University, Shanghai Innovation Institute, MOSI.AI)、Mingshu Chen (Fudan University, MOSI.AI)、Ruiming Wang (Fudan University, MOSI.AI)、Wenbo Zhang (Fudan University, Shanghai Innovation Institute, MOSI.AI)、Qinyuan Cheng (Fudan University, MOSI.AI)、Zhaoye Fei (Fudan University, MOSI.AI)、Shimin Li (MOSI.AI)、Xipeng Qiu (Fudan University, Shanghai Innovation Institute)
- 机构:复旦大学、上海创新研究院、MOSI.AI。
💡 毒舌点评
这篇工作真正意义上逼近了“无文本指导”的语音大模型愿景,其“模态分层”设计从隐藏状态相似性分析中获得灵感,是工程直觉与理论分析的漂亮结合。然而,其高质量合成数据的依赖(特别是助理端语音)和庞大的模型参数量,可能使其在“真实性”和部署门槛上面临现实挑战,离真正廉价、通用的语音交互还有一步之遥。
🔗 开源详情
- 代码:论文中明确表示“我们将会发布代码和模型”(We will release our code and models),但未提供具体链接。状态为承诺发布。
- 模型权重:同上,承诺发布。
- 数据集:预训练和SFT数据集多为公开或可获取(如Librispeech, FineWeb-Eu),但论文构建的SFT数据集未提及公开。论文中未提及将公开其合成SFT数据集。
- Demo:未提及。
- 复现材料:论文详细提供了预训练和SFT的数据规模、流程、关键超参数、消融实验设置。附录包含数据适应提示词、相似度计算公式、解冻学习率调度等,对复现非常友好。
- 引用的开源项目:论文中引用并依赖的主要开源项目/工具有:Qwen-3-8B(骨干), CosyVoice 2(语音分词器基础), Librispeech(评测), FineWeb-Eu/Chinese FineWeb-Edu V2.1(数据), pyannote(VAD), Seed-TTS(语音合成), SenseVoice-Small(质量过滤)。
- 整体开源计划:论文承诺开源核心代码和模型,复现指引详细,但未提及发布合成SFT数据集。
📌 核心摘要
本文旨在解决当前语音对话系统依赖文本中间表示所带来的延迟高、信息损失(副语言线索丢失)和表现力受限的根本问题。核心方法是构建一个真正的端到端语音到语音大语言模型。模型架构上,创新性地采用“模态分层”设计,在Transformer骨干的第32层将共享表示路由到模态特定的输出分支(文本4层,语音4层),以利用底层融合并支持模态特异性生成。训练上,采用两阶段“冻结预训练”策略:先冻结预训练的文本LLM骨干,仅训练新增的语音组件以实现对齐;再进行联合微调,同时引入文本数据以保持文本能力。实验结果表明,该模型在语音问答(如LlamaQA达77.33%/63.67% S→T/S→S)任务上达到了SOTA水平,同时在文本理解基准(MMLU 67.19, CMMLU 69.53)上几乎保持了原LLM的性能(Qwen3-8B)。消融研究证实了模态分层和冻结预训练策略对于平衡语音学习和文本能力保持的关键作用。该工作为建立更具表现力和效率的端到端语音交互范式奠定了基础。主要局限性包括对大规模高质量合成数据的依赖,以及模型本身较大的参数规模可能带来的部署成本。
🏗️ 模型架构
模型基于一个36层的自回归Transformer骨干(初始化自Qwen3-8B)。整体流程分为语音编码、LLM处理和语音解码三个部分。
- 模态分层架构(核心创新)
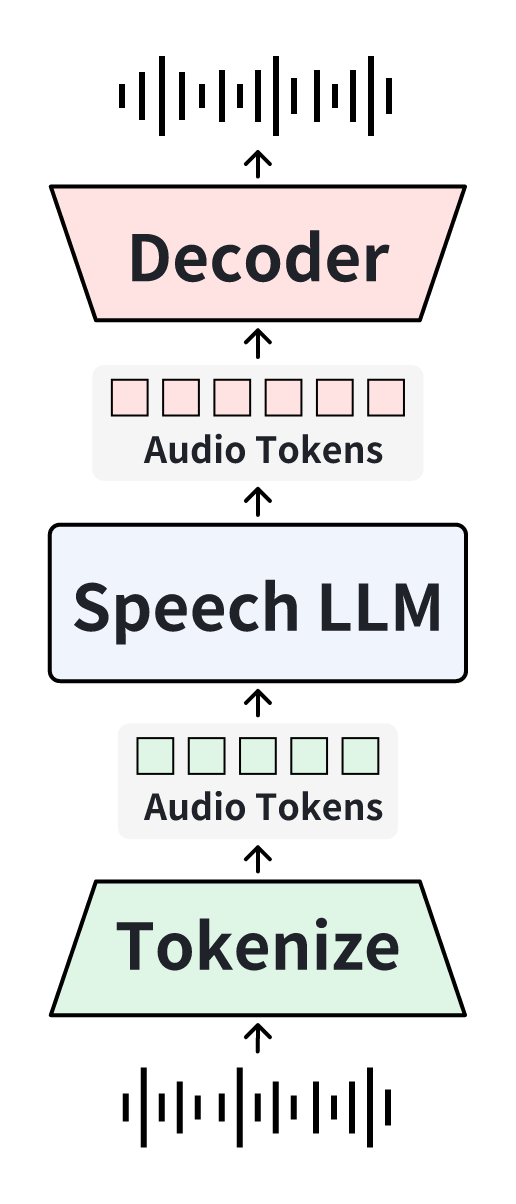 图3展示了核心架构:一个共享的32层Transformer骨干(前32层)。在第32层后,隐藏状态被路由到两个平行的模态特定分支:
图3展示了核心架构:一个共享的32层Transformer骨干(前32层)。在第32层后,隐藏状态被路由到两个平行的模态特定分支:
- 文本分支:接在原始文本嵌入和语言模型头之后,包含4层额外的Transformer层和文本LM头,用于预测文本token。
- 语音分支:接在语音token嵌入之后,包含4层独立的Transformer层和语音LM头,用于预测语音token。 该设计的动机(由图2启发)是:在骨干模型中,文本和语音的隐藏状态表示在前25层左右逐渐融合(相似性高),但在最后几层开始发散。因此,前32层用于学习跨模态融合,后4层则专注于各模态的特定生成任务,从而既能利用LLM的预训练知识,又能增强模态间的传输。
- 语音标记器
- 编码器:采用基于ASR训练的离散语音编码器。它以GLM-4-Voice Tokenizer为基础,被改造为全因果(causal)结构以支持真正的流式处理。其训练目标是ASR,旨在最大化语义信息保留,输出为低比特率(175 bps)、单码本的离散token序列。
- 解码器:采用基于CosyVoice 2的流匹配(Flow Matching)架构,并进行了流式优化(压缩chunk size以减少延迟),用于从离散token高保真地重建语音波形。
- 输入/输出流程
- 输入:可以是文本序列或语音token序列(由语音编码器生成)。输入通过各自的嵌入层进入模型。
- 处理:混合模态的token序列在共享的32层Transformer中处理,进行深度融合。
- 输出:根据任务需要,激活相应模态的分支(文本或语音),生成下一个文本token或语音token。支持四种模态组合:语音问→语音答,语音问→文本答,文本问→语音答,文本问→文本答。
💡 核心创新点
- 模态分层架构:这是最核心的创新。与之前将语音token简单扩展词汇表或使用统一网络处理所有层不同,本文通过分析层间跨模态相似性,在骨干网络末端进行显式分流。这使模型在底层能充分融合信息,在顶层则能专门化生成,有效缓解了向LLM添加语音模态时常见的文本能力退化问题。
- 冻结预训练策略:在第一阶段预训练中,冻结整个文本LLM骨干,只训练新加入的语音组件(嵌入、特定层、LM头)。这提供了一个稳定且低风险的方式来初始化语音能力,并建立与预训练文本表征的良好对齐,避免了早期训练破坏LLM原有能力。
- 真正的端到端,无文本指导:模型在生成阶段,其语音分支的预测不依赖任何中间文本表示。语音响应直接由语音token预测生成,避免了文本引导方法中的信息瓶颈和延迟,支持如笑声、犹豫等非文本可表示的副语言现象。
- 高质量流式语音标记器:设计了同时满足单码本低比特率、高语义、支持流式和高保真的语音分词器,其中编码器使用ASR目标并改为全因果,解码器优化了流匹配的延迟。
🔬 细节详述
- 训练数据:
- 预训练数据:约900万小时网络音频,经VAD处理后得到约400万小时语音。分为两类:1) 交错语音-文本数据(主要来自播客),使用ASR转录并基于CTC对齐切分成3-6秒的随机片段,交错排列;2) 无监督语音数据(主要来自视频),使用完整音频片段。此外,使用FineWeb-Eu等文本语料合成交错数据以提升知识密度。总规模见表1。
- 监督微调数据:基于现有开源文本SFT数据集,使用GPT-5 API进行文本适应(转为口语化、过滤不适合内容),然后使用Seed-TTS和MOSS-TTSD合成语音。用户角色语音多样,助手角色语音固定。通过ASR质量过滤(WER<0.2)。最终得到超过150万对问答对。
- 损失函数:未在正文中明确说明。根据描述,LLM部分应使用标准的下一个token预测交叉熵损失。语音解码器(流匹配)使用其对应的流匹配损失。
- 训练策略:
- 预训练阶段1:冻结Qwen3-8B所有参数。仅训练语音嵌入、语音特定层(4层)和语音LM头。优化器AdamW,学习率4e-4,cosine衰减,批大小2.2M tokens,上下文长度14,336,权重衰减0.1。训练约1个epoch。
- 预训练阶段2:采用三种解冻配置之一(默认全部参数解冻)。加入文本数据(FineWeb-Eu)联合训练。学习率降低(6e-5衰减至6e-6),批大小增至2.8M tokens。训练2个epoch语音数据+0.1个epoch文本数据。
- 监督微调:在预训练模型上,使用构建的SFT数据训练2个epoch。学习率从1e-5衰减至1e-6,批大小8,最大上下文长度10,240 tokens,序列打包。训练时采用四种输入-输出模态组合以增强跨模态对齐。
- 关键超参数:
- 模型骨干:36层Transformer(32共享+4模态特定),基于Qwen3-8B。
- 语音标记器:编码器帧率12.5Hz,比特率175bps。解码器使用流匹配。
- 训练硬件:未在论文中明确说明。
- 推理细节:LLM部分为自回归生成。语音解码器为流式解码。论文提到解码策略如温度等具体值未说明。
- 正则化技巧:使用了权重衰减、学习率调度(cosine)、序列打包等标准技巧。
📊 实验结果
主要对比与SOTA声明:
- 语音问答任务(表5):在LlamaQA(S→T)、TriviaQA(S→T)和WebQA(S→T/S→S)上,SFT后的模型均达到或超越现有最佳结果。例如,在WebQA S→T上,本文模型(45.90)远超GLM-4-Voice(39.22)。
语音建模与文本能力保持(表4):
| 模型 | 语音任务 (S.C.) | 文本任务 | |||||
|---|---|---|---|---|---|---|---|
| tS.C. | sS.C. | zh-tS.C. | zh-sS.C. | MMLU | CMMLU | ||
| Moshi | 83.60 | 62.70 | - | - | 49.8 | - | |
| GLM-4-Voice | 82.90 | 62.40 | 83.27 | 69.10 | 57.49 | 54.39 | |
| SpiritLM | 82.90 | 61.00 | - | - | 36.90 | - | |
| Ours | 84.87 | 63.17 | 90.32 | 71.94 | 67.19 | 69.53 | |
| 表4关键结论:本文模型在所有语音建模和文本理解基准上均大幅超越SpiritLM、GLM-4-Voice和Moshi,证明其既能学习语音,又极好地保持了预训练LLM的知识。 |
消融实验(表6):
| 模型 | 分割层数 | 语音 | 文本 | ||||
|---|---|---|---|---|---|---|---|
| tS.C. | sS.C. | zh-tS.C. | zh-sS.C. | MMLU | CMMLU | ||
| FP-Full | 4 | 85.20 | 63.12 | 90.21 | 72.10 | 66.50 | 69.15 |
| NF | 4 | 77.66 | 56.60 | 88.51 | 67.56 | 62.11 | 64.11 |
| NF-NoSplit | 0 | 77.12 | 55.80 | 88.72 | 67.02 | 60.97 | 63.73 |
| Qwen3-8B | - | - | - | - | - | 76.60 | 77.35 |
| 表6关键结论:1) 模态分层(Split)至关重要:对比NF(分割4层)与NF-NoSplit(不分割),语音和文本分数均有提升。2) 冻结预训练(Frozen Pretrain)效果显著:对比NF与FP-Full,在所有指标上都带来巨大提升。3) 不同解冻策略差异不大:FP-Full, FP-Shared, FP-Layerwise结果相近。 |
生成语音质量(表3,与CosyVoice 2对比):
| 模型 | 帧率 | 英文Seed-TTS-Eval | 中文Seed-TTS-Eval | ||||
|---|---|---|---|---|---|---|---|
| WER↓ | SIM↑ | DNSMOS↑ | WER↓ | SIM↑ | DNSMOS↑ | ||
| Cosyvoice2 | 25hz | 4.63 | 0.68 | 3.09 | 3.11 | 0.75 | 3.22 |
| Ours | 12.5hz | 4.14 | 0.67 | 3.10 | 2.86 | 0.73 | 3.24 |
| 表3关键结论:本文解码器在更低帧率下,在可懂度(WER)和感知质量(DNSMOS)上优于基线CosyVoice 2,仅在说话人相似度(SIM)上略有不及。 |
非言语行为生成的人工评估(表8):
| 行为 | Ours | GPT-4o | Gemini |
|---|---|---|---|
| 停顿 | 4.17 | 2.81 | 2.73 |
| 填充词 | 4.15 | 3.11 | 2.85 |
| 响应风格 | 4.25 | 3.59 | 3.22 |
| 表8关键结论:在生成停顿、填充词(如轻笑)等非言语行为方面,本文模型显著优于GPT-4o和Gemini,证明了其在表现力上的优势。 |
模型层级相似度分析(图2):
 该图展示了在不同模型层(0, 10, 24, 27),语音和文本隐藏状态的余弦相似度热力图及整体得分曲线。关键发现:相似度在第10层左右达到高峰,在第25层后开始下降,在最后几层显著降低。这一��证观察直接驱动了“在第32层进行模态分层”的设计选择。
该图展示了在不同模型层(0, 10, 24, 27),语音和文本隐藏状态的余弦相似度热力图及整体得分曲线。关键发现:相似度在第10层左右达到高峰,在第25层后开始下降,在最后几层显著降低。这一��证观察直接驱动了“在第32层进行模态分层”的设计选择。
⚖️ 评分理由
- 学术质量:6.5/7:创新性极高,提出的“模态分层+冻结预训练”是一套针对LLM语音化难题的完整、新颖且有效的解决方案。技术实现细节清晰,有深度的分析(如隐藏状态相似度)作为支撑。实验设计全面,有充分的基线对比、消融研究和人工评估,数据可信。
- 选题价值:1.8/2:直击当前语音交互系统的核心瓶颈(文本中间件),探索最自然的交互方式。成果对学术界和工业界(智能助手、可穿戴设备、无障碍应用)均具有明确且重大的价值。
- 开源与复现加成:0.8/1:明确承诺开源,文中提供了相当多的训练细节和超参数,复现门槛相对较低。主要扣分点在于部分数据依赖外部合成,且未提供所有硬件的详细规格。